图中展示的是在Jupyter Notebook环境下的Python代码及运行结果。代码利用 seaborn 和 matplotlib 库,以 datal 数据集为基础,绘制上下两个子图。上方子图呈现各店铺中各大类的销售量,下方子图展示各店铺中各大类的销售额,通过条形图展示不同店铺和商品大类组合下的销售数量与金额情况 ,并注释了 estimator 参数作用(用于指定聚合函数,这里是求和) 。
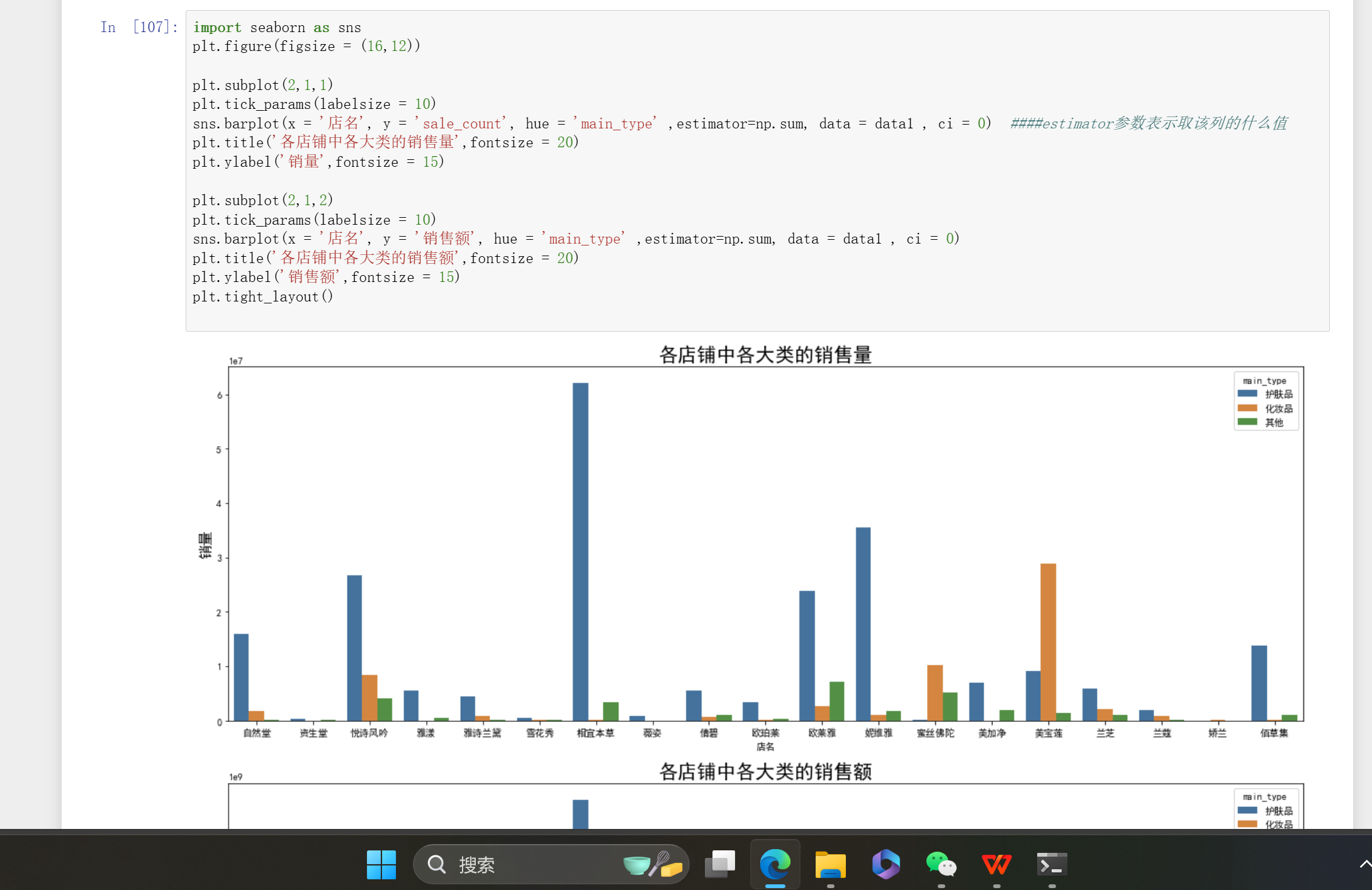
在 sns.barplot ( seaborn 库中的函数,用于绘制柱状图)中, estimator 参数用于指定对 y 轴数据进行何种聚合操作 。
这里 estimator = np.sum , np 是 numpy 库的常用别名, np.sum 表示求和函数。所以当 estimator = np.sum 时,它表示对 y 轴对应列(在第一个 barplot 中是 sale count 列,第二个 barplot 中是 销售额 列)的数据按照 x 轴( 店名 )和 hue ( sub_type )分组后进行求和操作。
总结: estimator = np.sum 表示对 y 轴对应列的数据按照 x 和 hue 分组后取总和值。
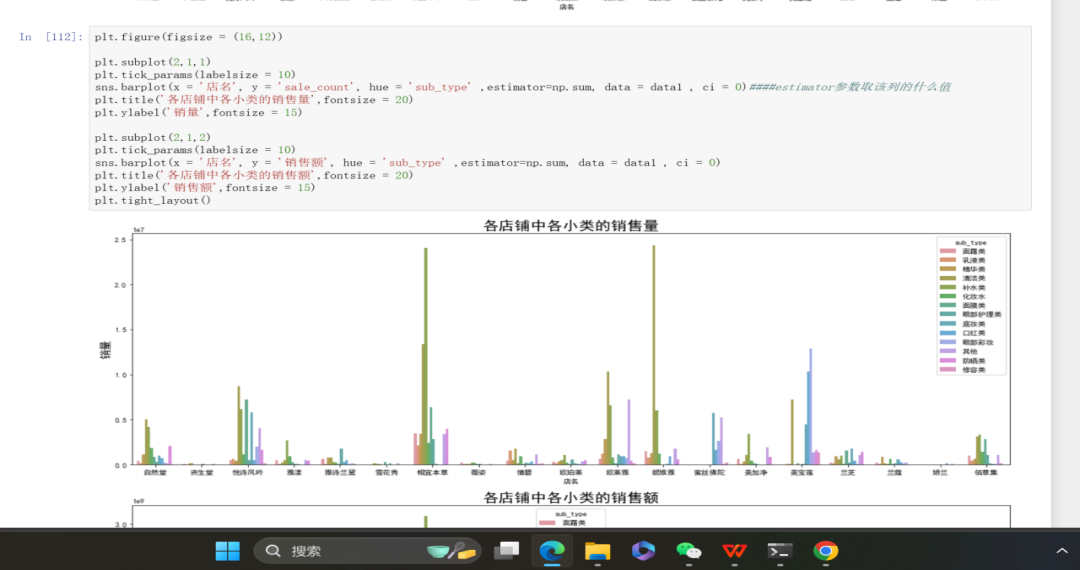
图中展示的是Jupyter Notebook里的Python代码及运行结果。代码使用 matplotlib 和 seaborn 库,创建一个两行一列的子图布局,分别绘制各小类中各店铺的销售量和销售额条形图 ,其中 sns.barplot 函数里的 estimator=np.sum 用于按店铺和小类分组对销售量、销售额求和聚合。同时,代码对图表的字体、标题等样式进行设置,还配有文字说明,阐述比较不同类别商品在各店铺销售量更有价值的原因 。
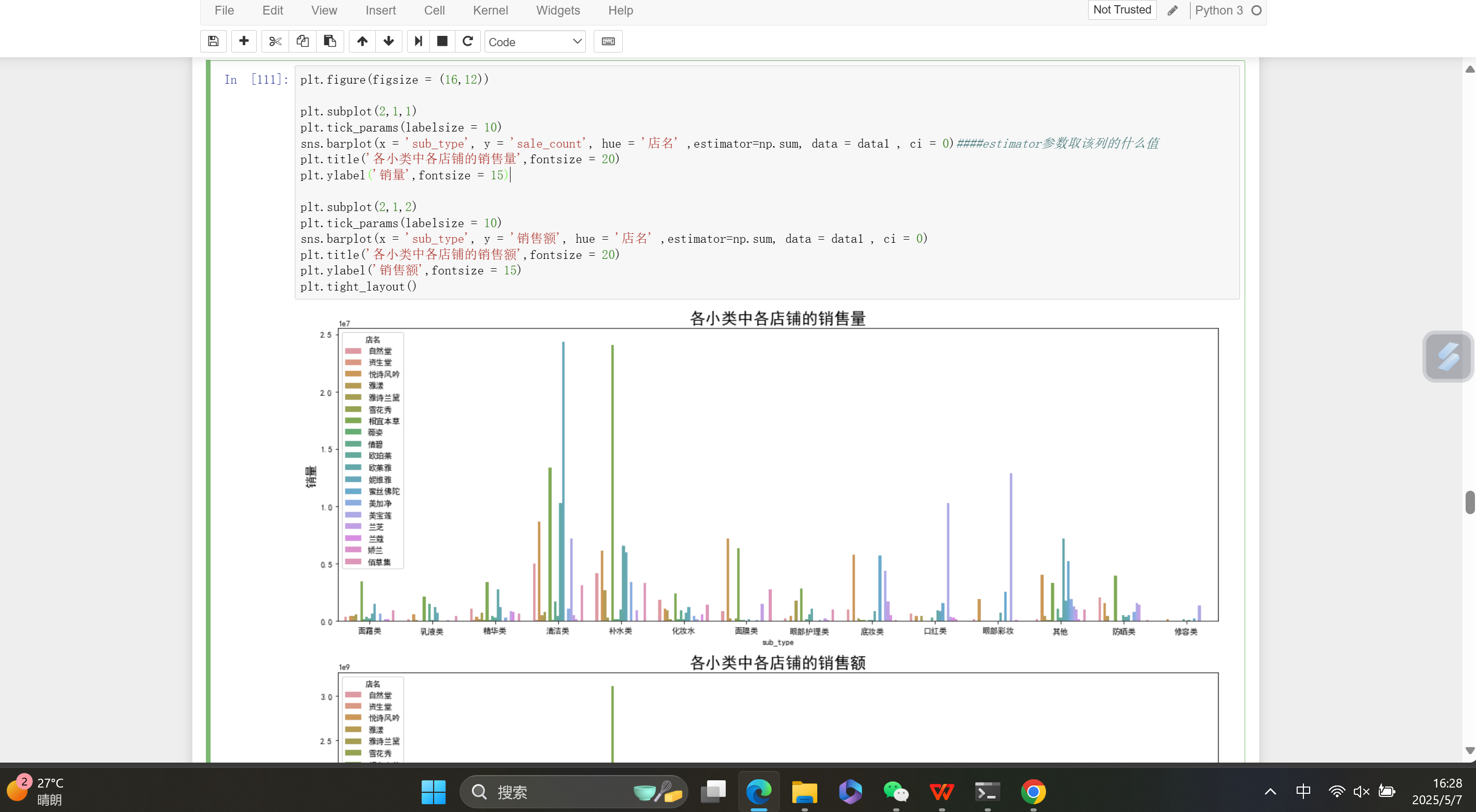
