文章目录
-
- 概要
- 一、原理
- 二、LOCK汇编指令
-
-
- [2.1、 LOCK](#2.1、 LOCK)
- [2.2、 原理](#2.2、 原理)
-
-
- [2.2.1、 缓存行](#2.2.1、 缓存行)
- [2.2.2、 缓存一致性之MESI协议](#2.2.2、 缓存一致性之MESI协议)
- 2.2.3、lock原理
-
-
- 三、x86缓存发展
- [四、x86 DMA发展](#四、x86 DMA发展)
- 参考
概要
在并发操作下,对一个简单的a=a+2的操作都会出错,这是因为这样简单的操作在被CPU执行时,分为三步:
- cpu从内存中读取a的值;
- cpu执行a=a+2操作;
- cpu将执行结果写回内存。
在多核环境下,很容易发生,A核和B核同时从内存中读取a的值,经过各自计算后写回内存的情况,这也解释了为什么在并发下,不加锁的累加操作结果常常比预期值小的原因。
在go语言中,对于有竞争的数据操作,我们常常用sync/atomic标准库提供的原子操作,经典的比如借助CAS原子操作实现自旋锁。
原子操作即是进行过程中不能被中断的操作。针对某个值的原子操作在被某个CPU执行的过程当中,其它CPU绝不会进行其它针对该值的原子操作,也就是说,为了实现这样的严谨逻辑,同一时刻原子操作仅会由一个独立的CPU执行,其它CPU等待,只有这样才能够在并发环境下保证原子操作的绝对安全。
Go语言提供的原子操作都是非侵入式的,我们通过调用sync/atomic标准库提供的函数,对6种简单的类型的值进行原子操作,这些类型包括int32、int64、uint32、uint64、uintptr和unsafe.Pointer类型。这些函数提供的原子操作共有5种,分别是增加(Add)、比较并交换(CompareAndSwap)、载入(Load)、存储(Store)、交换(Swap)。
调试的服务器信息:Centos Linux 7 ,CPU AMD x86_64,Go version 1.24
本文通过在CPU x86_64环境下的汇编分析这些原子操作的原理。
前置知识:
x86系列CPU寄存器和汇编指令
go 通过汇编分析栈布局和函数栈帧
一、原理
本章以原子操作Add为例,通过其汇编逐步去分析。
1.1、案例
go
package main
import (
"fmt"
"sync/atomic"
)
func main() {
a := uint64(1)
atomic.AddUint64(&a, 5)
a+=5
fmt.Println("Add", a)
}1.2、关键汇编
bash
[root@test gofunc]# dlv debug atomic.go
Type 'help' for list of commands.
(dlv) b atomic.go:8
Breakpoint 1 set at 0x4b1b13 for main.main() ./atomic.go:8
(dlv) c
> [Breakpoint 1] main.main() ./atomic.go:8 (hits goroutine(1):1 total:1) (PC: 0x4b1b0e)
3: import (
4: "fmt"
5: "sync/atomic"
6: )
7:
=> 8: func main() {
9: a := uint64(1)
10: atomic.AddUint64(&a, 5)
11: a+=5
12:
13: fmt.Println("Add", a)
(dlv) disass
Sending output to pager...
TEXT main.main(SB) /home/fpf/server/moa-20241226160534/background/tools/source/go-apps/src/gofunc/atomic.go
atomic.go:8 0x4b1b00 493b6610 cmp rsp, qword ptr [r14+0x10]
atomic.go:8 0x4b1b04 0f86e8000000 jbe 0x4b1bf2
atomic.go:8 0x4b1b0a 55 push rbp #BP寄存器值入栈
atomic.go:8 0x4b1b0b 4889e5 mov rbp, rsp #保存main函数栈帧基址
=> atomic.go:8 0x4b1b0e* 4883ec68 sub rsp, 0x68 #申请0x68大小栈内存
atomic.go:9 0x4b1b12 48c744241801000000 mov qword ptr [rsp+0x18], 0x1 #令变量a=1
atomic.go:10 0x4b1b1b b905000000 mov ecx, 0x5 #令CX寄存器值等于5
atomic.go:10 0x4b1b20 488d542418 lea rdx, ptr [rsp+0x18] #&a操作,即将变量a的地址加载到DX寄存器
atomic.go:10 0x4b1b25 f0480fc10a lock xadd qword ptr [rdx], rcx #atomic.AddUint64原子操作,对变量a的地址进行原子操作,可以看到用的是x86_64 cpu提供的lock和xadd汇编指令配合,xadd进行加法操作,lock对变量a地址上锁
atomic.go:11 0x4b1b2a 48ff442418 add qword ptr [rsp+0x18], 0x5 #a+=5操作,add汇编指令完成
atomic.go:13 0x4b1b2f 440f117c2448 movups xmmword ptr [rsp+0x48], xmm15
atomic.go:13 0x4b1b35 440f117c2458 movups xmmword ptr [rsp+0x58], xmm15
atomic.go:13 0x4b1b3b 488d4c2448 lea rcx, ptr [rsp+0x48]
atomic.go:13 0x4b1b40 48894c2428 mov qword ptr [rsp+0x28], rcx
atomic.go:13 0x4b1b45 8401 test byte ptr [rcx], al
atomic.go:13 0x4b1b47 488d1592a00000 lea rdx, ptr [rip+0xa092]
#...省略二、LOCK汇编指令
2.1、 LOCK
在x86架构下,当指令附加LOCK前缀时,CPU会在执行该指令期间置位LOCK#信号,将指令转换为原子操作。在多核环境下,LOCK#信号确保CPU在信号置位期间独占操作任何共享内存。
LOCK前缀仅可附加于以下指令,且目标操作数必须为内存操作数:
ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC,
NEG, NOT, OR, SBB, SUB, XOR, XADD, XCHG。
2.2、 原理
在单核环境下,不存在对某个内存地址出现竞争读写的情况,故我们只需讨论多核环境。
现代CPU基本都是多核架构,并且为了平衡CPU执行指令与内存读写之间的效率差距,引入了三级缓存,从缓存角度看,其结构如下图:
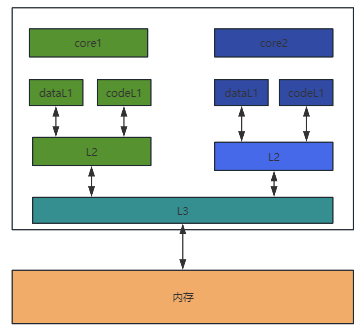
L1 缓存距离 CPU 核心最近,具有最快的访问速度但容量较小。通常,L1 缓存会分为两部分:数据缓存(L1 Data)和指令缓存(L1 code)。这是因为代码和数据的更新策略不同,需要分别进行缓存管理。
L2 缓存的容量比 L1 缓存大,但访问速度稍慢。它充当了中间缓冲区的作用,当 L1 缓存未命中时,CPU 会尝试从 L2 缓存中获取数据。每个核心拥有独立的 L2 缓存。
L3 缓存通常具有更大的容量,但访问速度相对较慢。它在多核心处理器中扮演着重要的角色,多个核心共享 L3 缓存中的数据。如果 L1 和 L2 缓存都未命中,CPU 核心会尝试从 L3 缓存中获取数据,以减少直接访问主内存的高延迟。
主内存的容量更大,但访问速度相对更慢。
2.2.1、 缓存行
由于每一级缓存的访问都是有成本的,所以本级缓存向下一级取数据时的基本单位并不是字节,而是缓存行(cache line)。每个cache line包含Flag、Tag和Data,通常Data的大小是64字节,但不同型号 CPU 的 Flag 和 Tag 可能不相同。数据是按照缓存块大小从内存向缓存加载和从缓存写回内存的,也就是说,即使缓存只访问1字节的数据,也得把这个字节附近以缓存行对齐的64字节的数据加载到缓存中。

- FLAG:用于指示缓存行的状态,例如是否有效、是否被修改等;
- TAG:用于记录该缓存行所对应的内存地址,这样同一缓存块在不同核心的缓存中,也能识别出来;
- DATA:实际存储的数据,通常是64字节。
缓存行大小一般是64字节,从下级缓存取数据一定是64字节,假设内存地址0,1024,那么CPU读取第89地址内容时,会直接取64,128这整个内存块。取内存块时从0开始以64字节为单位进行对齐的。
缓存行(cache line)缓存管理的最小存储单元,也被称为缓存块.
2.2.2、 缓存一致性之MESI协议
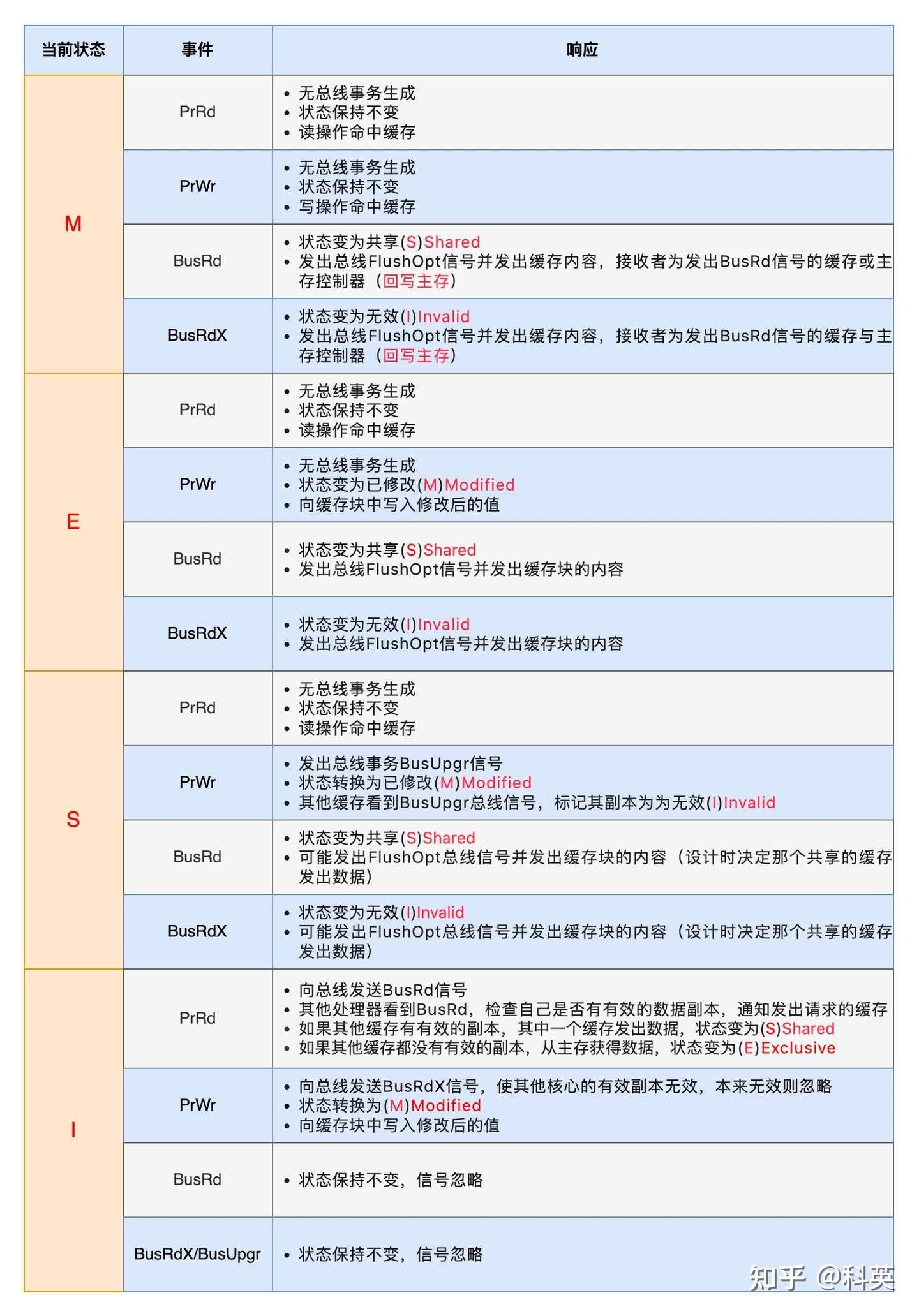
多级缓存在提高CPU性能的同时,由于不是所有核共有的,就有了缓存一致性的问题,因此诞生了MESI协议(一致性协议除了MESI,还有其改进版MOESI、简化版MSI、其他如Dragon协议)。
由伊利诺伊大学(或称伊利诺斯州立大学)的研究者提出,因此也称为伊利诺斯协议(Illinois Protocol)。MESI协议是早期缓存一致性协议的代表,其设计背景与多核处理器的发展密切相关,尤其是在需要解决共享数据一致性问题的场景中。协议名称来源于其核心四种状态:Modified(M)、Exclusive(E)、Shared(S)、Invalid(I)。
1:状态机
- 已修改(Modified,简称M):表示缓存块中的数据与内存中的数据不一致,即缓存块是脏的。如果其他核心要读取这块数据,那么必须先将缓存块的数据写回内存,然后将缓存块的状态变为共享(S)。在这种状态下,确保其他核心可以读取到最新的内存数据,并维护一致性。
- 独占(Exclusive,简称E):表示缓存块只存在于当前核心的缓存中,并且是干净的,即与内存中的数据一致。如果其他核心要读取这个缓存块,那么当前核心会将自己的缓存块的状态变为共享(S)。当当前核心写入数据时,缓存块的状态变为已修改(M)。
- 共享(Shared,简称S)表示缓存块是共享的,存在于当前核心和其他核心的缓存中,并且是干净的,即与内存中的数据一致。在共享状态下,多个核心可以同时读取这个缓存块,而且这个缓存块随时都可以被其他缓存块替换,并且不需要写回内存,因为它的内容与内存中的数据一致。
- 无效Invalid (I):缓存行是无效的。
该状态信息存在缓存行结构的FLAG中.
2:事件
为了解决多个核心之间的数据传播问题,Intel公司提出了总线嗅探(Bus Snooping)策略,即把读写请求事件都通过总线广播给所有核心,各个核心能够嗅探到这些请求,然后根据本地缓存块状态对其进行响应。
1)缓存块收到来自核心的事件
- PrRd事件指的是读取事件,其中Pr代表Processor(处理器)。该事件表示某个核心对一个缓存块发起了一个读取操作,希望获取对这个缓存块的共享访问权限;
- PrWr事件指的是写入事件,其中Pr也代表Processor。该事件表示某个核心对一个缓存块发起了一个写入操作,希望获取对这个缓存块的独占访问权限。
2)缓存块收到来自总线的事件 - BusRd事件表示某个核心发起了一个读操作,希望获取对某个缓存块的共享访问权。该事件使得多个核心能够在需要时同时共享相同的数据,从而提高系统性能并有效管理共享数据。不涉及对缓存块的修改,因此不需要执行失效或写回操作,确保了共享数据的正确同步;
- BusRdX事件表示某个核心发起了一个读-修改-写的操作,希望获取对特定缓存块的独占访问权限。这个事件的发生意味着该核心需要读取该缓存块的数据并执行修改,可能导致其他核心的缓存失效或需要写回内存,以确保在修改之前获取最新的数据状态;
- BusUpgr表示某个核心发起了升级请求,希望从对某个缓存块的共享访问切换到独占访问。这个事件触发时,核心通常需要将其他核心的相同缓存块的状态切换为无效或将其写回内存,以确保在执行修改操作之前,该核心获得最新且独占性的数据状态;
- Flush事件表示某个核心对一个缓存块进行刷新操作。这可能包括将缓存块的数据写回内存或者通知其他核心将其缓存中的对应数据失效。通过执行 Flush 操作,系统确保所有核心使用相同的、最新的数据,避免缓存中的数据与内存不一致;
- FlushOpt事件也表示某个核心对一个缓存块执行刷新操作,但不是写回内存,而是将整个缓存块发送给另一个核心,即缓存到缓存的传递。
------------------------------------------------- MESI协议缓存块在不用状态下收到不同事件的行为
ps:其实缓存一致性,除了多核、多级缓存外,DMA也会引起缓存一致性问题。
在x86发展过程中,不是一开始就是多级缓存的:
1:一开始就是单核直接访问内存;
2:后因为性能问题,即cpu执行指令与访问内存速度上存在巨大差异,引入了多级缓存;
3:后来单核性能也不足,就提出了多核机制,也就引入了MESI等协议(只作用于处理器内部,与DMA无关),形成了现代CPU的普遍架构。
2.2.3、lock原理
早期缓存一致性的解决方案比较粗暴,某个cpu核心LOCK指令发出后会直接锁总线(独占总线),这样其他cpu核心或MDA根本无法通过总线总内存读取数据了,也就不存在缓存一致性问题了。
弊端显而易见,锁范围过大,在引入多级缓存时,为了更好的管理内存,提出了缓存行,基于此,LOCK指令不在锁总线,而是只锁操作值所在的缓存行。
假如两个CPU核心都持有相同的缓存行,且各自状态为S,此时core0 执行lock指令要修改缓存行内某个值,会出现如下流程:
- 总线通过总线嗅探(Bus Snooping)策略检测到冲突,向core1 发出BusRdX事件;
- core1 收到BusRdX事件,将core1本地对应缓存行状态置为I;
- core0 执行操作,将core0本地对应缓存行状态置为M,并更改相应操作值;
- 假如接着core1 也要执行lock指令修改该操作值,总线通过总线嗅探(Bus Snooping)策略检测到冲突,向core0 发出BusRdX事件;
- core0 收到BusRdX事件,将core0本地对应缓存行状态置为I,并通过FlushOpt事件将缓存行发给core1;
- core1收到core0发来的缓存行后,将core1本地对应缓存行状态置为M,并更改相应操作值;
- ...
三、x86缓存发展
- 单核时代(1978--2000 初期)
早期的 x86 CPU(如 8086、80286、80386)是纯粹的单核设计,没有缓存:
无缓存阶段:CPU 直接访问内存,性能受限于内存速度。
缓存引入:
80486(1989):首次在芯片内集成 L1 缓存(8 KB),显著减少内存访问延迟。
Pentium(1993):分离为 指令 L1 缓存 和 数据 L1 缓存(各 8 KB),提升并行性。
Pentium Pro(1995):首次引入 L2 缓存(256 KB--1 MB),但位于 CPU 封装外的独立芯片(速度较慢)。
Pentium III(1999):将 L2 缓存集成到 CPU 芯片内(256 KB),速度大幅提升。
2. 多级缓存的完善(2000 初期)
随着单核性能提升遇到瓶颈,缓存层级逐渐扩展:
L3 缓存的引入:
Intel Xeon(2003):为服务器市场引入 L3 缓存(共享缓存),优化多任务性能。
Core 2 系列(2006):在消费级 CPU 中普及 L2/L3 缓存(如 4 MB L2 缓存)。
缓存逻辑的优化:引入缓存一致性协议(如 MESI)、非阻塞缓存、预取技术等。
3. 多核技术的诞生(2005 年后)
单核频率提升遭遇物理极限(功耗、散热),转向多核并行:
早期尝试:
Pentium D(2005):通过"双芯封装"(两个独立单核)实现"伪多核",无共享缓存。
Core 2 Duo(2006):真正的 原生双核设计,共享 L2 缓存,标志多核时代开启。
多核与缓存的协同:
每个核心独立 L1/L2 缓存:减少核心间竞争。
共享 L3 缓存(如 Intel Nehalem, 2008):提升多核数据共享效率。
NUMA 架构:在服务器 CPU 中优化多核内存访问。
四、x86 DMA发展
DMA(直接内存访问)控制器绕过 CPU,直接读写内存。
如果 CPU 缓存未与内存同步,会导致数据不一致,解决:
1)总线仲裁,当 CPU 和 DMA 同时请求访问内存时,总线仲裁器会按仲裁策略选择优先分给谁,另一个等待。
2)CPU缓存刷新,当 CPU缓存与主存不一致时,DMA 请求访问内存时总线会先让CPU将对应缓存写回主存;
3)DMA将数据写回内存时,强制 CPU 丢弃其缓存中的旧数据(即对应缓存行状态置为I)
| 事件 | 关键产品/技术 | 意义 |
|---|---|---|
| 1976年 | Intel 8257 DMA控制器发布 | 首款商用可编程DMA控制器,奠定基础架构 |
| 1980年 | 8237芯片组集成DMA控制器 | DMA技术普及至PC主板 |
| 1993年 | 奔腾系列芯片组支持UDMA | 优化存储设备性能 |
| 2023年 | 酷睿Ultra集成雷电5与DMA加速 | 融合高速I/O与DMA技术,提升扩展性 |