1 IVF_PQ
IVF_PQ 索引是一种基于量化的 索引算法,用于高维空间中的近似近邻搜索。虽然速度不如某些基于图的方法,但IVF_PQ通常需要的内存要少得多,因此是大型数据集的实用选择。
1.1 概述
IVF_PQ 是Inverted File with Product Quantization 的缩写,是一种结合索引和压缩的混合方法,用于高效的向量搜索和检索。它利用了两个核心组件:反转文件 (IVF) 和乘积量化 (PQ )。
1.1.1 反转文件
IVF 就像在一本书中创建索引。你不用扫描每一页(或者,在我们的情况下,每一个向量),而是在索引中查找特定的关键词(群组),从而快速找到相关的页面(向量)。在我们的方案中,向量被归入簇,算法将在与查询向量接近的几个簇内进行搜索。
下面是其工作原理:
- **聚类:**使用 k-means 等聚类算法,将向量数据集划分为指定数量的簇。每个聚类都有一个中心点(聚类的代表向量)。
- **分配:**每个向量被分配到其中心点最接近的聚类中。
- **反向索引:**创建一个索引,将每个聚类的中心点映射到分配给该聚类的向量列表中。
- **搜索:**搜索近邻时,搜索算法会将查询向量与群集中心点进行比较,并选择最有希望的群集。然后将搜索范围缩小到这些选定簇内的向量。
1.1.2 PQ
**乘积量化(PQ)**是一种针对高维向量的压缩方法,可显著降低存储需求,同时实现快速的相似性搜索操作符。PQ 过程包括以下几个关键阶段:
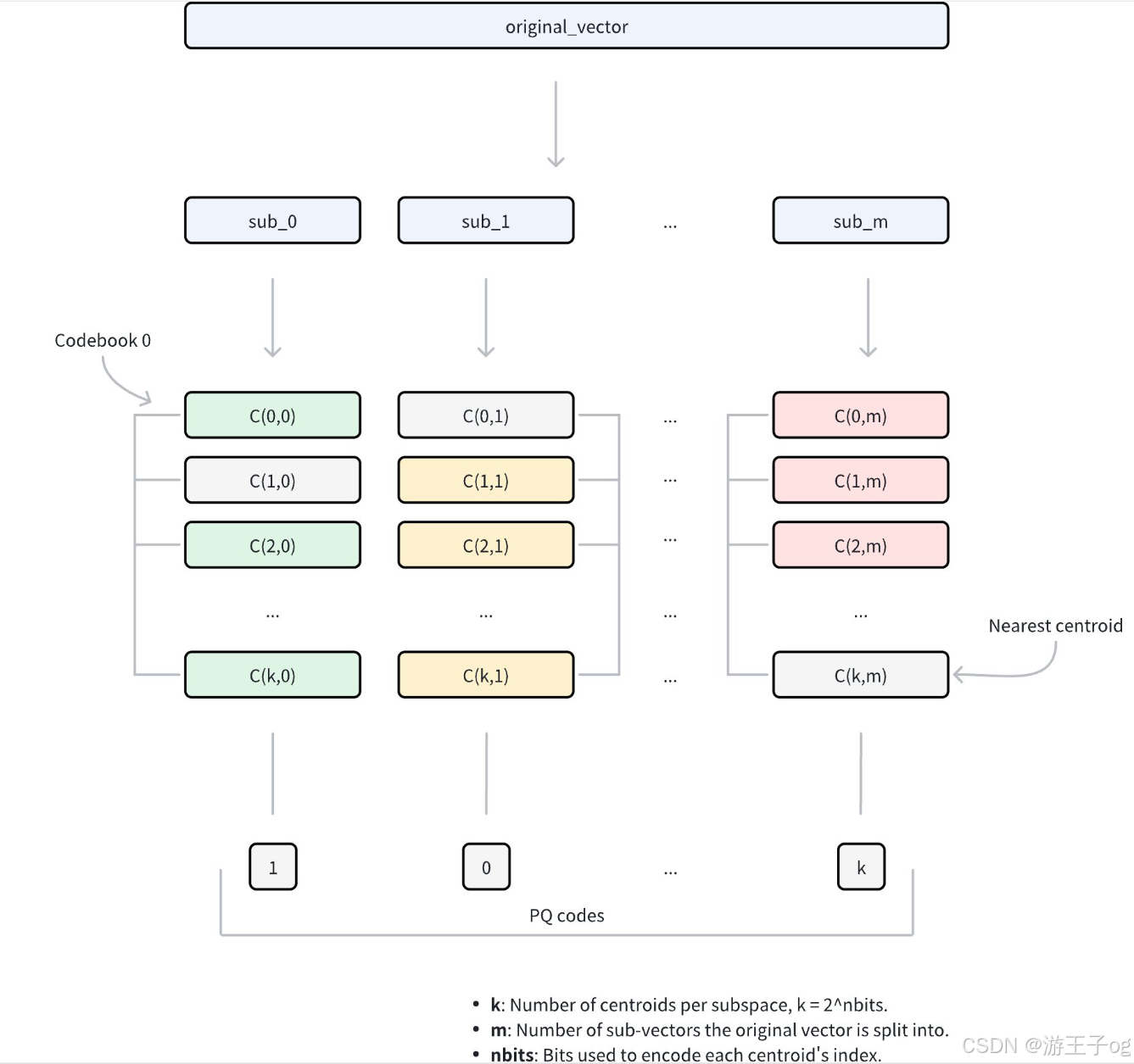
- 维度分解 :该算法首先将每个高维向量分解为
m大小相等的子向量。这种分解将原始的 D 维空间转换为m不相交的子空间,其中每个子空间包含D/m 维。参数m控制分解的粒度,并直接影响压缩比。 - 子空间编码本生成 :在每个子空间内,算法应用k-means 聚类来学习一组代表性向量(中心点)。这些中心点集合起来就形成了该子空间的代码集。每个编码本中的中心点数量由参数
nbits决定,其中每个编码本包含2 nbits 中心点。例如,如果nbits = 8,每个编码本将包含 256 个中心点。每个中心点都有一个唯一的索引,索引位数为nbits。 - 向量 量化:对于原始向量中的每个子向量,PQ 使用特定的度量类型在相应的子空间内识别其最近的中心点。这一过程可有效地将每个子向量映射到编码本中与其最接近的代表向量。PQ 不存储完整的子向量坐标,只保留匹配中心点的索引。
- 压缩表示 :最终的压缩表示由
m索引组成,每个子空间一个索引,统称为PQ 编码 。这种编码方式将存储需求从D × 32 位(假设为 32 位浮点数)减少到m ×nbits位,在保留近似向量距离能力的同时实现了大幅压缩。
考虑一个使用 32 位浮点数的D = 128 维向量。在 PQ 参数m = 64 (子向量)和nbits = 8 (因此k = 2 8 = 每个子空间256 个中心点)的情况下,我们可以比较存储需求:
- 原始向量:128 维 × 32 位 = 4,096 位
- PQ 压缩向量:64 个子向量 × 8 位 = 512 位
这意味着存储需求减少了 8 倍。
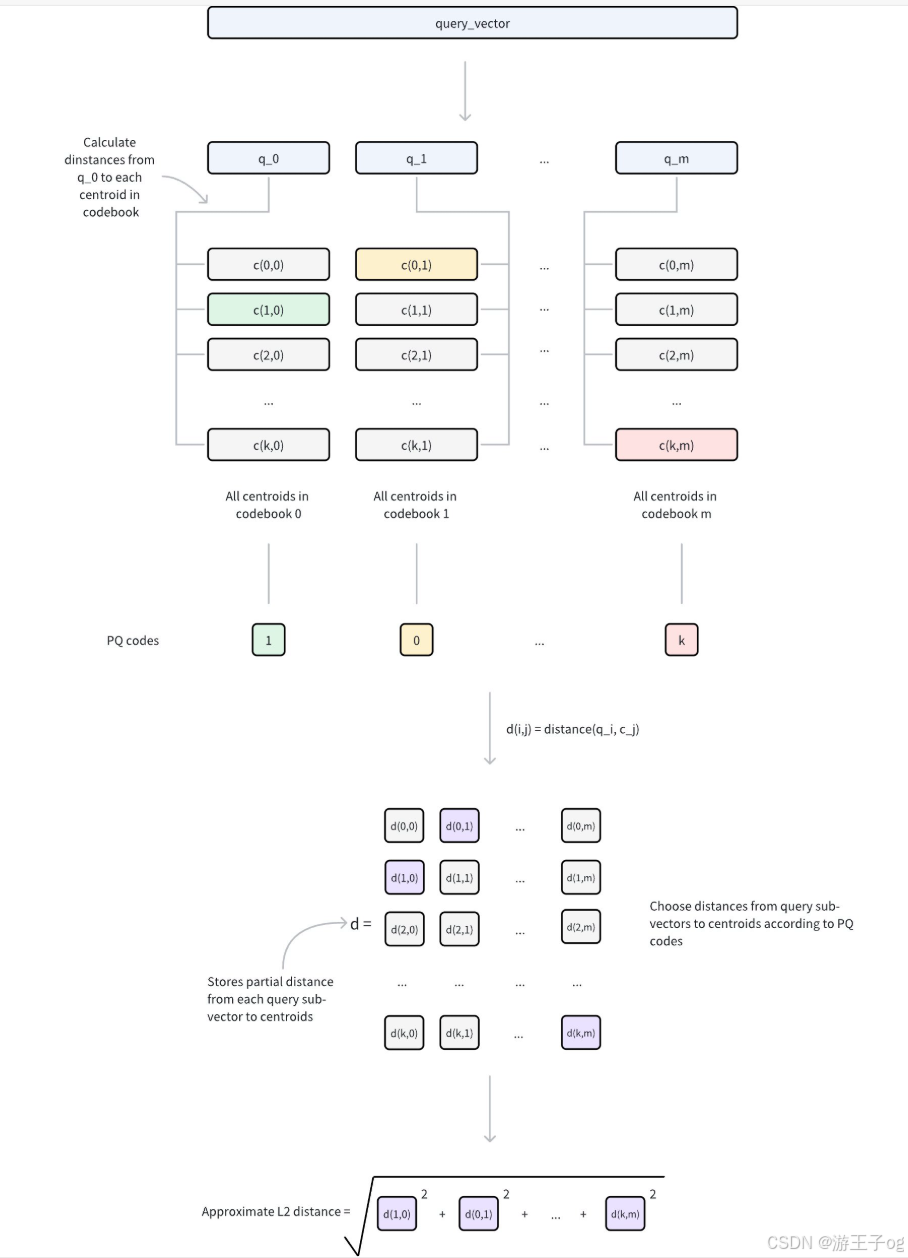
使用 PQ 计算距离
在使用查询向量进行相似性搜索时,PQ 可通过以下步骤实现高效的距离计算:
- 查询预处理
- 将查询向量分解为
m个子向量,与原始 PQ 分解结构相匹配。 - 对于每个查询子向量及其对应的编码本(包含2 nbits 中心点),计算并存储与所有中心点的距离。
- 这将生成
m查找表,其中每个表包含2 nbits 距离。
-
距离近似
对于任何由 PQ 代码表示的数据库向量,其与查询向量的近似距离计算如下:
- 对于
m的每个子向量,使用存储的中心点索引从相应的查找表中检索预先计算的距离。 - 将这些
m距离相加,得出基于特定度量类型(如欧氏距离)的近似距离。
1.1.3 IVF + PQ
IVF_PQ 索引结合了IVF 和PQ的优势,可加快搜索速度。这一过程分为两个步骤:
- 利用 IVF 进行粗过滤:IVF 将向量空间划分为簇,缩小了搜索范围。该算法不评估整个数据集,而只关注与查询向量最接近的簇。
- 与 PQ 进行细粒度比较:在选定的簇内,PQ 使用压缩和量化的向量表示来快速计算近似距离。
控制IVF 和 PQ 算法的参数对IVF_PQ索引的性能影响很大。调整这些参数对特定数据集和应用获得最佳结果至关重要。
1.2 建立索引
要在 Milvus 中的向量场上建立IVF_PQ 索引,请使用add_index() 方法,指定index_type,metric_type, 以及索引的附加参数。
python
from pymilvus import MilvusClient
# 准备索引构建参数
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # 要索引的向量字段的名称
index_type="IVF_PQ", # 要创建的索引类型
index_name="vector_index", # 要创建的索引的名称
metric_type="L2", # 用于度量相似性的度量类型
params={
"m": 4, # 将每个向量分割成的子向量的个数
} # 索引建立参数
)在此配置中
index_type:要建立的索引类型。在本例中,将值设为IVF_PQ。metric_type:用于计算向量间距离的方法。支持的值包括COSINE,L2, 和IP。params:用于建立索引的附加配置选项。m:将向量分割成的子向量个数。
配置好索引参数后,可直接使用create_index() 方法或在create_collection 方法中传递索引参数来创建索引。
1.3 在索引上搜索
建立索引并插入实体后,就可以在索引上执行相似性搜索。
python
search_params = {
"params": {
"nprobe": 10, # 要搜索的集群数
}
}
res = MilvusClient.search(
collection_name="your_collection_name", # 集合名称
anns_field="vector_field", # 向量字段名
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # 查询向量
limit=3, # 返回TopK结果
search_params=search_params
)1.4 索引参数
1.4.1 索引建立参数
下表列出了建立索引时可在params 中配置的参数。
| 参数 | 说明 | 值范围 | 调整建议 | |
|---|---|---|---|---|
| IVF | nlist |
在索引创建过程中使用 k-means 算法创建的簇数。 | 类型 : 整数整数范围:1, 65536 默认值 :128 |
nlist 值越大,创建的簇越精细,召回率越高,但会增加索引构建时间。请根据数据集大小和可用资源进行优化。大多数情况下,我们建议在此范围内设置值:32, 4096. |
| PQ | m |
在量化过程中将每个高维向量分成的子向量数(用于量化)。 | 类型 : 整数整数范围: 1, 65536\[1, 65536 默认值:无 | m m 必须是向量维数*(D* ) 的除数,以确保正确分解。通常推荐的值是m = D/2。 在大多数情况下,我们建议在此范围内设置一个值:D/8,D。 |
| PQ | nbits |
用于以压缩形式表示每个子向量中心点索引的比特数。它直接决定了每个编码本的大小。每个编码本将包含 2\^{textit{nbits}} 的中心点。例如,如果nbits 设置为 8,则每个子向量将由一个 8 位的中心点索引表示。这样,该子向量的编码本中就有 2^8$ (256) 个可能的中心点。 |
类型: 整数整数1, 64 默认值 :8 |
nbits 值越大,编码本越大,可能会更精确地表示原始向量。不过,这也意味着要使用更多比特来存储每个索引,从而导致压缩率降低。在大多数情况下,我们建议在此范围内设置一个值:1, 16. |
1.4.2 特定于索引的搜索参数
下表列出了在search_params.params 中搜索索引时可以配置的参数。
| 参数 | 说明 | 值范围 | 调整建议 | |
|---|---|---|---|---|
| IVF | nprobe |
搜索候选集群的集群数。 | 类型 : 整数整数范围 [1,nlist] 默认值 :8 |
数值越大,搜索的簇数越多,搜索范围扩大,召回率提高,但代价是查询延迟增加。设置nprobe 与nlist 成比例,以平衡速度和准确性。 在大多数情况下,我们建议您在此范围内设置值:1,nlist。 |
2 HNSW
HNSW 索引是一种基于图的 索引算法,可以提高搜索高维浮动向量时的性能。它具有出色的 搜索精度和低 延迟,但需要较高的内存开销来维护其分层图结构。
2.1 概览
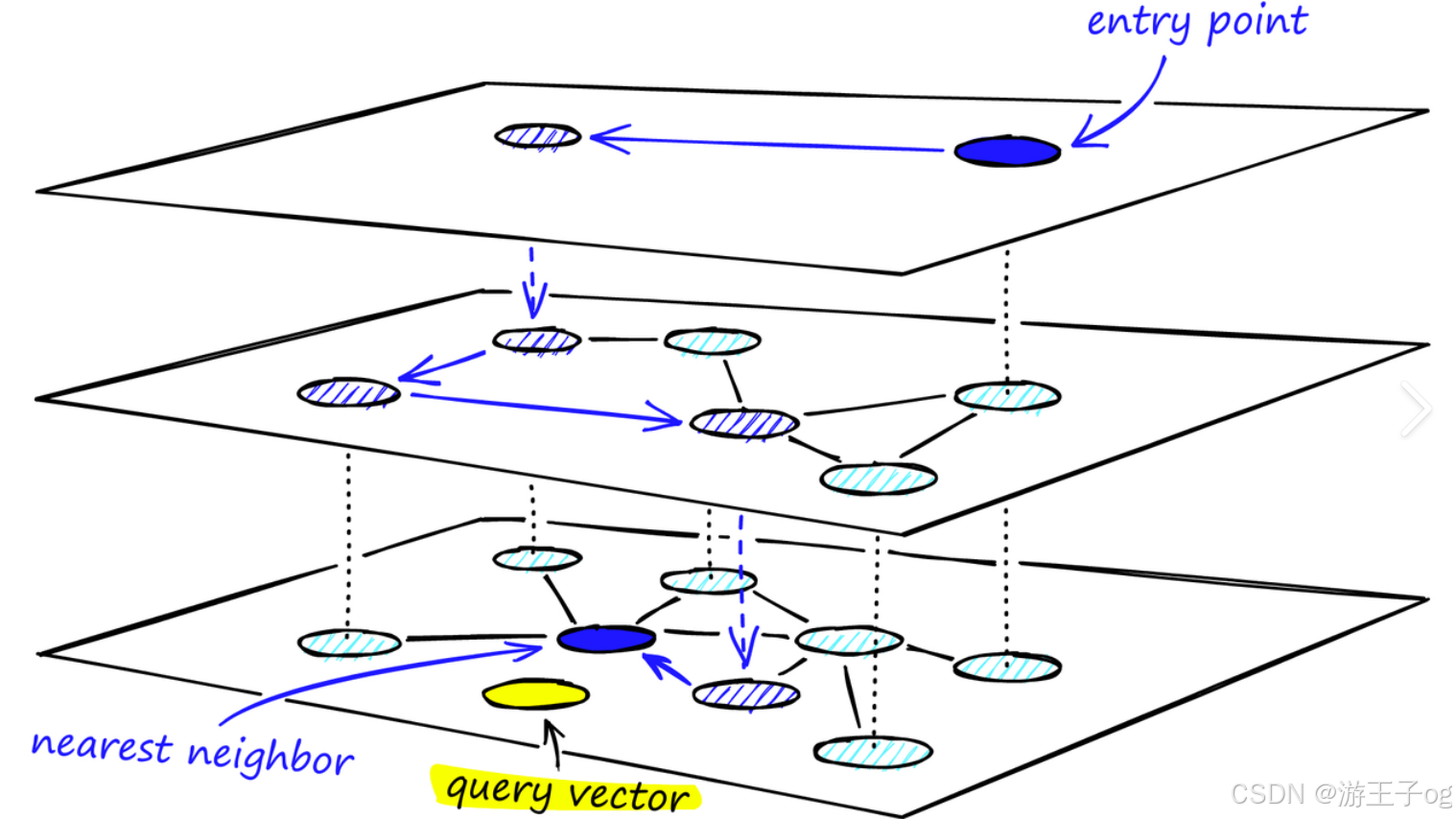
HNSW算法构建了一个多层图,有点像不同缩放级别的地图。底层 包含所有数据点,而上层则由从底层采样的数据点子集组成。
在这种层次结构中,每一层都包含代表数据点的节点,节点之间由表示其接近程度的边连接。上层提供远距离跳转,以快速接近目标,而下层则进行细粒度搜索,以获得最准确的结果。
下面是它的工作原理:
- 入口点:搜索从顶层的一个固定入口点开始,该入口点是图中的一个预定节点。
- 贪婪搜索:算法贪婪地移动到当前层的最近邻居,直到无法再接近查询向量为止。上层起到导航作用,作为粗过滤器,为下层的精细搜索找到潜在的入口点。
- 层层下降 :一旦当前层达到局部最小值,算法就会利用预先建立的连接跳转到下层,并重复贪婪搜索。
- 最后 细化:这一过程一直持续到最底层,在最底层进行最后的细化步骤,找出最近的邻居。
HNSW 的性能取决于控制图结构和搜索行为的几个关键参数。这些参数包括
M:图中每个节点在层次结构的每个层级所能拥有的最大边数或连接数。M越高,图的密度就越大,搜索结果的召回率和准确率也就越高,因为有更多的路径可以探索,但同时也会消耗更多内存,并由于连接数的增加而减慢插入时间。efConstruction:索引构建过程中考虑的候选节点数量。efConstruction越高,图的质量越好,但需要更多时间来构建。ef:搜索过程中评估的邻居数量。增加ef可以提高找到最近邻居的可能性,但会减慢搜索过程。
2.2 建立索引
要在 Milvus 中的向量场上建立HNSW 索引,请使用add_index() 方法,为索引指定index_type,metric_type, 以及附加参数。
python
from pymilvus import MilvusClient
# 准备索引构建参数
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # 要索引的向量字段的名称
index_type="HNSW", # 要创建的索引类型
index_name="vector_index", # 要创建的索引的名称
metric_type="L2", # 用于度量相似性的度量类型
params={
"M": 64, # 图中每个节点可以连接的最大邻居数
"efConstruction": 100 # 在索引构建期间考虑连接的候选邻居数
} # 索引建立参数
)在此配置中
-
index_type:要建立的索引类型。在本例中,将值设为HNSW。 -
metric_type:用于计算向量间距离的方法。支持的值包括COSINE,L2, 和IP。 -
params:用于建立索引的附加配置选项。-
M:每个节点可连接的最大邻居数量。 -
efConstruction:索引构建过程中考虑连接的候选邻居数量。
-
配置好索引参数后,可直接使用create_index() 方法或在create_collection 方法中传递索引参数来创建索引。
2.3 在索引上搜索
建立索引并插入实体后,就可以在索引上执行相似性搜索。
python
search_params = {
"params": {
"ef": 10, # 在搜索过程中要考虑的邻居数量
}
}
res = MilvusClient.search(
collection_name="your_collection_name", # 集合名称
anns_field="vector_field", # 向量字段名
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # 查询向量
limit=10, # 返回TopK结果
search_params=search_params
)2.4 索引参数
2.4.1 索引建立参数
下表列出了建立索引时可在params 中配置的参数。
| 参数 | 说明 | 值范围 | 调整建议 |
|---|---|---|---|
M |
图中每个节点可拥有的最大连接数(或边),包括出边和入边。该参数直接影响索引构建和搜索。 | 类型 : 整数整数范围:2, 2048 默认值 :30 (每个节点最多有 30 条出边和 30 条入边) |
较大的M 通常会提高准确率 ,但会增加内存开销 ,并减慢索引构建和搜索速度 。对于高维度数据集或高召回率至关重要时,可考虑提高M 。 当内存使用和搜索速度是首要考虑因素时,可考虑降低M 。 在大多数情况下,我们建议您在此范围内设置一个值:5, 100. |
efConstruction |
索引构建过程中考虑连接的候选邻居数量。每个新元素都会评估一个更大的候选池,但实际建立的最大连接数仍受M 限制。 |
类型 : 整数整数范围 :[1,int_max] 默认值 :360 |
efConstruction 越高,索引 越准确 ,因为会探索更多潜在连接。不过,这也会导致建立索引的时间延长和内存使用量增加 。考虑增加efConstruction 以提高准确性,尤其是在索引时间不太重要的情况下。 在资源紧张的情况下,可考虑降低efConstruction ,以加快索引构建速度。 在大多数情况下,我们建议在此范围内设置一个值:50, 500. |
2.4.2 特定于索引的搜索参数
下表列出了在索引上搜素时可在search_params.params 中配置的参数。
| 参数 | 说明 | 值范围 | 调整建议 |
|---|---|---|---|
ef |
控制近邻检索时的搜索范围。它决定访问多少节点并将其评估为潜在近邻。 该参数只影响搜索过程,并且只适用于图形的底层。 | 类型 : 整数整数范围 :[1,int_max] 默认值 :limit(返回的前 K 个近邻) | ef 越大,通常搜索精度越高 ,因为会考虑更多的潜在近邻。不过,这也会增加搜索时间 。如果实现高召回率至关重要,而搜索速度则不那么重要,则可考虑提高ef 。 考虑降低ef 以优先提高搜索速度,尤其是在可以接受稍微降低准确率的情况下。 在大多数情况下,我们建议您在此范围内设置一个值:K,10K。 |