Hadoop了解
Hadoop 是 Apache 基金会开发的一个开源分布式计算平台,主要用于存储和处理大规模数据集。
它能让用户在不了解分布式系统底层细节的情况下,轻松进行分布式程序的开发,将应用程序自动部署到由大量普通机器组成的集群上进行高效运算。下面为你详细介绍其应用场景和作用
hadoop生态系统包含了很多组件,主要的一个生态系统体系: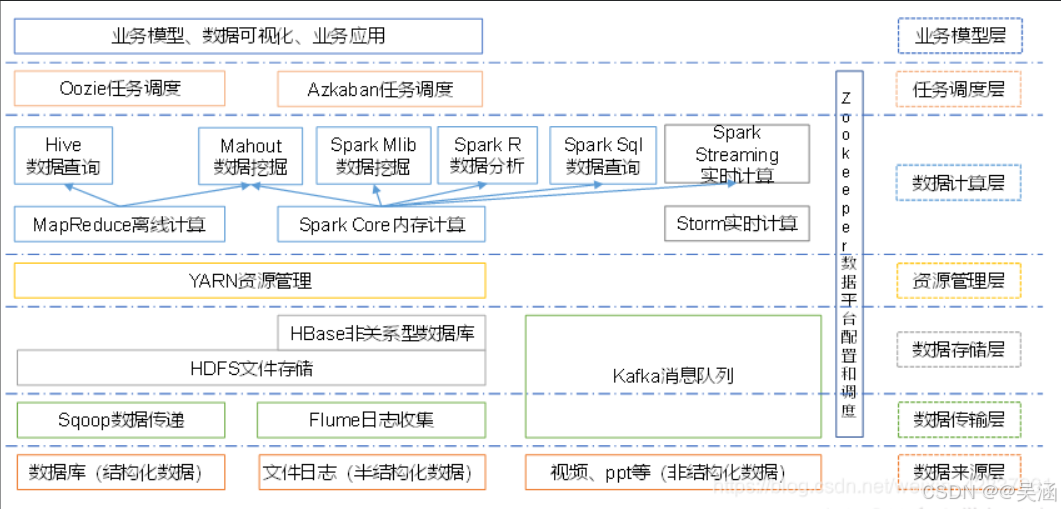
核心组件介绍
HDFS
Hadoop 分布式文件系统(HDFS): 是hadoop的存储基石,具备高容错性,可以将海量的数据分散存储在多个节点,数据会被分割为多个数据块,每个数据块会有多个副本,分布在不同的节点上,这样即使部分节点出现故障,数据也不会丢失,保证了数据的安全性和可靠性,支持流式访问.
- NameNode: 存储文件的元数据,运行在master node节点上,负责命名空间管理和文件访问控制,
- DataNode: 在本地文件系统存储文件块数据,以及数据校验和,运行在slave节点上,
- Secondary DataNode: 用来监控HDFS状态
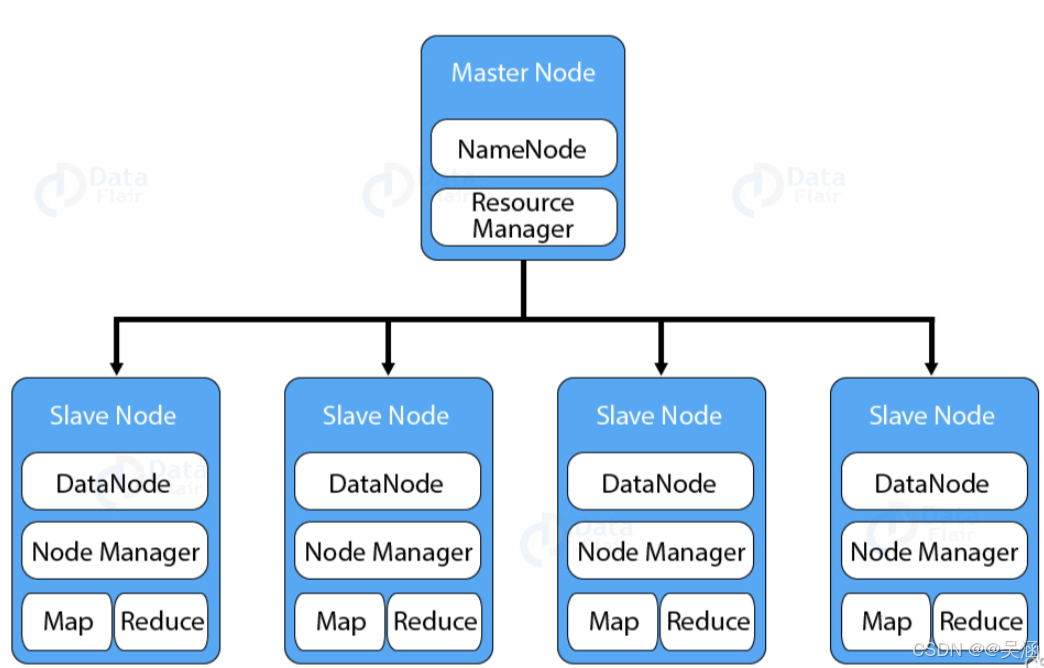
MapReduce
是一种编程模型,用于计算海量数据,并把计算任务分割成多个在几群上并行计算独立运行的task,MapReduce 是 Hadoop的核心,它会把计算任务移动到离数据最近的地方进行执行,因为移动大量数据是非常耗费资源的。主要的处理过程分为三个步骤:
- map阶段: 在这个里,针对输入的数据会被分割为多个小块,每个小块由一个map任务处理,map任务会读取输入的数据然后转为键值对的形式输出,这个过程可以理解为对原始数据进行初步的过滤.
- shuffle排序阶段: 这个阶段会对map阶段处理之后的数据进行排序和分组,将相同的键的值归类到一起,
