提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 消息确认机制介绍
- 手动确认方法
- 代码前言
- 代码编写
- 消息确认机制的演示
- 持久化介绍
- 持久化代码
- 持久化代码演示
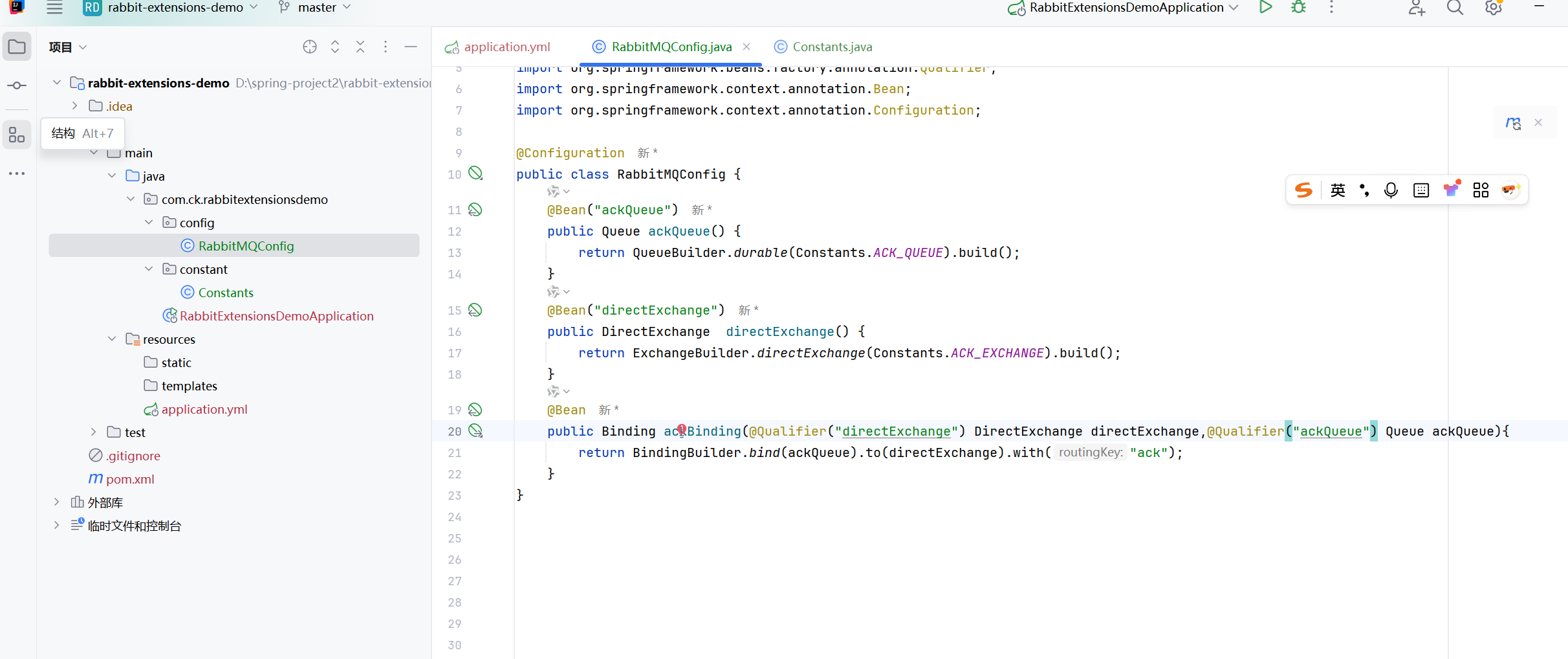
- 发送方确认介绍
- confirm模式代码
- confirm模式演示
- return退出模式介绍
- 常见面试题
- 重试机制介绍
- 重试机制-自动确认
- 重试机制-手动确认
- 设置消息TTL
- 设置队列的ttl
- 死信队列介绍
- 死信队列案例
- 死信其他情况案例
- 死信面试题
- 总结
前言
消息确认机制介绍
确认又分为自动确认和手动确认
自动确认就是消息送到了消费者,就把消息删除,就认为消息确认了,不管消费者是否收到
手动确认就是消费者确认了队列才会删除消息
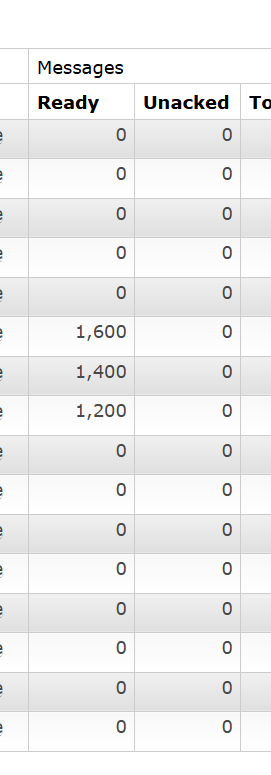
ready的意思就是准备好发给消费者了
unack的意思就是消费者还没有确认
手动确认方法
- 肯定确认: Channel.basicAck(long deliveryTag, boolean multiple)
RabbitMQ 已知道该消息并且成功的处理消息. 可以将其丢弃了.
参数说明:
- deliveryTag: 消息的唯⼀标识,它是⼀个单调递增的64 位的⻓整型值. deliveryTag 是每个通道
(Channel)独⽴维护的, 所以在每个通道上都是唯⼀的. 当消费者确认(ack)⼀条消息时, 必须使⽤对应的通道上进⾏确认. - multiple: 是否批量确认. 在某些情况下, 为了减少⽹络流量, 可以对⼀系列连续的 deliveryTag 进
⾏批量确认. 值为 true 则会⼀次性 ack所有⼩于或等于指定 deliveryTag 的消息. 值为false, 则只确认当前指定deliveryTag 的消息
这里的手动确认与原来的发布确认是不一样的
- 否定确认: Channel.basicReject(long deliveryTag, boolean requeue)
RabbitMQ在2.0.0版本开始引⼊了 Basic.Reject 这个命令, 消费者客⼾端可以调⽤
channel.basicReject⽅法来告诉RabbitMQ拒绝这个消息.
参数说明:
- deliveryTag: 参考channel.basicAck
- requeue: 表⽰拒绝后, 这条消息如何处理. 如果requeue 参数设置为true, 则RabbitMQ会重新将这条消息存⼊队列,以便可以发送给下⼀个订阅的消费者. 如果requeue参数设置为false, 则RabbitMQ会把消息从队列中移除, ⽽不会把它发送给新的消费者
- 否定确认: Channel.basicNack(long deliveryTag, boolean multiple,boolean requeue)
Basic.Reject命令⼀次只能拒绝⼀条消息,如果想要批量拒绝消息,则可以使⽤Basic.Nack这个命令. 消费者客⼾端可以调⽤ channel.basicNack⽅法来实现.参数介绍参考上⾯两个⽅法.multiple参数设置为true则表⽰拒绝deliveryTag编号之前所有未被当前消费者确认的消息
代码前言
我们基于SpringBoot来演⽰消息的确认机制, 使⽤⽅式和使⽤RabbitMQ Java Client 库有⼀定差异
Spring-AMQP 对消息确认机制提供了三种策略.
bash
public enum AcknowledgeMode {
NONE,
MANUAL,
AUTO;
}- AcknowledgeMode.NONE
◦ 这种模式下, 消息⼀旦投递给消费者, 不管消费者是否成功处理了消息, RabbitMQ 就会⾃动确认
消息, 从RabbitMQ队列中移除消息. 如果消费者处理消息失败, 消息可能会丢失. - AcknowledgeMode.AUTO(默认)
◦ 这种模式下, 消费者在消息处理成功时会⾃动确认消息, 但如果处理过程中抛出了异常, 则不会确
认消息. - AcknowledgeMode.MANUAL
◦ ⼿动确认模式下, 消费者必须在成功处理消息后显式调⽤ basicAck ⽅法来确认消息. 如果消
息未被确认, RabbitMQ 会认为消息尚未被成功处理, 并且会在消费者可⽤时重新投递该消息, 这
种模式提⾼了消息处理的可靠性, 因为即使消费者处理消息后失败, 消息也不会丢失, ⽽是可以被
重新处理
代码编写
先写生产者
这个就是自动确认
然后就可以发送消息了
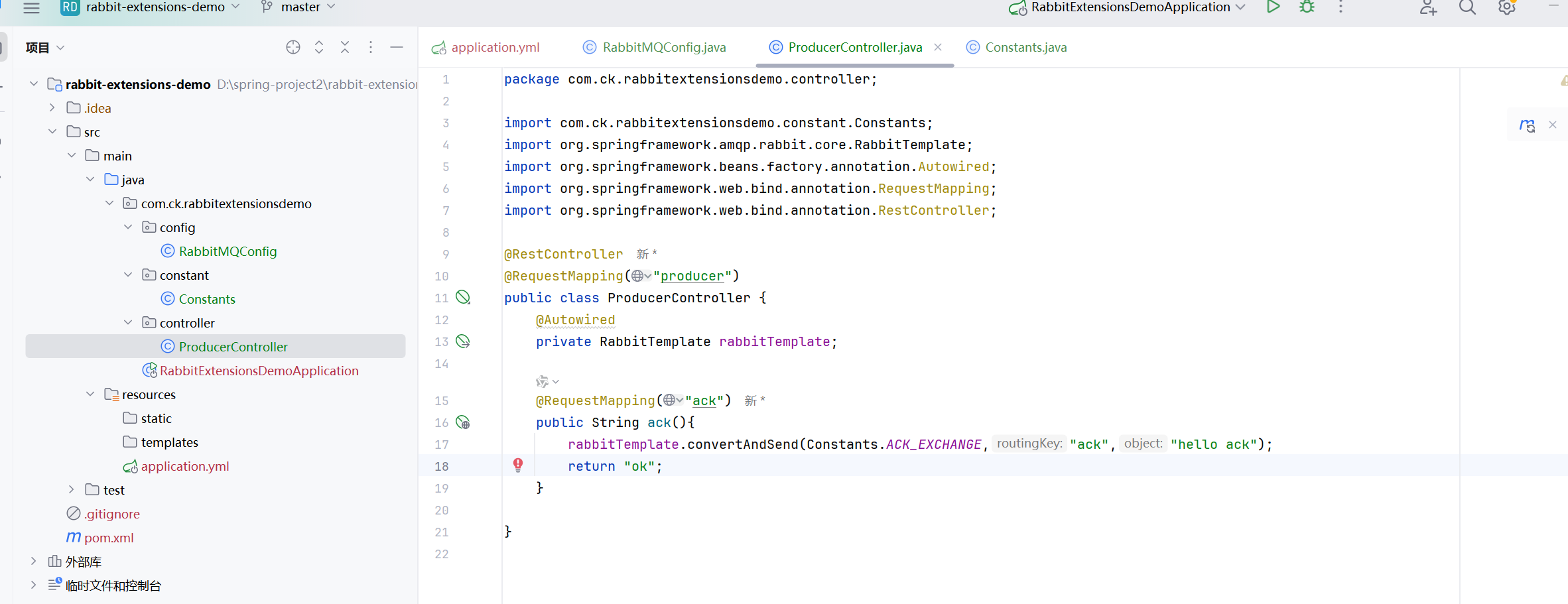
然后是消费者
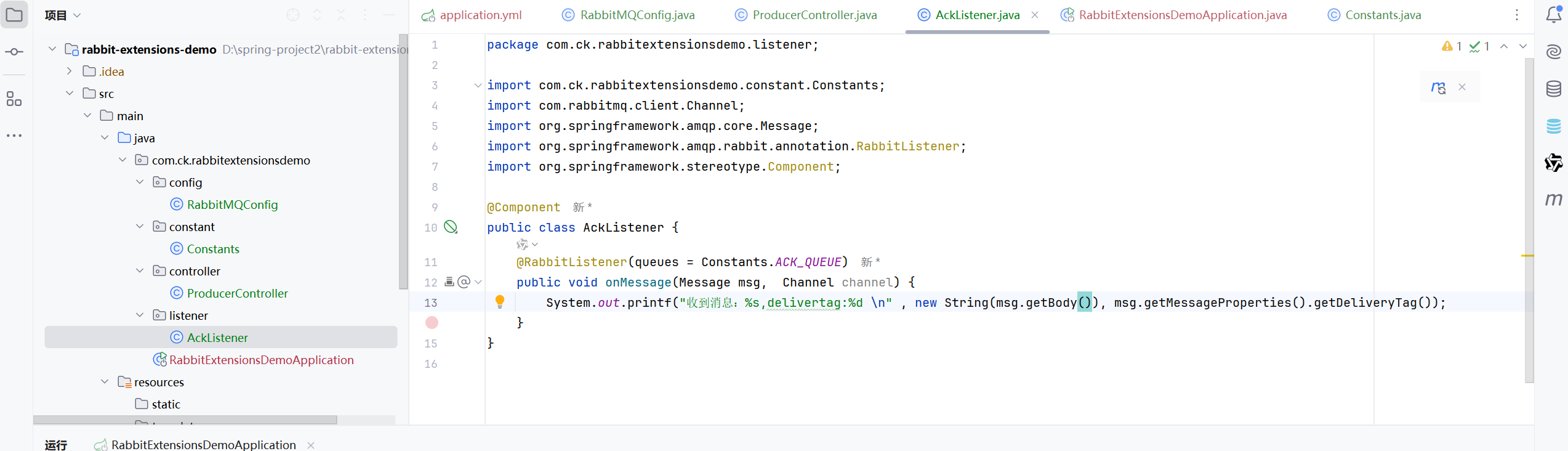
消息确认机制的演示
自动确认
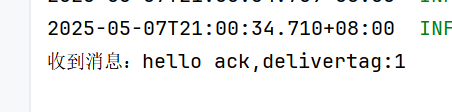
这个自动确认模式,就算消费者出现异常,也是会从队列中删除消息的
auto
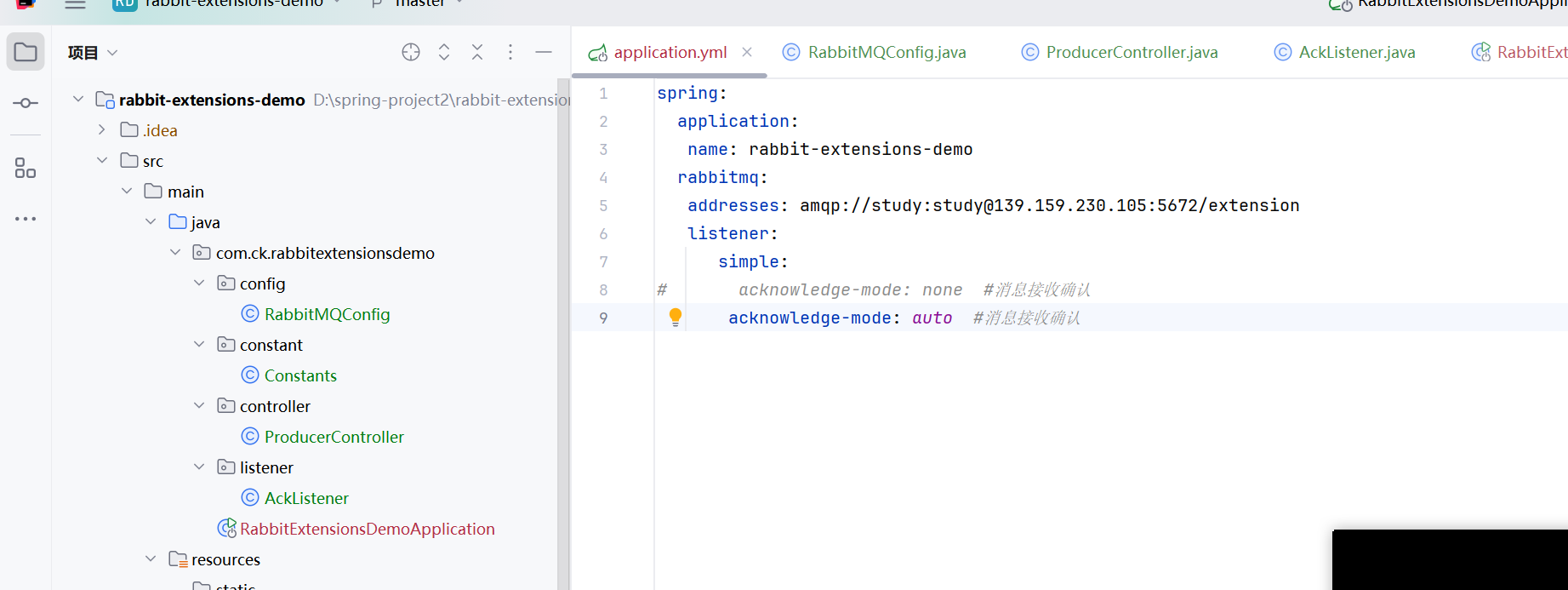
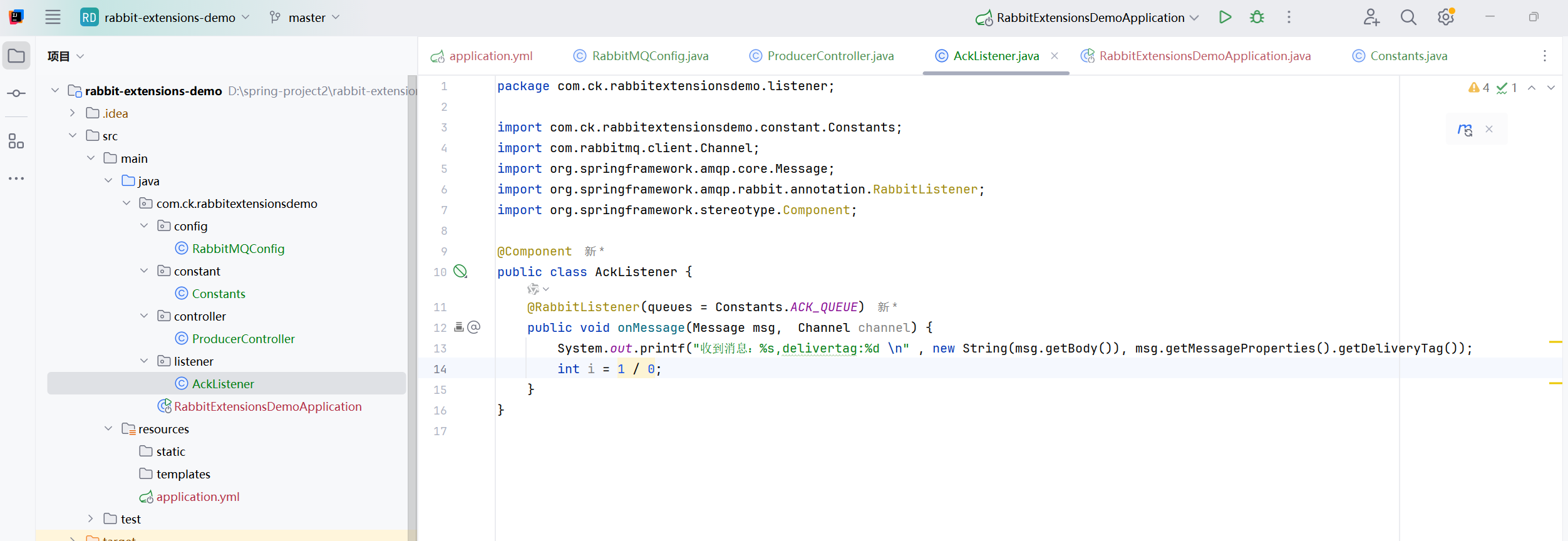
这个就是消费者出现异常的时候,队列就不会删除消息了
而且会不停的重试发送消息,就会一直不停的异常,这个消息就会一直存在队列里面
manual
手动确认就要自己确认了
自己调用方法来确认
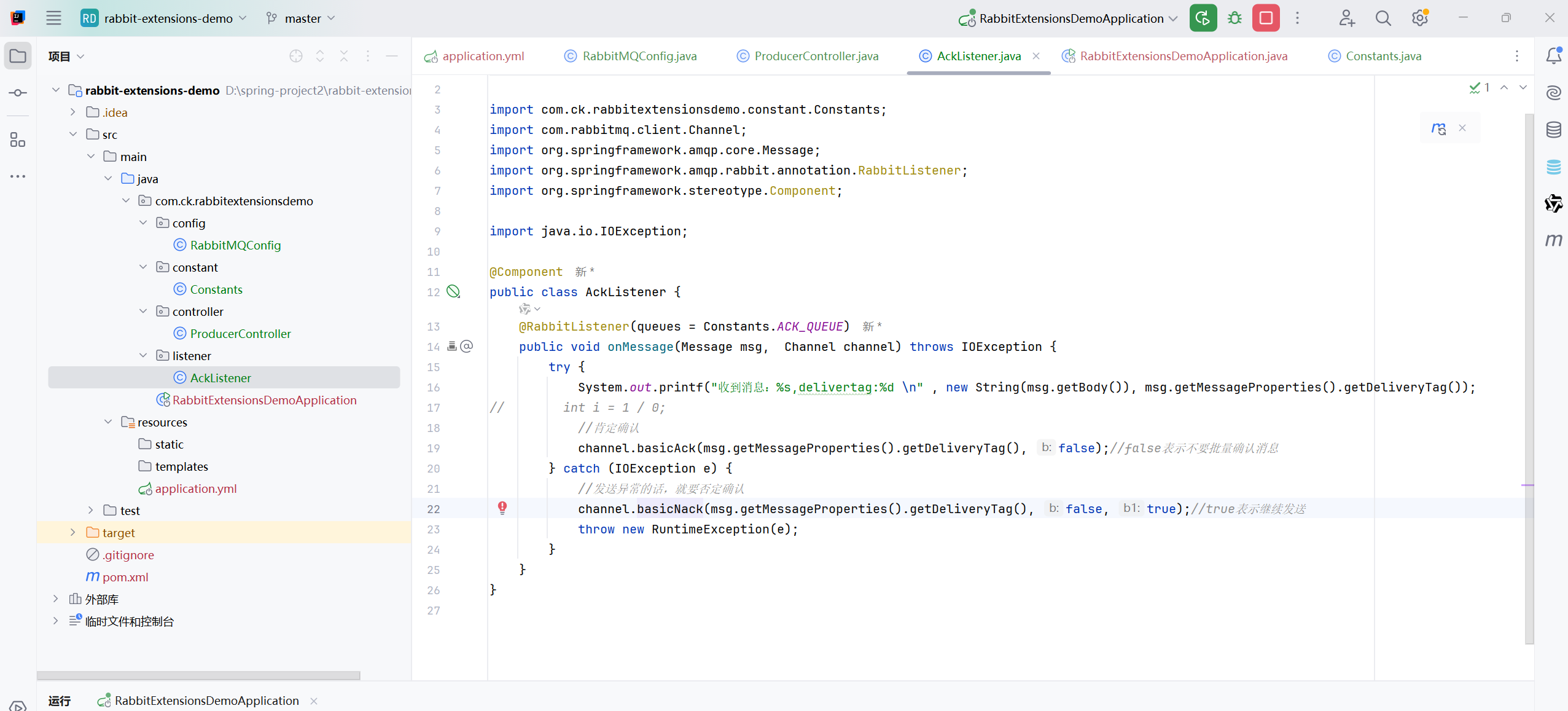
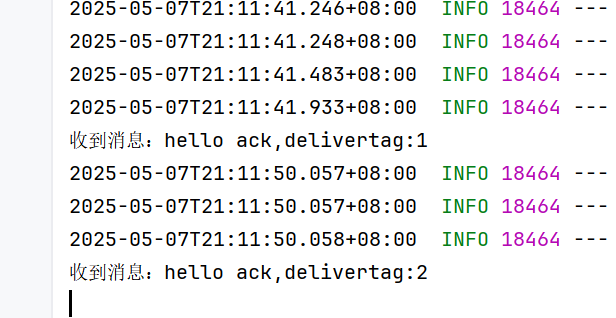
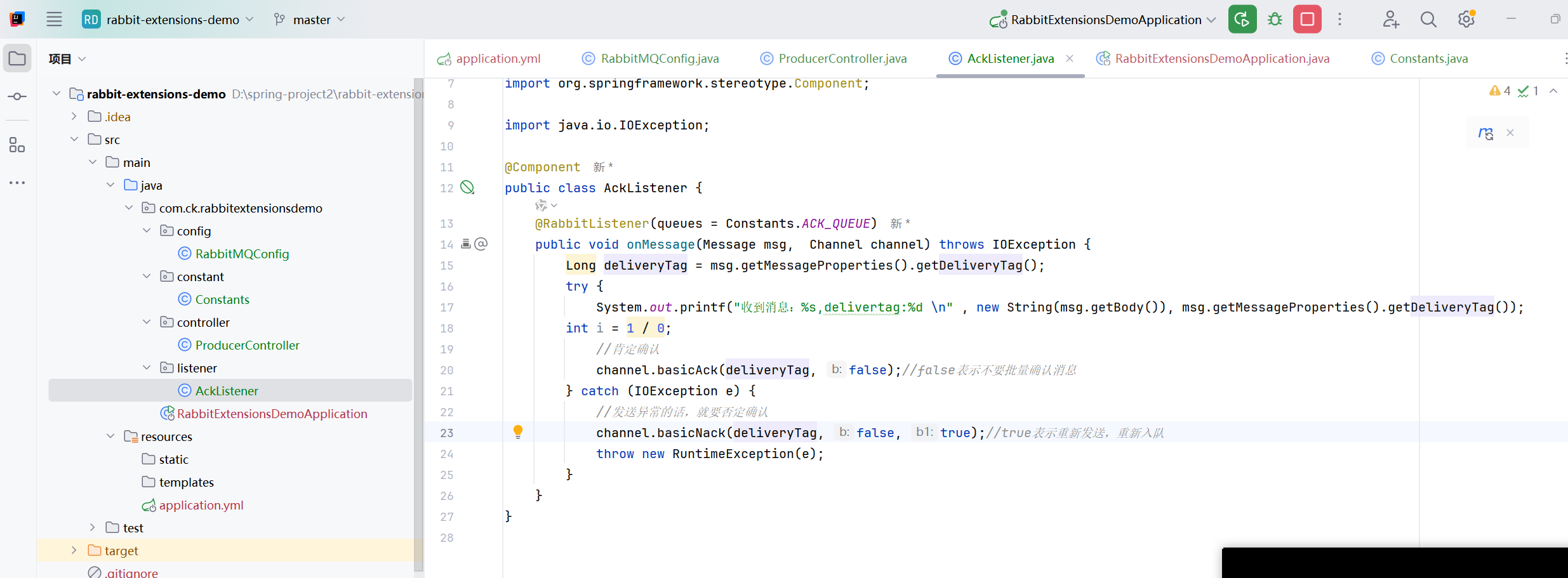