图中是Jupyter Notebook界面,代码位于单元格 In 23 。代码使用 matplotlib 库绘制饼图,通过 plt.figure 设置图形大小为 (16, 16) ,以 plt.subplot 构建2行2列的子图布局。代码根据数据集中"是否男士专用"字段,分别统计男士专用和非男士专用产品中各小类的销售量占比,以及男士专用产品的销售量、销售额占总销售量、总销售额的比例,并绘制对应的饼图展示,饼图添加了百分比标注,最后用 plt.tight_layout 调整布局。
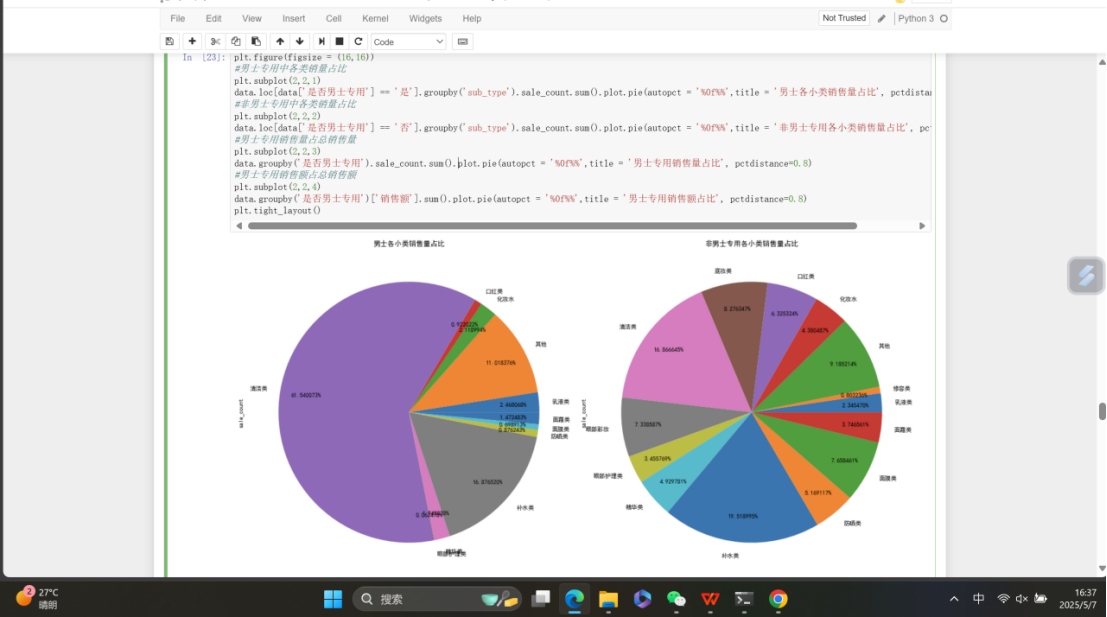
图中是Jupyter Notebook界面,单元格 In 119 中的Python代码,利用 matplotlib 和 seaborn 库进行数据可视化。代码先筛选出"是否男士专用"为"是"的数据存于 male_data ,随后设置图形大小为 (12, 8) ,绘制柱状图。柱状图以"店名"为 x 轴,"sale_count"(销售量)为 y 轴 ,"main_type"(商品大类)作为色调区分 ,通过 estimator=np.sum 对销售量求和聚合,展示各店男士专用商品销量情况 。图表标题为"各店男士专用商品销量" ,并设置了字体大小,还调整了布局防止元素重叠。图表下方文字说明男士专用护肤品销量前三是妮维雅、欧莱雅、相宜本草,且男士商品主要销量来自护肤品 。
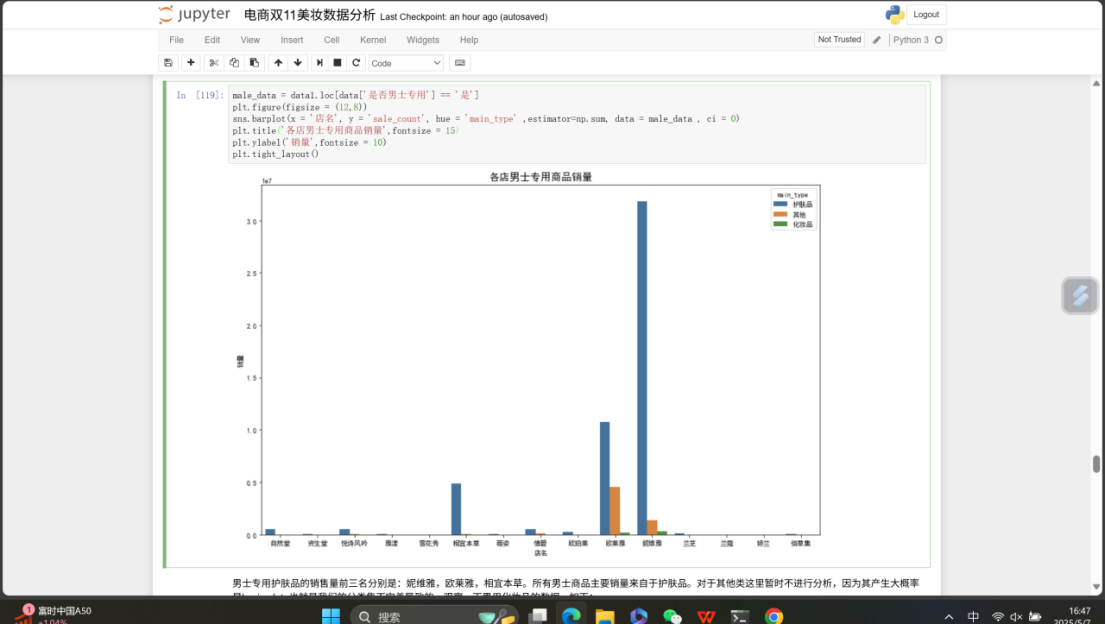
图中是Jupyter Notebook界面,呈现了关于电商美妆数据中男士专用商品的分析内容。文字说明指出男士专用护肤品销量前三是妮维雅、欧莱雅、相宜本草,且男士商品销量主要来自护肤品,其他类因分类集不完善暂不分析。
代码 In 209 使用 head() 方法展示 male_data 中 main_type 为"化妆品"的前几条数据,涉及产品更新时间、编号、名称、价格、销量、评论数、店名等信息,发现多为男用唇膏。代码 In 127 开始构建图形,设置大小为 (16, 12) ,准备绘制子图,计划按店名对男士专用商品销量求和并绘制条形图,以展示各店男士专用商品销量情况。
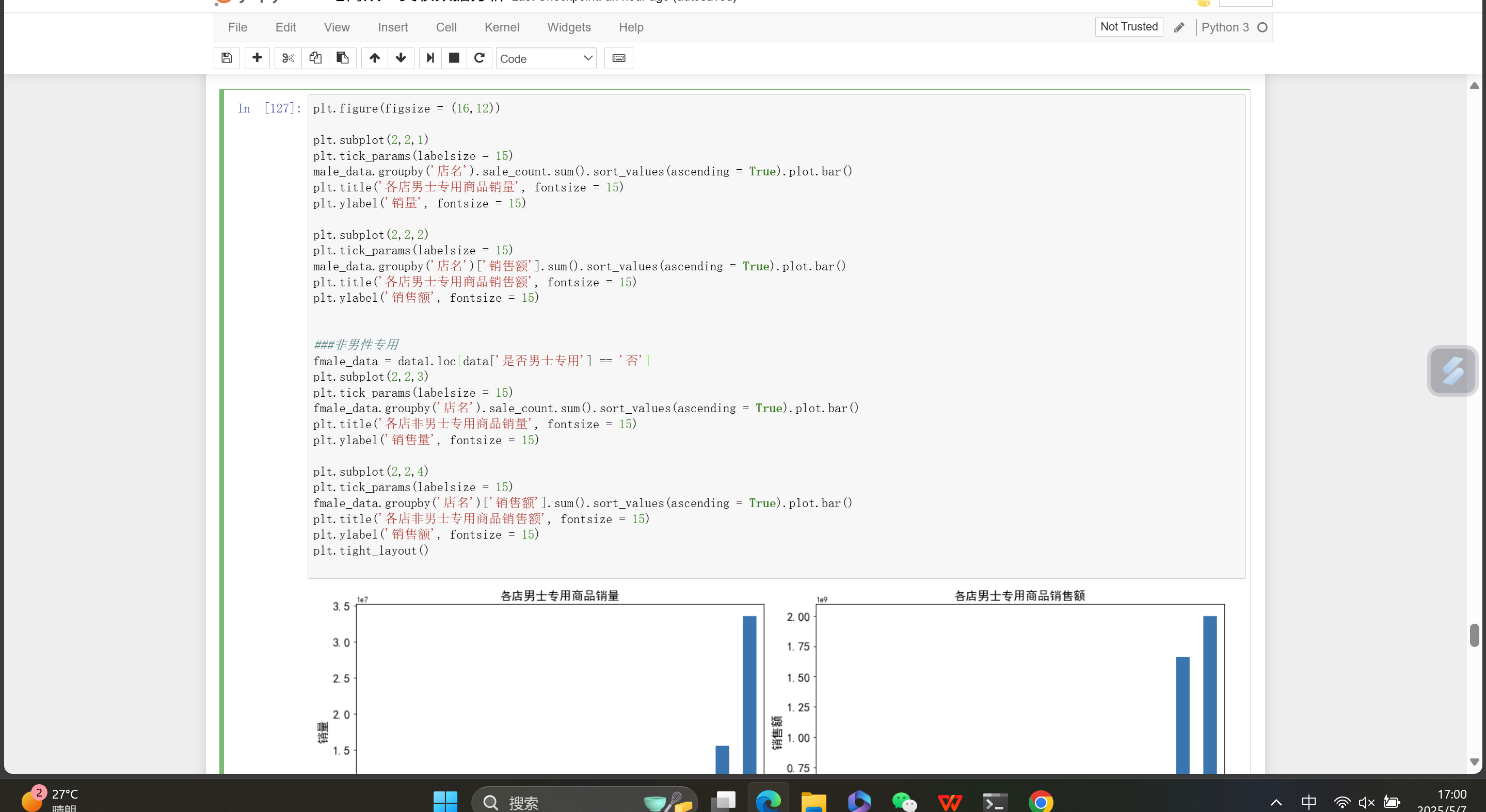
图中是Jupyter Notebook界面,展示了用于电商美妆数据分析的Python代码及部分运行结果。代码主要利用 matplotlib 库进行绘图:
-
首先设置图形大小为 (16, 12) ,构建2×2的子图布局。
-
针对男士专用商品,分别按店名对销售量( sale_count )和销售额进行求和,再按升序排序并绘制条形图,展示各店男士专用商品的销量和销售额情况。
-
接着筛选出非男士专用商品数据,同样按店名对销售量和销售额求和、排序后绘制条形图,呈现各店非男士专用商品的销量和销售额情况。最后使用 plt.tight_layout() 调整子图布局,避免元素重叠。已展示的运行结果为各店男士专用商品销量和销售额的条形图。
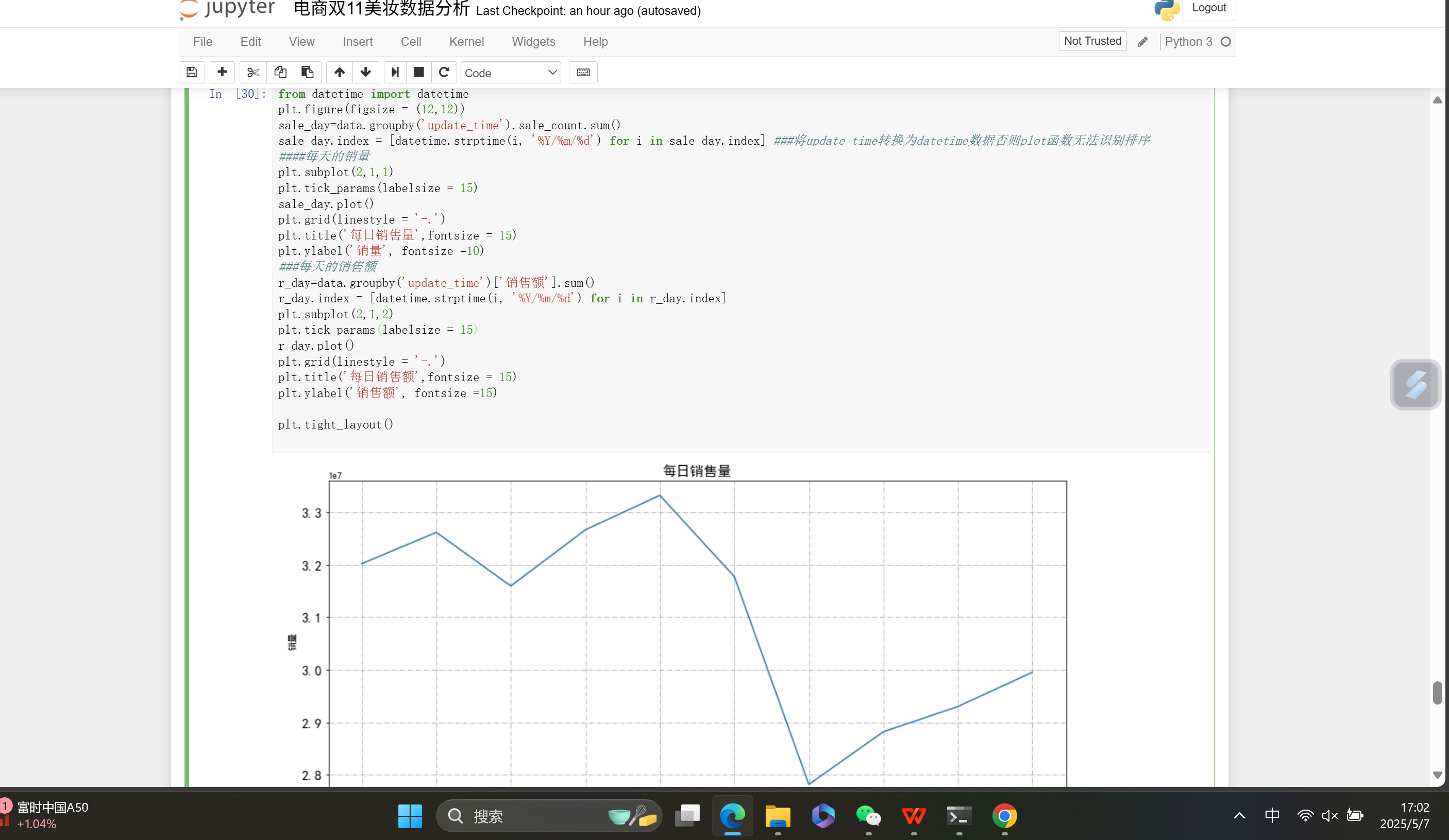
图中是Jupyter Notebook界面,单元格 In 130 的Python代码利用 matplotlib 库进行电商美妆数据可视化。代码从 datetime 模块导入 datetime 类,设置图形大小为 (12, 12) 。先按 update_time 对销售数据求和,将 update_time 转换为 datetime 格式后绘图,绘制每日销售量折线图,添加网格线,设置标题为"每日销售量" 、 y 轴标签为"销量" 。接着按 update_time 对销售额求和,同样转换时间格式后绘制每日销售额折线图,添加网格线,设置标题为"每日销售额" 、 y 轴标签为"销售额" ,最后用 plt.tight_layout 调整布局。界面还展示了"每日销售量"折线图的绘制结果。
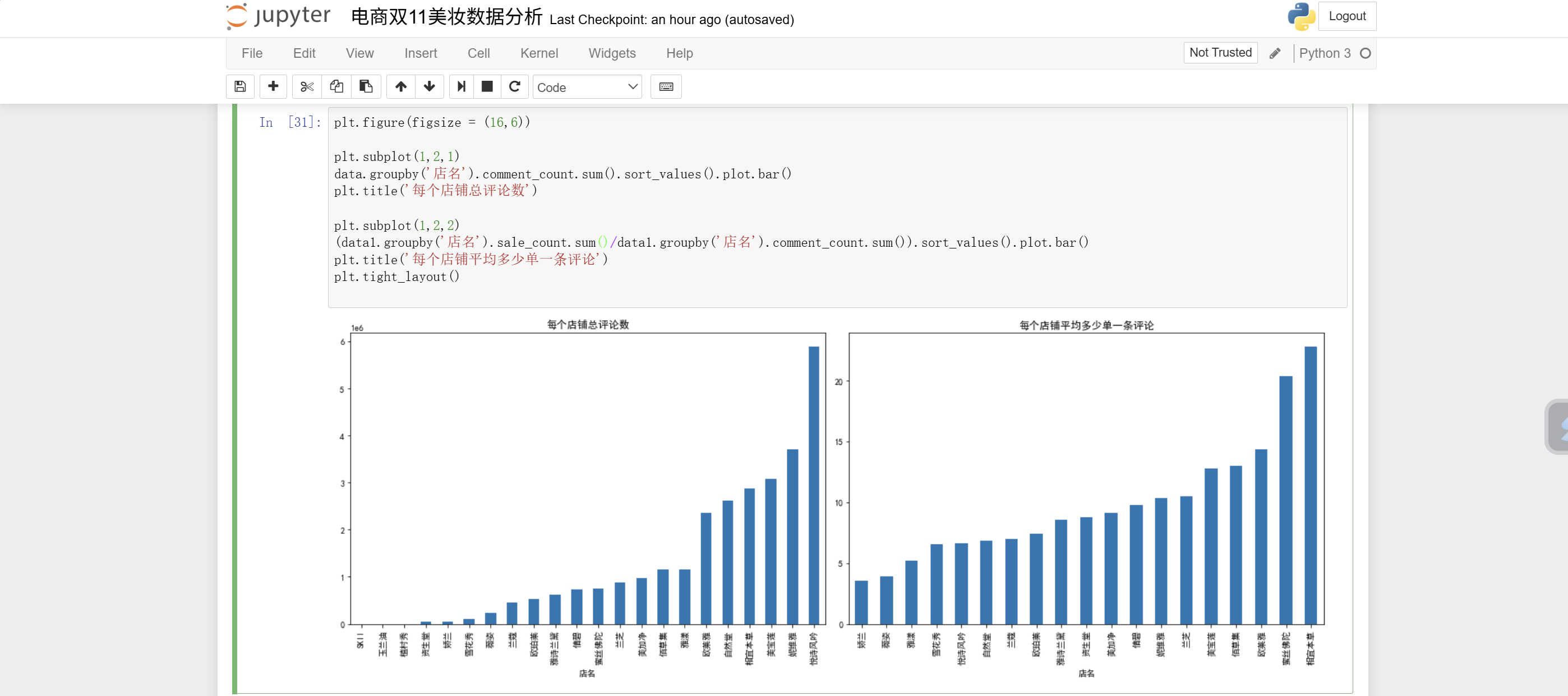
图中是Jupyter Notebook界面,展示了电商双11美妆数据分析的代码及图表。代码 In 31 利用 matplotlib 库,设置图形大小为 (16, 6) ,创建1行2列的子图布局。第一个子图按"店名"对 data 数据分组,统计各店铺总评论数并绘制升序柱状图,标题为"每个店铺总评论数";第二个子图对 datal 数据,用各店铺销售单数总和除以评论数总和,计算平均多少单一条评论,排序后绘制柱状图,标题为"每个店铺平均多少单一条评论",最后调整布局。下方文字分析悦诗风吟评论数高但销量排名不符,相宜本草销量高评论数低,探讨平均多少单一条评论指标与水军刷单问题的关联。
总结分析
- 平均每单价格低的店铺的总销量、销售额都高于均价更高的。价格便宜是消费者考虑的最多的一个点。销量最高的相宜本草的均价就很低,同时它的销售额也是最高额的。而均价较高的类中,只有雅诗兰黛的销售额相对客观。对于一些中高端商品,可以考虑适当降价来吸引更多消费者。而一些低端商品可以考虑多推广来提高知名度获取销量。
- 所有大类中,护肤品类的销量最高,其次是化妆品类。所有小类中,清洁类、补水类分别是销量的前二名。
- 男士专用的商品中,护肤品销量最高,而化妆品类中主要是唇膏。并且妮维雅占据了男士专用的大部分市场。
- 平均每多少单一条评论这个指标,相宜本草过高了,是评论数最多的悦诗风吟的4倍。可能存在刷单等现象。
- 不同的日期销量也不同。在双11销量反而有一个剧烈的下滑。原因可能是预热活动导致了消费者提前消费,并且由于消费者往往会主观的考虑到双11当天的网络、平台会卡顿,一般都会提前下单来避免"高峰",虽然这个高峰并不存在。而在双11之后销量又有了小幅度的增长,可能跟商家的持续优惠等各种活动有关。所以商家应该把目光放在双11之前,尽量的吸引消费者消费来增加销量,不要局限于双11当天。在双11之后可以通过类似双11购物返满减卷,来刺激二次消费。