vllm简介
vLLM是一个高效的大语言模型推理和部署服务系统,专为大型语言模型的高效执行而设计。它不仅支持多种量化技术以减少模型大小和加速推理过程,还提供了与OpenAI API兼容的服务接口,使得现有的应用程序能够无缝对接。
一、前提环境
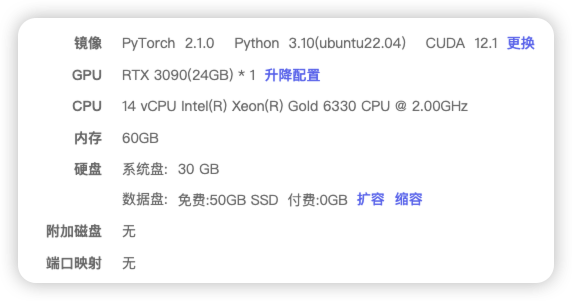
1、系统环境
2、安装相关环境
- 安装依赖
shell
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.11.0
pip install openai==1.17.1
pip install torch==2.1.2+cu121
pip install tqdm==4.66.3
pip install transformers==4.39.3
# 下载flash-attn 请等待大约10分钟左右~
MAX_JOBS=8 pip install flash-attn --no-build-isolation
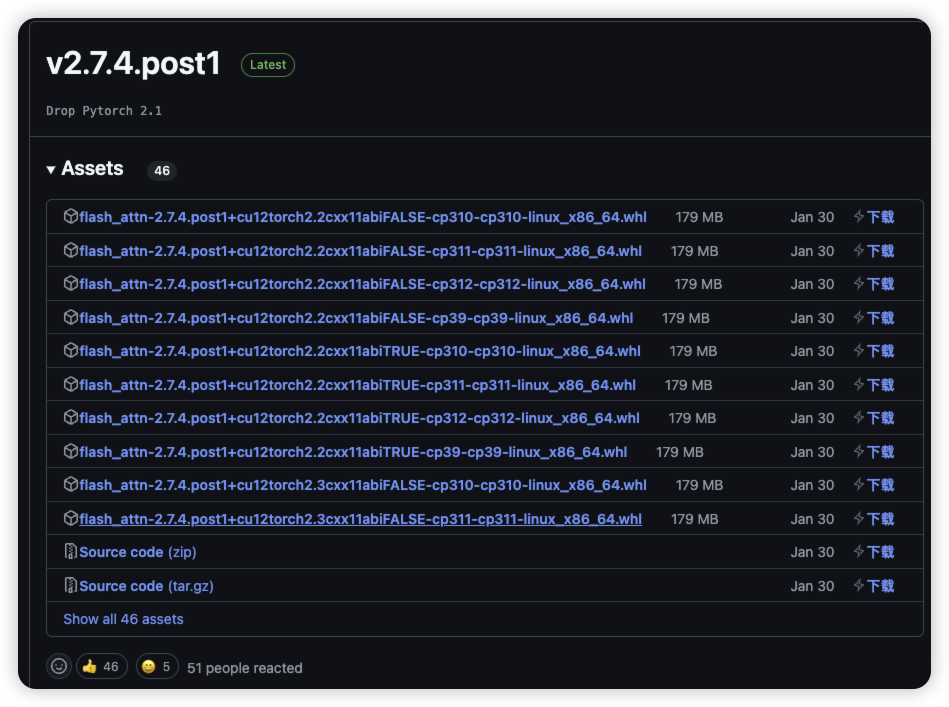
pip install vllm==0.4.0.post1- 注意:如果安装 flash-attn 失败,使用离线安装
下载地址:flash-attn下载 - 下载界面:根据自己系统的版本进行下载
- 安装命令
shell
pip install flash-att本地地址二、模型下载
- 使用 魔搭 下载模型
python
# model_download.py
import os
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
model_dir = snapshot_download('qwen/Qwen2-7B-Instruct', cache_dir='/root/autodl-tmp', revision='master')三、运行模型
1、方式一(使用代码 直接运行 模型)
- 首先从 vLLM 库中导入 LLM 和 SamplingParams 类。LLM 类是使用 vLLM 引擎运行离线推理的主要类。SamplingParams 类指定采样过程的参数,用于控制和调整生成文本的随机性和多样性。
- vLLM 提供了非常方便的封装,我们直接传入模型名称或模型路径即可,不必手动初始化模型和分词器
- 详细代码如下:
python
# vllm_model.py
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
import os
import json
# 自动下载模型时,指定使用modelscope。不设置的话,会从 huggingface 下载
os.environ['VLLM_USE_MODELSCOPE']='True'
def get_completion(prompts, model, tokenizer=None, max_tokens=512, temperature=0.8, top_p=0.95, max_model_len=2048):
stop_token_ids = [151329, 151336, 151338]
# 创建采样参数。temperature 控制生成文本的多样性,top_p 控制核心采样的概率
sampling_params = SamplingParams(temperature=temperature, top_p=top_p, max_tokens=max_tokens, stop_token_ids=stop_token_ids)
# 初始化 vLLM 推理引擎
llm = LLM(model=model, tokenizer=tokenizer, max_model_len=max_model_len,trust_remote_code=True)
outputs = llm.generate(prompts, sampling_params)
return outputs
if __name__ == "__main__":
# 初始化 vLLM 推理引擎
model='/root/autodl-tmp/qwen/Qwen2-7B-Instruct' # 指定模型路径
# model="qwen/Qwen2-7B-Instruct" # 指定模型名称,自动下载模型
tokenizer = None
# 加载分词器后传入vLLM 模型,但不是必要的。
# tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False)
text = ["你好,帮我介绍一下什么时大语言模型。",
"可以给我将一个有趣的童话故事吗?"]
