eShopSupport 项目深度解析
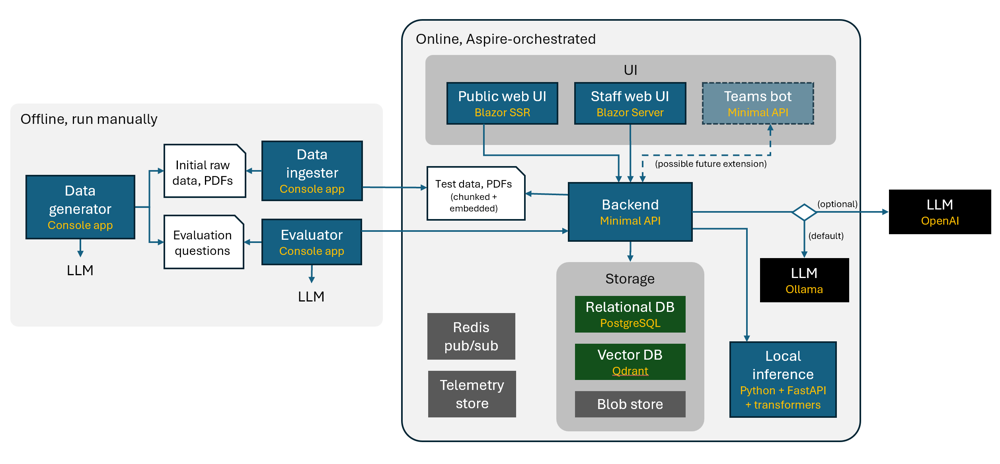
eShopSupport 项目的整体架构示意图。左侧为离线运行的工具(DataGenerator、DataIngestor、Evaluator)用于数据准备和评估;右侧为在线运行的系统,由多个服务和前端组成,通过 .NET Aspire 编排在本地或云端运行。
项目架构与模块划分
eShopSupport 是一个面向电子商店客户支持的参考 .NET 应用,采用服务化架构,将不同功能划分为多个模块/子项目并通过 .NET Aspire 进行统一编排。整体架构包括离线数据工具 、在线后端服务 、前端应用 以及基础设施服务几大部分:
-
DataGenerator(数据生成器):控制台应用,负责生成各种种子数据文件,如产品类别、产品信息、用户手册、支持工单及问答对等,用于为系统提供模拟数据和评估问题答案。该模块利用 GPT-35-Turbo 等大模型生成虚构的产品描述、手册内容和支持对话等数据。它会依次调用不同的生成器类(如 CategoryGenerator、ProductGenerator、ManualGenerator 等)构造出完整的数据集,并输出为 JSON/PDF 文件供后续使用。
-
DataIngestor(数据导入器) :控制台应用,负责处理 DataGenerator 生成的原始数据文件,对其进行解析、切分(Chunking)和嵌入向量(Embedding) 等操作。DataIngestor 不直接将数据导入数据库,而是将处理后的结果保存为新的文件,供应用启动时加载。它的主要任务包括:整理工单和产品数据、将长文本的产品手册拆分为段落并生成嵌入向量表示,以及准备评估问答对等。例如,其
Program.cs中依次执行 TicketIngestor、ProductIngestor、ManualIngestor 等,将生成的数据转换为可种子化的数据文件。 -
Evaluator(评估器) :控制台应用,用于离线评估聊天问答功能的质量 。Evaluator 项目使用预先生成的评估问答对(
evalquestions.json)作为基准。它会调用后端的 Assistant API(聊天机器人接口),输入测试问题,获取回答并与预期答案进行比对打分,从而衡量聊天机器人的准确性、速度和成本等指标。这一模块帮助开发者客观评估和改进 AI 功能的表现。 -
AppHost(应用主机) :Aspire 项目之一,负责本地开发环境下的服务编排和资源管理。AppHost 定义了整套应用在 Aspire 中的运行模型,会将各个服务(如 Backend、Web UI、PythonInference 等)和依赖资源(如数据库、向量库、缓存等)添加到 Aspire 的应用模型中,并统一启动。在本地运行时,开发者通过启动 AppHost 来同时启动所有需要的服务,以及 Aspire 仪表盘用于监控这些资源。AppHost 简化了多进程应用的本地部署,确保各组件(包括容器化的依赖服务)正确启动并连接。
-
ServiceDefaults(服务默认配置) :Aspire 项目之二,提供公共的配置和抽象,用于简化各服务的设置和通信 。该库包含跨项目共享的代码,例如 HTTP 客户端封装、服务注册扩展等。其中定义了 PythonInferenceClient (用于与 PythonInference 服务通信的 HTTP 客户端)以及 StaffBackendClient(用于 StaffWebUI 调用后端 API 的客户端)等封装,从而方便 .NET 应用调用其他服务的接口。ServiceDefaults 提供了标准化的配置方式,使各微服务的启动和互相调用更加便利一致。
-
IdentityServer(身份认证服务) :ASP.NET Core Web 应用,用于为 Web 前端和 API 提供认证和授权。该模块负责管理用户登录、安全令牌等,保证只有授权的用户(如客服人员)才能访问后台管理界面或调用相关 API。eShopSupport 将客户前端和员工后台的身份验证集中在此服务,例如使用 OAuth2/OIDC 流程实现登录,并向前端应用提供 IdentityUrl 等配置。IdentityServer 项目的存在使系统具备基础的安全控制。
-
Backend(后端服务) :基于 ASP.NET Core Minimal API 实现的核心服务,提供整个支持系统的业务接口。它负责业务数据的管理和AI逻辑的编排 :处理来自前端的请求(如创建支持工单、查询知识库等),读写关系数据库 和向量数据库 ,并调用 AI 服务完成分类、总结、问答等功能。后端通过 Minimal API 定义了各类端点,例如支持工单管理、知识库查询以及聊天助手接口(AssistantApi)等。Backend 内部包含诸如 SemanticSearch 服务类用于语义搜索、TicketSummarizer 用于对话摘要和情感分析,AssistantApi 控制器用于聊天问答等关键模块。它也是整个应用的大脑,协调各部分工作:当有新支持请求进来时,后端会将请求分发给AI分类器、存储到数据库,并通知员工端界面。
-
PythonInference(Python 推理服务) :基于 FastAPI 和 Transformers 实现的独立服务,用于本地运行小型模型推理 。它通过 Uvicorn 服务器托管,提供 REST API 接口供 .NET 后端调用。当前项目主要使用了其中的
/classify端点,对客户提交的工单文本进行自动分类 。该服务在启动时加载 Hugging Face 的一个小型零样本分类模型(如cross-encoder/nli-MiniLM2-L6-H768)到 GPU,并对输入文本预测最合适的标签。通过将 Python 擅长的丰富AI模型生态与 .NET 应用集成,eShopSupport 展示了在不重写现有 .NET 项目的情况下利用 Python 来增强 AI 能力的方式。值得注意的是,PythonInference 项目除了分类外还实现了一个嵌入向量生成(embedder)的路由,但在本示例中未被实际使用。 -
CustomerWebUI(客户前端) :基于 Blazor Server-Side Rendering (SSR) 的Web前端项目,面向客户用户,提供提交支持请求的界面。客户可以通过该网站填写支持工单(包括选择产品、问题描述等),系统将记录这些请求并自动应用AI分类等功能。CustomerWebUI 还可能提供知识库搜索功能,让客户查询产品手册或常见问题。该前端主要职责是收集客户问题并展示基础的反馈,例如提交成功通知或相关文档提示。作为 Blazor SSR 应用,它在服务器端渲染页面,提升初次加载性能,同时也能利用交互组件提升用户体验。
-
StaffWebUI(员工前端) :基于 Blazor Server 的内部Web应用,供客服人员使用,用于查看和处理客户支持工单。员工可以在此查看所有客户提交的请求,查看系统自动生成的分类结果和情感分析分值,阅读对话历史摘要,并可以与客户进行回复交流。StaffWebUI 集成了 AI 辅助功能,例如内部聊天助手:客服可以就客户问题询问内置的知识库问答机器人,并得到带引用出处的答案建议,以帮助撰写回复。此外,员工界面还提供一键生成回复草稿的功能,由 AI 根据上下文自动给出回复内容,供人工审核编辑后发送。通过 StaffWebUI,支持人员能够高效地利用 AI 提供的洞见(如情绪、总结、建议)处理工单。
-
E2ETest(端到端测试) :基于 Playwright 的自动化测试项目,用于对 StaffWebUI 进行端到端的集成测试。由于 AI 功能具有一定随机性,E2ETest 模块提供了一种实验性的确定性测试方法,确保在AI输出不确定的情况下仍可验证关键路径功能是否正常。例如,通过预先设定好随机种子或替换模型输出为固定结果,来测试整个应用从客户提交问题到员工收到AI建议回复的流程。该测试项目有助于在持续集成中保证应用基本功能的可靠性。
上述模块通过 .NET Aspire 进行组合和运行。.NET Aspire 是一个云原生应用开发栈 ,可方便地定义和启动多服务应用以及所需的依赖资源。在本地运行时,Aspire 会以 Docker 容器方式启动 PostgreSQL (关系数据库)、Qdrant (向量数据库)、Redis (缓存/消息)和 Blob 存储 等基础服务,每个服务都有持久化卷以保存数据。Aspire 仪表盘提供了直观视图让开发者查看各服务的运行状态。通过模块化架构和 Aspire 编排,eShopSupport 展现了一个多项目协作 、前后端分离 且AI赋能的企业应用范例。
核心功能与技术实现
eShopSupport 实现了一系列面向客户支持场景的 AI 核心功能,每项功能背后都有相应的技术实现:
-
支持工单自动分类 :当客户提交新的支持请求后,系统会自动判断该请求的类型(例如咨询、投诉或反馈)。技术上,后端会调用 PythonInference 服务 的
/classify接口,将客户填写的文本和预定义的候选标签列表传给模型。PythonInference 使用 Hugging Face 提供的零样本文本分类模型 (cross-encoder MiniLM)在本地 GPU 上运行推理,输出与文本最匹配的标签。例如,候选标签可能包括"问题咨询","产品投诉","功能请求"等,模型会计算哪个标签与用户描述语义最相近并返回之。后端接收该结果后,将该支持工单归类标记,从而无需人工初筛即可自动分配类别。这一流程充分利用小型预训练模型实现快速分类,提高工单处理的自动化程度。 -
客户情绪与意图分析 :系统对客户消息内容进行情感倾向分析 ,判断用户语气是正面、负面还是中性。通过情感分析,支持团队可以优先处理愤怒或不满的客户,提升满意度。在实现上,可以有多种方式:eShopSupport 将此作为对话摘要的一部分,由 LLM 在生成总结时顺带给出用户情绪的评价。也可能使用类似文本分类的小模型或OpenAI API直接分析情感。无论实现细节如何,结果都会存储为每个对话线程的一个情感分值或标签,供工作人员在后台界面查看,用于工单优先级排序和情绪化妥善处理。
-
对话内容自动总结 :对于已经有多轮往返消息的支持工单,系统可以生成该对话的摘要 。这样支持人员无需从头阅读长篇对话,就能快速了解关键问题和进展。技术实现上,Backend 包含一个 TicketSummarizer 服务,它利用 大型语言模型(LLM) 来对整条对话(所有消息记录)进行语义概括。通过 Microsoft.Extensions.AI 提供的接口,后端将对话文本传递给配置的 LLM(本地或云),请求其生成几句总结,将重点提炼出来。例如,LLM 输出"客户询问产品X的使用方法,客服提供了步骤说明,客户确认问题解决"。该摘要会显示在 StaffWebUI 界面供客服快速了解当前状态。因为使用了统一的 AI 抽象层,这个总结功能无论背后调用的是本地 Ollama 模型还是 Azure OpenAI 服务,代码实现都是相同的,只是配置不同而已。
-
语义搜索与知识检索 :eShopSupport 将产品手册等非结构化文档引入支持流程,提供基于语义的知识库搜索 功能。客户或客服提出问题时,系统可以在后台实时从产品手册中查找相关内容,即使用户使用不同措辞或有拼写错误,也能找到匹配的信息。其技术要点是向量数据库 :在数据准备阶段,DataIngestor 已将每份产品手册 PDF 按段落切分,并使用嵌入模型将段落转化为向量存入 Qdrant 向量库。运行时,Backend 接收到查询后,会将查询句子通过同样的嵌入模型编码为向量,然后在 Qdrant 中执行相似度搜索,找出最相关的几个文档段落。通过这种向量语义匹配,系统能检索到潜在有用的信息片段。搜索结果返回给用户时,可展示相关段落内容或提供指向手册的链接,从而帮助用户自助找到答案,减少人工参与。语义搜索也为聊天机器人提供了支撑,使其能够引用知识库内容作答。
-
内部知识问答机器人 :为了辅助客服人员,系统提供了一个内部使用的问答助手 。客服可以通过后台界面的聊天框,向这个 AI 助手提问与产品或业务相关的问题,助手会给出答案并附上引用来源以佐证。该功能背后的实现属于 RAG(检索增强型生成) 范式:首先,Backend 会将客服提出的问题当作查询,在向量数据库(Qdrant)中搜索相关的产品手册段落(就像上面的语义搜索)。然后,Backend 将检索到的内容片段连同原始问题一起提交给 LLM,请其根据提供的知识进行回答,并在答案中引用这些内容来源。例如,LLM 可能回复:"根据产品手册,第3页,该设备不防水,因此不能水下使用。" 这里引用的就是知识片段来源标识。这种做法确保机器人回答准确且有依据。当客服拿到答案后,可以直接采用或稍作编辑回复客户,大大提升了复杂问题解答的效率和准确性。
-
AI建议回复生成 :当客服需要回复客户时,系统可以基于当前对话上下文自动生成回复草稿 供参考。这利用了 LLM 的文本生成能力:Backend 将客户最近的问题、相关上下文以及系统希望回复的语气/格式提示一起发送给 LLM,请其产生一段合适的回复语。在 eShopSupport 中,如果客服打开某个工单,内部问答机器人可以根据该工单内容"草拟"一份回复。当客服对回复草稿满意后,可一键发送,或经过人工润色再发送给客户。该功能相当于一个AI客服助手,减轻了人员的撰写负担,使响应更快捷。然而出于责任考虑,草稿通常需要人工审核,以确保礼貌和准确无误。
-
测试数据合成与加载 :为方便演示和测试,eShopSupport 内置了大规模测试数据生成 能力。DataGenerator 模块利用 OpenAI GPT-3.5 等生成模型批量创作模拟数据,涵盖产品目录、产品手册内容以及成百上千条虚构的客户支持对话,以构建一个看似真实的支持系统场景。这些数据生成后由 DataIngestor 进一步加工,然后在应用启动时自动导入:应用会将预生成的 JSON 数据文件加载到 PostgreSQL 数据库,将向量嵌入文件导入 Qdrant 库,将 PDF 文件保存到 Blob 存储。通过这一机制,开发者开箱即得丰富的数据用于实验各项 AI 功能,无需手动准备数据集。
-
AI功能效果评估 :针对聊天机器人和AI辅助功能,项目提供了自动评估工具 (Evaluator)来衡量其质量和改进空间。Evaluator 使用一系列预先定义的问题及其"标准答案"来测试 Backend 的问答接口(AssistantApi)。运行评估时,程序依次发送每个测试问题给系统,记录 AI 的回答并与标准答案比对,计算准确率等指标。这样可以量化模型回答的准确度和可靠性,发现偏差或错误之处。eShopSupport 还探索了端到端的确定性测试方案,将 AI 生成的不确定性因素固定,以便在持续集成中自动验证 AI 功能不出现严重退化。这些评估手段体现了将 AI 组件纳入常规软件质量保障流程的实践,为开发者持续优化 AI 效果提供依据。