- reduce(聚合): 这个阶段每个reduce任务接受一组相同的键值列表,并对这组值执行指定规则的汇总或聚合操作.然后产生新的输出.
YARN
Yarn :是一个资源管理系统,其作用就是把资源管理和任务调度/监控功分割成不同的进程,Yarn 有一个全局的资源管理器叫 ResourceManager,每个 application 都有一个 ApplicationMaster 进程。一个 application 可能是一个单独的 job 或者是 job 的 DAG (有向无环图)。
在 Yarn 内部有两个守护进程:
• ResourceManager :负责给 application 分配资源
• NodeManager :负责监控容器使用资源情况,并把资源使用情况报告给 ResourceManager。这里所说的资源一般是指CPU、内存、磁盘、网络等。
ApplicationMaster 负责从 ResourceManager 申请资源,并与 NodeManager 一起对任务做持续监控工作。
Yarn 具有下面这些特性:
• 多租户:Yarn允许在同样的 Hadoop数据集使用多种访问引擎。这些访问引擎可能是批处理,实时处理,迭代处理等;
• 集群利用率:在资源自动分配的情况下,跟早期的Hadoop 版本相比,Yarn拥有更高的集群利用率;
• 可扩展性:Yarn可以根据实际需求扩展到几千个节点,多个独立的集群可以联结成一个更大的集群;
• 兼容性:Hadoop 1.x 的 MapReduce 应用程序可以不做任何改动运行在 Yarn集群上面。
hadoop的工作方式
hadoop的主从工作方式
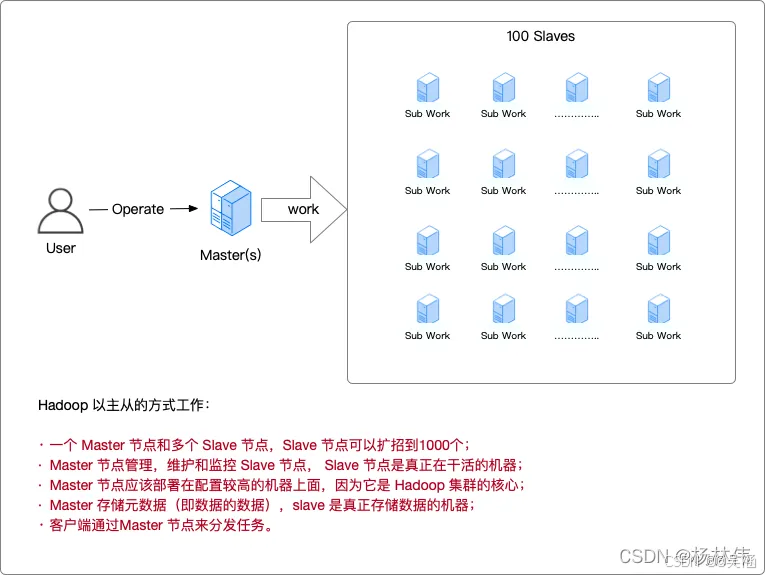
主从的架构:
- 一个master节点可以和多个slave节点交互
- master节点管理,维护和监控slave节点,slave是任务处理的机器.
