目录
- 一、简介
- 二、相关命令
-
- [2.1 hset 和 hget](#2.1 hset 和 hget)
- [2.2 hexists](#2.2 hexists)
- [2.3 hdel](#2.3 hdel)
- [2.4 hkeys](#2.4 hkeys)
- [2.5 hvals](#2.5 hvals)
- [2.6 hgetall](#2.6 hgetall)
- [2.7 hmget](#2.7 hmget)
- [2.8 hlen](#2.8 hlen)
- [2.9 hsetnx](#2.9 hsetnx)
- [2.10 hincrby](#2.10 hincrby)
- [2.11 hincrbyfloat](#2.11 hincrbyfloat)
- [2.12 小结](#2.12 小结)
- 三、编码方式
- 四、应用场景
-
- [4.1 作为缓存](#4.1 作为缓存)

一、简介
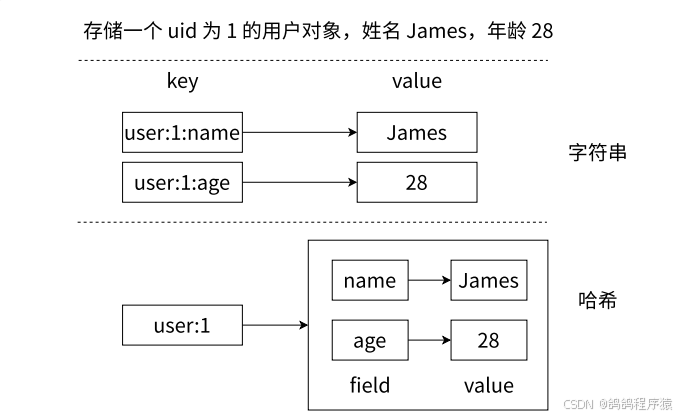
在 Redis 中,哈希类型是指值本⾝⼜是⼀个键值对结构,形如 key = "key",value = { { field1, value1 }, ..., {fieldN, valueN} },在Redis中为了与key - value作区分,将Hash类型键值对结构表示为filed - value。
String与Hash对比图:
二、相关命令
2.1 hset 和 hget
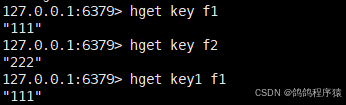
hset: 设置 hash 中指定的字段(field)的值(value)。
语法:hset key field value [field value ...]
命令有效版本:2.0.0 之后
时间复杂度:插⼊⼀组 field 为 O(1), 插⼊ N 组 field 为 O(N)
返回值:添加的字段的个数。
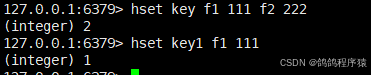
也可以当修改字段的效果:
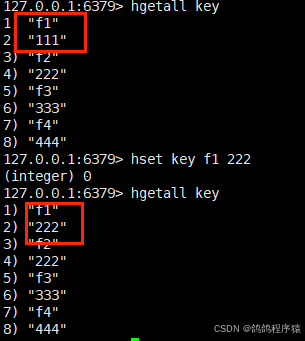
hget:获取 hash 中指定字段的值。
语法:hget key filed
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:字段对应的值或者 nil。
2.2 hexists
hexists判断 hash 中是否有指定的字段。
语法:hexists key filed
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:1 表⽰存在,0 表⽰不存在。

2.3 hdel
hdel删除 hash 中指定的字段。
语法:hdel key field [field ...]
命令有效版本:2.0.0之后
时间复杂度:删除⼀个元素为 O(1). 删除 N 个元素为 O(N).
返回值:本次操作删除的字段个数。

