转载请注明出处:
最近在项目中遇到一个奇怪的现象,项目运行环境中的redis在业务运行中,一直没有更新redis的值,在服务的日志中也没有看到相关的异常,导致服务看起来正常,但和redis相关的功能却没有更新。记录下这个异常定位解决的过程。
登录到redis里面,发现redis也是运行正常的,且能正常获取。所以进入到了服务端里面,获取jvm线程进行具体分析,看到有很多个线程栈如下:
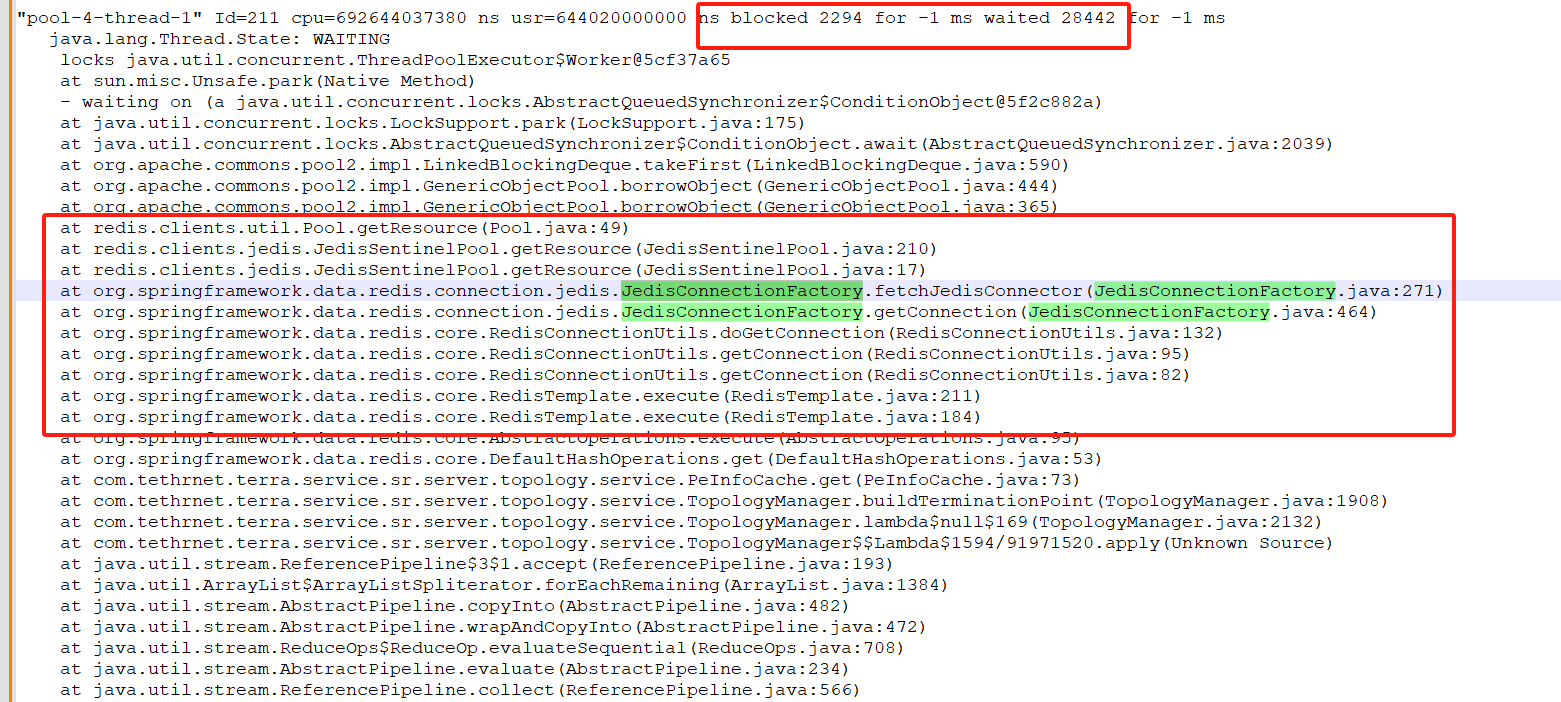
定位分析过程
-
pool-4-thread-1:线程名称,表明该线程属于线程池
pool-4的第一个工作线程(线程池通常由ThreadPoolExecutor管理)。 -
Id=211:JVM 内部分配的线程唯一标识符(非操作系统线程ID)。
CPU 时间统计
cpu=692644037380 ns usr=644020000000 ns -
cpu=692644037380 ns:线程从启动至今消耗的 总 CPU 时间(包括内核态和用户态),单位为纳秒(≈ 692.64 秒)。
-
usr=644020000000 ns:线程在 用户态(User Mode) 消耗的 CPU 时间(≈ 644.02 秒)。
差值意义 :cpu - usr ≈ 48.62秒为线程在内核态(Kernel Mode)的耗时,通常由系统调用(如 I/O、锁竞争)引起。
线程阻塞与等待统计
blocked 2294 for -1 ms waited 28442 for -1 ms-
blocked 2294:线程因 竞争锁(synchronized) 而被阻塞的次数(总计 2294 次)。
-
for -1 ms:阻塞时间的统计方式,
-1 ms表示未记录具体阻塞时长(需启用 JVM 参数-XX:+PrintBlocked获取)。 -
waited 28442:线程在 等待条件触发 (如
Object.wait()或Condition.await())的次数(总计 28442 次)。 -
for -1 ms:等待时间的统计方式,
-1 ms表示未记录具体等待时长(需启用-XX:+PrintWait获取)。
线程状态与堆栈跟踪
java.lang.Thread.State: WAITING
at sun.misc.Unsafe.park(Native Method)
- waiting on (a java.util.concurrent.ThreadPoolExecutor$Worker@5cf37a65)-
Thread.State: WAITING:线程处于 无限期等待 状态,通常由以下操作触发:
-
Object.wait()(无超时参数)。 -
LockSupport.park()。 -
Condition.await()(无超时参数)。
-
-
sun.misc.Unsafe.park(Native Method):线程通过
LockSupport.park()进入阻塞状态,底层调用Unsafe.park()。 -
waiting on (a java.util.concurrent.ThreadPoolExecutor$Worker@5cf37a65):线程正在等待
ThreadPoolExecutor.Worker对象(线程池工作线程的封装)关联的条件变量(如任务队列非空)。
关键堆栈分析
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)-
核心路径:
-
线程从
LinkedBlockingQueue.take()尝试获取任务。 -
若队列为空,调用
ConditionObject.await()进入等待。 -
最终通过
LockSupport.park()挂起线程,直到新任务到达。
-
性能问题诊断
1. 高 waited 次数(28442 次)
-
可能原因:
-
线程池任务队列长期为空,工作线程频繁等待新任务。
-
任务生产速度不足(如上游系统吞吐量低)。
-
线程池配置不合理(核心线程数过多,超出实际需求)。
-
2. 高 blocked 次数(2294 次)
-
可能原因:
-
线程池内部锁竞争(如
Worker线程争用任务队列)。 -
共享资源(如数据库连接池)的同步访问冲突。
-
3. CPU 时间分配
- 用户态耗时占比 :
usr / cpu ≈ 644.02 / 692.64 ≈ 93%,表明线程主要执行用户代码,而非系统调用。若应用为计算密集型,此比例为正常现象。
优化建议
1. 线程池配置优化
-
调整核心线程数 :
若队列长期为空,减少
corePoolSize,避免线程闲置。new ThreadPoolExecutor( corePoolSize, // 根据负载动态调整(如使用动态线程池框架) maxPoolSize, keepAliveTime, TimeUnit.SECONDS, new LinkedBlockingQueue<>(capacity) );
2. 任务队列监控
-
检查队列容量 :
若使用无界队列(如
LinkedBlockingQueue未指定容量),可能导致内存溢出,建议改为有界队列。 -
监控队列堆积 :
通过 JMX 或
ThreadPoolExecutor的getQueue().size()实时观察任务积压情况。
3. 减少锁竞争
-
使用无锁数据结构 :
替换
LinkedBlockingQueue为ConcurrentLinkedQueue(需配合非阻塞任务调度逻辑)。 -
分离读写操作 :
若共享资源访问频繁,使用读写锁(
ReentrantReadWriteLock)替代独占锁。
问题解决:
根据截图中的线程栈调用过程,可以定位到项目代码执行调用的地方,发现调用的地方是频繁批量更新redis缓存值得,且每次都是单独一条设置更新得。因此很快推测出来,是这个调用得地方在频繁更新redis缓存值时,导致服务中redis得连接数不够了,因此将代码中更新redis值得方式,使用管道得方式进行更新设置,问题得以解决。