# messages = [
# {"role": "system", "content": "你是一个有用的助手。"},
# {"role": "user", "content": prompt}
# ]
# 作为聊天模板的消息,不是必要的。
# text = tokenizer.apply_chat_template(
# messages,
# tokenize=False,
# add_generation_prompt=True
# )
outputs = get_completion(text, model, tokenizer=tokenizer, max_tokens=512, temperature=1, top_p=1, max_model_len=2048)
# 输出是一个包含 prompt、生成文本和其他信息的 RequestOutput 对象列表。
# 打印输出。
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")- 代码运行结果

2、方式二(提高 openai 式接口)
- 运行指令
shell
python -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/qwen/Qwen2-7B-Instruct --served-model-name Qwen2-7B-Instruct --max-model-len=2048-
解释:
--host 和 --port 参数指定地址。
--model 参数指定模型名称。
--chat-template 参数指定聊天模板。
--served-model-name 指定服务模型的名称。
--max-model-len 指定模型的最大长度。 -
指令运行结果

-
测试代码
python
#使用langchain 调用 openai 的方式调用
# 引入 OpenAI 支持库
from langchain_openai import ChatOpenAI
# 连接信息
base_url ="http://localhost:8000/v1"
api_key ="EMPTY"
model_id ="Qwen2-7B-Instruct"
# 连接大模型
llm =ChatOpenAI(
base_url=base_url,
api_key=api_key,
model=model_id
)
# 大模型调用
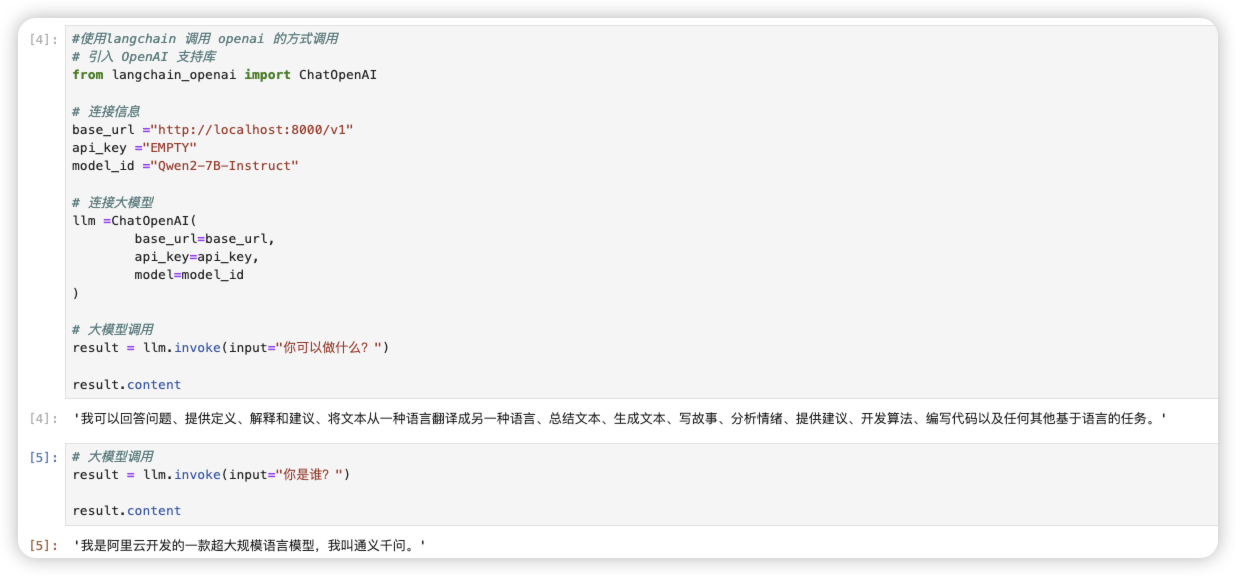
result = llm.invoke(input="你可以做什么?")
result.content- 运行结果