否定确认后,还把消息保存在队列中
这个就是否定确认,但是消息就不要放在队列里面了
注意我们捕捉的应该是excetion,不是ioexcetion,因为basicAck才是ioexcetion,除法的异常不是ioexcetion,如果写的是ioexcetion,那么就不会进入这个捕获了
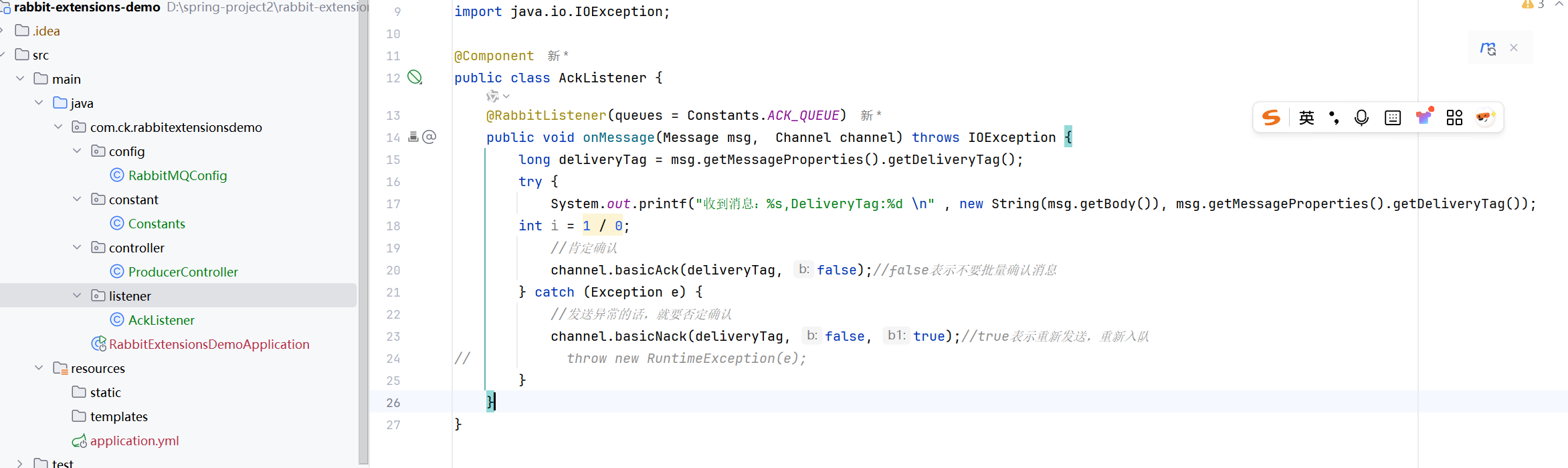
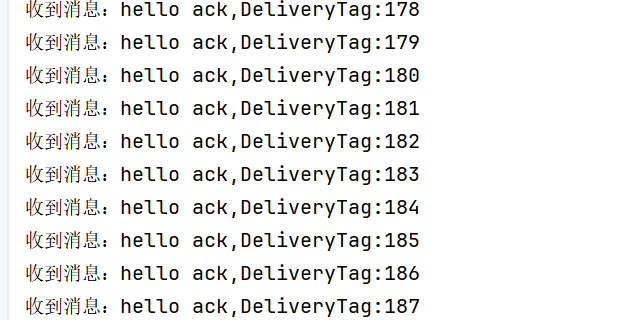
如果Nack的第三个参数是true的话,那么就会一直否定确认,然后消息还一直保留在队列中,一直发送,就会一直打印了

一直是uack的状态,这个是没有确认的状态,包括没有否定,没有肯定,停止程序之后就是ready状态,这个状态包括,肯定确认和否定确认
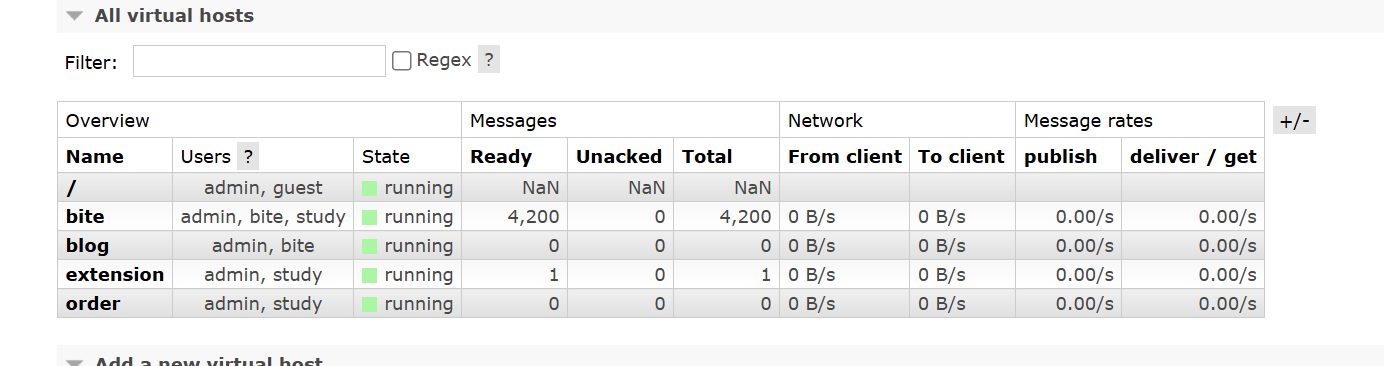
如果参数是false的话,否定确认之后就不会保留在队列中了

持久化介绍
交换机持久化
就是断电了,还一直保存着,保存在本地,如果不持久化的话,服务器重启,那么就全部没有了
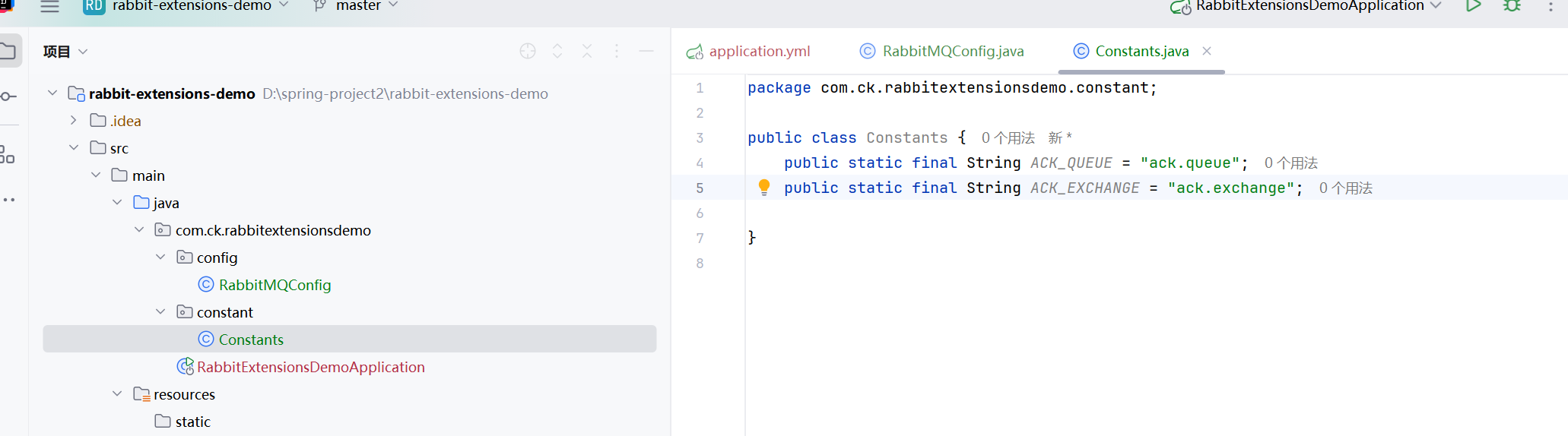
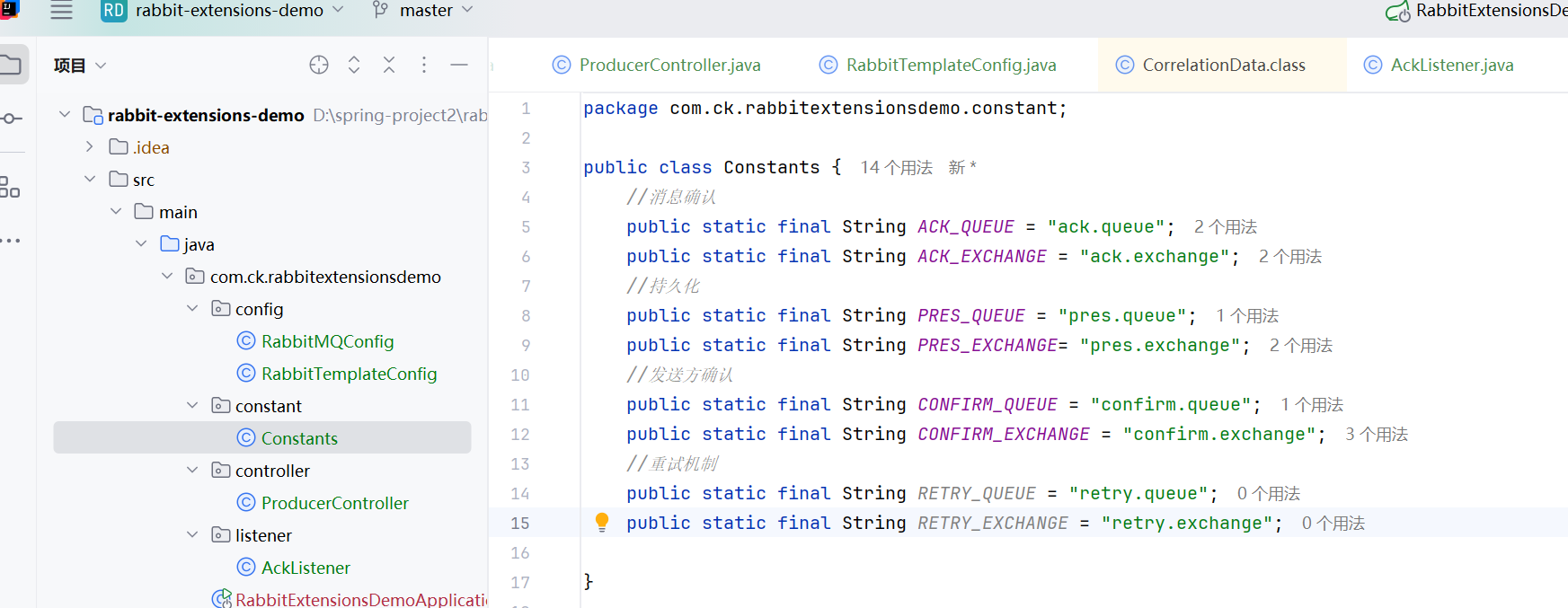
RabbitMQ的持久化分为三个部分:交换器的持久化、队列的持久化和消息的持久化
交换器的持久化是通过在声明交换机时是将durable参数置为true实现的.相当于将交换机的属性在服务器内部保存,当MQ的服务器发⽣意外或关闭之后,重启 RabbitMQ 时不需要重新去建⽴交换机, 交换机会⾃动建⽴,相当于⼀直存在.如果交换器不设置持久化, 那么在 RabbitMQ 服务重启之后, 相关的交换机元数据会丢失, 对⼀个⻓期使⽤的交换器来说,建议将其置为持久化的
bash
ExchangeBuilder.topicExchange(Constant.ACK_EXCHANGE_NAME).durable(true).build()
directExchange默认是持久化的

这样设置一下,就不是持久化的了
队列持久化
队列的持久化是通过在声明队列时将 durable 参数置为 true实现的.
如果队列不设置持久化, 那么在RabbitMQ服务重启之后,该队列就会被删掉, 此时数据也会丢失. (队列没有了, 消息也⽆处可存了)队列的持久化能保证该队列本⾝的元数据不会因异常情况⽽丢失, 但是并不能保证内部所存储的消息不会丢失. 要确保消息不会丢失, 需要将消息设置为持久化.
咱们前⾯⽤的创建队列的⽅式都是持久化的
如果队列不是持久化的,那么消息就不是持久化的
bash
QueueBuilder.durable(Constant.ACK_QUEUE).build();durable就是设置队列为持久化了
用nonDurable就是非持久化的了
消息持久化
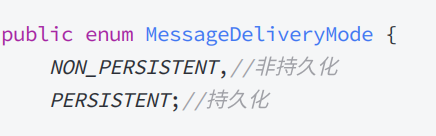
消息实现持久化, 需要把消息的投递模式( MessageProperties 中的 deliveryMode )设置为2,
也就是 MessageDeliveryMode.PERSISTENT
设置了队列和消息的持久化, 当 RabbitMQ 服务重启之后, 消息依旧存在. 如果只设置队列持久化, 重
启之后消息会丢失. 如果只设置消息的持久化, 重启之后队列消失, 继⽽消息也丢失. 所以单单设置消息持久化⽽不设置队列的持久化显得毫⽆意义
bash
//⾮持久化信息
channel.basicPublish("",QUEUE_NAME,null,msg.getBytes());
//持久化信息
channel.basicPublish("",QUEUE_NAME,
MessageProperties.PERSISTENT_TEXT_PLAIN,msg.getBytes());这个是sdk的方法,了解一下
如果使⽤RabbitTemplate 发送持久化消息
java
// 要发送的消息内容
String message = "This is a persistent message";
// 创建⼀个Message对象,设置为持久化
Message messageObject = new Message(message.getBytes(), new
MessageProperties());
messageObject.getMessageProperties().setDeliveryMode(MessageDeliveryMode.PERSIS
TENT);
// 使⽤RabbitTemplate发送消息
rabbitTemplate.convertAndSend(Constant.ACK_EXCHANGE_NAME, "ack",
messageObject);RabbitMQ默认情况下会将消息视为持久化的,除⾮队列被声明为⾮持久化,或者消息在发送时被标
记为⾮持久化
持久化代码
我们以前写的默认都是持久化的

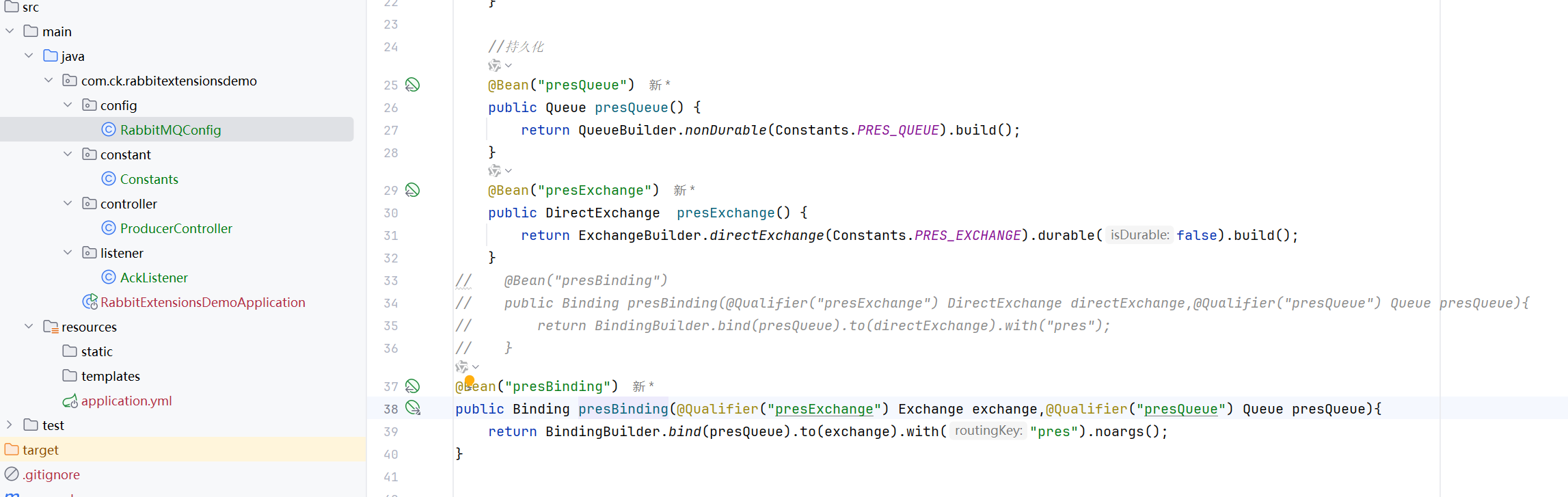
这样就写好了非持久化的队列和交换机
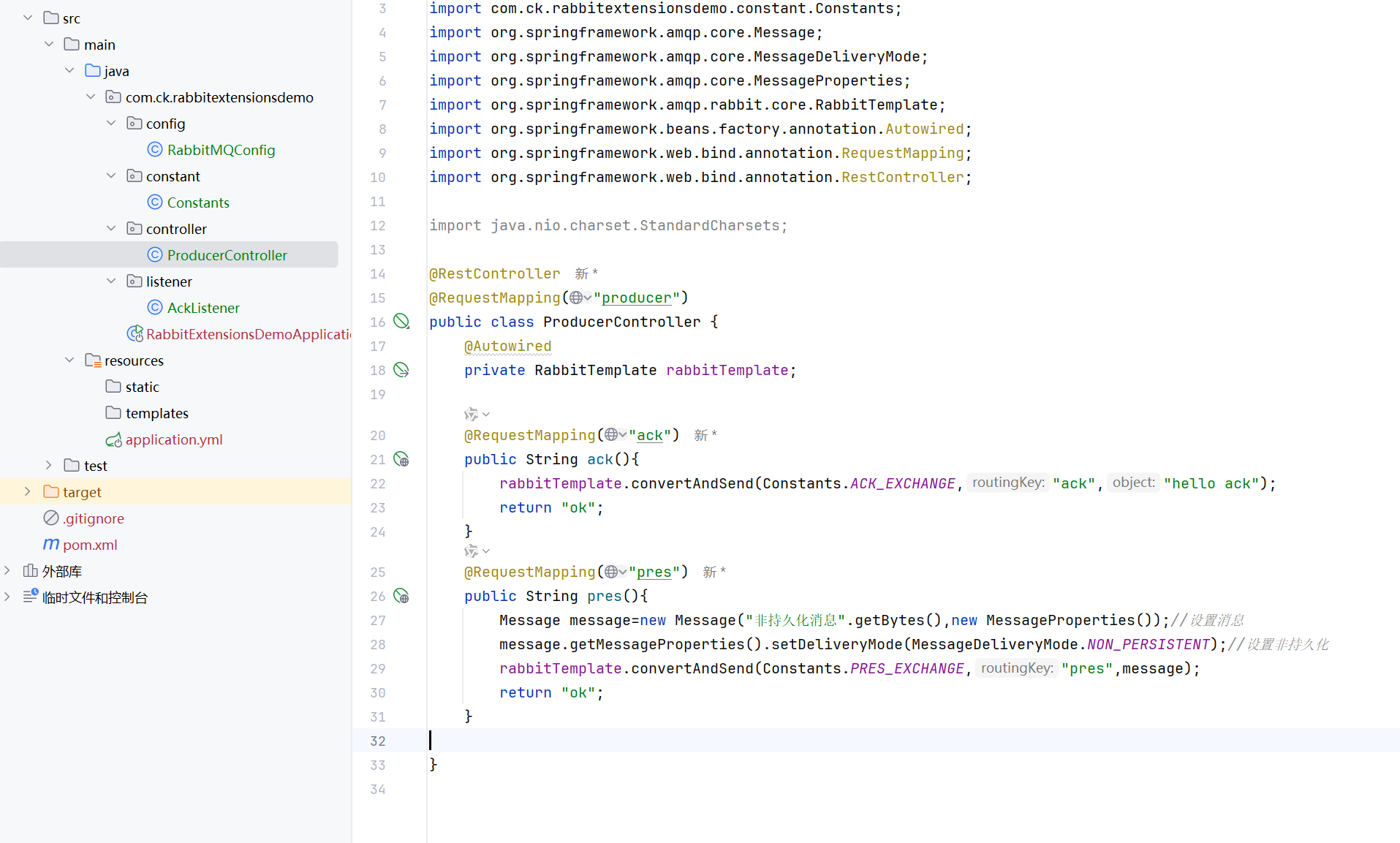
然后设置非持久化消息
持久化代码演示


发现没有D了,这样就是非持久化的了
然后重启rabbitmq的服务器的时候的话,那么它们就都消失了
重启rabbitmq,还要关掉我们的springboot服务
java
systemctl restart rabbitmq-server.service # 重启rabbitmq服务器但是重启之后,它们依然存在,为什么呢,因为springboot服务没有停掉的原因,没有停掉的话,会先断联,然后重连,重连之后就又会重新创建队列和交换机,但是消息已经没了
关闭springboot服务,然后重启rabbitmq,那么队列和交换机都消失了

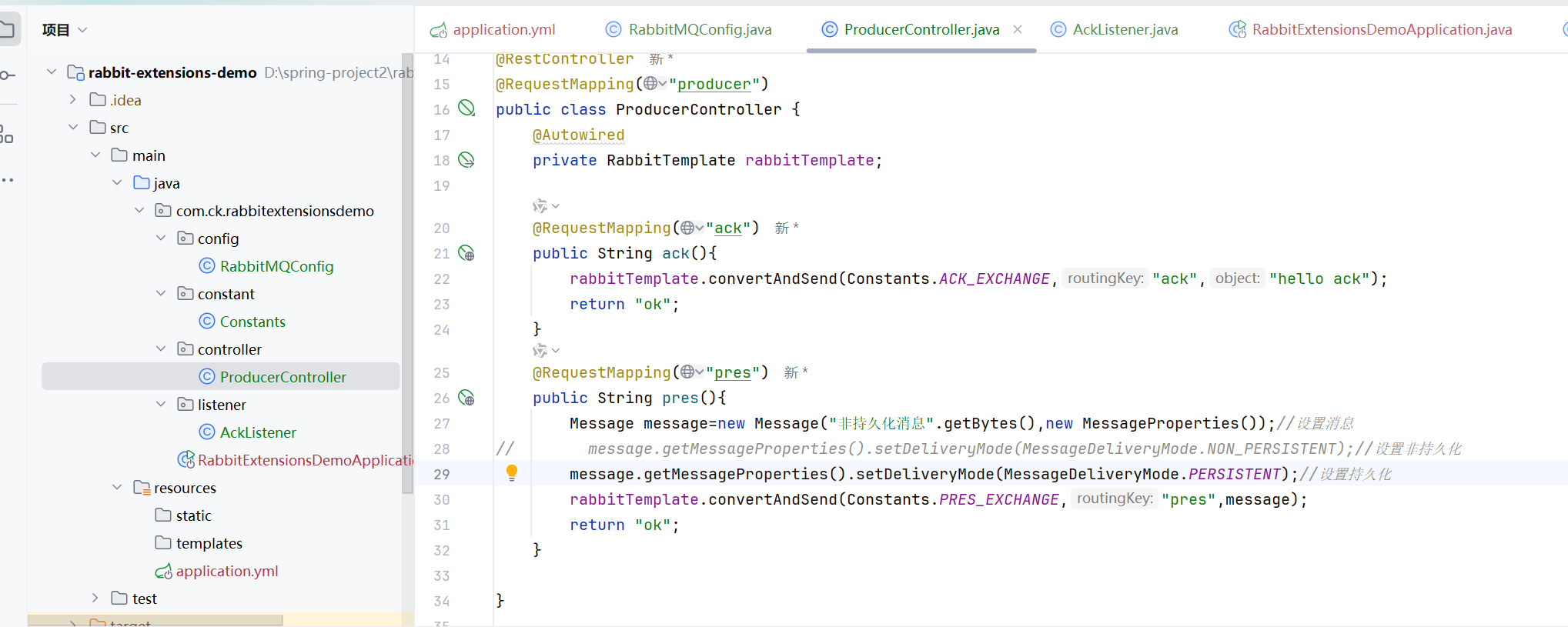
这样消息就是持久化的,或者什么都不设置,默认就是持久化的
如果一个队列已经是在rabbitmq服务器中持久化的了,那么就不能在springboot代码中随便让它非持久化了,不能随便修改属性

将交换器、队列、消息都设置了持久化之后就能百分之百保证数据不丢失了吗? 答案是否定的.
- 从消费者来说, 如果在订阅消费队列时将autoAck参数设置为true, 那么当消费者接收到相关消息之
后, 还没来得及处理就宕机了, 这样也算数据居丢失. 这种情况很好解决, 将autoAck参数设置为
false, 并进⾏⼿动确认,详细可以参考消息确认章节. - 在持久化的消息正确存⼊RabbitMQ之后,还需要有⼀段时间(虽然很短,但是不可忽视)才能存⼊磁盘中.RabbitMQ并不会为每条消息都进⾏同步存盘(调⽤内核的fsync⽅法)的处理, 可能仅仅保存到操
作系统缓存之中⽽不是物理磁盘之中. 如果在这段时间内RabbitMQ服务节点发⽣了宕机、重启等异
常情况, 消息保存还没来得及落盘, 那么这些消息将会丢失
这个问题怎么解决呢?
- 引⼊RabbitMQ的仲裁队列(后⾯再讲), 如果主节点(master)在此特殊时间内挂掉, 可以⾃动切换到从节点(slave),这样有效地保证了⾼可⽤性, 除⾮整个集群都挂掉(此⽅法也不能保证100%可靠, 但是配置了仲裁队列要⽐没有配置仲裁队列的可靠性要⾼很多, 实际⽣产环境中的关键业务队列⼀般都会
设置仲裁队列). - 还可以在发送端引⼊事务机制或者发送⽅确认机制来保证消息已经正确地发送并存储⾄RabbitMQ
中, 详细参考--"发送⽅确认"
发送方确认介绍
在使⽤ RabbitMQ的时候, 可以通过消息持久化来解决因为服务器的异常崩溃⽽导致的消息丢失, 但是还有⼀个问题, 当消息的⽣产者将消息发送出去之后, 消息到底有没有正确地到达服务器呢? 如果在消息到达服务器之前已经丢失(⽐如RabbitMQ重启, 那么RabbitMQ重启期间⽣产者消息投递失败), 持久化操作也解决不了这个问题,因为消息根本没有到达服务器,何谈持久化?
RabbitMQ为我们提供了两种解决⽅案:
a. 通过事务机制实现(用的少)
b. 通过发送⽅确认(publisher confirm) 机制实现
事务机制⽐较消耗性能, 在实际⼯作中使⽤也不多, 咱们主要介绍confirm机制来实现发送⽅的确认.
RabbitMQ为我们提供了两个⽅式来控制消息的可靠性投递
- confirm确认模式
- return退回模式
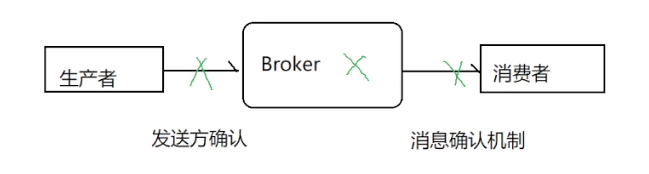
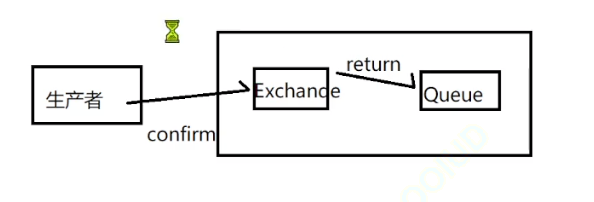
发送消息总共有三个地方有可能有问题,就是上面的三个叉叉
confirm确认模式
Producer 在发送消息的时候, 对发送端设置⼀个ConfirmCallback的监听, ⽆论消息是否到达
Exchange , 这个监听都会被执⾏, 如果Exchange成功收到, ACK( Acknowledge character , 确认
字符)为true, 如果没收到消息, ACK就为false
return退回模式
消息到达Exchange之后, 会根据路由规则匹配, 把消息放⼊Queue中. Exchange到Queue的过程, 如果⼀条消息⽆法被任何队列消费(即没有队列与消息的路由键匹配或队列不存在等), 可以选择把消息退回给发送者. 消息退回给发送者时, 我们可以设置⼀个返回回调⽅法, 对消息进⾏处理
confirm模式代码
要使用这个模式,直接配置就可以了
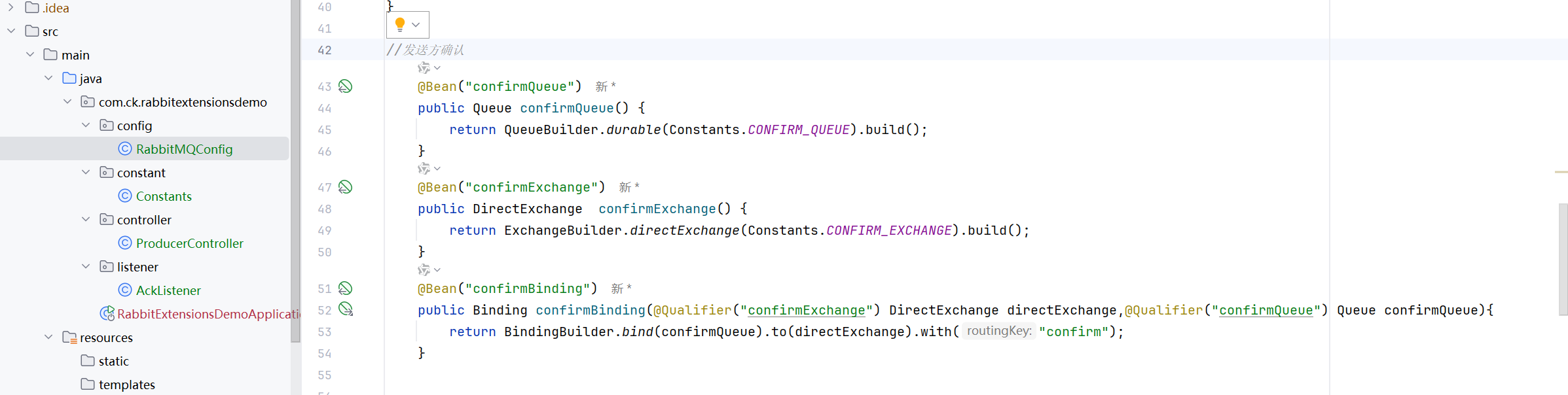
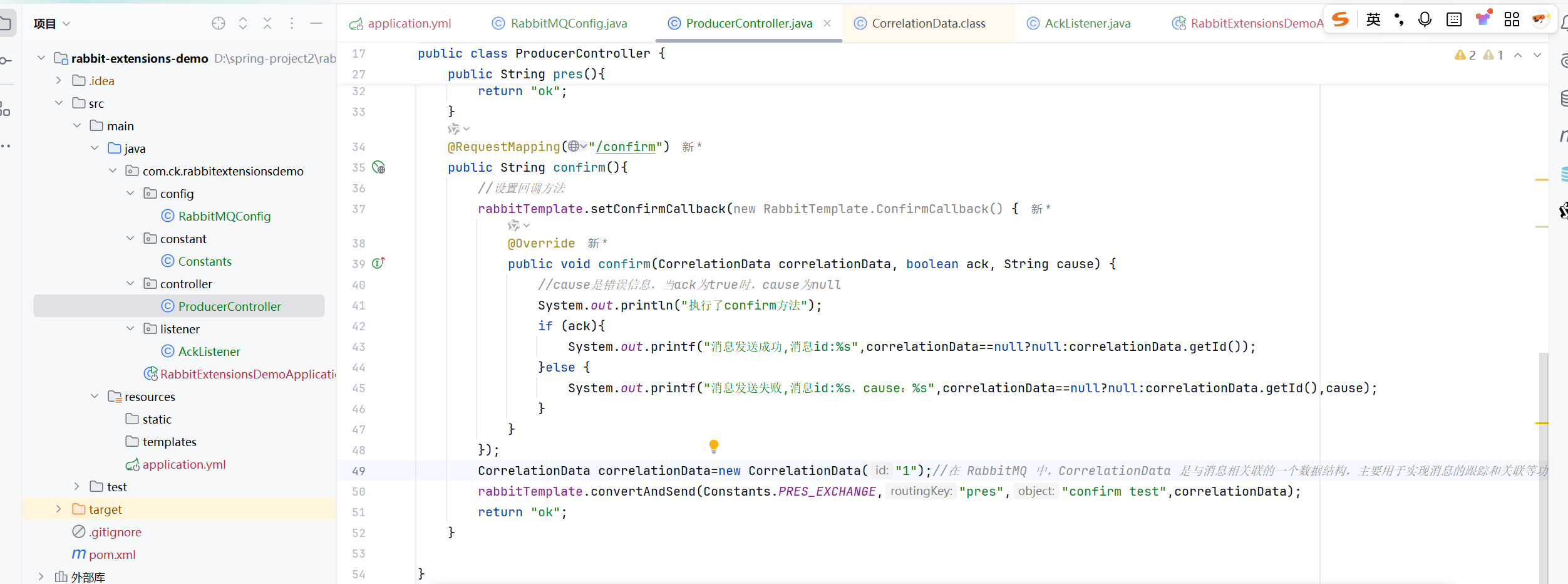
confirm模式演示
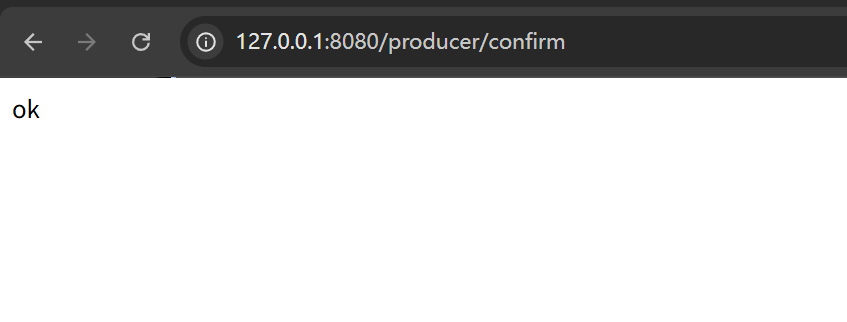
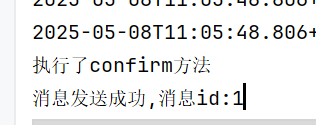
现在我们来演示一下,接收失败的情况
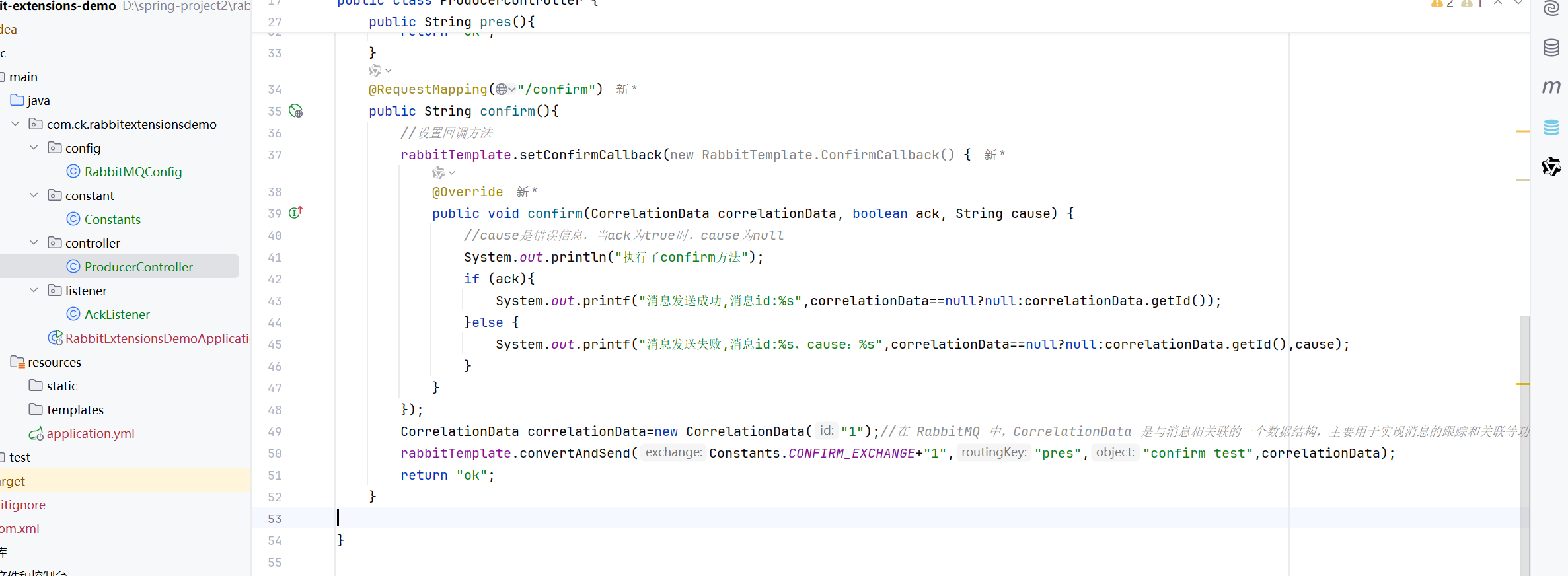
改一下交换机的名字就可以了,改为不存在的交换机

但是我们再试一次
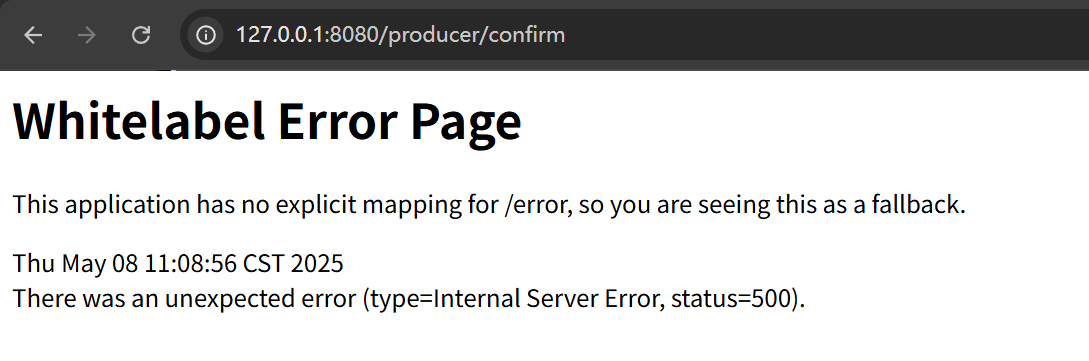

为什么呢
因为rabbitTemplate这个对象在我们的springboot项目中是一个单例的对象,只能set一次setConfirmCallback,set一次setConfirmCallback,rabbitTemplate就会监听所有的生产者的请求了

比如我们调用pres的请求,就是这样
我们在confrim里面设置了setConfirmCallback,那么就会影响整个项目的rabbitTemplate,整个项目的rabbitTemplate都有这个setConfirmCallback了,而且只能set一次
我们可以给confrim的controller单独设置一个rabbitTemplate
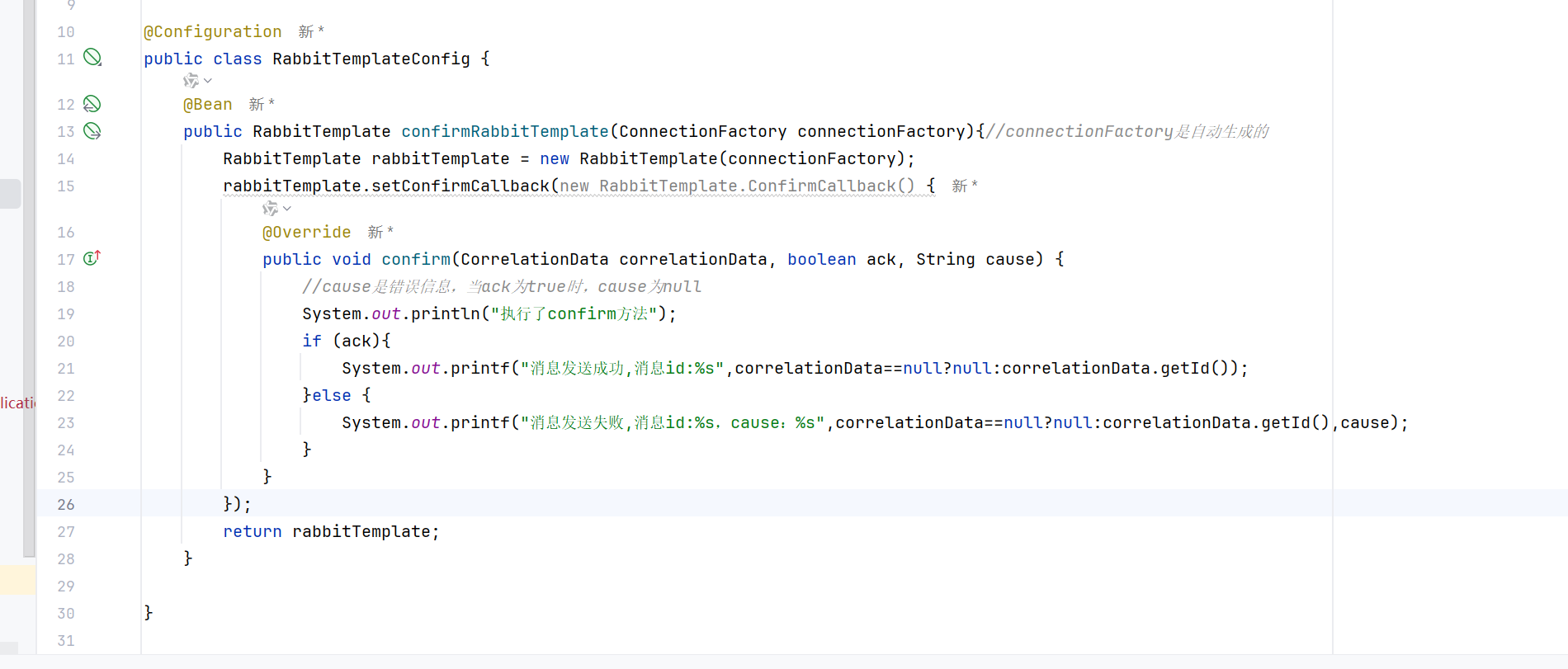
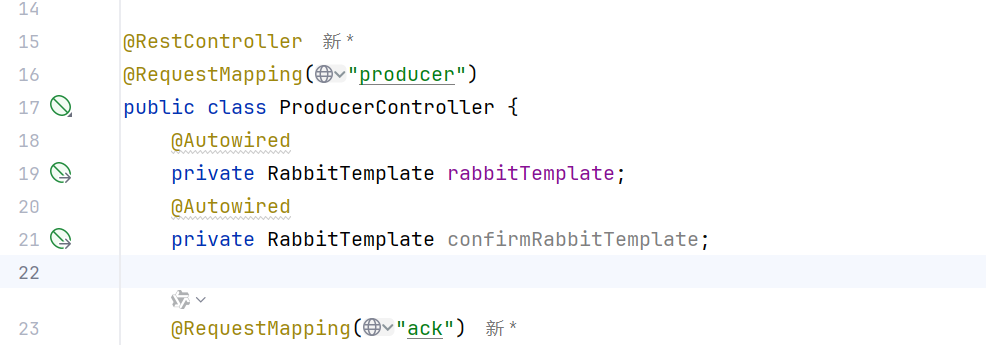

