我用Deepseek + 亮数据爬虫神器 1小时做出輿情分析器
- 一、前言
- [二、Web Scraper API 实战](#二、Web Scraper API 实战)
-
- (1)选择对应的URL
- (2)点击进入对应url界面
- (3)API结果实例和爬取结果展示
- (4)用户直接使用post请求访问Facebook.com报错
- [(5)使用Bright Data 的 API访问 Facebook.com ,爬取comments可以解决上述问题:](#(5)使用Bright Data 的 API访问 Facebook.com ,爬取comments可以解决上述问题:)
- (6)结果分析
- (7)用户心理分析
- [三、Bright Data介绍与注册](#三、Bright Data介绍与注册)
-
- [步骤 1:访问官网](#步骤 1:访问官网)
- [步骤 2:填写信息](#步骤 2:填写信息)
- [步骤 3:验证邮箱](#步骤 3:验证邮箱)
- [步骤 4:完成KYC认证(可选)](#步骤 4:完成KYC认证(可选))
- 四、官方资源
- 个人主页 : ζ小菜鸡
- 大家好我是ζ小菜鸡,我用Deepseek + 亮数据爬虫神器 1小时做出輿情分析器
- 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)
一、前言
在社群媒体高度发达的时代,用户评论和舆情动态成为品牌、产品乃至社会事件的重要风向标。然而,如何快速、系统地收集并分析这些分散在平台上的评论信息,一直是个技术挑战。传统爬虫容易被平台封锁,数据结构复杂,且缺乏高效的情感分析工具。
为了解决这些问题,我尝试结合 Bright Data 的强大爬虫能力与 Deepseek 的自然语言处理模型,打造一个自动化的"舆情分析器"。这个项目的目标是:在最短时间内,实现对 Facebook 评论的抓取、存储与情绪分析,帮助用户快速洞察社群情绪走向。过程中也遇到了一些技术难点,例如反爬机制、数据清洗与模型调优等,本文将逐步分享我的实战过程与解决方案。
二、Web Scraper API 实战
构建了一个完全本地化的多代理 Facebook -Comments分析系统,基于 DeepSeek-R1,并集成 Bright Data 的 API,实现大规模抓取收集Facebook Comments,用于实时趋势分析。
【1】用户操作控制台登录进入之后找到web Scraper,如下图所示:
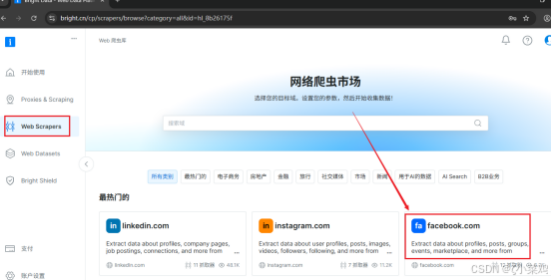
【2】web scrapers在facebook.com提供了12抓取器和8个数据集 如下图所示:
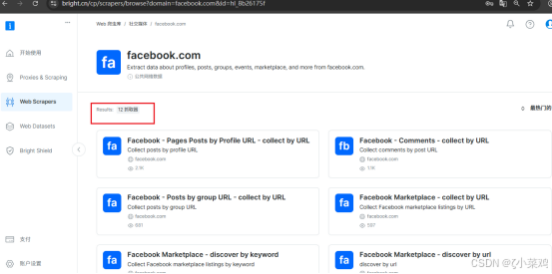
主要展示的是使用Facebook-Comments-collect by URL实现大规模抓取收集Facebook Comments的效果
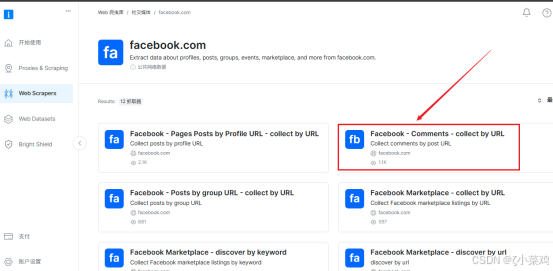
(1)选择对应的URL
web scrapers在 facebook.com 提供了12抓取器和8个数据集,我们需要抓取的是Facebook comments需要选择对应的url 如下图所示:
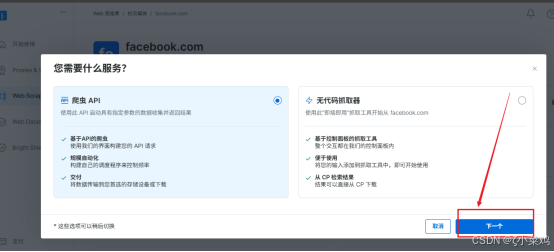
(2)点击进入对应url界面
选择对应url界面,如下图所示:
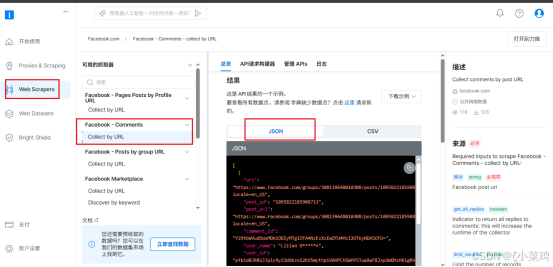
(3)API结果实例和爬取结果展示
在对应的Facebook-Comments URL中web scrapers提供两天一个API结果实例和爬取结果展示,如下图所示:
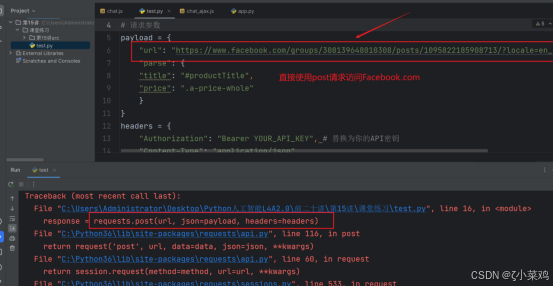
(4)用户直接使用post请求访问Facebook.com报错
Python代码:用户直接使用post请求访问Facebook.com报错,如下图所示:
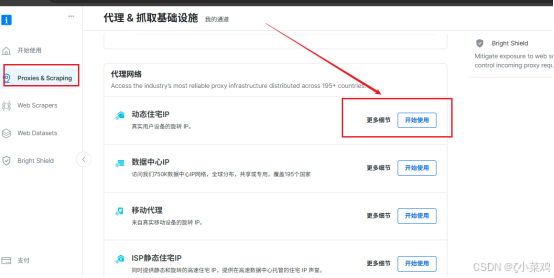
(5)使用Bright Data 的 API访问 Facebook.com ,爬取comments可以解决上述问题:
【1】在用户控制台设置代理网络。如下图所示:
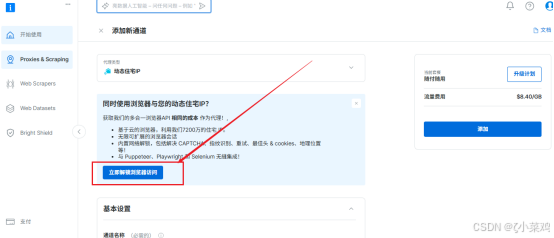
【2】立即解锁浏览器访问。如下图所示:
【3】同意协议 如下图所示:
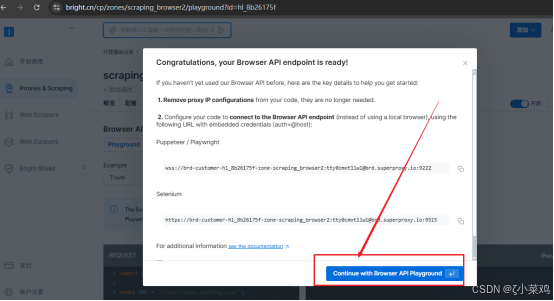
【4】使用平台提供的Chrome DevTools 调试器,如下图所示:
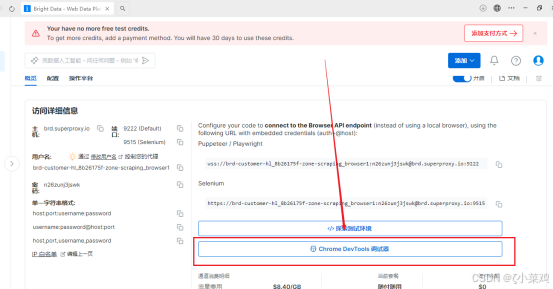
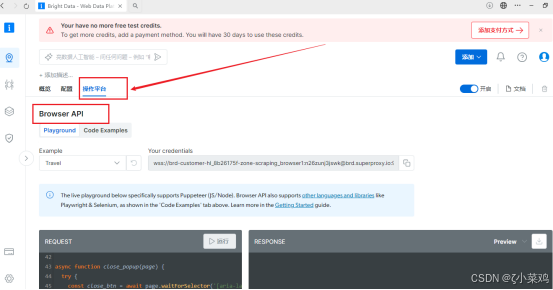
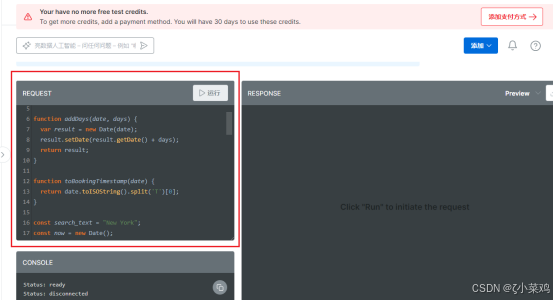
(6)结果分析
将爬取的结果写入comments集合中,并使用deepseek进行结果分析,如下图所示:
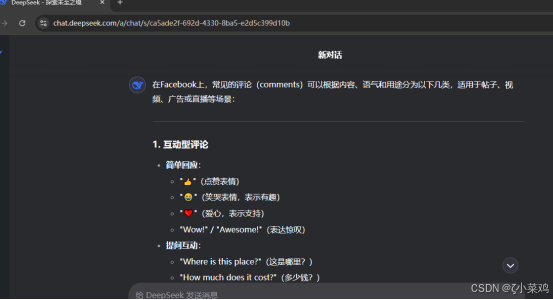
(7)用户心理分析
使用deepseek对Facebook中常见comments进行用户心理分析,如下图所示:
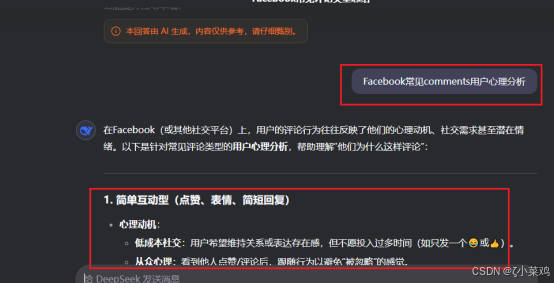
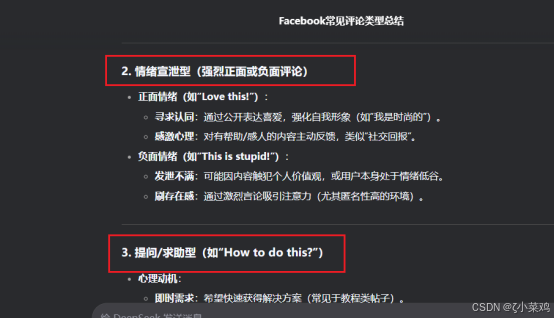
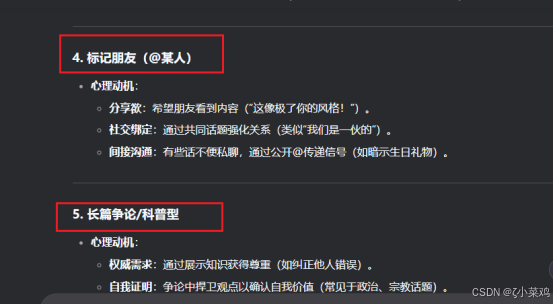
三、Bright Data介绍与注册
Bright Data亮数据是一家领先的网络数据采集平台,提供全球范围的高匿名代理服务和强大的爬虫工具。它支持住宅、数据中心、移动等多种类型的代理IP,并配备自动化浏览器和结构化数据API,帮助用户高效、合规地抓取公开网页数据,广泛应用于电商监控、社交媒体分析、品牌保护等场景。
以下是 Bright Data 注册与使用 的详细图文指南,帮助你快速上手其代理和数据采集服务:
步骤 1:访问官网
- 打开 Bright Data 官网。
- 点击右上角 "登录" 或 "免费使用",如下图所示:
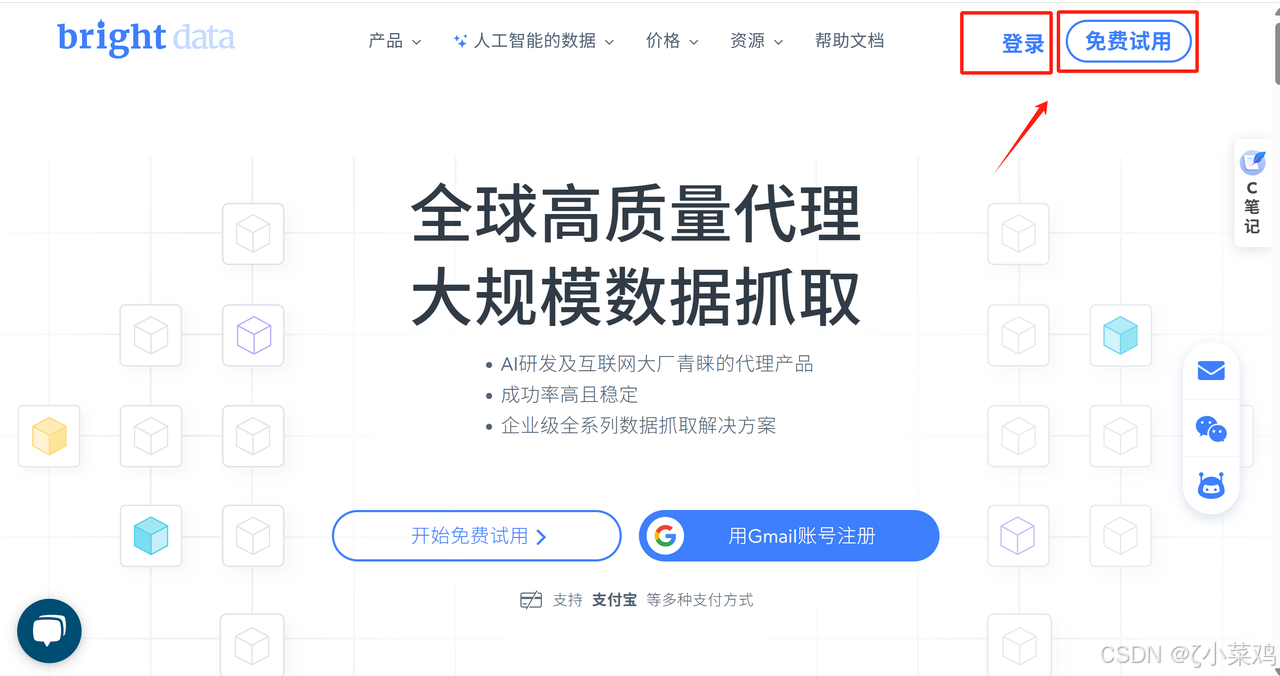
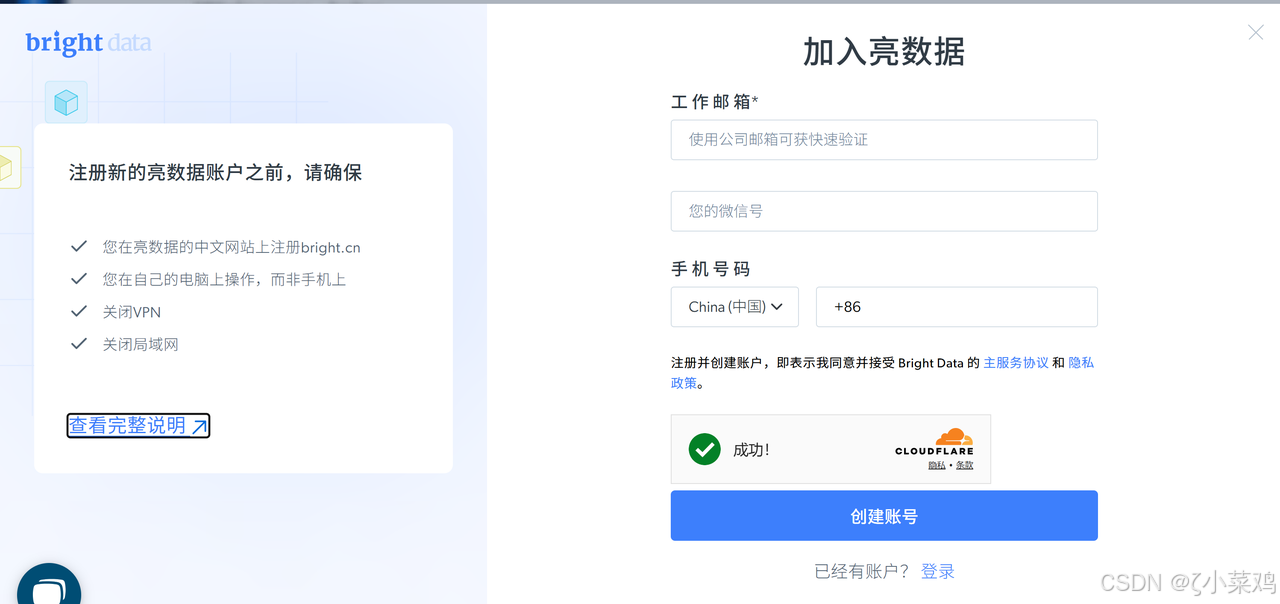
步骤 2:填写信息
- 输入邮箱、密码、公司名称(个人用户可填个人姓名)。
- 选择用途(如市场研究、电商监控等)。
- 阅读并同意服务条款,点击 "创建账号"。
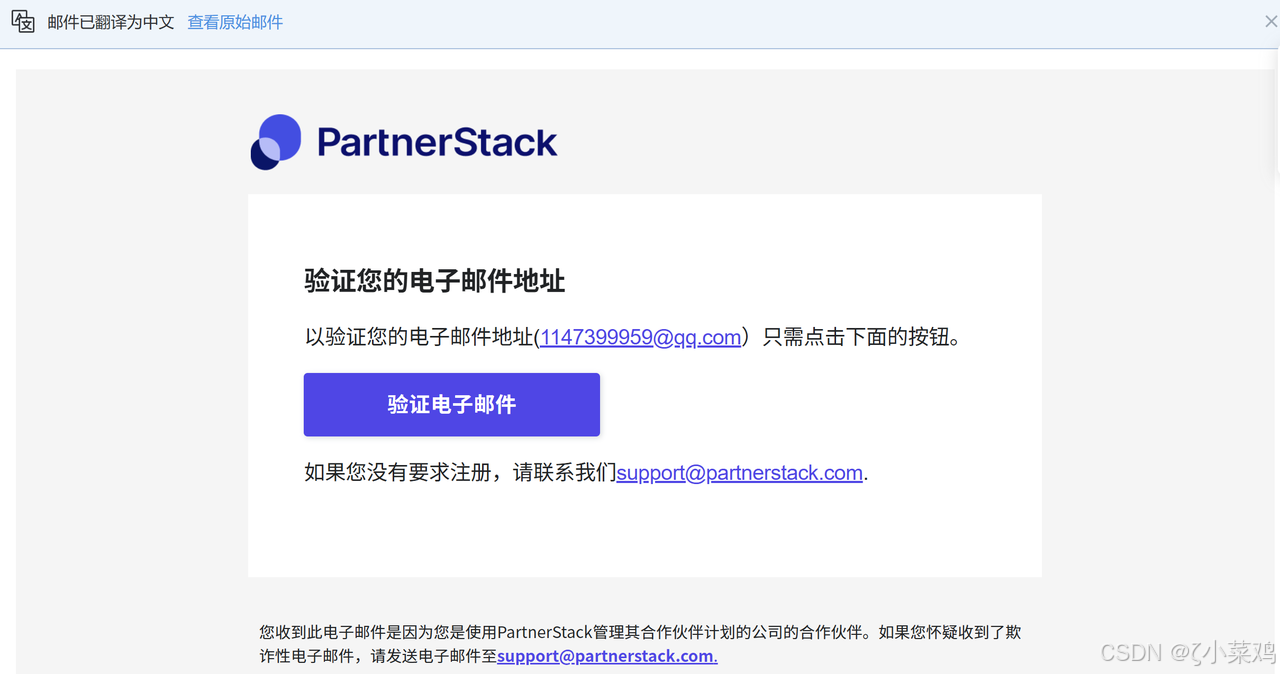
步骤 3:验证邮箱
- 登录邮箱查收验证邮件,点击链接激活账号,如下图所示:
步骤 4:完成KYC认证(可选)
- 部分功能(如住宅代理)需提交身份验证(企业用户可能需要营业执照)。
四、官方资源
这里写注册免费试用,官方网站:https://www.bright.cn
我用Deepseek + 亮数据爬虫神器 1小时做出輿情分析器就到这里,感谢大家阅读,如果文章对你有帮助,欢迎关注、点赞、收藏(一键三连),敬请期待下篇项目具体实现。