本文参考:
咸鱼技术的文档: https://juejin.cn/post/7174610735434547236#heading-9
美团非常详细地讲解JIT原理:https://tech.meituan.com/2020/10/22/java-jit-practice-in-meituan.html
研究背景
在服务发布或者重启的过程中,服务经常都会出"CPU 利用率超限 75%" 的报警,从监控看来,CPU 确实存在抖动飙高甚至打满的现象。这主要是由于应用重启时,JVM 重新进行类加载鱼对象初始化。从网上搜索了相关文章,学习一下它们的解决思路。
问题定位
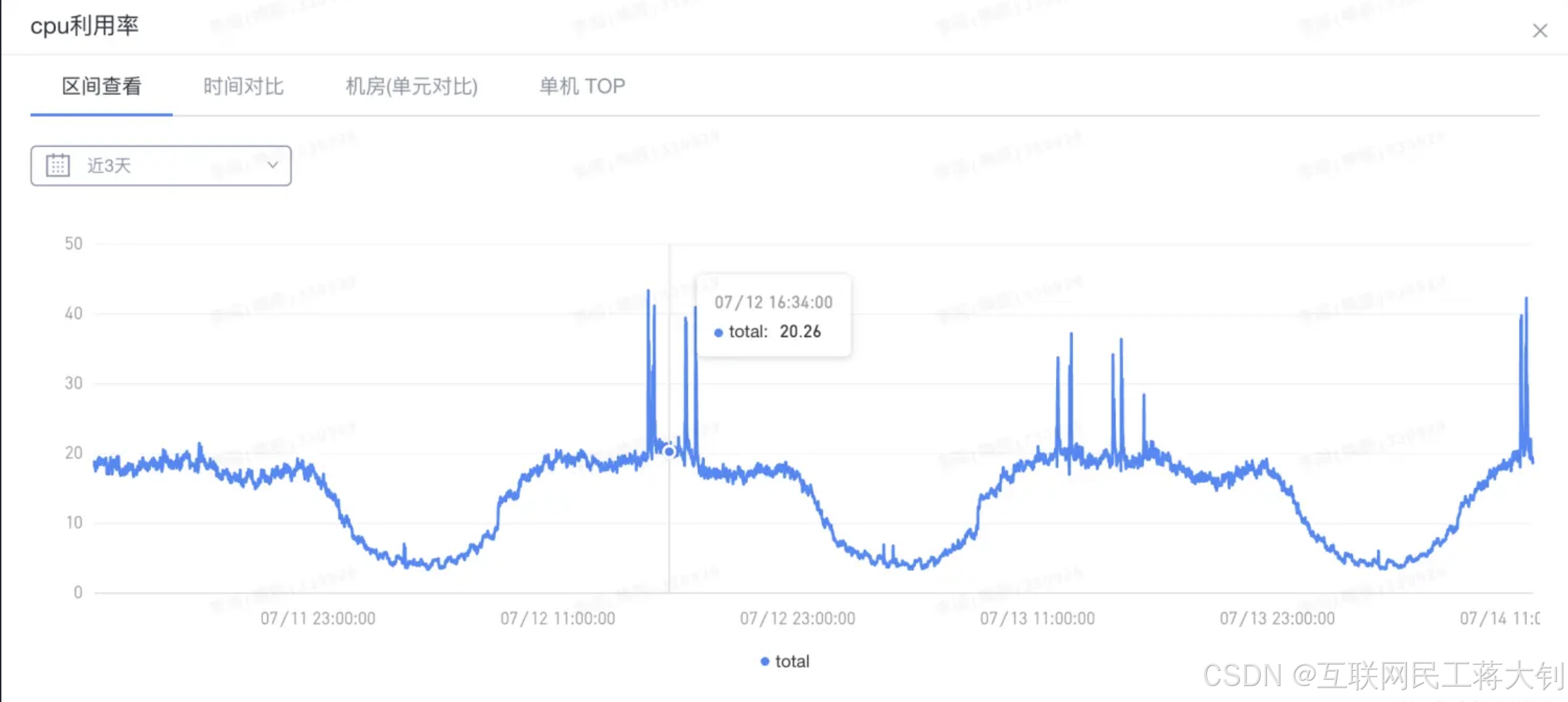
通过 Arthas dashboard 观察 CPU 使用情况,发现应用启动时,C2 CompilerThread 以及 C1 CompilerThread 占用了大量的 CPU,导致 CPU 使用率飙增。这俩都是 JIT complier 中的线程,故可以确认,CPU 飙高的原因是 激进的JIT编译。
C1(Client Compiler)是一个简单快速的编译器,主要实现浅层的局部优化,而放弃了需要花费大量时间精力的全局深度优化,默认被触发编译的阈值为1500次。
C2(Server Compiler)则是专门面向服务器端的,运行时会收集更多信息,花费更多时间,实现更为充分的全局优化,被触发编译的阈值为10000次。
JIT 编译
发布时CPU利用率的飙高是由于 JIT 编译导致的,因此在处理问题之前,我们需要了解Java编译的机制,这对于后续的理解很重要。
常见的编译型语言如C++,通常会把代码直接编译成CPU所能理解的机器码来运行。然而为了实现"一次编译,处处运行"的特性。Java把编译的过程分成两个阶段:
- 先由javac编译成通用的中间形式(字节码),该阶段通常被称为编译期。