通过上述功能,eShopSupport 展示了将生成式 AI 融入业务应用的多种典型场景,不仅实现了智能客服聊天,还将 AI 用于分类、搜索、总结、创成内容 等方面。在实现过程中,项目充分利用了 .NET 8 提供的新特性和库:例如使用 Microsoft.Extensions.AI 抽象来编写与模型无关的代码,使同一套逻辑可以无缝切换本地或云端的大语言模型;通过 .NET Aspire 工作负载,一键启用所需的 AI 推理基础设施(如本地 LLM 推理器 Ollama、向量数据库等)。这种架构确保核心业务与AI逻辑解耦,开发者可以方便地替换模型或调整推理方式而不改变应用主体代码。总的来说,eShopSupport 的每个核心功能都体现了 AI 技术在实际业务中的应用方式,从而为开发者提供了宝贵的参考。
关键技术栈和依赖
eShopSupport 所使用的技术栈覆盖前后端、AI框架和基础设施多个层面,构建了一个现代化的 .NET 智能应用:
-
后端框架 :基于 .NET 8 和 ASP.NET Core 。后端服务采用 Minimal API 风格构建,使接口定义简洁明确,同时利用依赖注入、日志等ASP.NET基础设施。前端应用采用 Blazor 技术,其中客户站点使用 .NET 8 新增的 Blazor SSR(服务端渲染) 模式,员工后台使用 Blazor Server 模式,实现丰富的交互界面。Blazor 让开发者使用 C# 和 Razor 构建客户端 UI,而 SSR 提升了首屏性能和 SEO 友好度。样式方面,项目包含大量 CSS/LESS 样式和前端脚本资源(GitHub 统计约85%为JavaScript,可能包括Blazor编译出的WebAssembly资源和前端库),保证了良好的用户体验。
-
AI 与机器学习 :项目大量用到 大语言模型 (LLM) 技术以及自然语言处理库。微软提供的 Microsoft.Extensions.AI 库被用于标准化与 AI 服务交互的接口。通过该库,开发者可以使用一套统一的 API 调用不同 AI 模型,例如 Azure OpenAI Service 上的 GPT-3.5/4,或本地部署的开源模型(通过 Ollama 等工具)。eShopSupport 支持两种模式:默认使用本地 LLM(通过 Ollama 运行诸如 Llama2 等模型),可选配置下切换为 Azure OpenAI 云服务。这种灵活性源于依赖注入配置不同的提供程序,例如在本地模式下注册 OllamaClient,在云模式下注册 OpenAIClient,但二者实现了相同的接口,因此业务代码无需修改。
-
.NET Aspire :作为贯穿项目的核心基架,Aspire 提供了云原生应用开发 所需的工具集合和运行时支持。它通过 Workload 形式集成(需要安装
dotnet aspire工作负载),提供了类似 Infrastructure as Code 的能力用于声明应用的各项资源和服务依赖。eShopSupport 利用 Aspire 定义了数据库、缓存、AI 模型等资源,并实现一键启动所有组件的本地运行。Aspire 还支持将 Python 项目纳入 .NET 解决方案共同编排运行,在本项目中通过 AppHost 启动 FastAPI 服务,确保 .NET 与 Python 服务协同工作。Aspire 简化了复杂分布式应用的调试和部署,被称为一个 "约定式、云原生的 .NET 开发栈",帮助开发者以一致的方式配置微服务、容器和资源。 -
数据与存储 :后端使用 PostgreSQL 关系数据库来保存结构化数据,包括客户、产品类别、产品信息、支持工单和对话线程等。Postgres 容器通过 Aspire 在本地启动,并使用数据卷持久化存储,以模拟生产环境的数据库。同时,项目引入 向量数据库 Qdrant 作为语义搜索的存储后端,专门用于保存产品手册文本片段的向量表示。Qdrant 同样作为容器运行,提供高效的相似度搜索 API。为了与 .NET 代码交互,项目实现了 QdrantHttpClient 扩展,封装了调用 Qdrant 的 HTTP 客户端,并与 Semantic Kernel 的 MemoryStore 接口对接,以标准化向量存取操作。此外,Blob 存储 (通过 Azurite 或类似模拟器)用于保存产品手册 PDF 等二进制文件。Redis 则被用作发布/订阅和缓存服务器,提升跨服务通信效率。所有这些存储服务都通过 Aspire 声明配置,在本地以 Docker 方式运行,方便开发测试。
-
Python 技术栈 :PythonInference 子项目使用了 FastAPI 框架构建 Web API。FastAPI 以其高性能和简洁声明式路由著称,非常适合构建ML推理服务。服务器由 Uvicorn ASGI服务器托管。在机器学习方面,该服务利用 Hugging Face Transformers 库加载模型并执行推理。具体而言,使用
transformers.pipelineAPI 构建了一个 Zero-Shot Classification 管道,加载 HuggingFace 上的cross-encoder/nli-MiniLM2-L6-H768微型模型(约数百万参数量),并在启动时将其加载到 CUDA GPU 上。Hugging Face 模型提供了本地执行的能力,不需要外部API即可完成诸如文本分类等任务。依赖管理方面,项目附带了requirements.txt,列出了所需的 Python库版本(FastAPI、transformers等),开发者需使用 pip 安装。通过 VS Code 或 Visual Studio 的 Python 工具,可以在 .NET 开发环境中顺畅地编辑和调试该 Python 服务。 -
身份认证与安全 :项目采用了 IdentityServer (Duende IdentityServer 或 ASP.NET Core Identity) 实现用户认证。IdentityServer 项目作为独立的 ASP.NET Core 应用,负责登录页面、用户注册,以及为前后端提供 JWT/OIDC 等令牌服务。客户和员工可能采用不同的身份域,例如客户直接提交工单无需登录(或使用临时身份),而员工必须登录后才能访问 StaffWebUI 和 Backend API。配置上,Aspire 在启动 CustomerWebUI 和 StaffWebUI 时将 IdentityServer 的地址注入为环境变量,使前端知道认证服务的位置。这一安全架构保证了后台数据和接口的访问控制,模拟了真实系统中对内部系统和外部用户的权限隔离需求。
-
前端技术 :Blazor 应用使用了 Razor 组件和C#编写交互逻辑,前端构建由 .NET SDK 完成,产生静态资源(HTML/JS/CSS)。值得一提的是,项目中客户UI采用 SSR,因此页面初次由服务器渲染为 HTML,之后可能通过 Blazor WebAssembly 或 SignalR 接管交互(.NET 8 SSR 支持Hydration)。员工UI为 Blazor Server,则完全通过 SignalR 保持客户端与服务器的组件状态同步。两种模式充分展示了 Blazor 在不同场景下的应用。界面上,项目可能使用了一些现成 Blazor 组件库或自定义样式(代码库中出现了大量 CSS/LESS),以实现友好的 UI 体验。测试方面,使用 Playwright 脚本对 Web UI 进行了 E2E 测试模拟真实用户操作,这也属于前端依赖的一部分。
-
其他依赖 :项目采用 Docker 来部署运行依赖服务(数据库、向量库等),需要本地安装 Docker Desktop。此外要求本地有支持 CUDA 的 NVIDIA GPU 以运行本地模型(若无GPU也提供降级方案使用CPU)。开发环境建议 Visual Studio 2022 v17.10+ 并安装 ASP.NET、Python、Aspire SDK 等工作负载。通过这些工具链,开发者可以顺利构建和运行整个解决方案。项目的依赖还包括一些 .NET 扩展库,如 Aspire.Azure.AI.OpenAI (可能用于对接 Azure OpenAI 服务)和 Aspire.Qdrant.Client 等,如果选择使用,也需要通过
Directory.Packages.props引入 NuGet 包。不过 eShopSupport 默认通过自己实现的 HttpClient 扩展来访问 Qdrant 而未必使用官方客户端。所有依赖在仓库的nuget.config和各子项目.csproj中均有声明,可供参考。
综上,eShopSupport 构建在 Microsoft 最新的 .NET 技术栈 之上,并融合了 Python 机器学习生态 和 容器化部署。这种多元的技术组合展示了在企业应用中引入 AI 的端到端方案:既利用了 .NET 强大的 Web 开发能力和新推出的 AI 支持库,也不避讳引入 Python 等异构技术来用其所长。通过 PostgreSQL、Qdrant、Redis 等组件,项目还涉及现代后端存储和检索技术,为实现语义搜索和大规模数据处理提供支持。对于希望将 AI 集成到现有技术栈的开发者而言,该项目提供了全面且前沿的技术示范。
核心实现细节与代码逻辑
在了解架构和功能后,我们进一步深入代码层面,分析 eShopSupport 若干关键模块的实现方式和逻辑流程:
-
自动分类流程 :当客户在 CustomerWebUI 提交支持请求后,前端会通过 HTTP 调用 Backend 提供的 API(例如 POST
/api/tickets)创建工单。Backend 接收到请求后,会提取其中的描述文本,并调用内部的分类逻辑。具体实现上,Backend 使用 ServiceDefaults 提供的 PythonInferenceClient ,向 PythonInference 服务的/classify接口发送分类请求。例如,请求内容为:{"text": "产品在水下能用吗?", "candidate_labels": ["咨询","投诉","反馈"]}。在 PythonInference 的classifier.py中,该请求被路由到classify_text函数处理。代码首先利用 HuggingFace 的零样本分类管道对文本进行推理:pythonclassifier = pipeline('zero-shot-classification', model='cross-encoder/nli-MiniLM2-L6-H768', device='cuda') classifier('warm up', ['a','b','c']) # 预热模型 @router.post("/classify") def classify_text(item: ClassifyRequest) -> str: result = classifier(item.text, item.candidate_labels) return result['labels'][0]如上所示,模型会返回各候选标签的置信度并排序,代码取置信度最高的标签作为结果返回。Backend 收到结果后,将该类别写入数据库中新工单的记录中(例如标记
Ticket.Category字段),并可通过 WebSocket/SignalR 通知 StaffWebUI 有新工单到来。StaffWebUI 页面上立即显示新工单以及系统分配的类型标签,实现了提交->分类->展示的一条龙自动处理。整个过程体现了前后端、Python 服务的联动:前端提交->后端调用Python模型->结果回传->前端更新 UI,代码清晰地分工于各模块,协同完成需求。 -
聊天问答实现 :内部聊天助手(Assistant API)的实现包含信息检索和语言生成两个步骤。Assistant API 在 Backend 中作为一个 Minimal API 端点实现(例如 POST
/api/assistant/ask)。当 StaffWebUI 调用该端点并传入问题时,Backend 首先执行语义检索 :利用 Qdrant 向量数据库查找与问题相关的知识片段。代码逻辑可能类似:调用 QdrantHttpClient 扩展,检索存储的手册段落,筛选出若干相似度最高的段落。接着,Backend 将问题和检索到的段落一起提交给 LLM。由于项目使用 Microsoft.Extensions.AI 抽象,这里代码会通过注入的 IPromptCompletion 或类似接口来调用模型。例如,Backend 可能构造一个 Prompt 包含:「问题 :{用户问题}\n知识 :{片段1}\n{片段2}\n请根据以上知识回答 :」这样的提示,然后调用promptCompletion.GenerateAsync(prompt)。模型提供者可以是本地 Ollama(例如加载了 Llama2 7B 模型)或 Azure OpenAI(例如调用 gpt-35-turbo),具体由配置决定。生成的答案通常带有引用标记(模型被提示在引用知识片段时加编号或出处标识)。Backend 获取模型输出后,将答案返回给 StaffWebUI 前端。工作人员在界面上会看到 AI 的回答以及引用来源(通常对应产品手册章节)。若满意可采纳,不满意也可以忽略。这个过程中涉及的关键代码路径包括:向量搜索 (Backend 调 Qdrant)、LLM 调用 (通过 Extensions.AI 统一接口调用本地或云模型)和结果组装 。所有这些都在 AssistantApi 的实现中串联起来。Evaluator 项目对 AssistantApi 的测试也证明了其工作方式:Evaluator 逐条读取 evalquestions.json 里的问题,通过 HTTP 调用 AssistantApi,得到回答 JSON,再解析比对答案。因此,可以推断 AssistantApi 返回的数据结构包含模型回答文本,可能还有引用的原始段落或标识,供前端呈现。在代码组织上,Backend 很可能将检索和生成封装在一个 AssistantService 或 QAService 中,AssistantApi 调用该服务的方法得到回答,从而使逻辑易于测试和复用。 -
对话摘要与情感分析 :当客服打开某个支持工单或查看对话线程时,系统会呈现AI 总结 和情绪评分 。这一功能由 Backend 的 TicketSummarizer 服务实现。其核心逻辑是在对话内容每有更新后,或当客服请求摘要时,汇总该线程的所有消息文本,然后调用 LLM 生成概要。由于可能涉及多轮对话,提示词会精心设计,例如「请总结以下客服对话的主要内容和结论,并判断客户情绪倾向」。Backend 调用 LLM 完成生成后,将结果存储在数据库(如 Ticket.ThreadSummary 字段)以及情感分(如 Ticket.SentimentScore)。在 StaffWebUI 上对应界面位置显示这些信息。从代码角度,TicketSummarizer 可能被实现为后台任务:每当有新客户回复到达,触发重新总结。或者也可以在用户点击"生成摘要"按钮时即时调用生成。情感分析部分可能复用 LLM 返回的信息或者通过简单的规则/模型另行计算。例如,如果摘要中包含「客户对解决方案表示非常不满」,可以解析出负向情绪。更专业的做法是在 PythonInference 中增加情感分析模型路由,但据项目介绍,情感分析是与总结一起由 LLM 完成的。代码实现上,Microsoft.Extensions.AI 提供的接口使调用 OpenAI 的情感分析 API 也很方便,但本项目选择了让 LLM一并输出。总结与情感这两个功能相辅相成地提供对对话的洞察,其代码关键在于 prompt 设计和结果解析存储,保障生成内容的可靠性和可用性。
-
数据种子与初始化 :当 AppHost 启动整个应用时,会执行数据库和向量库的初始化逻辑。Aspire 配置中声明了 ImportInitialDataDir 环境变量,指向
seeddata/dev目录。Backend 在启动时检测该目录下的种子文件(例如 products.json、tickets.json 等),读取内容并写入数据库对应表;同时读取向量嵌入文件,通过 Qdrant 客户端批量写入向量数据库。Manual PDF 则被复制到 Blob 存储容器中以供下载。当使用默认的 dev 数据集运行时,这些初始化数据已经由 DataGenerator 和 DataIngestor 准备妥当。因此代码层面,Backend 项目很可能包含一个 DataSeeder 类或在 Program.cs 中编排调用种子加载函数。如果发现数据库非空则跳过,以免重复导入。值得一提的是,Jason Haley 博客提到后台还会在启动时处理手册内容,比如将 PDF 文档文本索引到向量库。这暗示 Backend 启动逻辑与 DataIngestor 输出紧密配合:DataIngestor 已经输出了手册的分段和向量,但是最终插入 Qdrant和生成 Embedding索引的步骤可能放在 Backend 来做(或至少由 Backend 调用 Qdrant 导入 API)。因此 Backend 的初始化部分代码对于理解整个数据流很重要:从生成的数据文件到真正可被查询的持久化存储,完成闭环。 -
端到端测试控制 :E2ETest 项目旨在测试员工界面的关键功能,包括 AI 辅助。由于 AI 输出存在随机性,测试难点在于确保每次运行有可比性。项目通过 Aspire 的配置来控制这一点:当 E2ETest 启动 AppHost 时,会传入特殊标志,例如
isE2ETest=true,Aspire 针对此标志调整一些行为。可能的机制是,AppHost 在检测到 E2E 测试模式时,使用固定的模型应答或模拟服务。例如,用规则化的 stub 替换真正的 LLM 调用(返回预定义答案),或者加载特定的"小模型"使结果可预测。Jason Haley 提到 Evaluator 项目目前不会跑完全部500个问题,因为成本较高,取而代之希望用 Microsoft.Extensions.AI.Evaluation 等包来替代 Evaluator 的功能。这暗示今后可能有更标准的测试库。但在本项目中,为展示概念,E2ETest 采取了冻结外部因素的做法。代码实现上,可能在 AppHost 的配置里有类似:if (isE2ETest) modelConfig.UseDeterministicMode();或对随机种子 RandomSeed 统一设定。这样,Playwright 脚本就可以假定特定的输入会得到特定输出,从而验证 UI 上显示的 AI 回复是否等于预期值。该设计体现了对 AI 应用进行自动化测试的一种尝试,其代码细节复杂但思想值得借鉴,即通过依赖注入或条件分支,将AI服务替换为可预测的实现来进行测试。 -
关键逻辑和类职责 :在代码组织方面,eShopSupport 广泛使用了面向接口和依赖注入 。例如,Backend 中可能定义了
ITicketRepository接口来抽象数据库操作,由 EF Core 或 Dapper 的实现类提供具体功能,使得更换数据库或模拟数据变得容易。对于 AI 相关的逻辑,也可能有IClassifierService、IQAService等接口,由实际调用 PythonInference 或 LLM 的类实现。在 ServiceDefaults 里提供的 PythonInferenceClient、StaffBackendClient 则是封装 HttpClient 的工具类,它们使用 Typed HttpClient 功能注册到 DI 容器,以便在需要调用时直接注入使用。这样的封装将底层 REST 调用隐藏,提供了类似方法调用的体验,调用代码更简洁易读。例如,StaffWebUI 中获取AI建议回复可能直接调用staffBackendClient.GetSuggestedReply(ticketId),内部实现就是对 Backend API 的HTTP请求。Aspire 还负责将不同项目连接起来,如在 IdentityServer 启动时需要知道前端的回调URL,在 Backend 需要知道 IdentityServer 的公开地址等,这些都通过 Aspire 提供的参数传递和.WithEnvironment(...)方法注入进环境变量。因此,代码中大量配置依赖于环境变量(如数据库连接串、Identity URL、OpenAI Key 等)。这一切配置均集中在 AppHost 的 Program.cs,通过 Aspire 的 fluent API 声明。可以说,AppHost.Program.cs 是整个应用的"总装配"代码,定义了服务清单和依赖关系。而各子项目则各司其职,遵循 SOLID 原则,保持清晰的职责划分:生成数据 的只管生成,导入处理 的只管加工文件,后端 聚焦业务和AI调用,前端负责交互呈现。每个部分既相对独立又通过明确定义的接口契约衔接,体现了良好的架构设计思想。 -
代码示例 :以 分类功能 为例,贯穿多种技术栈:在 .NET Backend 中,相关代码可能位于
TicketController的 POST 动作里,或在TicketService.CreateTicketAsync方法中。伪代码可能如下:csharp// 从请求DTO创建Ticket实体 var ticket = new Ticket { Title = dto.Title, Description = dto.Description, ... }; _db.Tickets.Add(ticket); await _db.SaveChangesAsync(); // 调用分类服务获取类型标签 string label = await _classifierClient.ClassifyAsync(ticket.Description, _predefinedLabels); ticket.Label = label; await _db.SaveChangesAsync();其中
_classifierClient就是通过 DI 注入的 PythonInferenceClient,其内部使用 HttpClient 调用Python服务的/classify,将结果直接返回。Python 端如前所示,使用模型推理并返回标签字符串。这样的交互模型简单直观。在 PythonInference 部分,代码示例已给出。在 问答功能 上,虽然未能直接获取代码片段,但根据 Semantic Kernel 类似案例,伪代码可能是:csharp// 检索知识 var queryEmbedding = _embeddingGenerator.GenerateVector(question); var topDocuments = await _qdrantClient.SearchAsync(queryEmbedding, topK:3); // 构造提示 string prompt = PromptTemplate.Fill(question, topDocuments); // 调用LLM string answer = await _llmClient.GetCompletionAsync(prompt);这里
_qdrantClient可能是通过 QdrantHttpClientExtensions 配置的 Named HttpClient 实例。_llmClient则是通过 Extensions.AI 注入的接口,例如 IChatCompletion 或 ITextCompletion 实现。PromptTemplate 包含预定义的系统提示,指导 LLM 按所需格式作答(例如要求引用文档)。整个流程高度模块化,每步都有独立的实现类,便于理解和维护。
最后
总结而言,eShopSupport 在代码实现上展示了清晰的分层和模块边界 :数据生成/处理层、后端业务逻辑层、AI调用层、前端交互层各尽其职,并通过依赖注入和接口解耦降低耦合度。关键的 AI 功能实现并没有神秘难懂的黑盒,而是以合理的代码结构集成在常规的 .NET 项目中。例如,调用 OpenAI 被包装成普通的方法调用,处理向量搜索也有专门的客户端扩展。通过查看实际代码(例如 PythonInference 的 classifier.py 或 Backend 某些 Service 类),可以看到这些 AI 特性的实现也遵循常见的编程范式,只是在内部调用了强大的预训练模型而已。代码逻辑简洁明了且富有工程思想,使开发者能够快速上手了解每个功能的运作。总之,eShopSupport 将前沿的生成式 AI 技术以工程最佳实践方式融入解决方案,其代码既是 AI 应用的范例,也是 .NET 微服务架构的优秀示例,值得深入研读和借鉴。
参考:https://jasonhaley.com/2024/08/23/introducing-eshopsupport-series/