- master节点是集群的核心
- master存储元数据,slave存储业务实际数据
- 通过master向slave节点分发任务
hadoop的守护进程
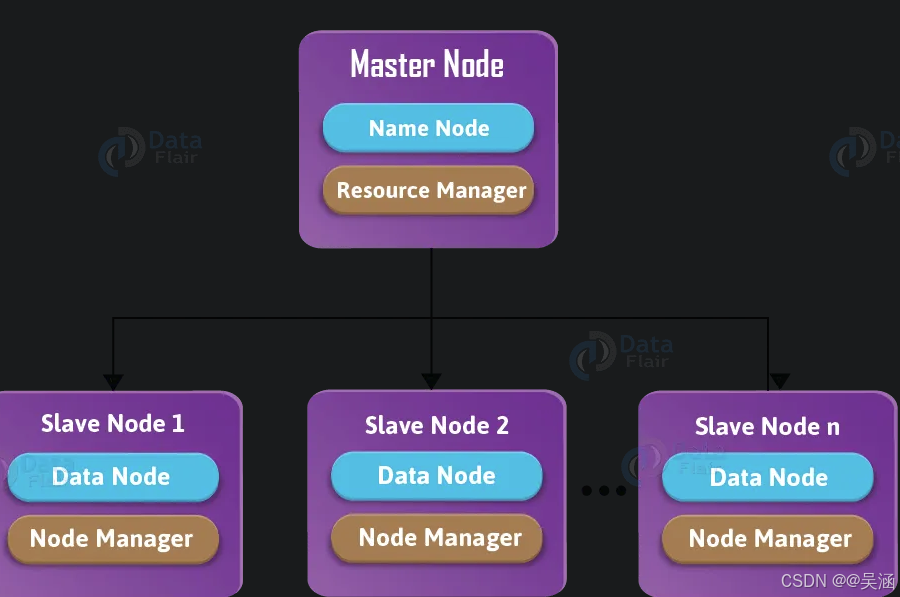
通过这个图的展示可以看出在hadoop中主要有4个守护进程:
- namenode: 它是HDFS运行在Master节点守护进程
- datanode: 它是 HDFS 运行在Slave节点守护进程。
- resourcemanager: 是yarn运行在master节点的守护进程
- NodeManager: 是yarn运行在slave节点的守护进程
除了这些,可能还会有 secondary NameNode,standby NameNode,Job HistoryServer 等进程
通过上面的架构图可以了解到在这种架构下,对于master节点是没有高可用的,集群会很不稳定面临单点的风险,下面介绍一下再hadoop中实现高可用的方案.
我们知道 NameNode 上存储的是 HDFS 上所有的元数据信息,因此最关键的问题在于 NameNode 挂了一个,备份的要及时顶上,这就意味着我们要把所有的元数据都同步到备份节点。好,接下来我们考虑如何同步呢?每次 HDFS 写入一个文件,都要同步写 NameNode 和其备份节点吗?如果备份节点挂了就会写失败?显然不能这样,只能是异步来同步元数据。如果 NameNode 刚好宕机却没有将元数据异步写入到备份节点呢?那这部分信息岂不是丢失了?这个问题就自然要引入第三方的存储了,在 HA 方案中叫做"共享存储"。每次写文件时,需要将日志同步写入共享存储,这个步骤成功才能认定写文件成功。然后备份节点定期从共享存储同步日志,以便进行主备切换。
Hadoop NameNode HA原理
核心组件介绍:
Namenode主备切换主要是由ZKFailoverController,HealthMonitor和ActiveStandbyElector这个3个组件来协同实现:
- ZKFailoverController作为Namenode上一个独立的进程启动(在hdfs启动脚本之中的进程为zkfc),启动的时候会创建HealthMonitor 和ActiveStandbyElector 组件,会进行整体协调负责管理和监控namenode的状态并与zookerper进行交互.
- HealthMonitor:是对本地的namenode进行健康状态检测,检测状态,状态反馈,根据检测结果向zkfc进行汇报.它可以检测多种故障,包括硬件故障、软件故障、网络故障等
- ActiveStandbyElector: 在zookerper的协调下进行active namenode的选举.每个 Standby NameNode 的 ActiveStandbyElector 会尝试在 ZooKeeper 中创建一个特定的节点,如果创建成功,则该 NameNode 成为新的 Active NameNode;如果创建失败,则表示有其他 NameNode 已经成功竞选为 Active NameNode,该 NameNode 继续保持 Standby 状态。在选举完成后,ActiveStandbyElector 会确保新的 Active NameNode 和其他 Standby NameNode 之间的状态同步,保证整个集群的一致性和稳定性
hadoop在linux下的安装部署
hadoop的运行模式
Hadoop 有三种运行模式,分别是本地(单机)模式、伪分布式模式和完全分布式模式,下面为详细介绍它们的区别;
本地模式
特点:
简单配置:这是 Hadoop 最基础的运行模式,几乎不需要额外配置。它把所有组件都运行在单个 Java 虚拟机中,就像普通的 Java 程序一样。
无分布式特性:此模式下不涉及数据的分布式存储与处理,主要用于开发调试简单的 MapReduce 程序或者进行代码测试。
数据存储:数据一般存于本地文件系统,而非 Hadoop 分布式文件系统(HDFS)
适用场景
适合初学者快速上手 Hadoop,在学习和开发初期用来验证 MapReduce 程序逻辑的正确性。
进行小规模数据的测试和实验。
伪分布式模式
特点:
模拟分布式环境:虽然所有 Hadoop 守护进程(如 NameNode、DataNode、ResourceManager、NodeManager 等)都在一台机器上运行,但它们以独立的 Java 进程形式存在,能够模拟分布式环境的运行机制。
使用 HDFS:数据存储采用 HDFS,可体验 Hadoop 分布式文件系统的功能,如数据的复制、容错等。
配置相对简单:相较于完全分布式模式,伪分布式模式的配置较为简便,通常只需对几个关键配置文件进行修改。
适用场景:
用于开发和测试分布式程序,让开发者在单机上就能模拟分布式环境,进行程序的调试和优化。
学习 Hadoop 各个组件的工作原理和交互方式。
完全分布式模式
特点
多节点集群:由多个物理节点组成集群,每个节点承担不同的角色,如 NameNode、DataNode、ResourceManager、NodeManager 等,各个节点之间通过网络进行通信和协作。
高可靠性和扩展性:可以根据实际需求添加或减少节点,以提高系统的处理能力和存储容量。同时,HDFS 的数据冗余机制和 YARN 的资源管理机制确保了系统的高可靠性。
复杂配置和管理:需要对每个节点进行详细的配置和管理,包括网络配置、节点间的通信、数据同步等,对运维人员的技术要求较高。
未完待续~