- 「解释器」逐条将字节码解释为机器码来执行,该阶段则属于运行期。
这里有几个概念提前辨析一下:
字节码:javac 编译的中间形式,以此实现一次编译,处处执行
机器码:最终需要由CPU操作系统运行的文件,C++是直接编译出来的,而 Java 需要由「解释器」将字节码 -> 机器码
但是为了优化Java字节码运行的性能 ,HotSpot在「解释器」之外引入了JIT(Just In Time)即时「编译器」,形成了用解释器+JIT编译器混合的执行引擎
二者会在运行期并肩作战,但分工不同:
- 解释器(Interpreter):当程序需要迅速启动时,使用解释器解释字节码,节省编译的时间,快速执行。
- JIT编译器(JIT Compiler):在程序启动后并且长时间提供服务时,JIT将越来越多的代码编译为本地机器码,获得更高的执行效率。
Java程序在JVM上执行的过程如下图所示:
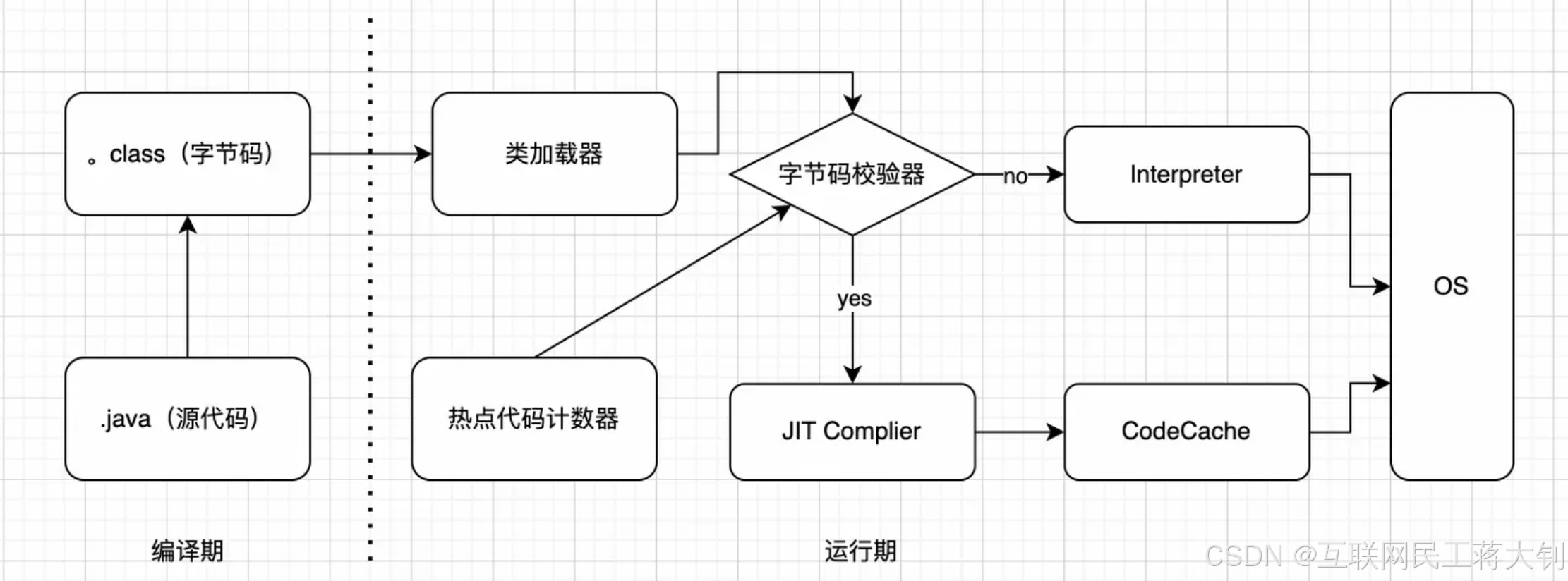
编译期先由javac将源码编译成字节码,在这个过程中会进行词法分析、语法分析、语义分析等操作,该过程也被称为前端编译。 当类加载完成,程序运行时,JVM会利用热点代码计数器进行判断,如果此时运行的代码是热点代码则使用JIT,如果不是则使用解释器。对于热点代码的判断方式有采样估计和计数两种方式,Hotspot采用计数方式,到达一定阈值时触发编译。
大多数情况下解释器首先发挥作用,将字节码按条解释执行。随着时间推移,通过不断对解释的代码进行信息采集,JIT逐渐发挥作用。把越来越多的字节码编译优化为本地机器码并存储在CodeCache中,来获取更高的执行效率。解释器这时可以作为编译运行的降级手段,在一些不可靠的编译优化出现问题时,再切换回解释执行,保证程序可以正常运行。JIT极大地提高了Java程序的运行速度,而且跟静态编译相比,即时编译器可以选择性地编译热点代码,省去了很多编译时间,也节省很多的空间。
有点类似于之前 OS 里学习的 CPU 指令 Cache 机制,整体总结下来,就是 JIT 编译器通过热点代码计数器,将原先解释执行字节码后的产物 - 机器码,存储在 CodeCache 中,下次可以直接从 CodeCache 取用执行。然而 JIT 编译时需要占用 CPU 的,所以激进的 JIT 编译导致了 CPU 飙高问题,下面看看解法。
解决方案
1. 分层编译
Java的分层编译可以渐进过渡的方式充分利用C1的灵活性和C2的深层优化,追求启动速度和峰值性能的平衡。在Java8之前,我们需要通过JVM参数-XX:TireCompilation 来打开分层编译。而对于Java8及之后的应用分层编译测试默认进行的。我们的应用基于Java8,因此已经打开了分层编译。
2. 调整 CodeCache
当codeCache容量不足时,在JDK1.7.0_4之后默认开启的回收机制是Speculative flushing。最早被编译的一半方法将会被放到一个old列表中等待回收。在一定时间间隔内,如果old列表中方法没有被调用,这个方法就会被从codeCache中清除,flushing操作则会带来CPU使用率的飙高。因此我们需要对其容量进行观测和调整。 通过JVM参数**-XX:ReservedCodeCacheSize=256M **设置Code Cache 的总容量上限。
对于应用程序复杂,CodeCache 容量不足的场景,通过扩大其容量可以避免编译优化的机器码被反复 flushing,从而避免 JIT 反复编译热点代码。
3. 龙井预热
需要使用阿里的 Ajdk 才能使用此功能,是「提前预热」思想的体现
根据前一次程序运行的情况,记录热点代码以及类加载顺序等信息。在应用下一次启动的时候积极主动地对相关类进行加载,并积极编译相关代码,进而使得应用尽快使用上C2编译优化的指令。从而在流量进来之前,提前完成类的加载、初始化和方法编译, 跳过解释阶段, 直接执行编译好的native code, 避免一面解释执行一面后台编译带来的CPU与load飙高, rt超时等问题。
4. 逐步放开流量
通过控制发布机器的流量大小, 用低流量来先去诱发JIT, 再把发布机器的流量设置到正常水位, 避免在JIT过程中, 因为全量流量进来导致的CPU飚高、LOAD飚高、RT飚高等问题, 使得应用发布或重启时顺滑平稳。
5. 调整 JIT 阈值
通常情况下,我们可以使用-XX:CompileThreshold=5000 修改JIT编译阈值为5000。
注意: 开启分层编译的情况下,-XX:CompileThreshold与-XX:OnStackReplacePercentage中参数设置的阈值将会失效,触发编译会由以下公式中新的参数的条件来判断:
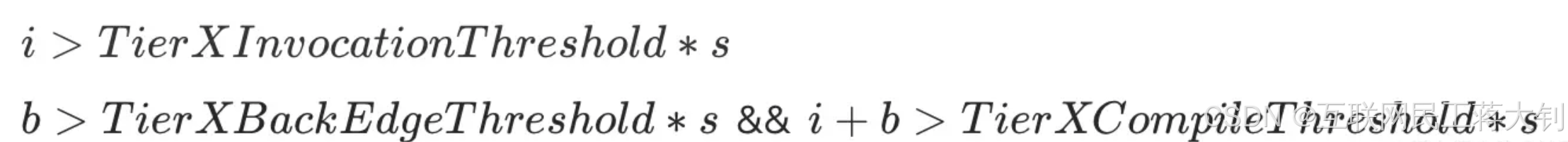
满足上述其中一个条件就会触发即时编译,i为调用次数,b是循环回边次数,s是系数,并且JVM会根据当前的编译方法数以及编译线程数动态调整系数s。 通过查看JVM运行时的参数 java -XX:+PrintFlagsFinal,我们可以看到相关的阈值参数如下:
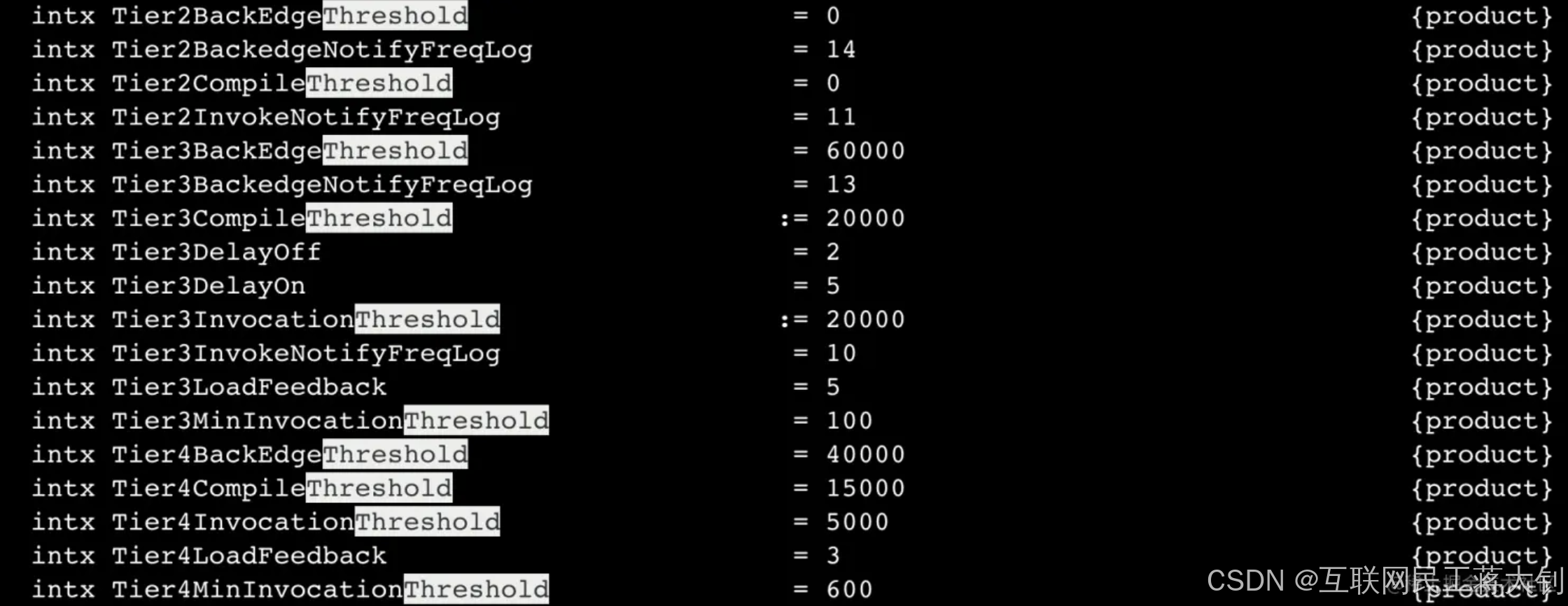
JVM 系统的分层编译支持5种级别
- Tier 0 - Interpertor 解释执行
- Tier 1 - C1 no profiling
- Tier 2 - C1 limited profiling
- Tier 3 - C1 full profiling
- Tier 4 - C2
对于集群 CPU 资源有限,且发布时 RT 没有极高要求的场景,通过调高 JIT 阈值,可以避免大量代码被当作热点代码所产生的激进的 JIT 编译。