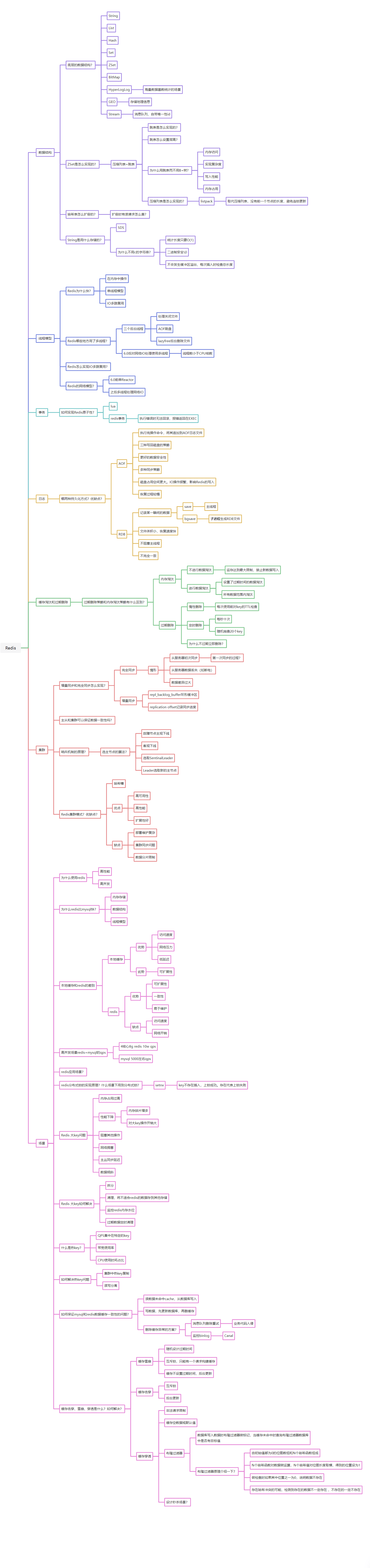
数据结构
Redis 提供了丰富的底层数据结构,且对部分结构的实现细节做了深度优化:
- String :
- 底层基于 SDS(简单动态字符串) 实现,SDS 记录了字符串长度(获取长度 O (1))、预留空间(避免频繁扩容)、二进制安全(可存储任意字节)。
- 衍生结构:
BitMap(位操作,如统计用户活跃天数)、HyperLogLog(基于伯努利试验的基数统计,误差约 0.81%)、GEO(存储地理位置,用 GeoHash 编码实现距离计算)、Stream(消息队列,支持多消费者组、消息持久化)。
- List :
- 底层是双向链表 + 压缩列表(小数据量时用压缩列表节省内存,大数据量时转双向链表)。
- 操作:
lpush/rpush(头 / 尾插入)、lpop/rpop(头 / 尾弹出)、lrange(范围查询)等,支持 "栈""队列""阻塞队列" 等模式。
- Hash :
- 底层是哈希表 + 压缩列表(字段少且值小时用压缩列表)。
- 优势:存储对象时更节省内存(相比 String 存 JSON 字符串),支持
hset(设字段)、hget(获取字段)、hdel(删除字段)等操作。
- Set :
- 底层是哈希表 + 整数集合(元素是整数且数量少时用整数集合)。
- 支持交集(
sinter)、并集(sunion)、差集(sdiff)操作,常用于 "共同好友""标签去重" 场景。
- ZSet :
- 底层是跳表 + 压缩列表(元素少且值小时用压缩列表)。
- 跳表原理:通过多层链表加速查询,插入、删除、查询复杂度均为 O (logN);压缩列表用
listpack优化(无节点长度冗余,查询更高效)。 - 核心操作:
zadd(添加带分数元素)、zrange(按分数范围查询)、zrank(查元素排名)等,适用于 "排行榜""延迟任务" 场景。
线程模型
- 单线程核心逻辑 :Redis 主线程处理命令解析、执行、响应,避免了多线程的上下文切换和锁竞争开销。
- 多线程辅助场景 :
- AOF 刷盘:6.0+ 版本用多线程异步刷盘,主线程写 AOF 缓冲区后,由子线程将缓冲区数据刷到磁盘。
- lazyfree 操作 :如
unlink(异步删除大 key)、flushdb async(异步清空数据库),主线程仅标记 key 为待删除,子线程负责实际内存释放。 - 网络 IO(6.0+):多线程处理 "socket 读取、解析命令、发送响应",但命令执行仍由主线程完成(保证原子性)。
- IO 多路复用 :基于
Reactor模型,通过epoll(Linux)/kqueue(BSD)等系统调用,让单线程能同时监听多个 socket 的 IO 事件,避免阻塞。
事务
Redis 事务通过 lua 脚本和自身事务机制保证原子性,执行错误时(如语法错)会在 EXEC 阶段回滚。
日志
对比了两种持久化方式的优劣:
- RDB 快照 :
- 触发方式:
save(主线程同步执行,阻塞业务)、bgsave(fork 子进程执行,不阻塞主线程)、配置save <秒> <修改次数>(自动触发)。 - 优势:恢复速度快、文件体积小;劣势:可能丢失 "最后一次快照后" 的数据,fork 子进程时若内存大,会有短暂卡顿。
- 触发方式:
- AOF 日志 :
- 同步策略:
appendfsync always(每次命令都刷盘,最安全但最慢)、everysec(每秒刷盘,平衡安全与性能)、no(由操作系统决定刷盘时机,最快但最不安全)。 - 重写机制:
bgrewriteaof会 fork 子进程,遍历内存中 key-value 生成新 AOF 文件(仅记录最终状态),解决 AOF 文件膨胀问题。
- 同步策略:
缓存淘汰和过期删除
-
- 不淘汰:内存满时返回
OOM错误(maxmemory-policy noeviction)。 - 淘汰类型:
- 过期键淘汰:
volatile-ttl(选过期时间最短的)、volatile-random(随机选过期键)、volatile-lru(LRU 淘汰过期键)、volatile-lfu(LFU 淘汰过期键)。 - 全库键淘汰:
allkeys-lru(全库 LRU 淘汰)、allkeys-random(全库随机淘汰)、allkeys-lfu(全库 LFU 淘汰)。
- 过期键淘汰:
- 不淘汰:内存满时返回
- 过期删除机制 :
- 惰性删除:访问 key 时检查 TTL,若过期则删除(避免无意义内存占用)。
- 定时删除:每秒随机选 20 个 key 检查过期,若过期 key 占比超 25%,则循环此操作(防止大量过期 key 堆积)。
集群
- 主从同步 :
- 全量同步:从节点初次连接主节点时,主节点生成 RDB 快照并发送,从节点加载 RDB 后再同步增量命令(
repl_backlog_buffer环形缓冲区记录)。 - 增量同步:主节点写命令同步到从节点,从节点执行命令保持数据一致(基于
replication offset标记同步进度)。
- 全量同步:从节点初次连接主节点时,主节点生成 RDB 快照并发送,从节点加载 RDB 后再同步增量命令(
- 哨兵机制 :
- 节点监控:哨兵进程定时 ping 主从节点,判断节点是否存活。
- 故障转移:主节点主观下线后,哨兵选举 leader 并推选新主节点,通知从节点切换主节点(保证服务不中断)。
- 集群模式(哈希槽) :
- 16384 个哈希槽分片数据,节点负责部分槽位;客户端通过
MOVED/ASK重定向找到目标节点。 - 优势:支持水平扩容、故障自动转移;劣势:运维复杂、跨槽操作(如多 key 事务)需额外处理。
- 16384 个哈希槽分片数据,节点负责部分槽位;客户端通过
场景
- Redis 优势:高性能、高并发、内存存储、数据结构丰富、单线程模型(对比 MySQL 有明显 QPS 优势,Redis 可达 10w+ qps,MySQL 约 5000 qps)。
- 经典问题与解决方案:
- 大 key 问题:危害是内存占用过高、性能下降等;解决方案包括拆分 key、清理非 Redis 适配数据、监控内存水位、过期数据定时清理。
- 热 key 问题:定义是 QPS 集中、带宽 / CPU 占用高的 key;解决方案是集中热 key 复制、读写分离。
- 数据一致性(Redis + MySQL):可通过 "缓存预热 + cache 读、数据库写""写数据库后删缓存""删除缓存失败时用消息队列重试(如 Canal 监控 binlog)" 等方案保障。
- 缓存策略(击穿、雪崩、穿透) :
- 击穿:热点 key 过期后被大量请求打穿,可通过互斥锁(同一时间仅一个请求重建缓存)解决。
- 雪崩:大量 key 同时过期,可通过随机过期时间避免。
- 穿透:请求不存在的 key 穿透到数据库,可通过布隆过滤器(判断 key 是否可能存在,过滤无效请求)解决。