技术栈
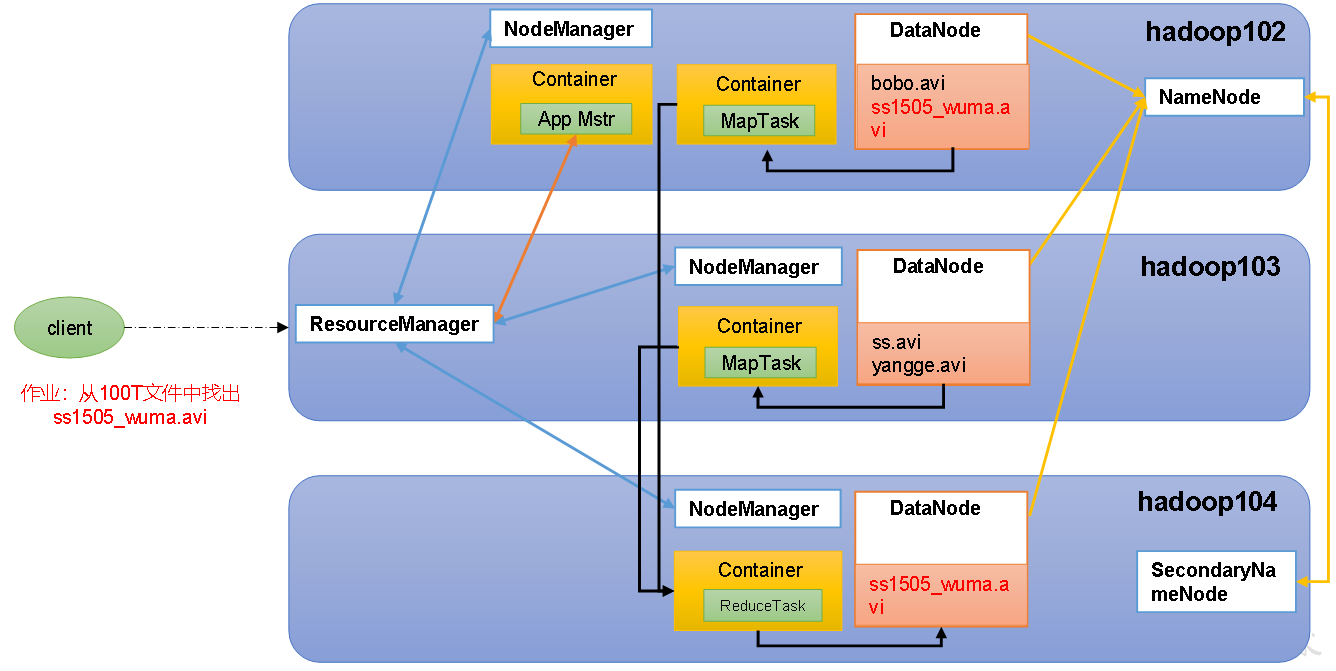
图文展示HDFS、YARN、MapReduce三者关系
计算机人哪有不疯的
2025-05-13 22:27
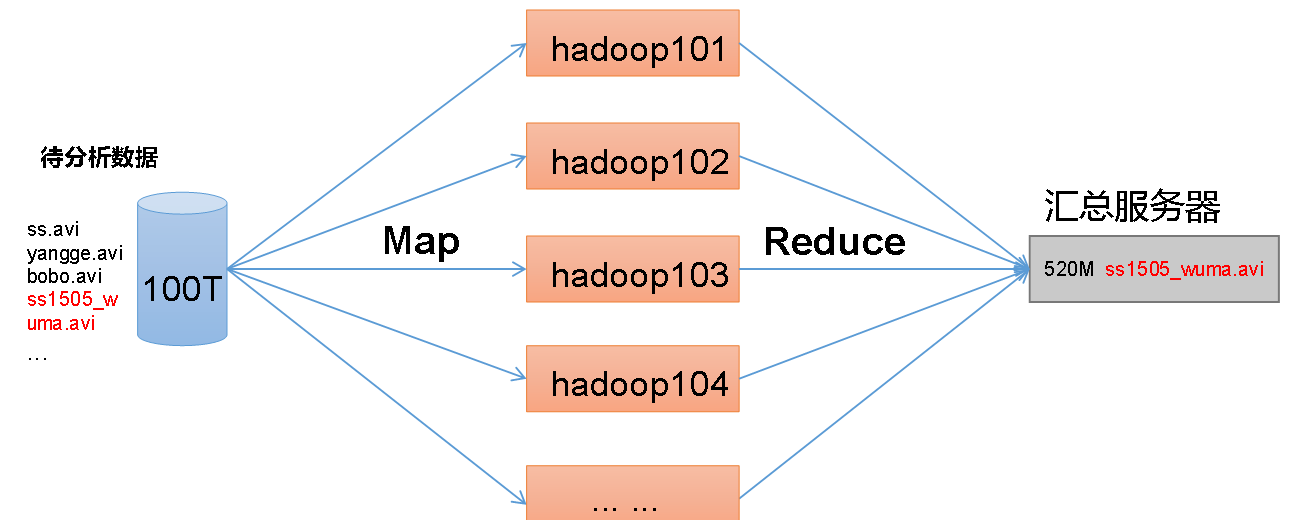
MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
(1)Map阶段并行处理输入数据
(2)Reduce阶段对Map结果进行汇总
HDFS、YARN、MapReduce三者关系
大数据
spark
上一篇:
【001】renPy android端启动流程分析
下一篇:
vue3+dhtmlx-gantt实现甘特图展示
相关推荐
大模型码小白
9 小时前
【Python零基础教程】继承、多态与魔法函数:面向对象编程三大核心特性详解
java
·
大数据
·
开发语言
·
人工智能
·
python
·
ai编程
延凡科技
11 小时前
多场景落地复盘:端边云架构无人机智能巡检系统设计与实践
大数据
·
数据结构
·
人工智能
·
科技
·
架构
·
无人机
·
能源
ifenxi爱分析
12 小时前
爱分析最新报告解读:AI数据基础设施与数据中台的区别
大数据
·
人工智能
品牌全球行
13 小时前
共商共建共享 链接数字未来——“一带一路数字新城(深圳)会客厅筹备办”揭牌仪式在深圳隆重举行
大数据
·
人工智能
数智化管理手记
15 小时前
账龄分析手工统计易遗漏?自动账龄分析工具怎么搭建
大数据
·
网络
·
数据库
·
人工智能
·
数据挖掘
ApacheSeaTunnel
15 小时前
Apache SeaTunnel AI CLI Benchmark:7 款大模型、100 个 ETL 任务实测,谁真正能跑起来?
大数据
·
ai
·
开源
·
大模型
·
数据集成
·
cli
·
seatunnel
·
技术分享
·
数据同步
电商API_18007905247
16 小时前
企业ERP进销存场景|京东商品详情接口自动同步方案|凭证鉴权批量调用技术实操
大数据
·
运维
·
人工智能
·
爬虫
·
数据挖掘
·
网络爬虫
小稻穗
16 小时前
市场调研样本选型坐标系:2026六家国内样本平台能力横向校验
大数据
·
运维
·
数据分析
极光代码工作室
16 小时前
基于Spark的日志监控与分析平台
大数据
·
hadoop
·
python
·
spark
·
数据可视化
wuhanzhanhui
17 小时前
从高强钢到碳纤维!2026武汉汽车材料轻量化制造技术展会,重塑未来造车新范式
大数据
·
汽车
·
制造
热门推荐
01
2026年7月AI圈大地震:GPT-5.6被政府限制、Claude入驻Slack、Anthropic自研芯片
02
GitHub 镜像站点
03
如何新建文件夹? 电脑新建文件夹的4种方法
04
幻兽帕鲁 - 服务器管理员权限与 GM 命令完全指南
05
AI科技热点日报 | 2026年07月01日
06
国内可直接用、免费额度/永久免费的大模型API清单(含 SiliconFlow、火山、阿里、智谱、百度、Kimi、DeepSeek、DMXAPI 等)
07
AI 编程 IDE 全景解析 2026:Agent 全面接管开发链路
08
2026 国产 AI 大模型横评:DeepSeek、通义千问、Kimi、文心一言、星火、豆包谁更能打?
09
微信历史版本含下载地址( Windows PC | 安卓 | MAC )及设置微信不更新
10
Kimi K3 真实体验:全网评价整理,优缺点一次性说清楚