索引的目的就是为了提高查询效率
索引的结构是B+树,那么说到B+树,必须提一下其他三种结构,分别是:二叉查找树、平衡二叉树、B树
我们来看看各自的结构特征
二叉查找树
特点:任何节点的左子节点的值都小于当前节点的值,右子节点的值都大于当前节点的值。
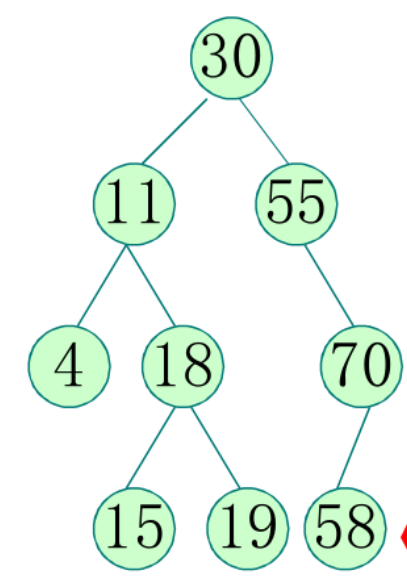
假如现在每个节点上的值代表主键,现在有一张表比如test
|-------|----|
| value | id |
| 1 | 4 |
| 2 | 11 |
| 3 | 15 |
| 4 | 18 |
| 5 | 19 |
| 6 | 30 |
| 7 | 55 |
| 8 | 58 |
| 9 | 70 |
现在我要查询这条语句,select name from test where id = 19,那么索引是如何走的呢?
首先从根节点开始判断,
19和30比较,19 < 30 ,那么走左节点,左节点是11,
19和11比较,19> 11,那么走右节点,右节点是18,
19和18比较,19 > 18,那么走右节点,右节点是19,找到了。总共找了3次。
那么如果没有索引,那么从表中一条一条找,就要找5次。
能提高查询效率,但是二叉查找树的缺点也比较明显,就是它可能会存在退化成一个链表的情况,
比如现在id有很多都是大于70的,那么在70这个节点的右节点就会是一个链表。链表的查询效率每次都得从第一个节点开始一直向后遍历,等同于全表扫描。
平衡二叉树
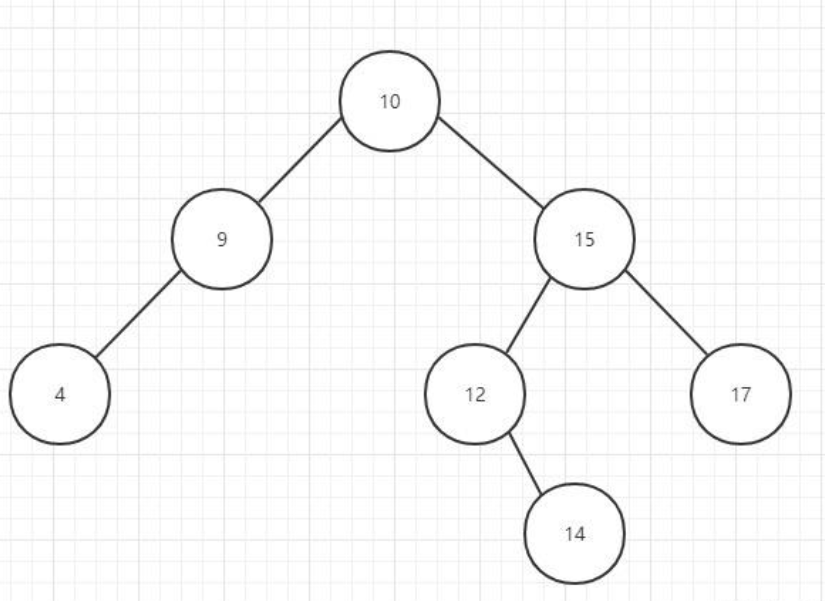
特点:每个节点的左右子树的高度差不能超过 1,避免了二叉查找树退化成链表的情形
能提高查询效率,而且比起二叉查找树更稳定,更平衡,不会有形成链表的情况。
但是也有缺点,因为索引是存放在一个磁盘页的,一个磁盘页只存放一个索引和数据,不但没有充分利用磁盘页的空间,而且当数据量越来越多的时候,这样就会创建更多的节点,节点越多,树的高度也就越高,那么查找的效率也就会降低了,磁盘IO次数多。
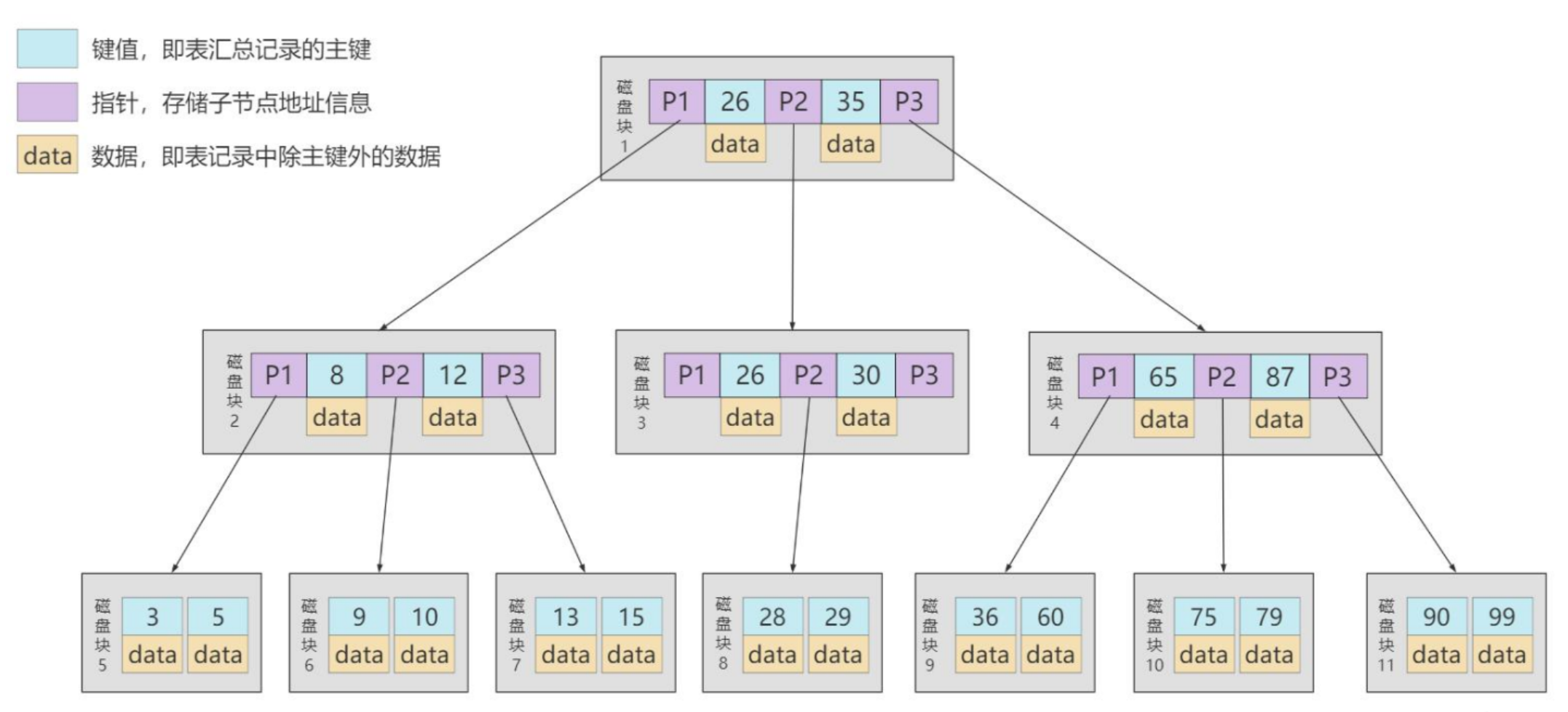
B树
特点:一个磁盘块会存放更多的索引和数据,也就是每一个非叶子节点会存放更多的索引和数据和指针,叶子节点没有指针,只有索引和数据。较小的高度就能承受很多的数据。而且查询速度也快。
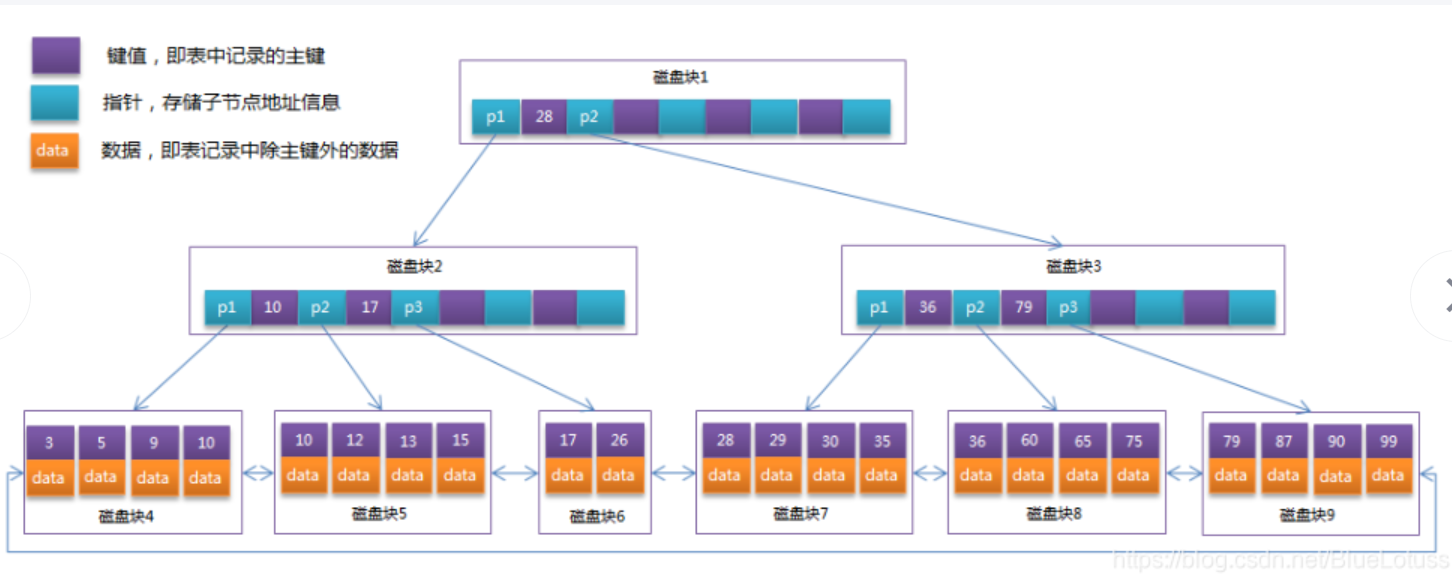
B+树
特点:和B树相比,非叶子节点只存放索引和指针,那么一个磁盘块相对于B树就可以存放更多的索引和指针,那么树的高度相对于B树就越低,查询效率也比 B树更快;
只有叶子结点是存放数据的,同时叶子结点与叶子结点之间还有指针指向,那么对于范围查询也比较适合,就不用从根节点重新开始查找了,比如我要找id>17的,那么当我找到17的,直接向右查找就可以了,就不用每次都从根节点开始查找。
总结:
为什么索引不使用二叉查找树,平衡二叉树,B树,一定要用B+树。
二叉查找树可能会退化成链表,每次查找都需要从第一节点开始查找,相当于全表扫描。
平衡二叉树高度平衡,虽然不会退化成链表,但是一个磁盘块只能存放一个索引和一个数据,没有充分发挥磁盘块的空间,当数据量大的情况下,就会创建更多的节点,节点越多,树的高度也就越高,查找效率也就下降,磁盘IO次数增多,B树的非叶子结点会存放索引,数据和指针,而B+树的非叶子结点是不存放数据的,那么相同磁盘块大小的情况下,B+树可以存发给更多的索引,那么树的高度比B树肯定是更矮,同时承接的数据量更大,查找效率肯定也就比B树快,而且B树的叶子结点是没有指针的,不适合范围查询,而B+树的叶子结点是有存放指针的,适合做范围查询。