2.4 hkeys
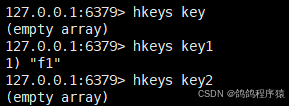
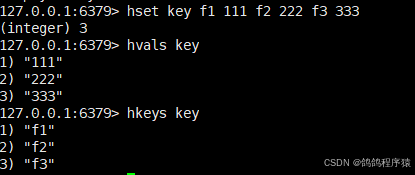
hkeys获取 hash 中的所有字段。
语法:hkeys key
命令有效版本:2.0.0 之后
时间复杂度:O(N), N 为 field 的个数.
返回值:字段列表。
2.5 hvals
hvals 获取 hash 中的所有的值。
语法:hvals key
命令有效版本:2.0.0 之后
时间复杂度:O(N), N 为 field 的个数.
返回值:Hash所有value列表。
2.6 hgetall
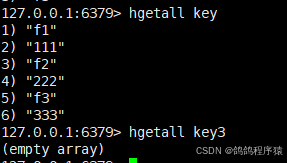
hgetall获取 hash 中的所有的字段和值。
语法:hgetall key
命令有效版本:2.0.0 之后
时间复杂度:O(N), N 为 field 的个数.
返回值:Hash所有字段和对应的值。
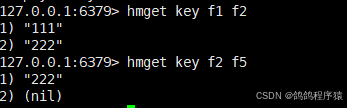
2.7 hmget
hmget⼀次获取 hash 中多个字段的值。
hmget key field [field ...]
命令有效版本:2.0.0 之后
时间复杂度:只查询⼀个元素为 O(1), 查询多个元素为 O(N), N 为查询元素个数.
返回值:字段对应的值或者 nil。
2.8 hlen
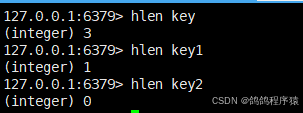
hlen获取 hash 中的所有字段的个数。
语法:hlen key
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:字段个数。
2.9 hsetnx
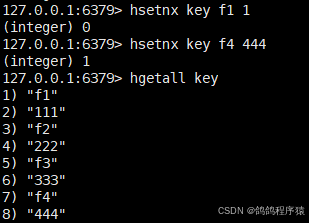
hsetnx在字段不存在的情况下,设置 hash 中的字段和值。
语法:hsetnx key field value
命令有效版本:2.0.0 之后
时间复杂度:O(1)
返回值:1表⽰设置成功,0 表⽰失败。
2.10 hincrby
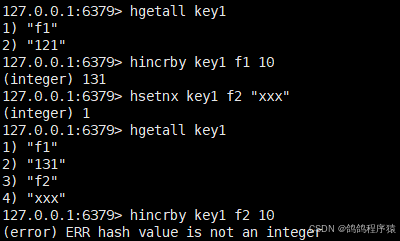
hincrby将 hash 中字段对应的数值(必须是整数)添加指定的值。
语法: hincrby key field increment
命令有效版本:2.0.0之后
时间复杂度:O(1)
返回值:该字段变化之后的值。
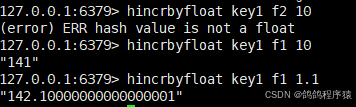
2.11 hincrbyfloat
hincrbyfloathincrby的浮点数版本, 将 hash 中字段对应的数值(可以是整数和浮点数)添加指定的值。
语法: hincrbyfloat key field increment
命令有效版本:2.6.0之后
时间复杂度:O(1)
返回值:该字段变化之后的值。
2.12 小结
| 命令 | 执⾏效果 | 时间复杂度 |
|---|---|---|
| hset key field value | 设置值 | O(1) |
| hget key field | 获取值 | O(1) |
| hdel key field field ... | 删除 field | O(k), k 是 field 个数 |
| hlen key | 计算 field 个数 | O(1) |
| hgetall key | 获取所有的 field-value | O(k), k 是 field 个数 |
| hmget key field field ... | 批量获取 field-value | O(k), k 是 field 个数 |
| hmset key field value field value ... | 批量获取 field-value | O(k), k 是 field 个数 |
| hexists key field | 判断 field 是否存在 | O(1) |
| hkeys key | 获取所有的 field | O(k), k 是 field 个数 |
| hvals key | 获取所有的 value | O(k), k 是 field 个数 |
| hsetnx key field value | 设置值,但必须在 field 不存在时才能设置成功 | O(1) |
| hincrby key field n | 对应 field-value +n | O(1) |
| hincrbyfloat key field n | 对应 field-value +n | O(1) |
| hstrlen key field | 计算 value 的字符串⻓度 | O(1) |
三、编码方式
哈希的内部编码有两种:
- ziplist(压缩列表):当哈希类型元素个数⼩于 hash-max-ziplist-entries 配置(默认 512 个)、同时所有值都⼩于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使⽤ ziplist 作为哈希的内部实现,ziplist 使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存⽅⾯⽐ hashtable 更加优秀。
- hashtable(哈希表):当哈希类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,⽽ hashtable 的读写时间复杂度为 O(1)。

四、应用场景
4.1 作为缓存
存储结构化的数据的时候,使用 hash 更加合适。
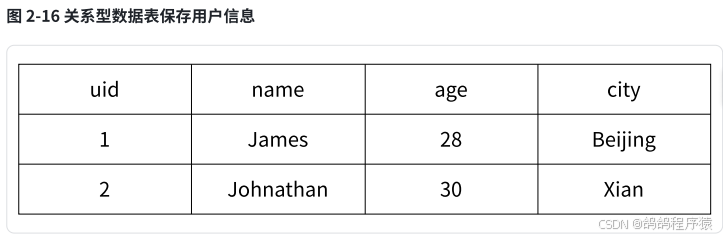
使用hash表示: