基于Spark的抖音数据分析热度预测系统技术博客
本文详细介绍了一个基于Apache Spark的抖音数据分析与热度预测系统的设计与实现。该系统集成了数据爬取、大数据处理、机器学习预测和可视化展示等完整功能模块。
📋 目录
🎯 项目概述
项目背景
随着短视频行业的快速发展,抖音作为头部平台每天产生海量数据。如何从这些数据中挖掘有价值的信息,预测视频热度趋势,为内容创作者和平台运营提供决策支持,成为了一项重要的技术挑战。
项目目标
- 构建完整的抖音数据采集体系
- 实现基于Spark的大规模数据处理
- 建立机器学习模型预测视频热度
- 提供直观的数据可视化界面
- 支持实时数据分析和趋势预测
系统特色
- 全栈技术栈:从数据采集到前端展示的完整解决方案
- 大数据处理:基于Spark的高性能分布式计算
- 智能预测:机器学习算法预测视频热度
- 实时分析:支持实时数据更新和分析
- 可视化展示:丰富的图表和地图展示
🏗️ 技术架构
整体架构图
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 数据采集层 │ │ 数据处理层 │ │ 应用展示层 │
│ │ │ │ │ │
│ Python爬虫 │───▶│ Apache Spark │───▶│ Django Web │
│ 抖音API接口 │ │ 大数据处理 │ │ 可视化界面 │
│ │ │ │ │ │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 数据存储层 │ │ 机器学习层 │ │ 用户交互层 │
│ │ │ │ │ │
│ MySQL/Hive │ │ Scikit-learn │ │ 响应式前端 │
│ CSV文件存储 │ │ 线性回归模型 │ │ ECharts图表 │
└─────────────────┘ └─────────────────┘ └─────────────────┘技术栈详情
后端技术
- Python 3.8+:主要开发语言
- Apache Spark 3.5.3:大数据处理引擎
- Django 3.1.14:Web框架
- PySpark:Spark Python API
- Scikit-learn:机器学习库
数据存储
- MySQL:关系型数据库
- Apache Hive:数据仓库
- HDFS:分布式文件系统
- CSV:数据交换格式
前端技术
- HTML5/CSS3:页面结构
- JavaScript:交互逻辑
- ECharts:数据可视化
- Bootstrap:响应式布局
部署环境
- Linux CentOS:服务器操作系统
- Hadoop 3.x:分布式存储
- YARN:资源调度
- Docker:容器化部署(可选)
🎨 系统设计
目录结构
基于Spark的抖音数据分析预测推荐系统/
├── spiders/ # 数据爬虫模块
│ ├── spider.py # 抖音数据爬虫
│ └── __init__.py
├── spark/ # Spark数据处理模块
│ ├── sparkAna.py # 主要分析逻辑
│ ├── sparkFir.py # 数据预处理
│ └── temp.csv # 临时数据文件
├── predict/ # 机器学习预测模块
│ ├── index.py # 预测模型主文件
│ ├── transfer.py # 数据转换
│ └── preVideo.csv # 预测数据
├── myApp/ # Django应用模块
│ ├── views.py # 视图控制器
│ ├── models.py # 数据模型
│ ├── urls.py # 路由配置
│ └── templates/ # 模板文件
├── utils/ # 工具函数模块
│ ├── getPublicData.py # 公共数据获取
│ └── getChartData.py # 图表数据生成
├── static/ # 静态资源
├── templates/ # 全局模板
├── assets/ # 资源文件
├── manage.py # Django管理脚本
├── requirements.txt # 依赖包列表
├── design_135_douyin.sql # 数据库设计
└── 配置文档.md # 系统配置说明数据库设计
系统设计了完整的数据库结构,包括:
- videodata:视频基础信息表
- commentdata:评论数据表
- addressum:地址统计表
- likerate:点赞收藏率表
- fanscategory:粉丝分类表
项目演示
项目源码获取,见页面底部卡片,码界筑梦坊,各大平台同名~
🚀 核心功能实现
1. 数据采集模块
抖音爬虫实现
python
import time
import pandas as pd
import requests
import csv
def spider(url, params):
"""发送HTTP请求获取数据"""
response = requests.get(url, headers=headers, params=params)
response.encoding = 'utf-8'
return response.json()
def search_keyword(keyword):
"""关键词搜索视频数据"""
offset = 0
count = 16
while True:
params = {
'aid': 6383,
'channel': 'channel_pc_web',
'search_channel': 'aweme_video_web',
'keyword': keyword,
'offset': offset,
'count': count,
}
url = 'https://www.douyin.com/aweme/v1/web/search/item/?'
time.sleep(1) # 避免频率限制
resp_data = spider(url, params)
for video_data in resp_data['data']:
save_video_info(video_data['aweme_info'])
if resp_data['has_more'] == 0:
break
offset += count
count = 10技术特点:
- 模拟真实浏览器请求头
- 实现分页数据获取
- 内置频率限制保护
- 支持多种搜索参数
数据清洗与存储
python
def save_video_info(video_data):
"""保存视频信息到CSV文件"""
minutes = video_data['video']['duration'] // 1000 // 60
seconds = video_data['video']['duration'] // 1000 % 60
video_dic = {
"用户名": video_data["author"]["nickname"].strip(),
"粉丝数量": video_data["author"]["follower_count"],
"发表时间": get_time(video_data["create_time"]),
"视频描述": video_data['desc'].strip().replace('\n', ''),
"视频时长": "{:02d}:{:02d}".format(minutes, seconds),
"点赞数量": video_data['statistics']['digg_count'],
"收藏数量": video_data['statistics']['collect_count'],
"评论数量": video_data['statistics']['comment_count'],
"下载数量": video_data['statistics']['download_count'],
"分享数量": video_data['statistics']['share_count'],
"aweme_id": video_data["aweme_id"],
}
writer.writerow(video_dic)2. Spark大数据处理模块
Spark会话配置
python
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
# 构建Spark会话
spark = SparkSession.builder.appName("sparkSQL").master("local[*]").\
config("spark.sql.shuffle.partitions", 2). \
config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse"). \
config("hive.metastore.uris", "thrift://node1:9083"). \
enableHiveSupport().\
getOrCreate()
# 获取SparkContext
sc = spark.sparkContext配置说明:
- 本地模式运行,便于开发调试
- 配置Hive元数据服务
- 启用Hive支持
- 优化shuffle分区数
数据统计分析
python
# 需求一:IP地址分布分析
result1 = commentdata.groupby("address").count()
df = result1.toPandas()
# 需求二:点赞收藏分析
top10 = videodata.select("likeCount","collectCount","description")\
.orderBy(F.desc("likeCount"))\
.limit(10)
result2 = top10.withColumn("ratio",
top10["collectCount"]/top10["likeCount"])
# 需求三:粉丝数量区间分析
videodata_df = videodata.withColumn("fansRange",
when(videodata["fansCount"] < 100,"小于100")
.when((videodata["fansCount"]>=100)&(
videodata["fansCount"]<1000 ),"100-1000")
.when((videodata["fansCount"]>=1000)&(
videodata["fansCount"]<10000 ),"1000-10000")
.when((videodata["fansCount"]>=10000)&(
videodata["fansCount"]<100000 ),"10000-100000")
.when(videodata["fansCount"] >= 100000,"大于100000")
.otherwise("未知"))
result3 = videodata_df.groupby("fansRange").count()分析功能:
- 地理分布统计
- 用户行为分析
- 粉丝群体分类
- 数据质量评估
3. 机器学习预测模块
线性回归模型
python
import pandas as pd
from sklearn.linear_model import LinearRegression
# 读取训练数据
data = pd.read_csv('./preVideo.csv')
# 特征工程
features = data[['视频时长','收藏数量','评论数量']]
target = data['点赞数量']
# 创建并训练模型
model = LinearRegression()
model.fit(features, target)
def pred(data):
"""预测视频点赞数"""
new_data = pd.DataFrame([data],
columns=['视频时长','收藏数量','评论数量'])
predictions = model.predict(new_data)
result = round(predictions[0], 0)
return result
# 预测示例
pred([133, 1311, 2282])模型特点:
- 基于线性回归算法
- 多特征输入预测
- 实时预测能力
- 模型可扩展性
4. Web应用展示模块
Django视图设计
python
from django.shortcuts import render
from utils.getPublicData import *
from utils.getChartData import *
from predict.index import *
def index(request):
"""首页数据展示"""
uname = request.session.get('username')
userInfo = User.objects.get(username=uname)
# 获取统计数据
maxData, maxLike, maxComment, maxCollect, \
xData, yData1, yData2, yData3 = getIndexData()
# 获取表格数据
tabledata = list(getvideodata())
return render(request, 'index.html', {
'userInfo': userInfo,
'maxData': maxData,
'maxLike': maxLike,
'maxComment': maxComment,
'maxCollect': maxCollect,
'xData': xData,
'yData1': yData1,
'yData2': yData2,
'yData3': yData3,
'tabledata': tabledata
})
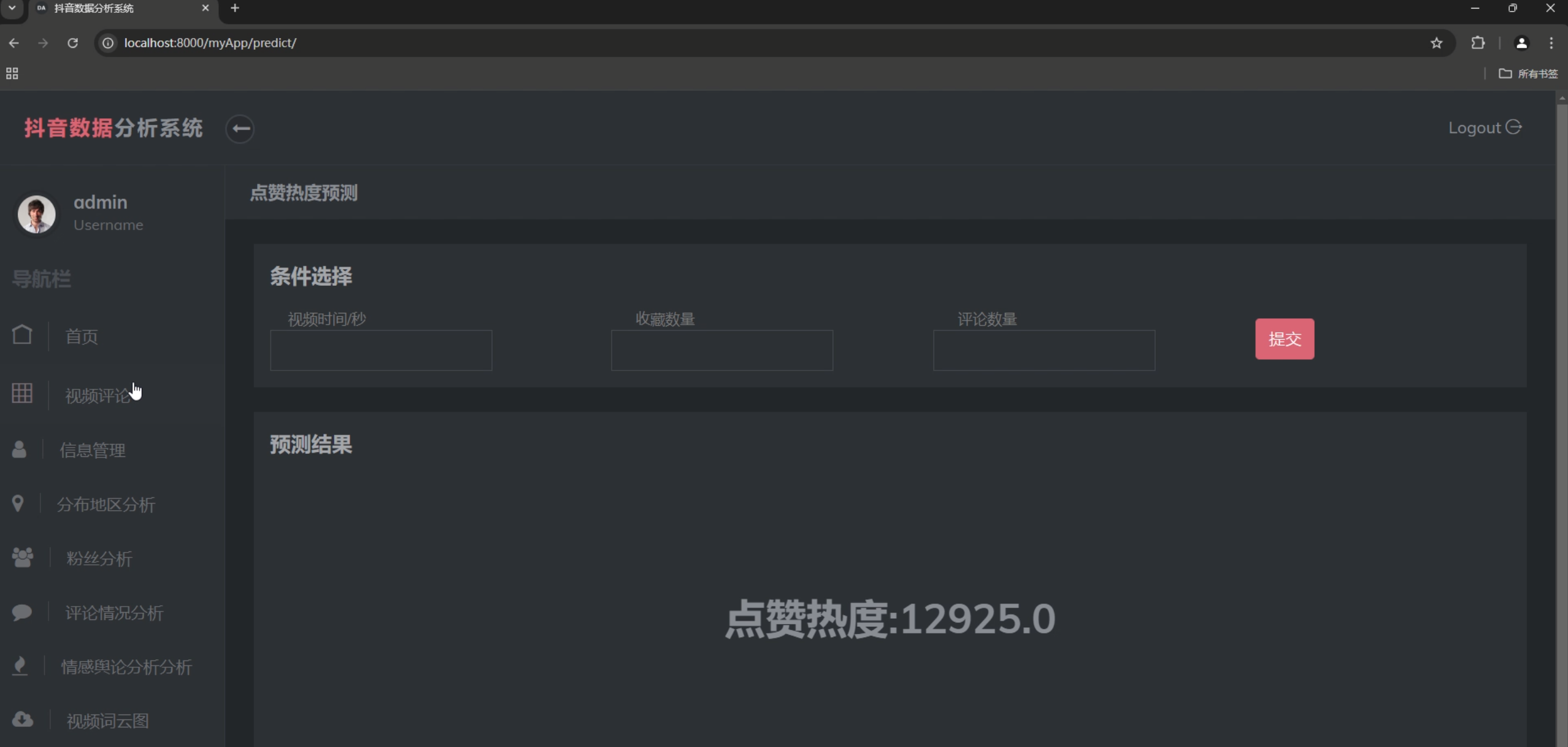
def predict(request):
"""热度预测功能"""
if request.method == 'POST':
video_duration = int(request.POST.get('video_duration'))
collect_count = int(request.POST.get('collect_count'))
comment_count = int(request.POST.get('comment_count'))
# 调用预测模型
result = pred([video_duration, collect_count, comment_count])
return render(request, 'predict.html', {
'result': result,
'input_data': {
'duration': video_duration,
'collect': collect_count,
'comment': comment_count
}
})
return render(request, 'predict.html')功能模块:
- 用户认证与授权
- 数据统计展示
- 图表可视化
- 热度预测
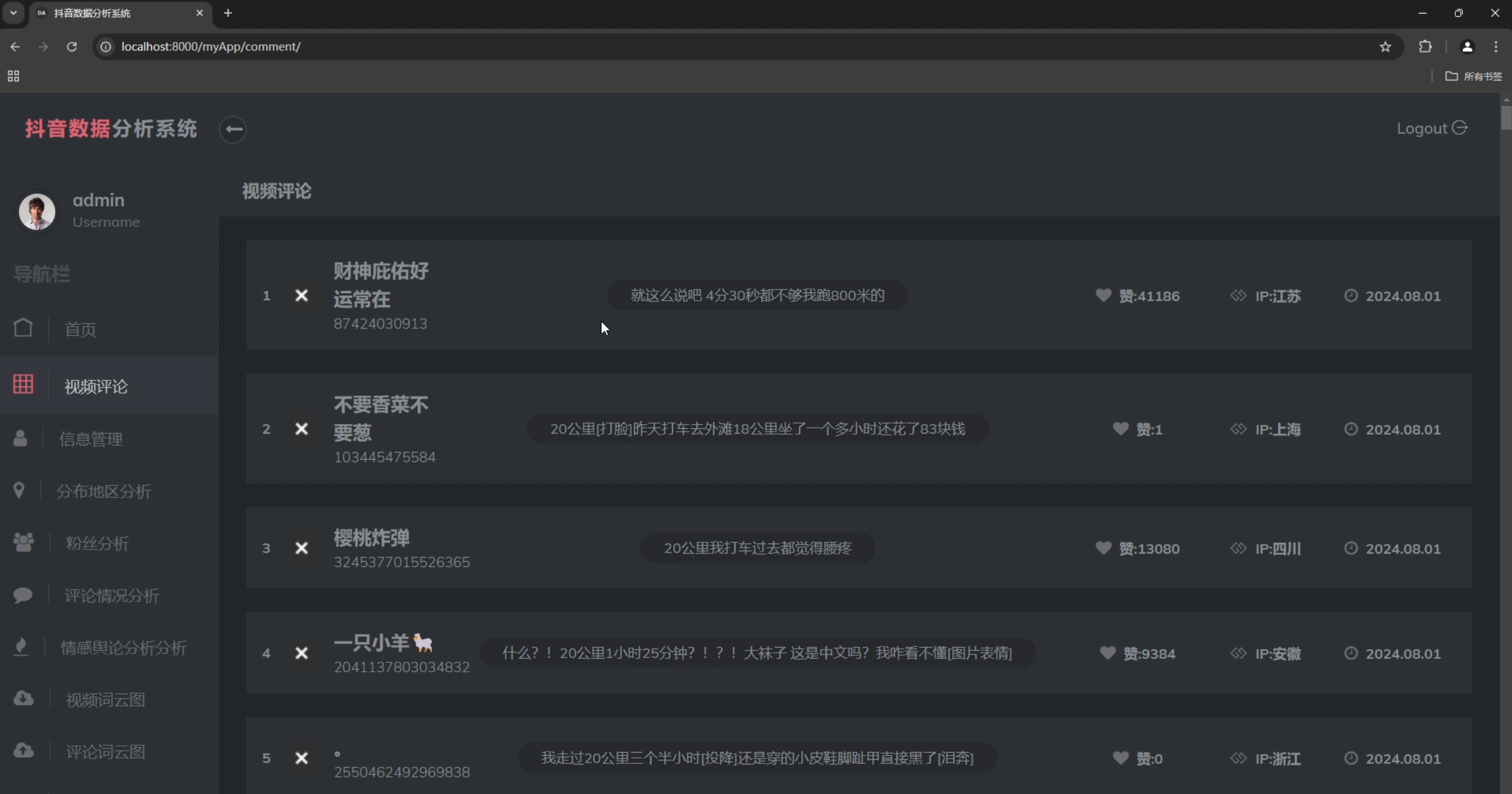
- 评论分析
🔧 技术难点与解决方案
1. 反爬虫对抗
问题描述: 抖音平台有完善的反爬虫机制,包括频率限制、IP封禁等。
解决方案:
- 模拟真实浏览器请求头
- 实现请求频率控制
- 使用代理IP池(可扩展)
- 定期更新Cookie信息
2. 大数据处理性能
问题描述: 海量数据处理时性能瓶颈明显。
解决方案:
- 使用Spark分布式计算
- 优化数据分区策略
- 实现数据缓存机制
- 采用增量处理方式
3. 实时数据更新
问题描述: 需要保持数据的实时性和准确性。
解决方案:
- 定时任务调度
- 增量数据同步
- 数据版本控制
- 异常处理机制
4. 机器学习模型优化
问题描述: 预测模型的准确性和泛化能力。
解决方案:
- 特征工程优化
- 模型参数调优
- 交叉验证评估
- 集成学习策略
⚡ 性能优化
Spark性能优化
python
# 配置优化
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
# 数据缓存
videodata.cache()
commentdata.cache()
# 分区优化
videodata.repartition(10).write.mode("overwrite").saveAsTable("videodata_opt")数据库优化
- 建立合适的索引
- 优化SQL查询语句
- 使用连接池管理
- 定期数据清理
前端性能优化
- 图表数据懒加载
- 静态资源CDN加速
- 响应式设计优化
- 浏览器缓存策略
🚀 部署与运维
环境要求
- 操作系统:CentOS 7+ / Ubuntu 18+
- 内存:最低8GB,推荐16GB+
- 存储:最低100GB可用空间
- 网络:稳定的网络连接
部署步骤
bash
# 1. 启动Hadoop集群
su hadoop
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
# 2. 启动Hive服务
cd /export/server/hive
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
# 3. 启动Spark集群
cd /export/server/spark
sbin/start-all.sh
sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port=10000
# 4. 部署Python应用
pip install -r requirements.txt
python manage.py runserver 0.0.0.0:8000监控与维护
- 系统资源监控
- 日志分析管理
- 性能指标跟踪
- 定期备份策略
📊 可视化展示
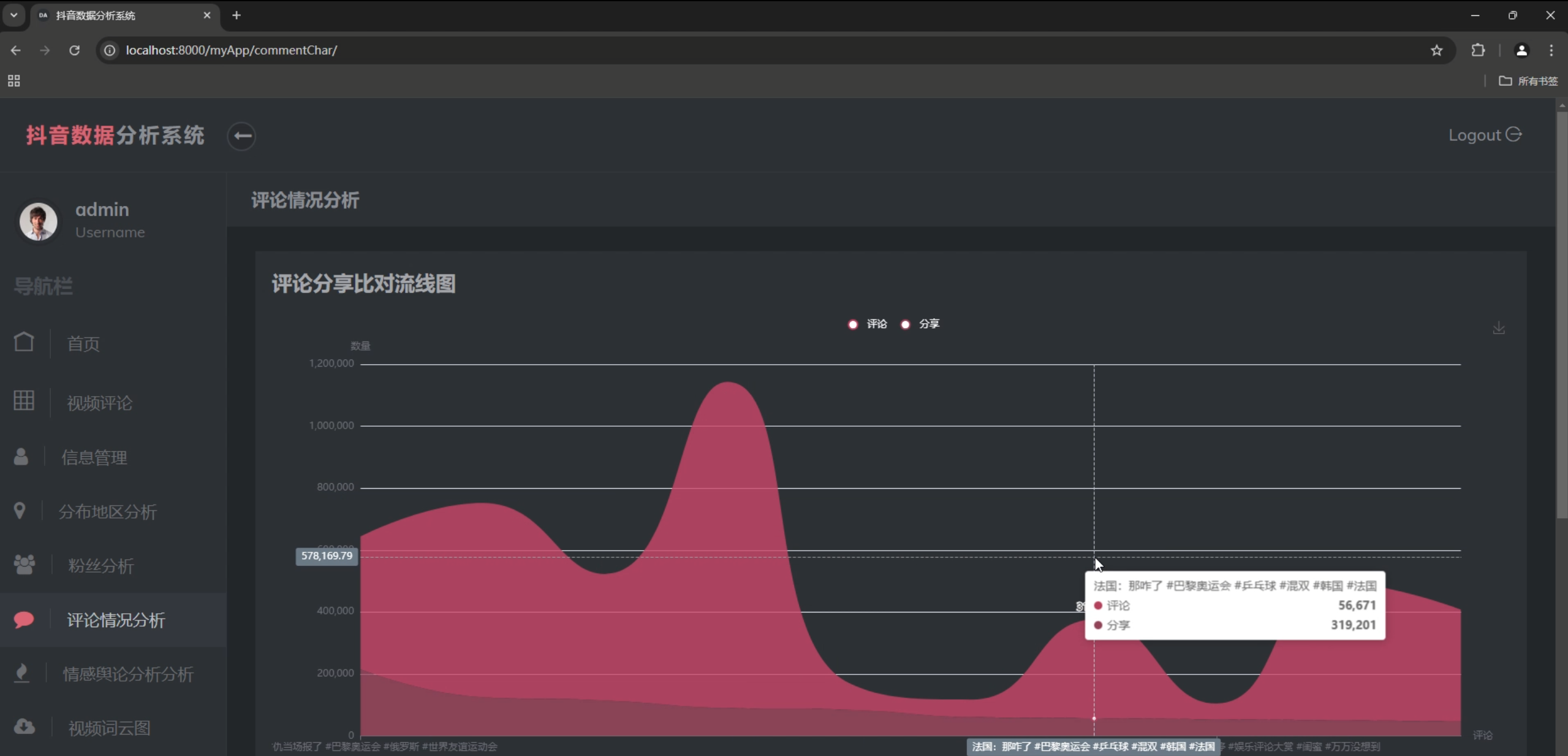
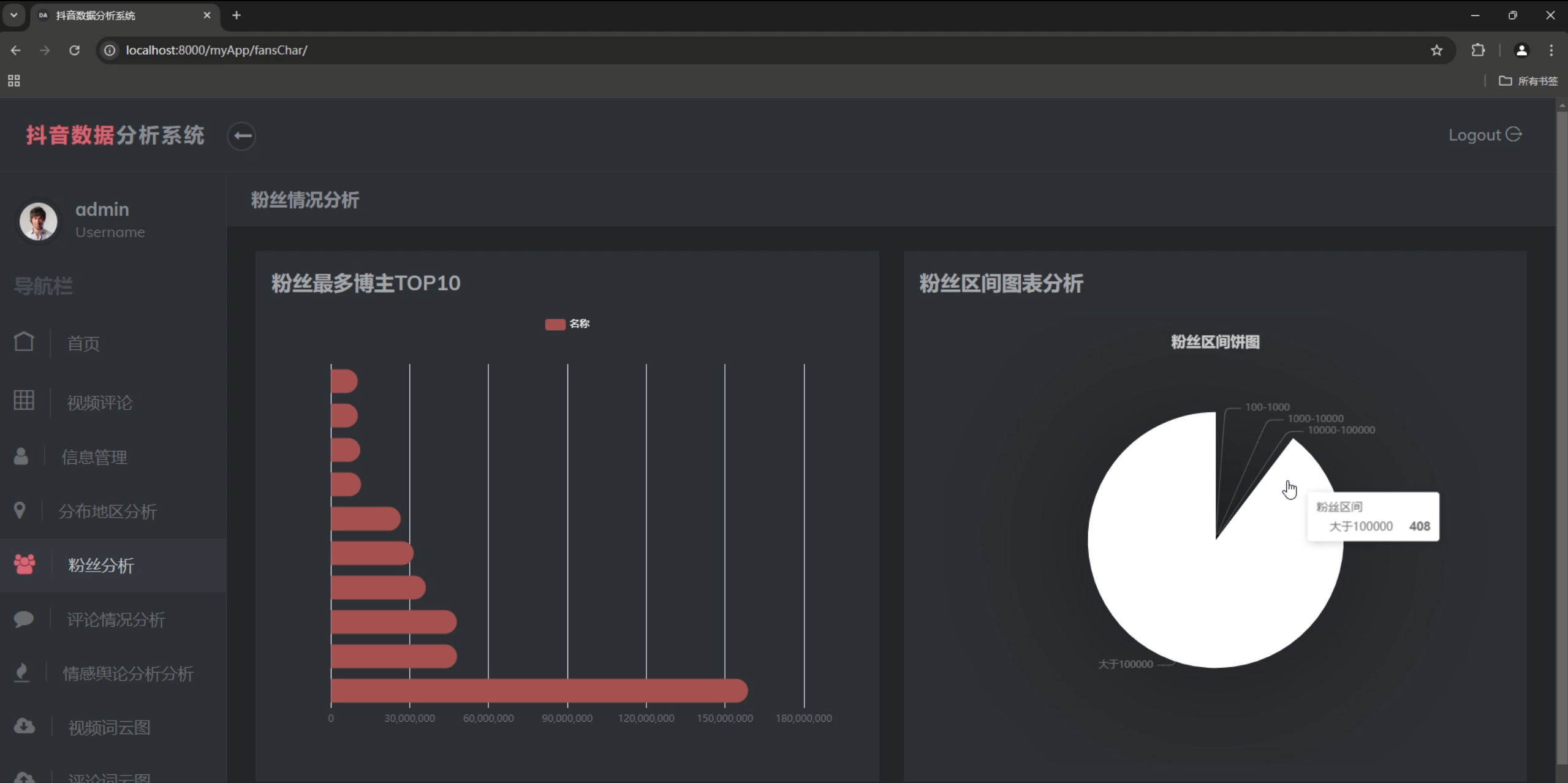
数据大屏设计
系统提供了丰富的数据可视化功能:
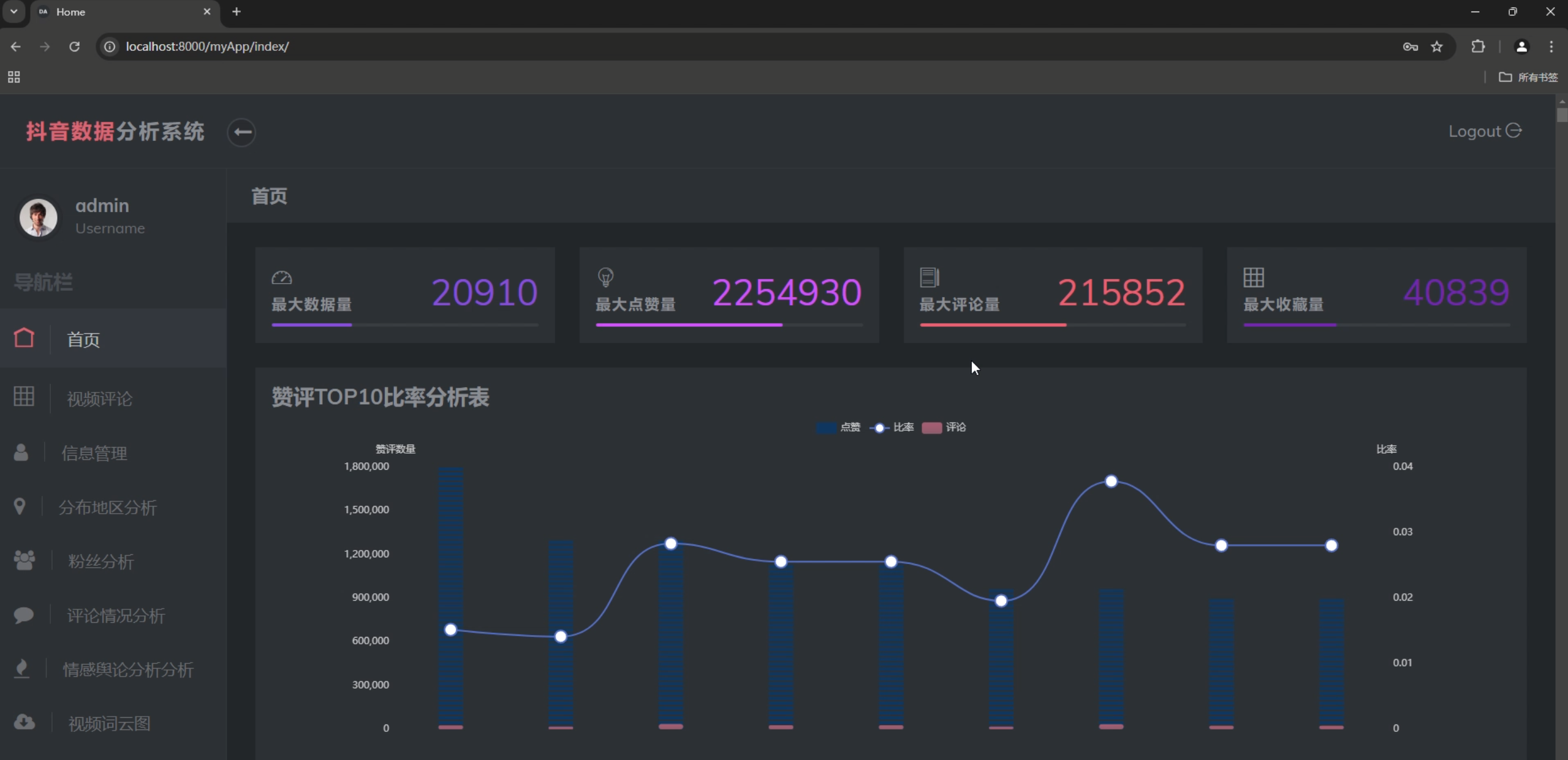
1. 统计概览
- 总视频数量
- 最高点赞数
- 最高评论数
- 最高收藏数
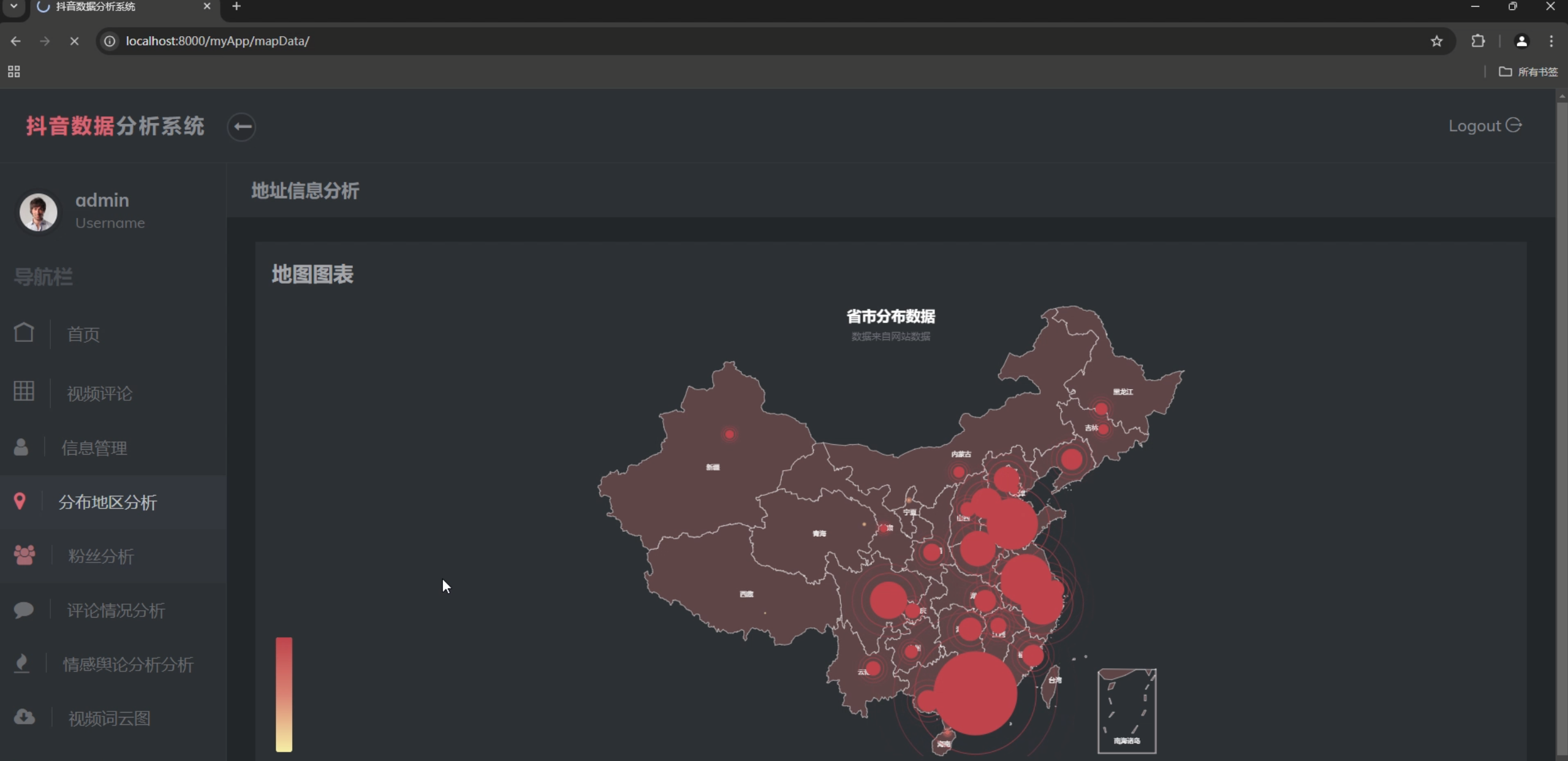
2. 地理分布图
- 用户地理分布热力图
- 地区活跃度分析
- 地理位置聚类
3. 用户行为分析
- 粉丝数量分布饼图
- 点赞收藏趋势图
- 评论分享统计
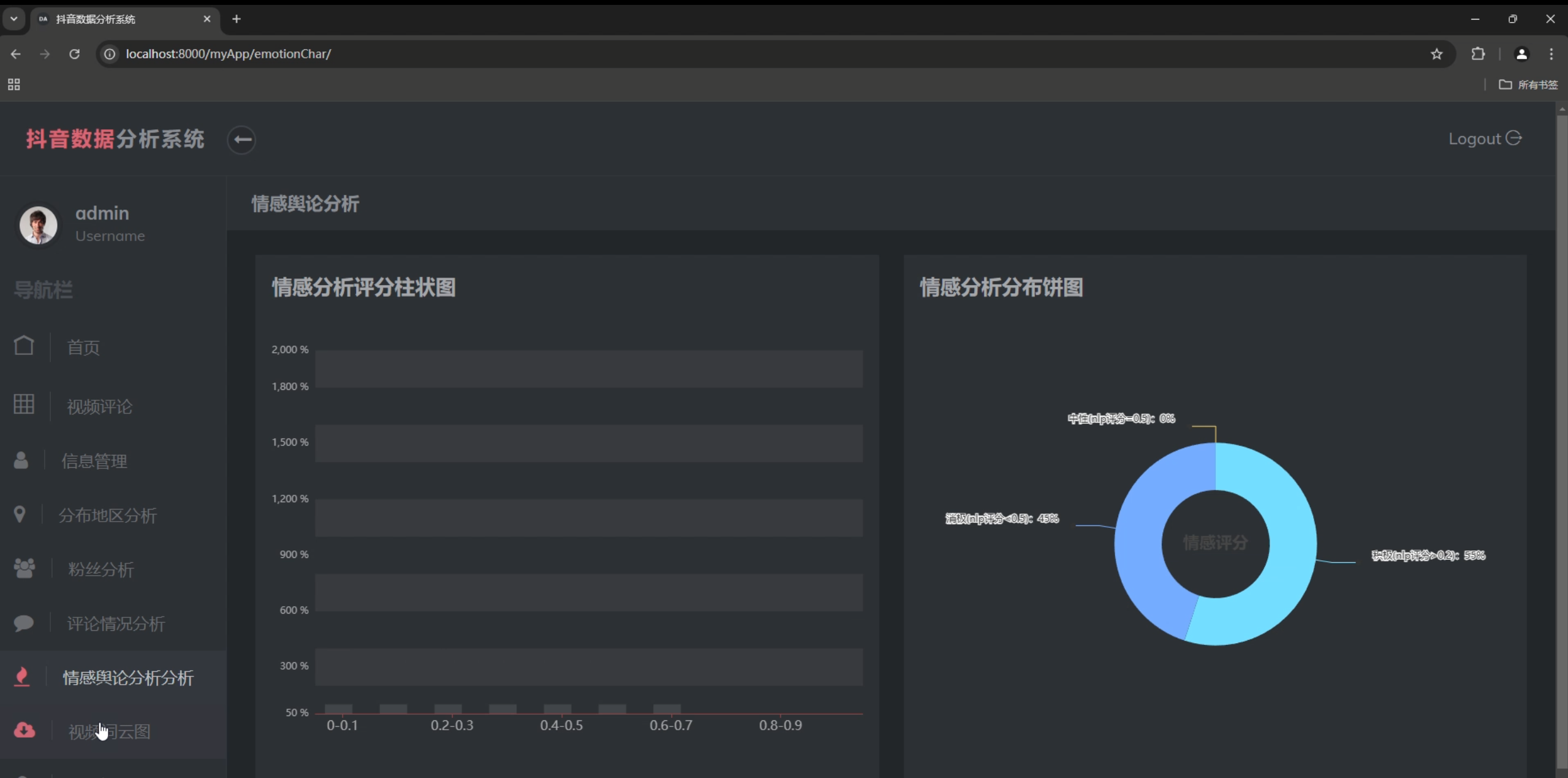
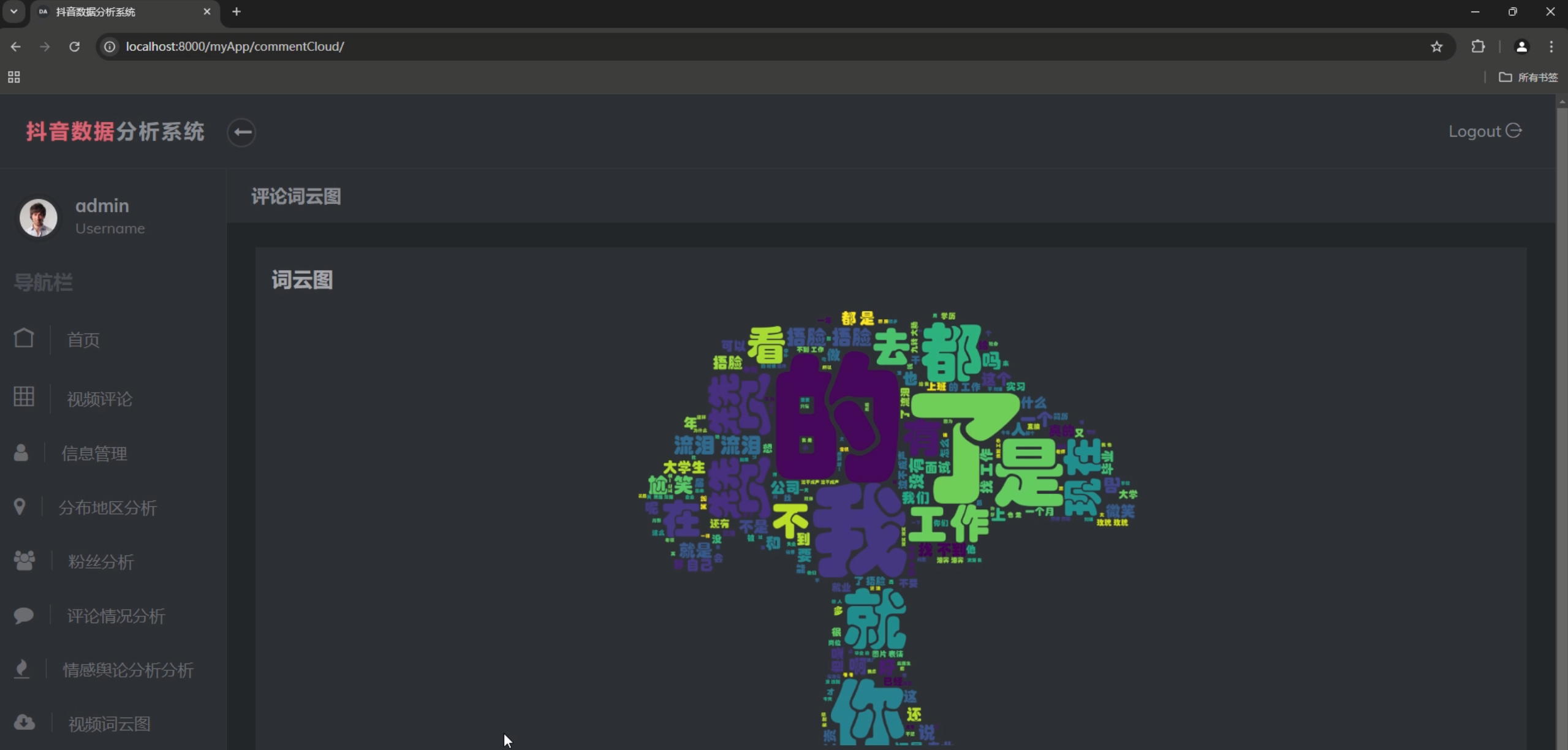
4. 情感分析
- 评论情感分布
- 情感趋势变化
- 关键词云图
5. 热度预测
- 预测结果展示
- 历史数据对比
- 趋势分析图表
📈 项目总结
技术成果
- 完整的数据采集体系:实现了抖音平台的数据爬取和清洗
- 高效的大数据处理:基于Spark的分布式计算架构
- 智能的预测模型:机器学习算法预测视频热度
- 直观的可视化界面:丰富的图表和数据展示
- 可扩展的系统架构:模块化设计,易于扩展
应用价值
- 内容创作者:了解内容表现,优化创作策略
- 平台运营:掌握用户行为,制定运营策略
- 数据分析师:提供数据支持,辅助决策分析
- 学术研究:为短视频研究提供数据基础
技术亮点
- 全栈技术集成:从数据采集到前端展示的完整解决方案
- 大数据处理能力:支持TB级数据处理
- 实时分析能力:支持实时数据更新和分析
- 智能预测功能:基于机器学习的趋势预测
- 高可用架构:分布式部署,支持高并发访问
未来展望
- 算法优化:引入深度学习模型,提升预测准确性
- 实时处理:实现流式数据处理,支持实时分析
- 多平台支持:扩展到其他短视频平台
- API服务化:提供RESTful API接口
- 移动端适配:开发移动端应用
📞 联系方式
码界筑梦坊 各大平台同名 欢迎咨询
技术交流
欢迎关注我们的技术分享,一起探讨大数据处理、机器学习、Web开发等前沿技术!
声明: 本项目仅用于技术学习和研究目的,请遵守相关平台的使用条款和法律法规。如有疑问或建议,欢迎通过上述联系方式与我们交流。
最后更新时间:2025年8月