这样的话,重复调用confirm方法,就不会出错了
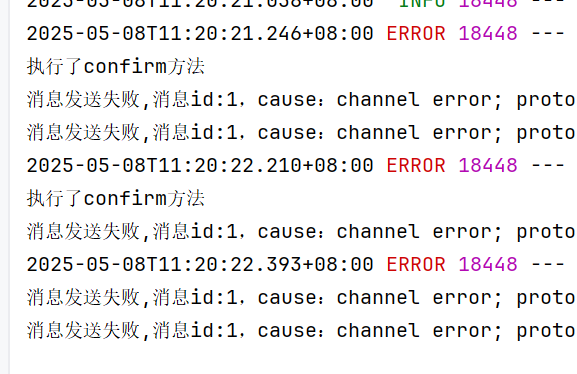
但是第一个问题,其他请求也会有setConfirmCallback
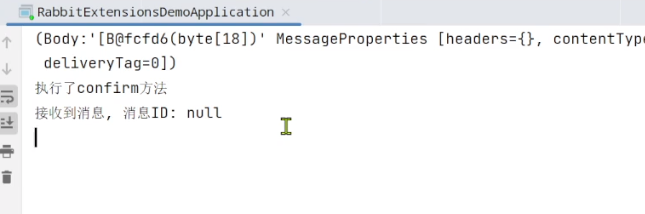
为什么会这样呢,明明用的不是同一个rabbitTemplate,为什么正常的rabbitTemplate也会setConfirmCallback呢
@Autowired
private RabbitTemplate rabbitTemplate;
@Autowired
private RabbitTemplate confirmRabbitTemplate;原因就是我们自己创建了一个RabbitTemplate ,那么springboot就不会帮我们自动创建一个RabbitTemplate ,所以我们始终用的都是一个RabbitTemplate ,而setConfirmCallback就在构造方法里面使用了一次,所以不会报错,所以就所有的都用的是一个RabbitTemplate
所以要使用两个的话,就要自己创建两个RabbitTemplate 了
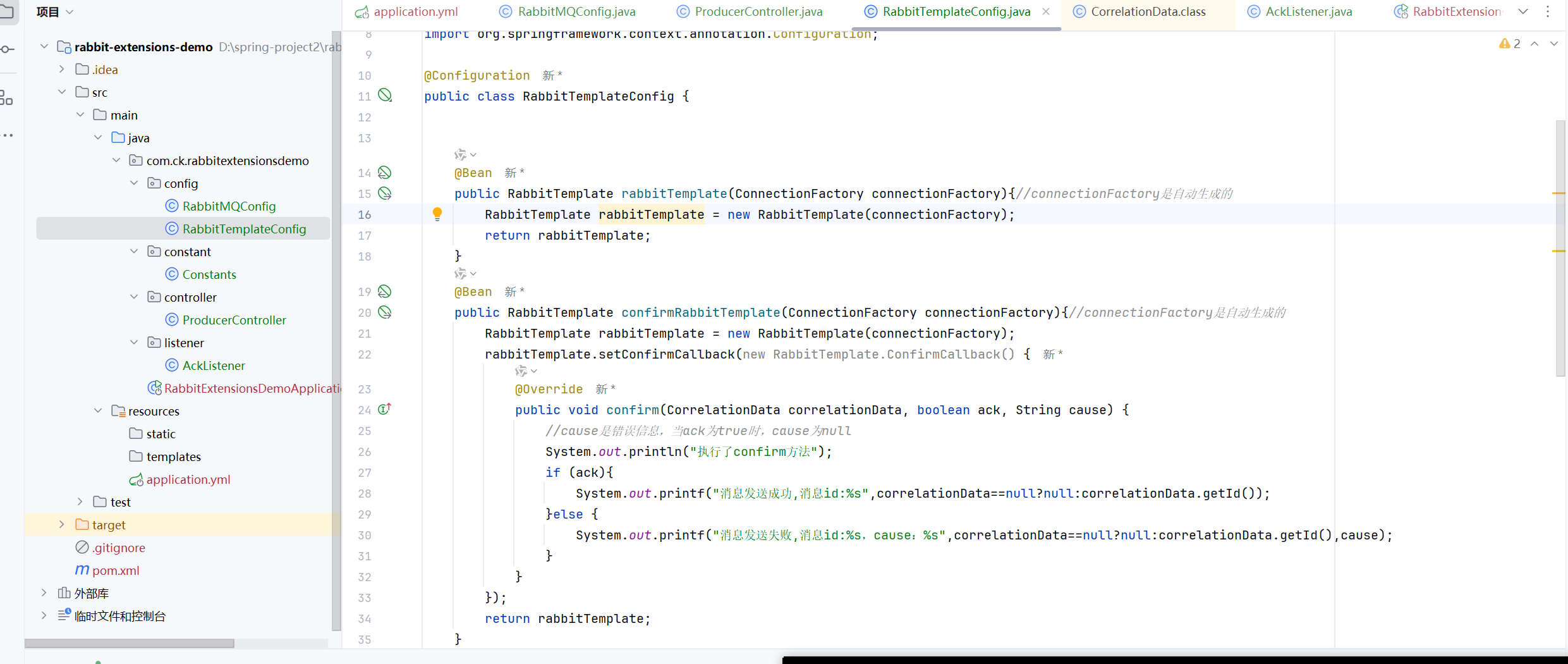
这样就有两个我们创建的RabbitTemplate 了,一个正常的,一个setConfirmCallback了
然后我们用resource来根据名称来注入就可以了
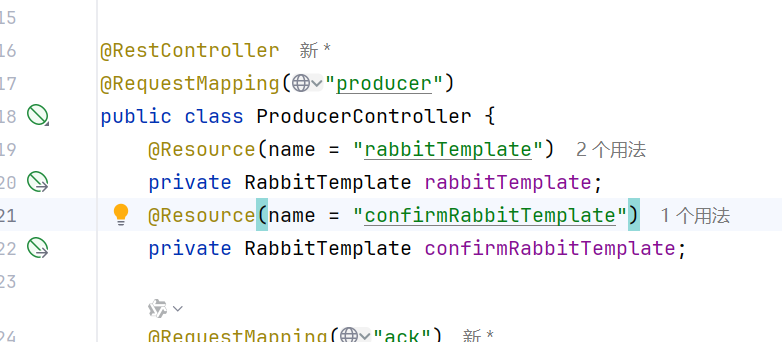
这样使用的就不是同一个对象了
注意我们上面的routingkey都写错了,但是仍然打印成功了,为什么呢,这个是因为这个setConfirmCallback针对的是,消息是否到达了交换机,和队列没什么关系
这个路由失败了该怎么保证呢?
return退出模式介绍
使⽤RabbitTemplate的setMandatory⽅法设置消息的mandatory属性为true(默认为false). 这个属性
的作⽤是告诉RabbitMQ, 如果⼀条消息⽆法被任何队列消费, RabbitMQ应该将消息返回给发送者, 此
时 ReturnCallback 就会被触发
java
rabbitTemplate.setMandatory(true);
rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {
@Override
public void returnedMessage(ReturnedMessage returned) {
System.out.printf("消息被退回: %s", returned);
}
});回调函数中有⼀个参数: ReturnedMessage, 包含以下属性
java
public class ReturnedMessage {
//返回的消息对象,包含了消息体和消息属性
private final Message message;
//由Broker提供的回复码, 表⽰消息⽆法路由的原因. 通常是⼀个数字代码,每个数字代表不同
的含义.
private final int replyCode;
//⼀个⽂本字符串, 提供了⽆法路由消息的额外信息或错误描述.
private final String replyText;
//消息被发送到的交换机名称
private final String exchange;
//消息的路由键,即发送消息时指定的键
private final String routingKey;
}模式演示
先配置,就和confirm是一样的配置
我们还是把回调函数写在confirmRabbitTemplate的构造函数里面
如果没有设置 rabbitTemplate.setMandatory(true);,那么写的回调函数在失败的情况下是无法执行的
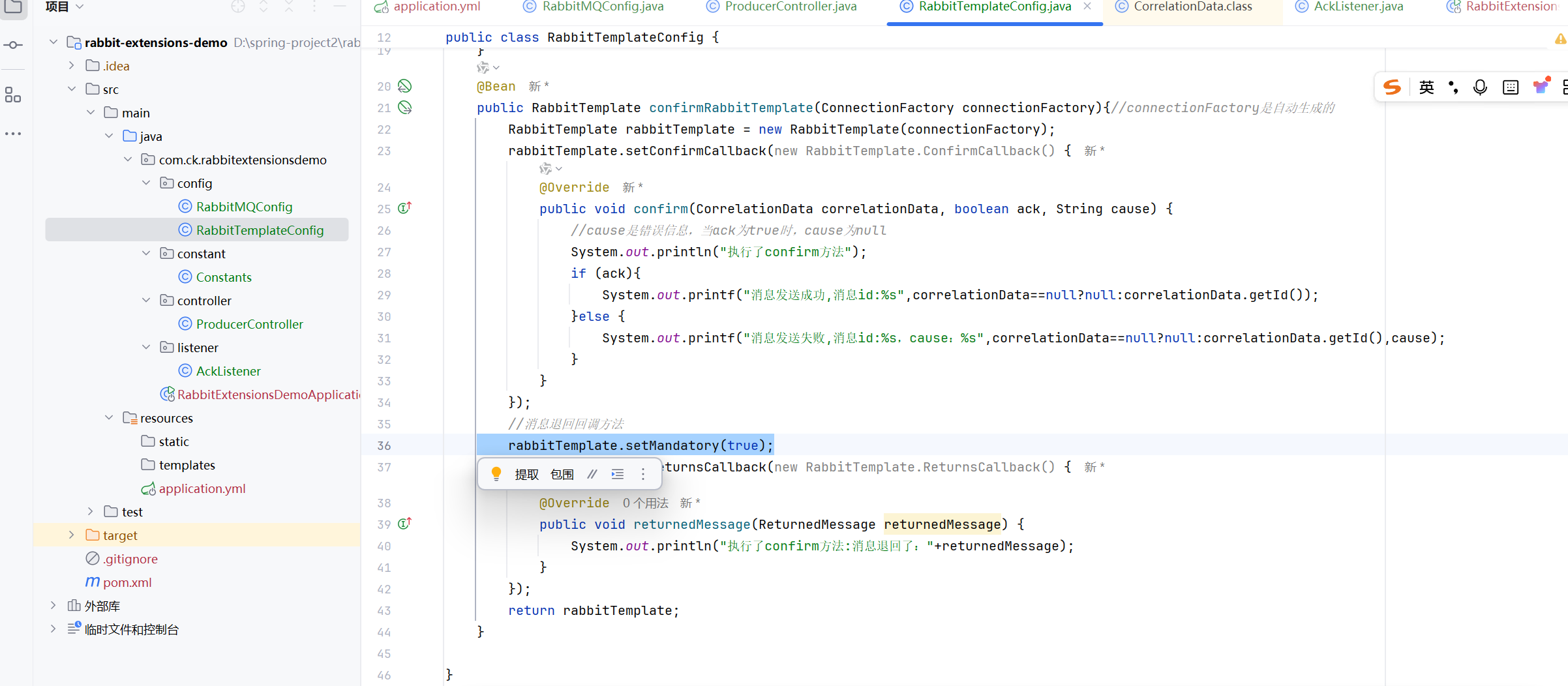


return模式和confirm模式互不干扰的,没有影响
常见面试题
如何保证RabbitMQ消息的可靠传输?
从这个图中, 可以看出, 消息可能丢失的场景以及解决⽅案:
- ⽣产者将消息发送到 RabbitMQ失败
a. 可能原因: ⽹络问题等
b. 解决办法: 参考本章节发送⽅确认-confirm确认模式 - 消息在交换机中⽆法路由到指定队列:
a. 可能原因: 代码或者配置层⾯错误, 导致消息路由失败
b. 解决办法: 参考本章节发送⽅确认-return模式 - 消息队列⾃⾝数据丢失
a. 可能原因: 消息到达RabbitMQ之后, RabbitMQ Server 宕机导致消息丢失.
b. 解决办法: 参考本章节持久性. 开启 RabbitMQ持久化, 就是消息写⼊之后会持久化到磁盘, 如果
RabbitMQ 挂了, 恢复之后会⾃动读取之前存储的数据. (极端情况下, RabbitMQ还未持久化就挂
了, 可能导致少量数据丢失, 这个概率极低, 也可以通过集群的⽅式提⾼可靠性) - 消费者异常, 导致消息丢失
a. 可能原因: 消息到达消费者, 还没来得及消费, 消费者宕机. 消费者逻辑有问题.
b. 解决办法: 参考本章节消息确认. RabbitMQ 提供了 消费者应答机制 来使 RabbitMQ 能够感知
到消费者是否消费成功消息. 默认情况下消费者应答机制是⾃动应答的, 可以开启⼿动确认, 当消
费者确认消费成功后才会删除消息, 从⽽避免消息丢失. 除此之外, 也可以配置重试机制(参考下
⼀章节), 当消息消费异常时, 通过消息重试确保消息的可靠性
重试机制介绍
在消息传递过程中, 可能会遇到各种问题, 如⽹络故障, 服务不可⽤, 资源不⾜等, 这些问题可能导致消息处理失败. 为了解决这些问题, RabbitMQ 提供了重试机制, 允许消息在处理失败后重新发送.
但如果是程序逻辑引起的错误, 那么多次重试也是没有⽤的, 可以设置重试次数

如果是代码问题重试多次也没有用,所以可以设置重试次数
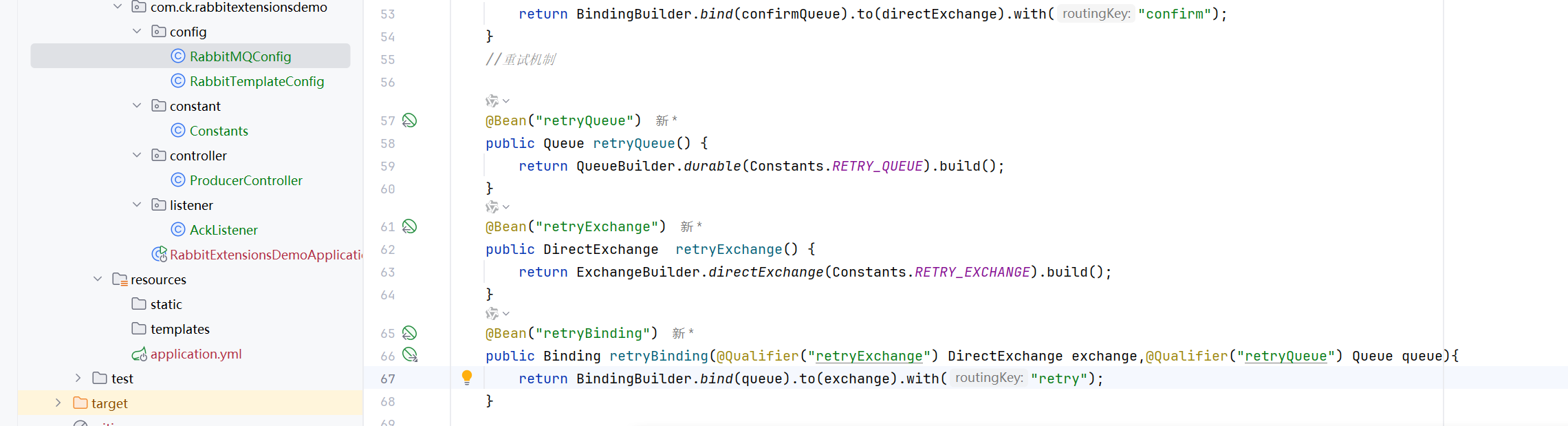
消费者抛出异常会自动进行重试
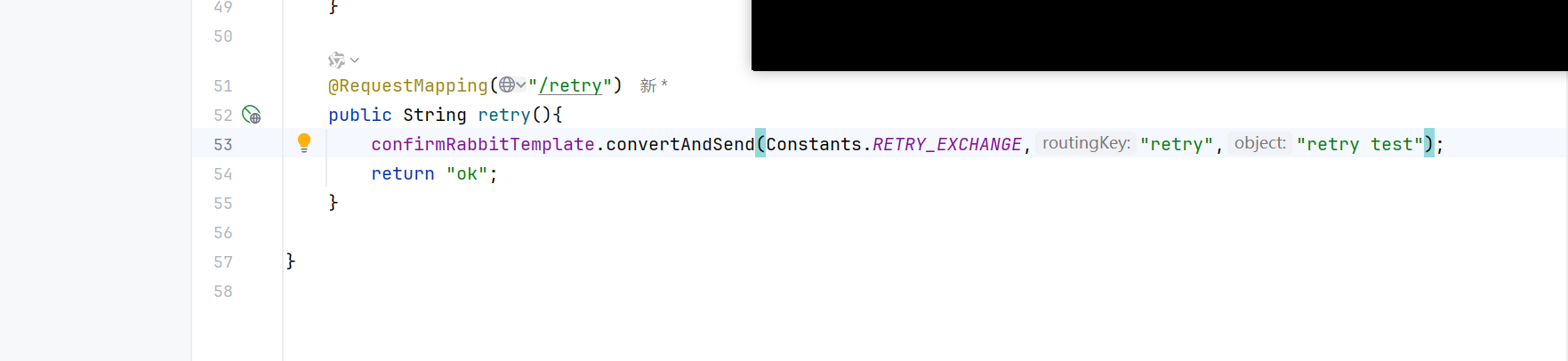
然后是消费者
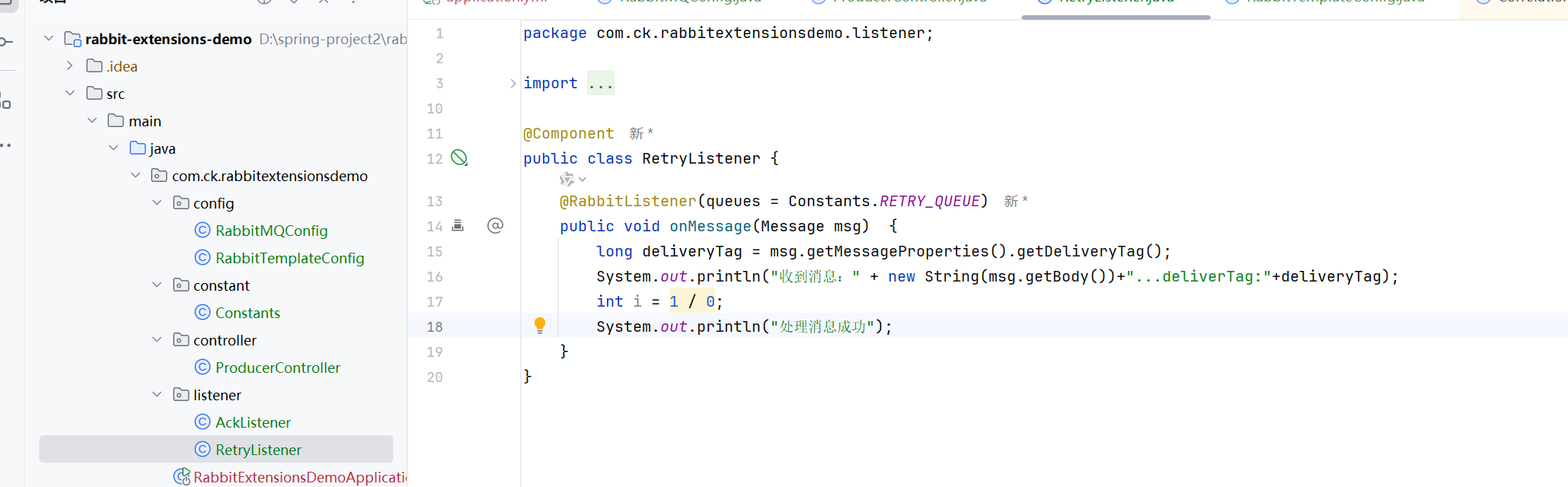
重试机制-自动确认


消息就会一直在这里了,一直重发,一直监听,一直报错
这样就是没有配置重试策略的弊端
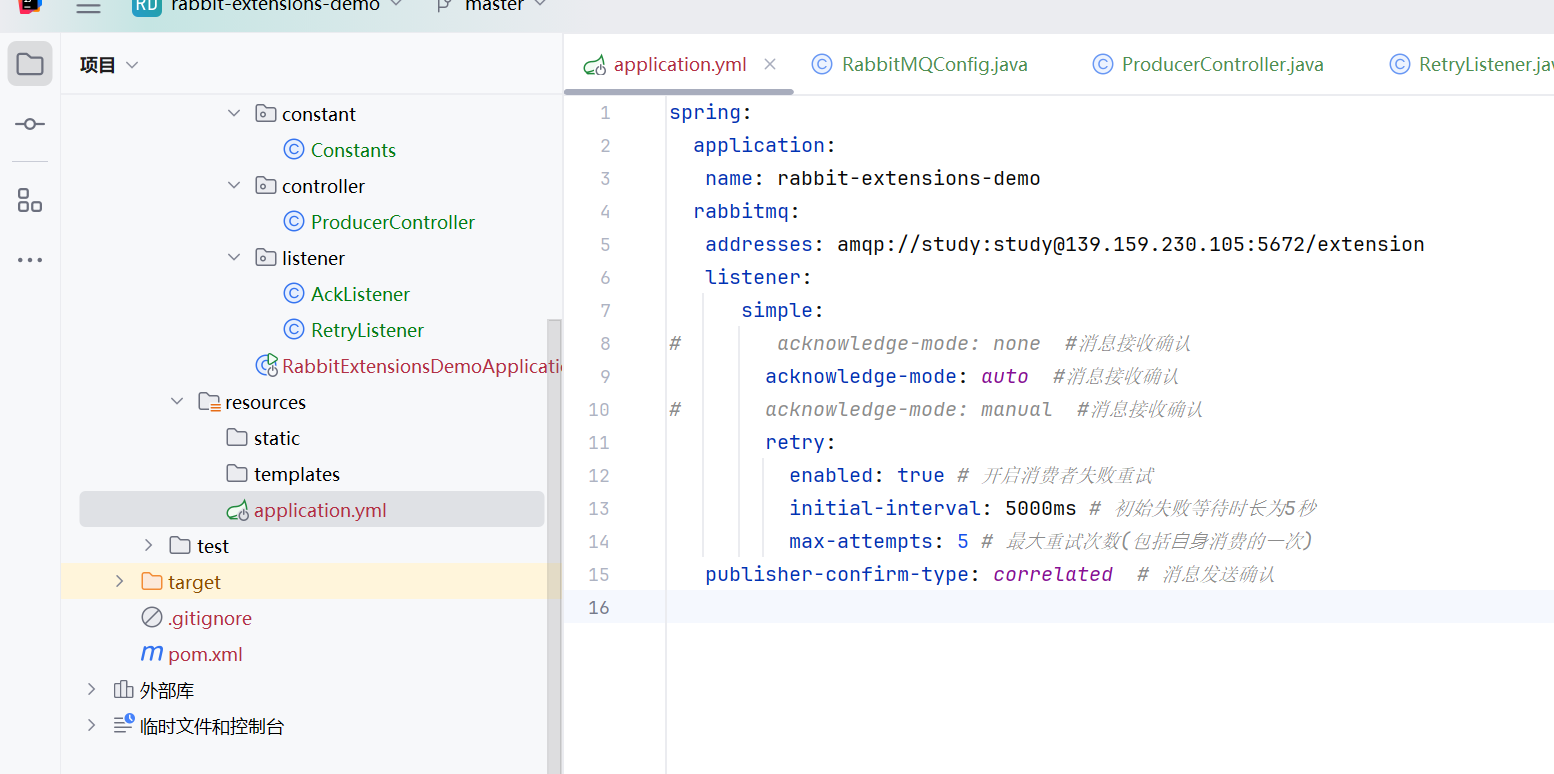
这样就会重试五次每次5秒了
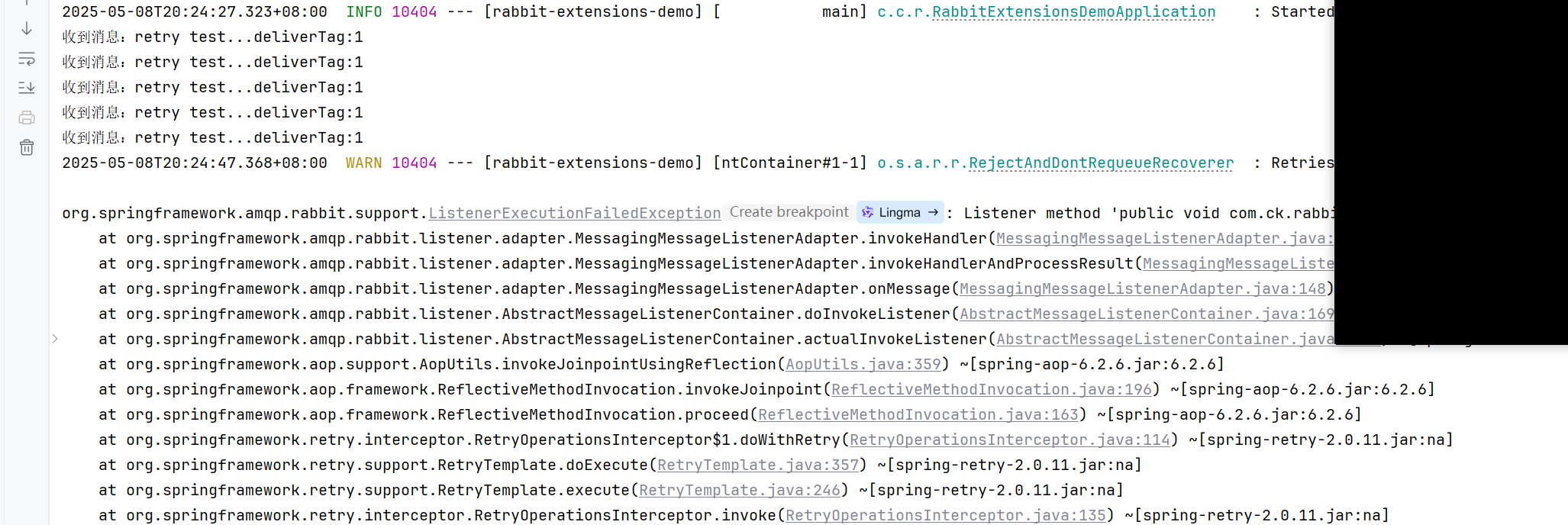
这样就重新发了五次,然后才报异常
重试机制-手动确认
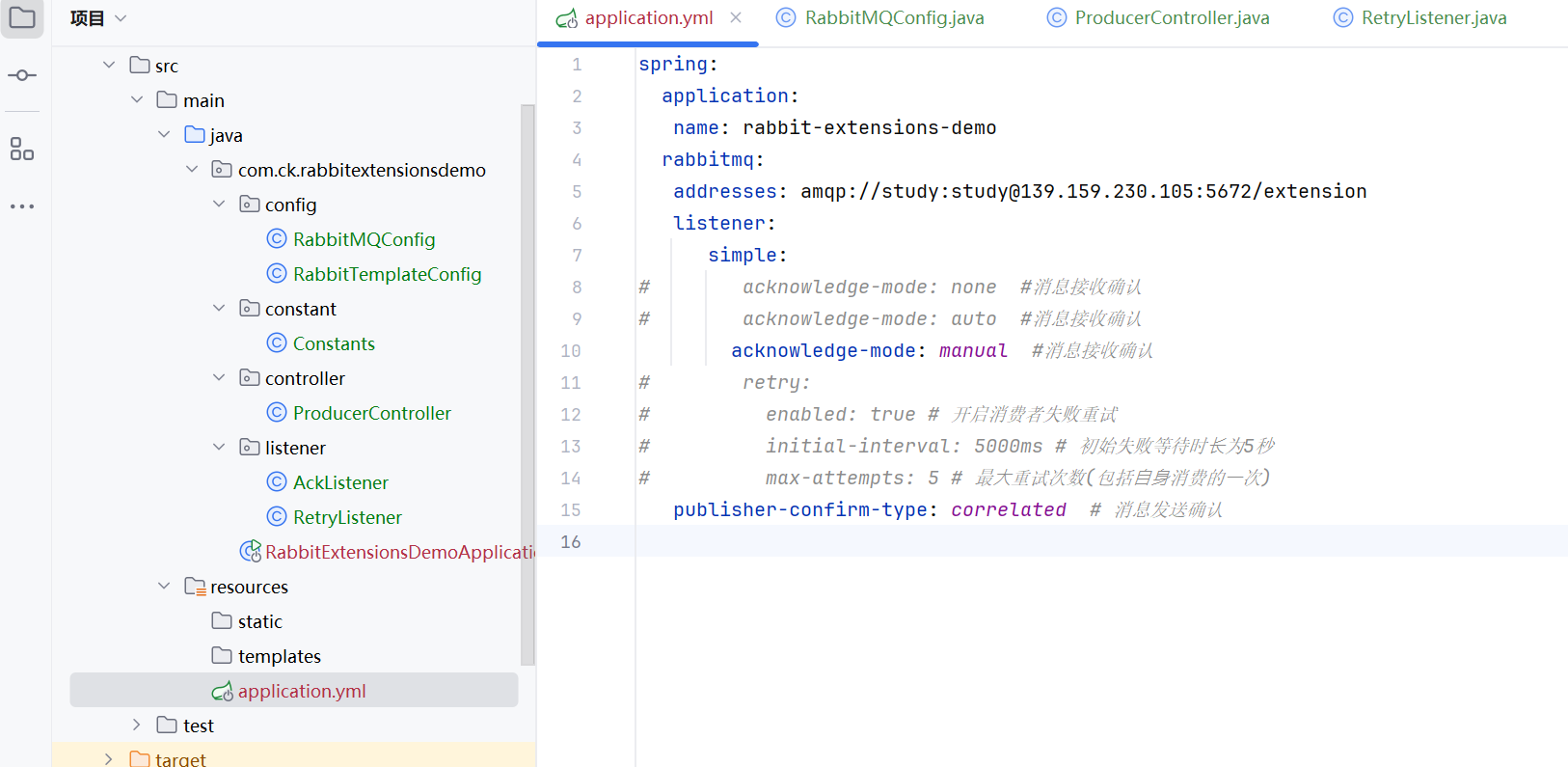
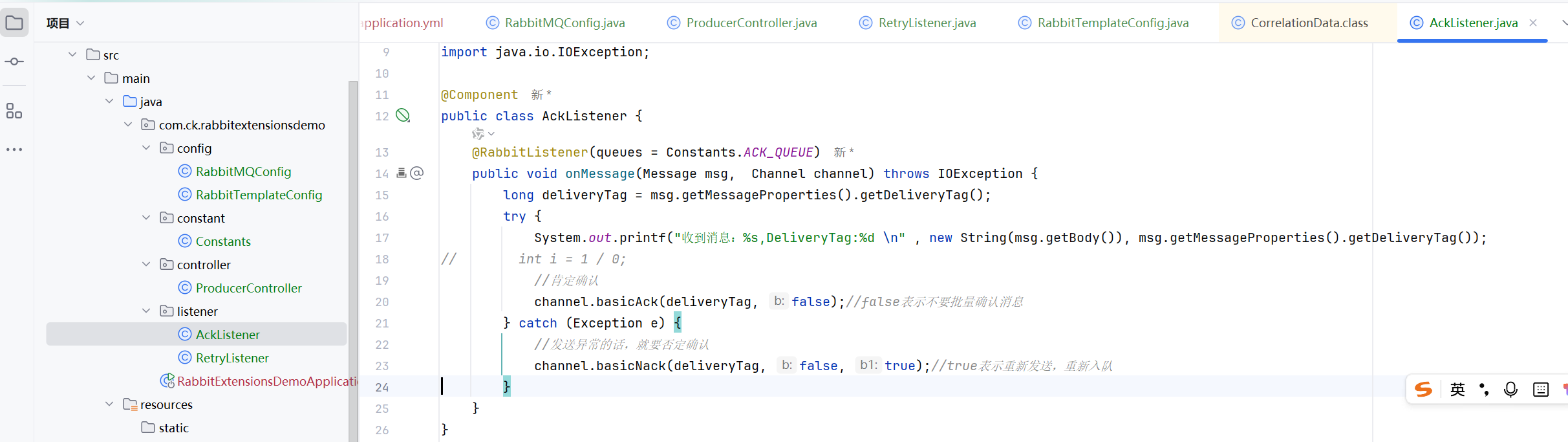
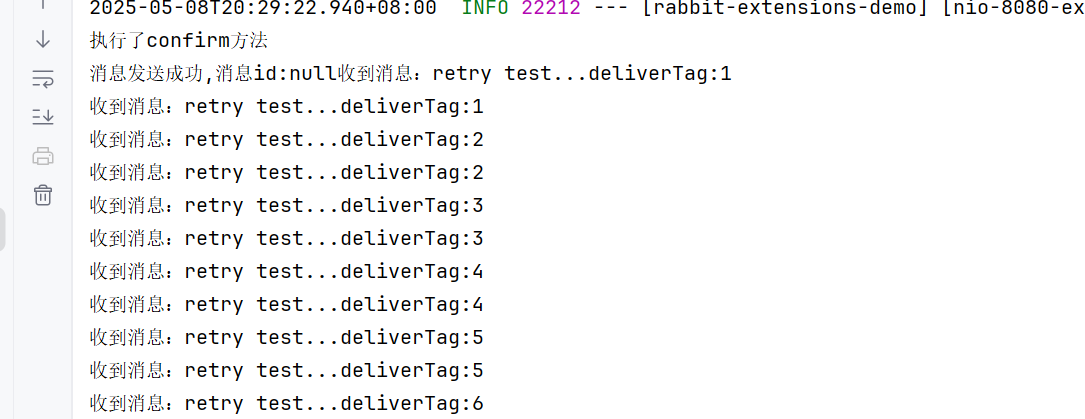
这样还是不断的递增的,而且消息一直存在队列中
auto的时候,dilivertag是不变的,因为没有重新入队
我们这个手动确认是重新入队了的,所以dilivertag会增加
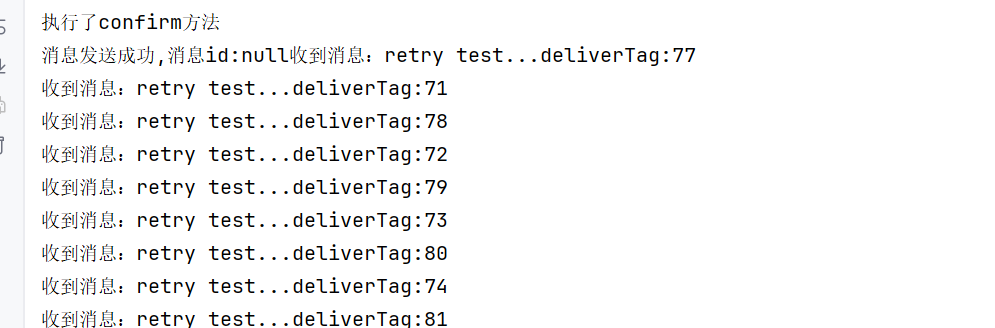
手动确认的话,重试策略是没有效果的
重试策略只有在自动确认的1机制下才是有效果的
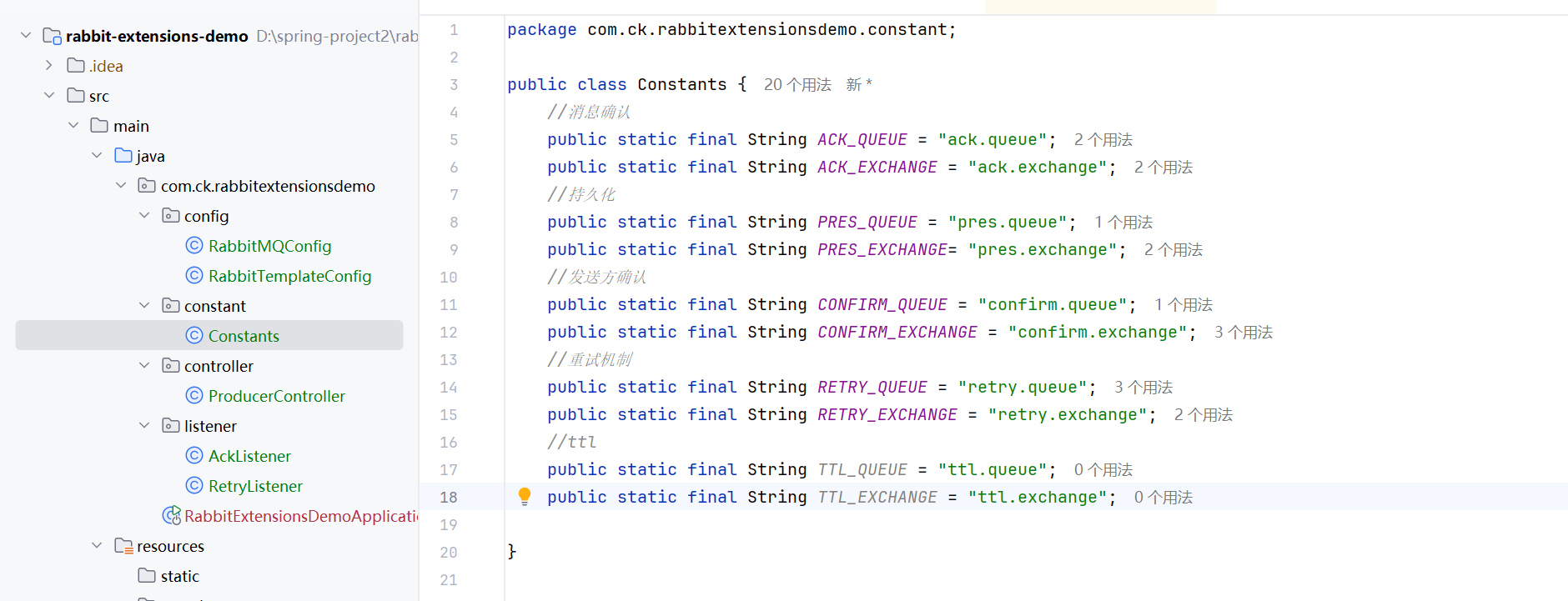
设置消息TTL
TTL(Time to Live, 过期时间), 即过期时间. RabbitMQ可以对消息和队列设置TTL.
当消息到达存活时间之后, 还没有被消费, 就会被⾃动清除

1.设置队列的ttl--》所有消息的ttl都是和队列一样的
2.设置消息的ttl

先创建队列和交换机
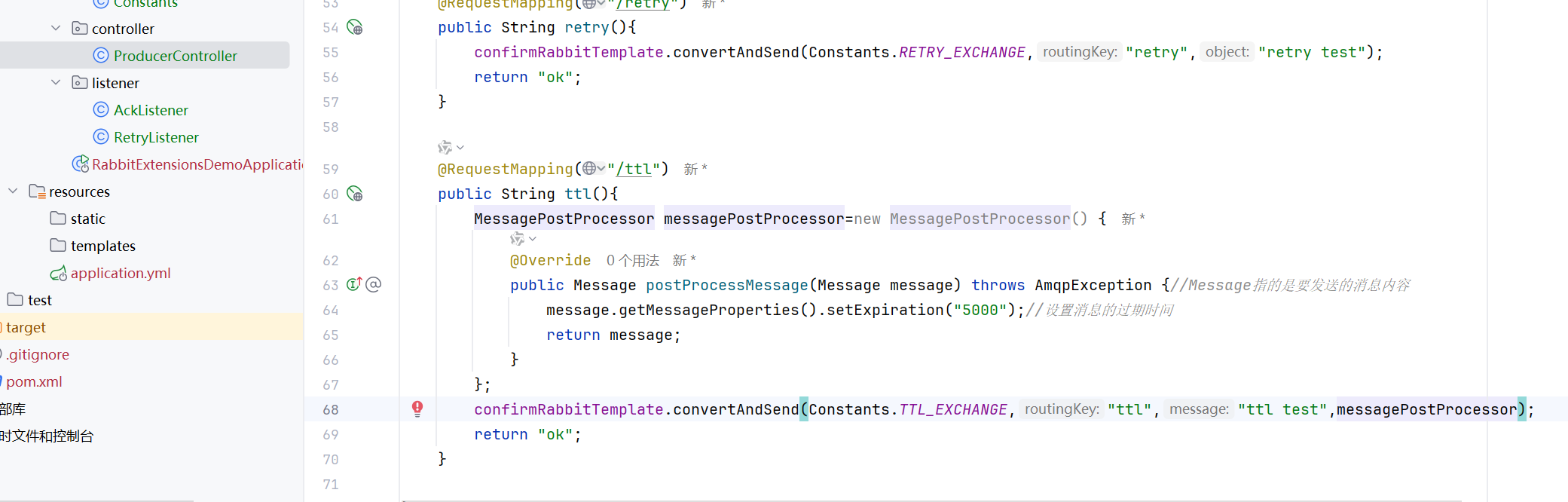
可以写成lambda表达式


发现过一会儿就消失了,这个ttl
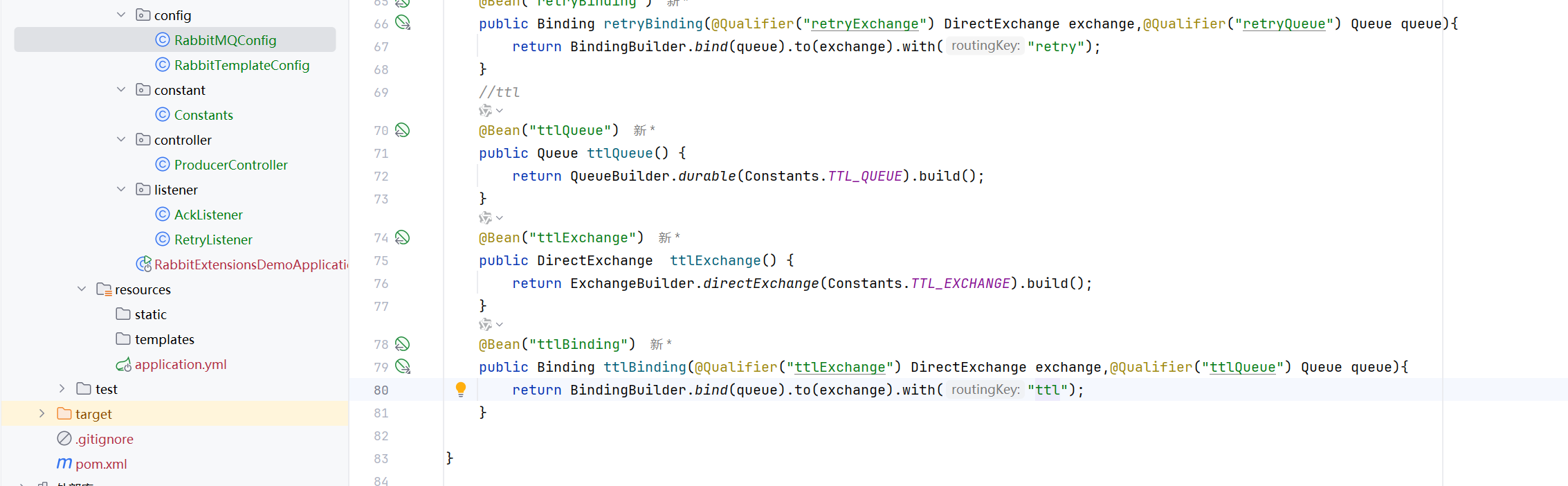
设置队列的ttl
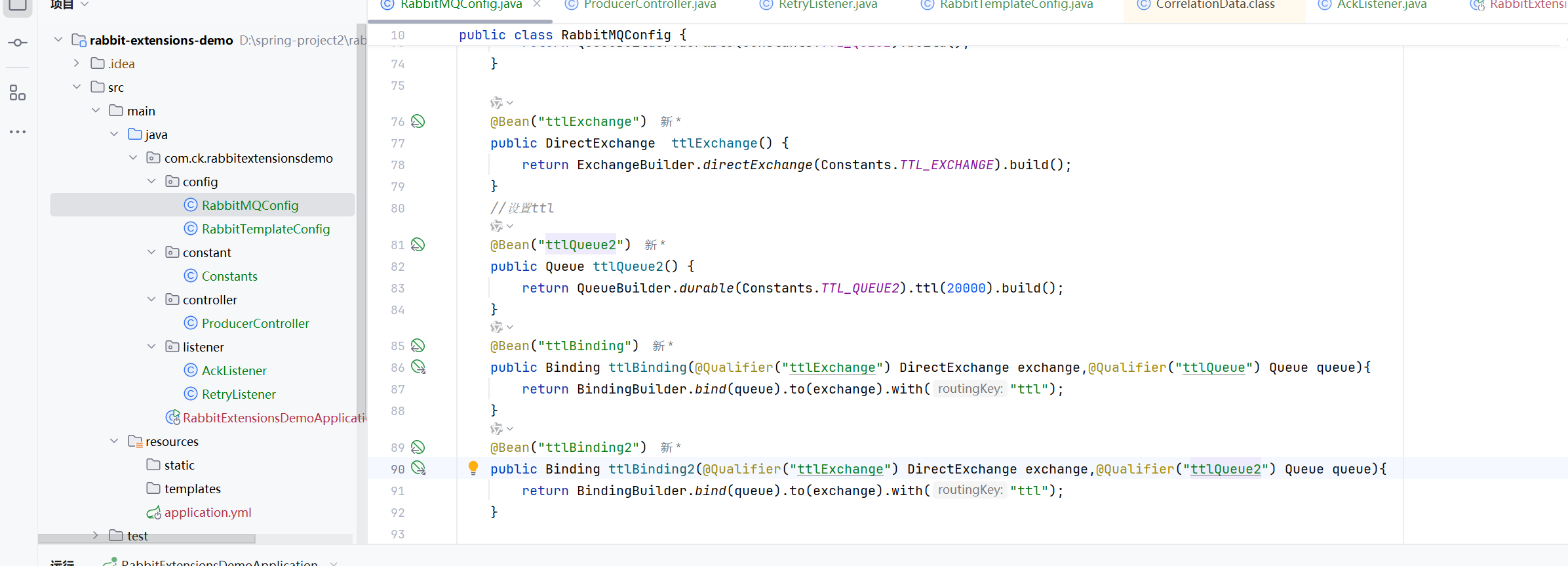
就是增加一个ttl的属性就可以了
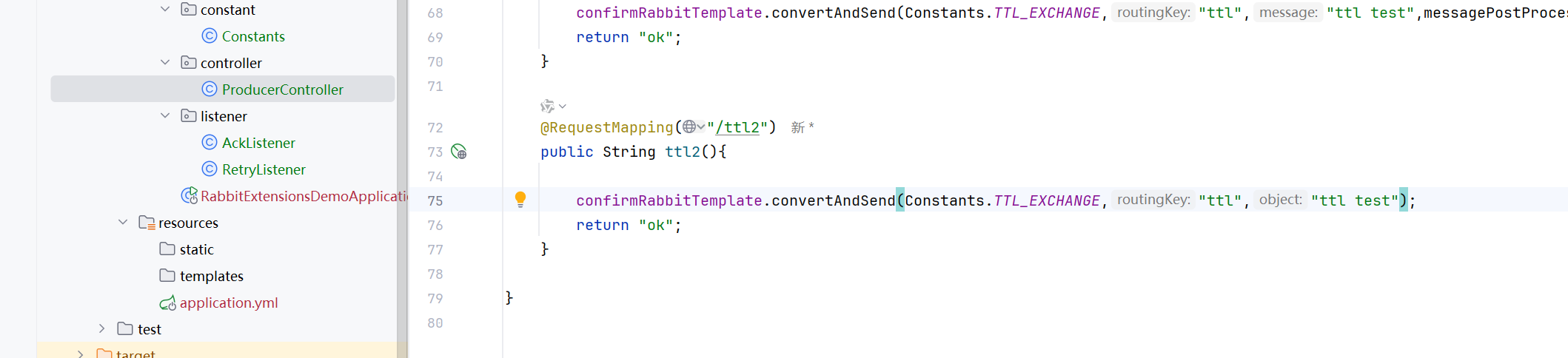
发送一个普通消息



过一会儿这个消息就过期了
设置了队列的ttl,那么所有的消息就变成了这个队列的ttl、,但是本身队列是不会过期的
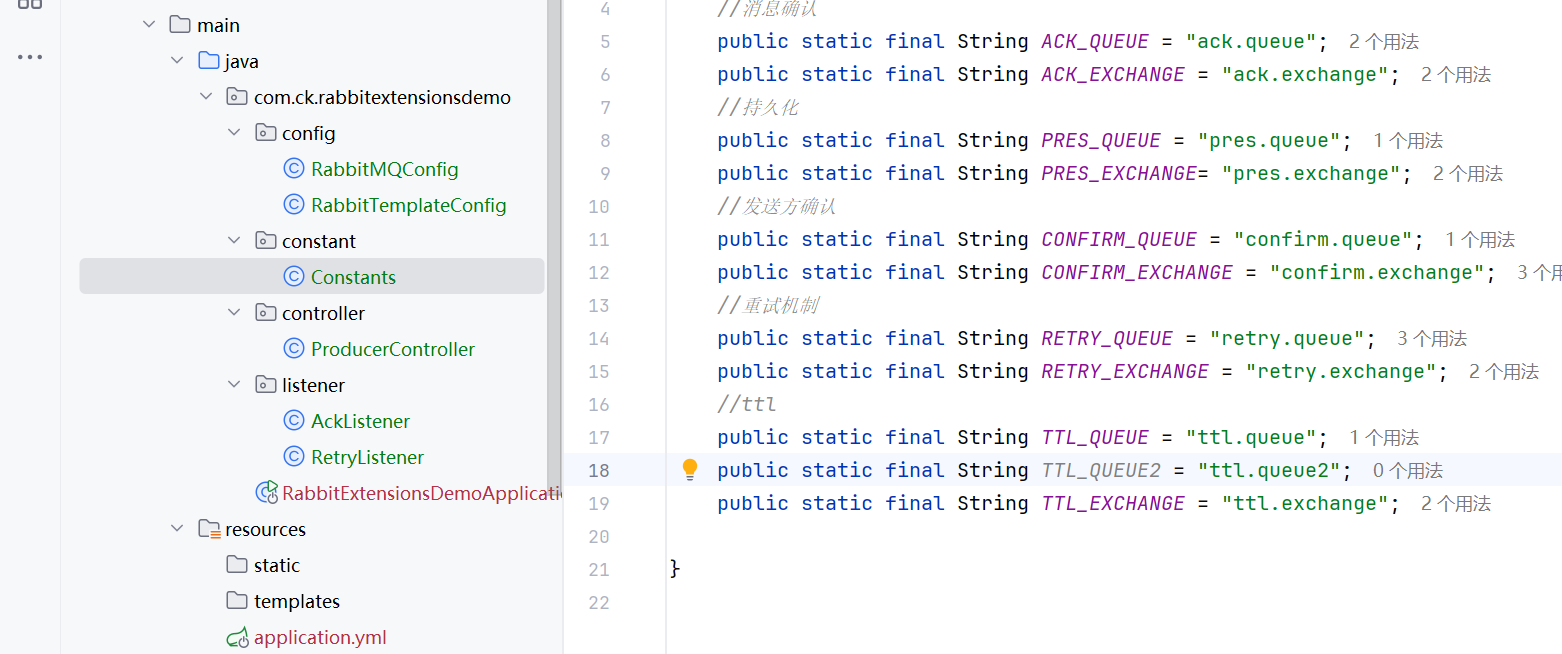
如果同时设置消息和队列的ttl,那么消息的ttl以短的ttl为主

然后这两个消息就会同时五秒钟过期了,但是第一个队列的消息不会消失

设置队列TTL属性的⽅法, ⼀旦消息过期, 就会从队列中删除
设置消息TTL的⽅法, 即使消息过期, 也不会⻢上从队列中删除, ⽽是在即将投递到消费者之前进⾏判定的.
为什么这两种⽅法处理的⽅式不⼀样?
因为设置队列过期时间, 队列中已过期的消息肯定在队列头部, RabbitMQ只要定期从队头开始扫描是否有过期的消息即可.
⽽设置消息TTL的⽅式, 每条消息的过期时间不同, 如果要删除所有过期消息需要扫描整个队列, 所以不如等到此消息即将被消费时再判定是否过期, 如果过期再进⾏删除即可
所以说因为我们的队列1有非过期的消息,所以就算我们的消息过期了,也不会从ttl。queue1删除消息
如果我们要去使用这个过期消息的时候,才会删除这个消息
如果里面这个队列只有一个消息的话,而且已经过期的话,就会删除,但凡这个非ttl队列里面的有消息没有过期,那么过期的消息都不会马上删除

先清空消息队列
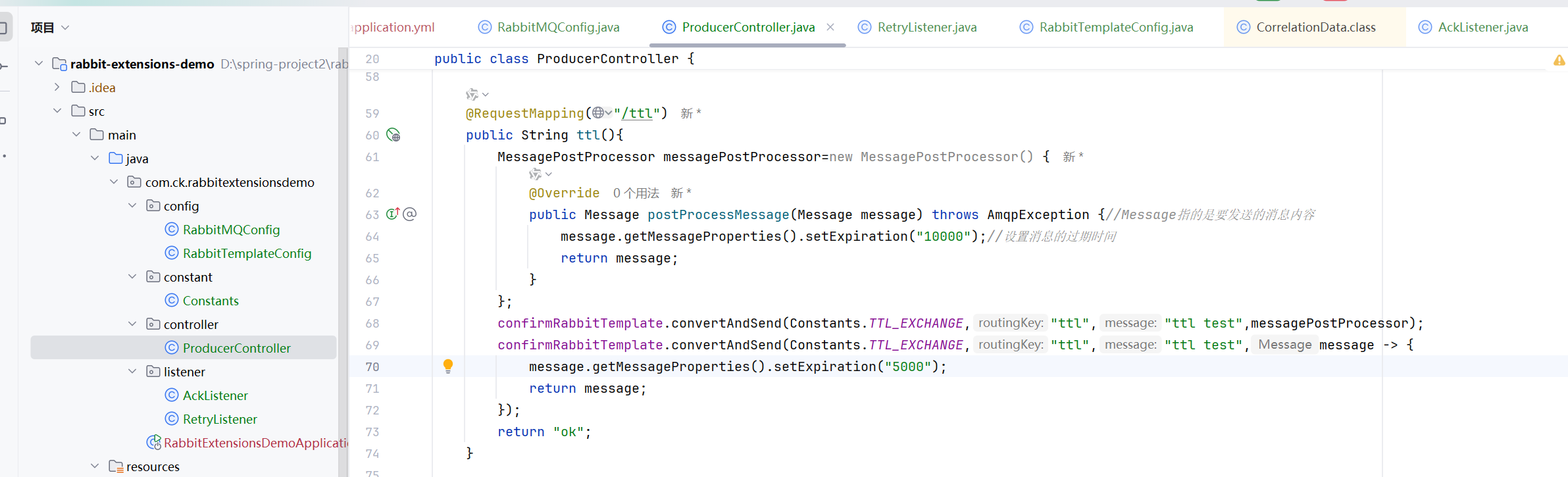

来发两条消息
给一个队列发送不同ttl消息
我们发现这两个消息在ttl1队列中是一起消失的
那么得出结论,非ttl队列的对头消息没有过期的话,就算这个消息过期了,也不会删除这个消息、如果对头消息过期了的话,那么就会删除这个对头消息,然后以此类推后面的消息
或者对头的消息没有过期的话,那么如果要使用其他过期的消息的话,也是会删除那些过期的消息的
这里对头消息10s,所以会和5s的一起消失
下面介绍其他设置队列ttl的方法

这样也是可以的,可以看原码,其实ttl就是调用的withArguments这个方法
死信队列介绍
死信(dead message) 简单理解就是因为种种原因, ⽆法被消费的信息, 就是死信.
有死信, ⾃然就有死信队列. 当消息在⼀个队列中变成死信之后,它能被重新被发送到另⼀个交换器
中,这个交换器就是DLX( Dead Letter Exchange ), 绑定DLX的队列, 就称为死信队列(Dead
Letter Queue,简称DLQ).
过期的消息就是死信的一种
消息变成死信⼀般是由于以下⼏种情况:
- 消息被拒绝( Basic.Reject/Basic.Nack ),并且设置 requeue 参数为 false.-》要求不能重新入队
- 消息过期.
- 队列达到最⼤⻓度
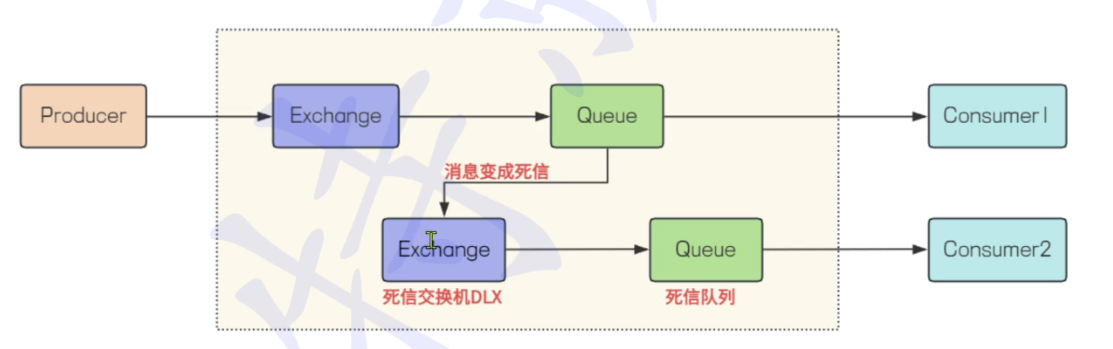
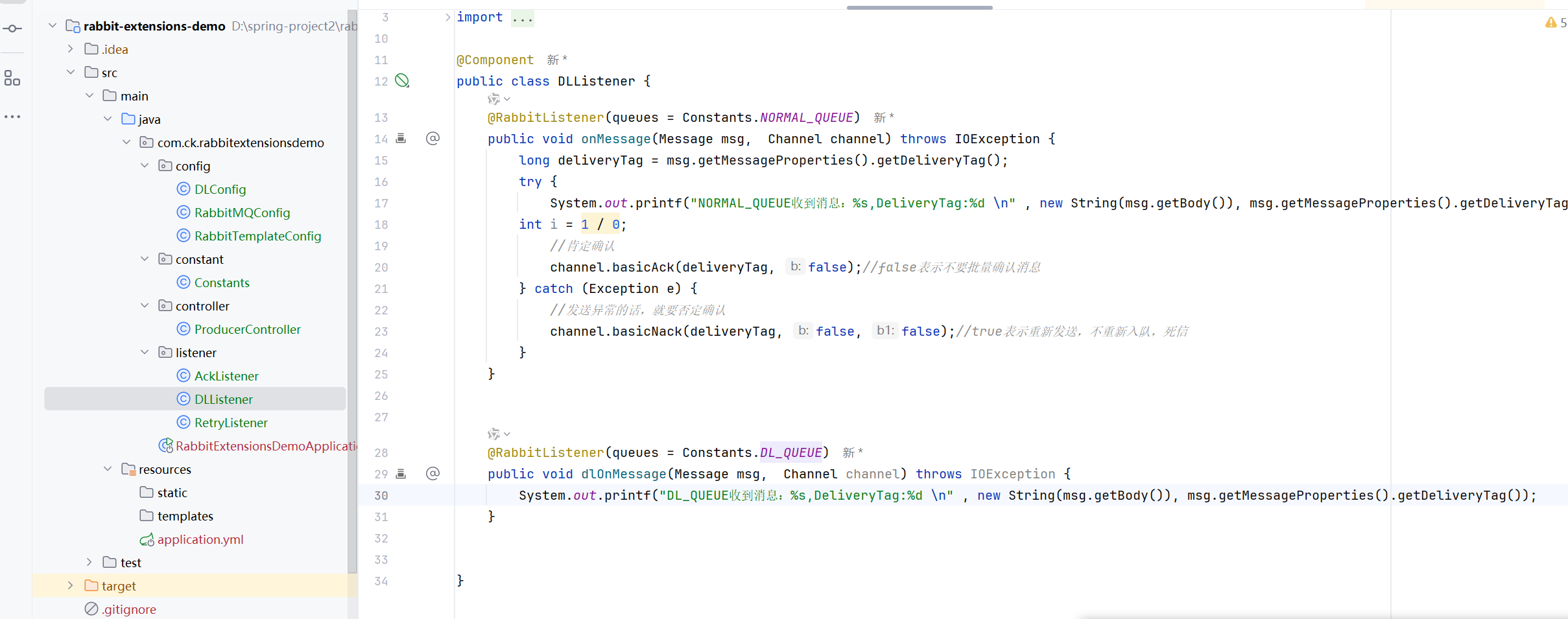
死信队列案例
然后还有一个关系就是消息变成死信的时候,要去死信队列
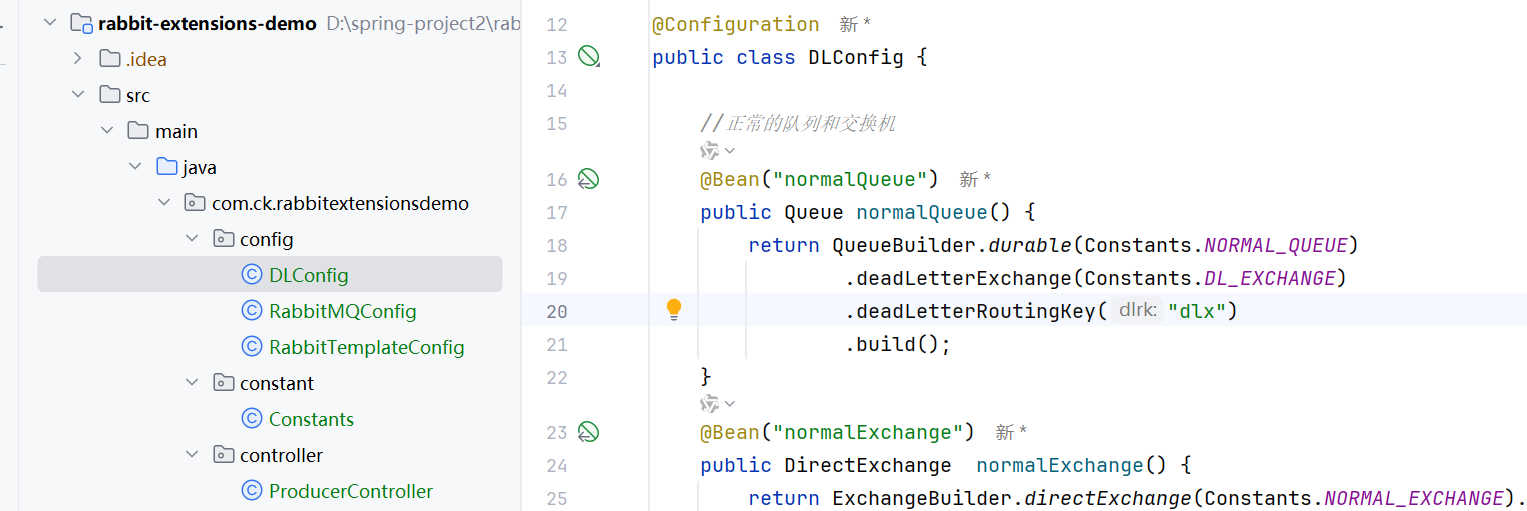
这样就可以了,这个的意思就是
这个正常的队列中的消息死信了,就会去这个死信交换机,然后根据routingkey去对应的死信队列
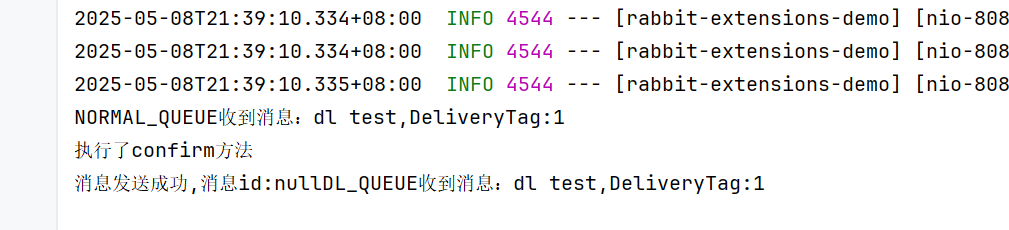
然后我们给队列设置过期时间,那么这个消息就会变成死信的了
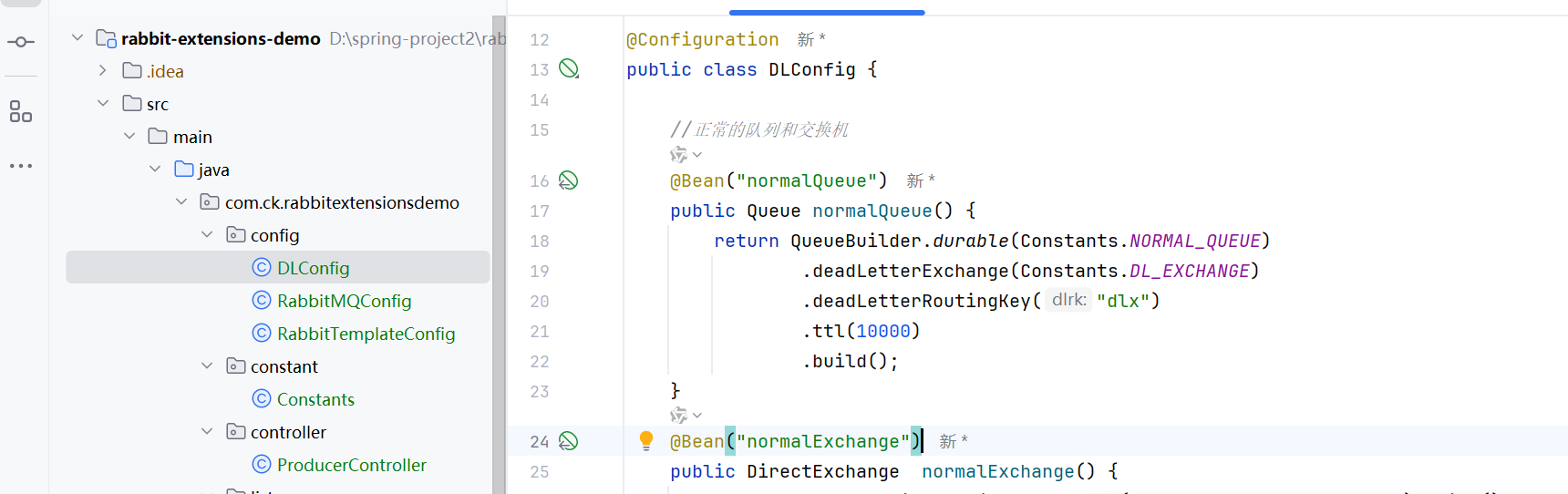
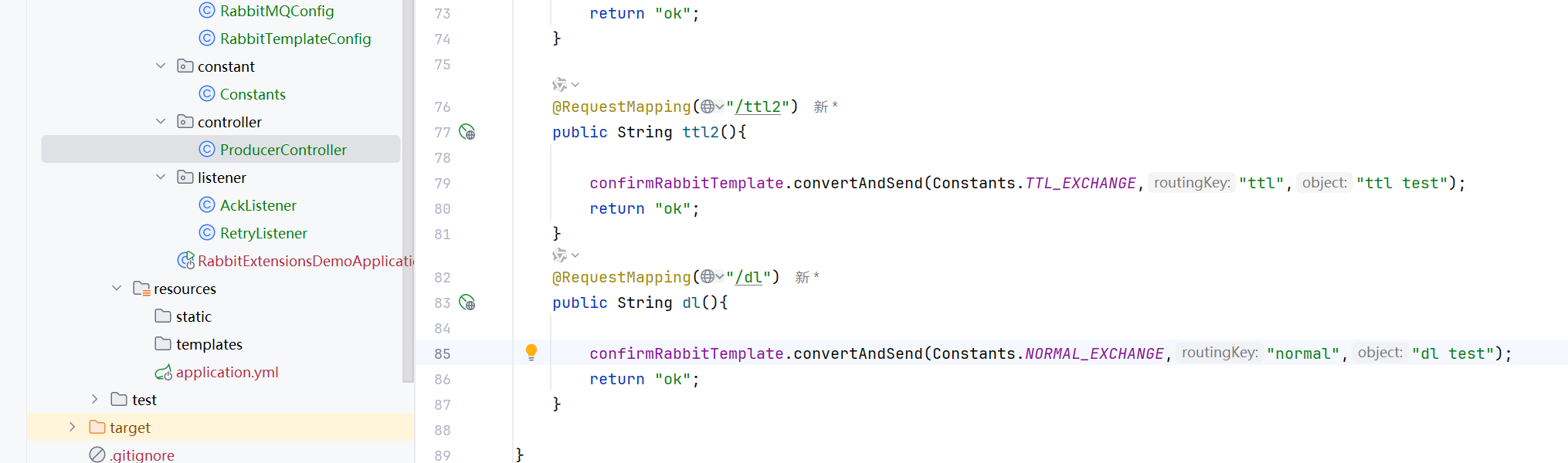
然后是生产者



10s后

这样就成功了
死信其他情况案例
消息拒绝
拒绝的是正常队列,而且还要设置消息不能重新入队

长度达到限制
我们先给队列设置长度
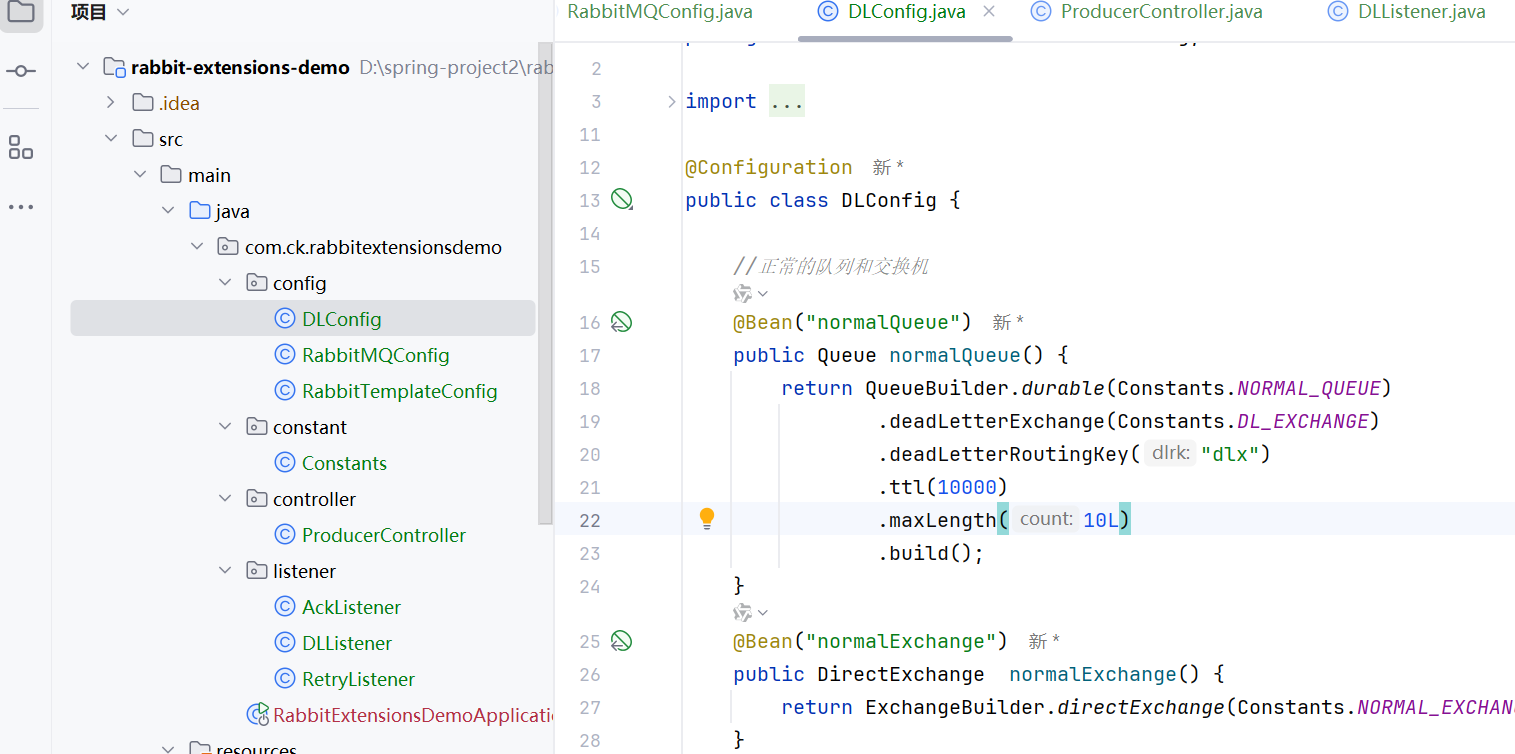
这个是设置长度为10
所以我们发送20个消息吧
但是队列属性是不能随便修改的,所以要先删除队列,在重新运行,我们在取消异常

我们把消费者取消掉,不然立马就被消费了,看不清除效果

我们发现,normal只能装10个,那么多余的就全部都是死信的消息了
死信面试题
- 死信队列的概念
死信(Dead Letter)是消息队列中的⼀种特殊消息, 它指的是那些⽆法被正常消费或处理的消息. 在消息队列系统中, 如RabbitMQ, 死信队列⽤于存储这些死信消息 - 死信的来源
- 消息过期: 消息在队列中存活的时间超过了设定的TTL
- 消息被拒绝: 消费者在处理消息时, 可能因为消息内容错误, 处理逻辑异常等原因拒绝处理该消息. 如果拒绝时指定不重新⼊队(requeue=false), 消息也会成为死信.
- 队列满了: 当队列达到最⼤⻓度, ⽆法再容纳新的消息时, 新来的消息会被处理为死信.
- 死信队列的应⽤场景
对于RabbitMQ来说, 死信队列是⼀个⾮常有⽤的特性. 它可以处理异常情况下,消息不能够被消费者正确消费⽽被置⼊死信队列中的情况, 应⽤程序可以通过消费这个死信队列中的内容来分析当时所遇到的异常情况, 进⽽可以改善和优化系统.
⽐如: ⽤⼾⽀付订单之后, ⽀付系统会给订单系统返回当前订单的⽀付状态
为了保证⽀付信息不丢失, 需要使⽤到死信队列机制. 当消息消费异常时, 将消息投⼊到死信队列中, 由订单系统的其他消费者来监听这个队列, 并对数据进⾏处理(⽐如发送⼯单等,进⾏⼈⼯确认).
场景的应⽤场景还有:
• 消息重试:将死信消息重新发送到原队列或另⼀个队列进⾏重试处理.
• 消息丢弃:直接丢弃这些⽆法处理的消息,以避免它们占⽤系统资源.
• ⽇志收集:将死信消息作为⽇志收集起来,⽤于后续分析和问题定位