目标链接:https://spa1.scrape.center
python
import requests
url = 'https://spa1.scrape.center'
html = requests.get(url).text
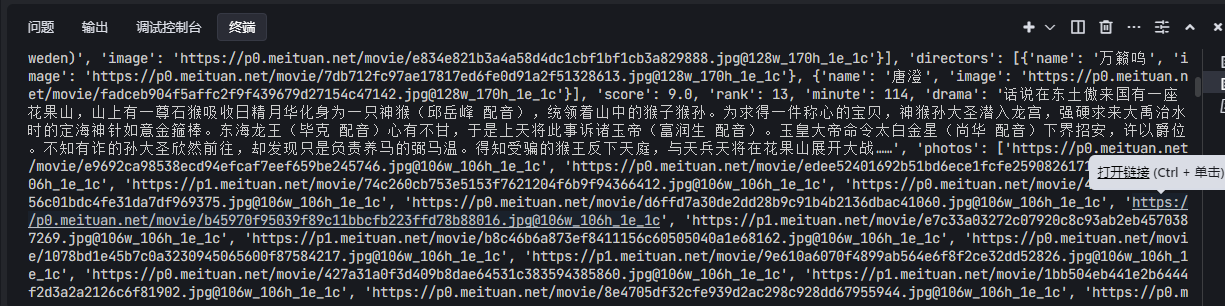
print(html)运行结果如下
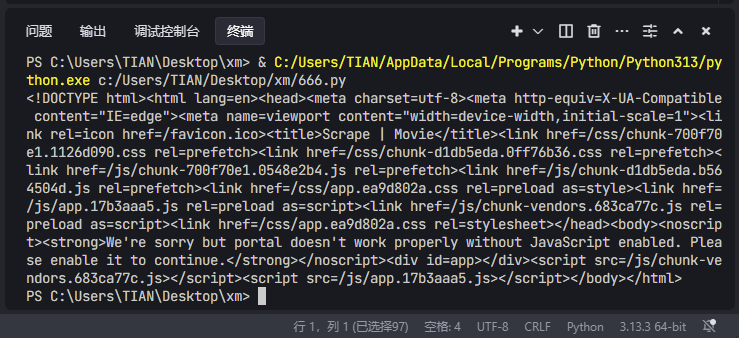
在HTML中我们只能在源码中看到引用了一些JS和CSS文件并没有观察到任何有关电影数据的信息,说明看到的页面是通过JS渲染得到的
一般情况下这些数据都是通过AJax来加载的,JS在后台调用这些Ajax数据接口得到数据后,再把数据进行解析并渲染呈现出来,得到最终的页面
要想获取页面,可以通过直接Ajax接口来获取数据
列表页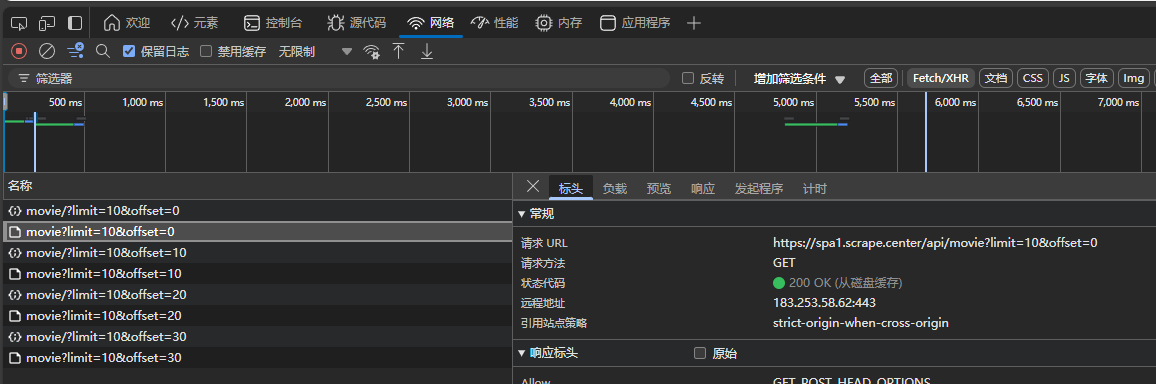
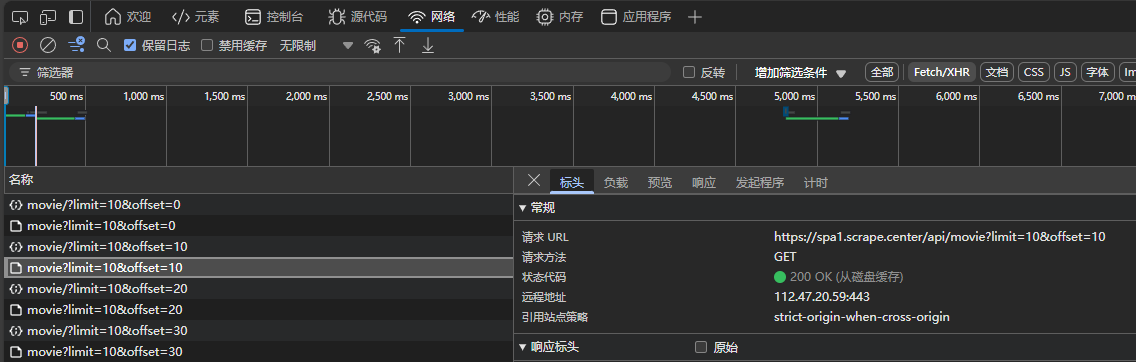
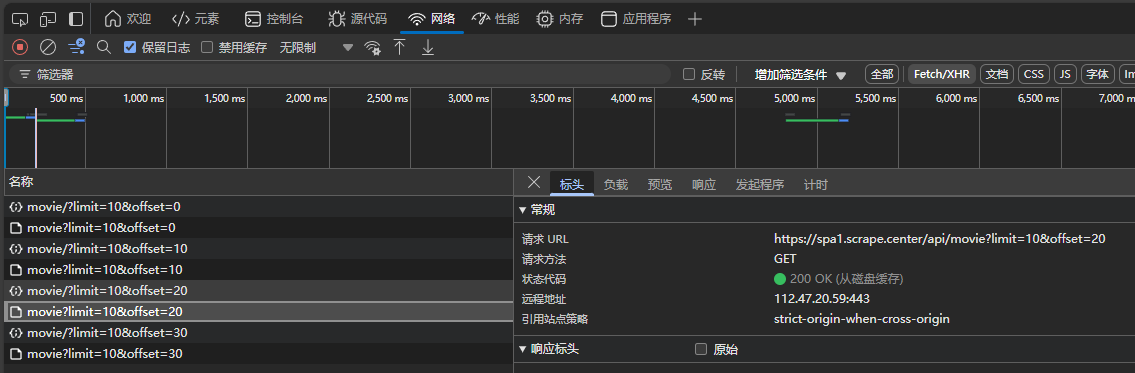
 页面加1 offset加10
页面加1 offset加10
python
import requests
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
INDEX_URL='https://spa1.scrape.center/api/movie/?limit={limit}&offset={offset}'
python
def scrape_api(url):
logging.info('scraping %s...',url)
try:
response=requests.get(url)
if response.status_code==200:
return response.json()
logging.error('get invalid status code %s while scraping %s',response.status_code,url)
except requests.RequestException:
logging.error('error occurred while scraping %s',url,exc_info=True)
python
LIMIT=10
def scrape_index(page):
url=INDEX_URL.format(limit=LIMIT,offset=LIMIT*(page-1))
return scrape_api(url)先构造一个URL,通过字符串的format的方法,传入limit和offset的值
构造好URl之后,直接调用scape_api方法并返回结果
python
DETATL_URL='https://spa1.scrape.center/api/movie/{id}'
def scrape_detail(id):
url=DETATL_URL.format(id=id)
return scrape_api(url)
TOTAL_PAGE=10
def main():
for page in range(1,TOTAL_PAGE+1):
index_data=scrape_index(page)
for item in index_data.get('results'):
id=item.get('id')
detail_data=scrape_detail(id)
logging.info('detail data %s',detail_data)
if __name__=='__main__':
main()运行结果如下: