(四) 使用Maven创建新项目
核心的操作步骤如下:
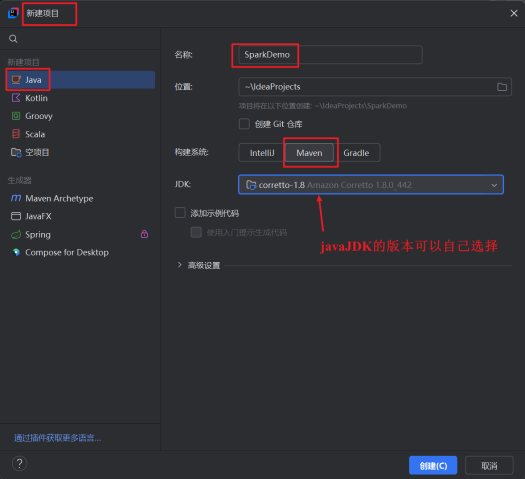
1.启动idea,选择新建项目。
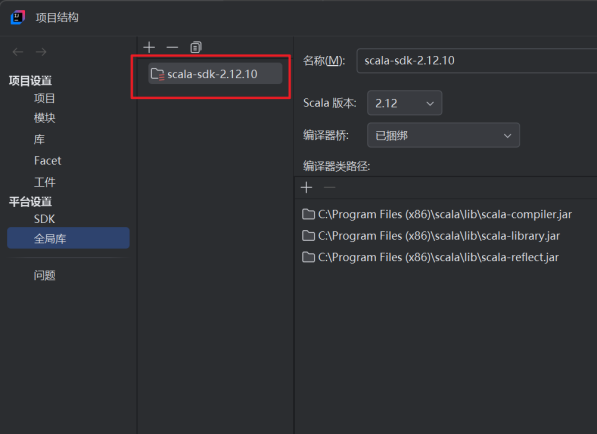
2.将Scala添加到全局库中。
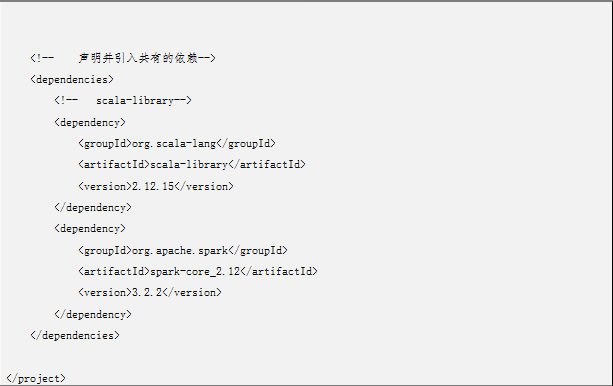
3.设置maven依赖项。修改pom.xml文件,添加如下:

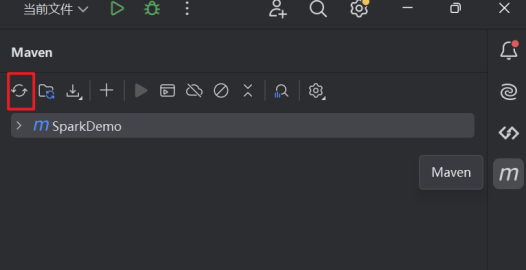
4.下载依赖。添加完成之后,刷新Maven,它会帮助我们去下载依赖。
5.编写代码。修改文件夹的名字。

6.新建Scala类。如果这里没有看到Scala类的选项,就去检查第2步。
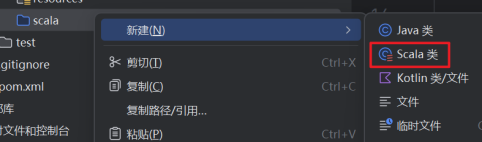
选择Object,输入WordCount
7.编写代码如下
它的功能是wordcount的功能:从指定的文件夹中去读取文件,并做词频统计。

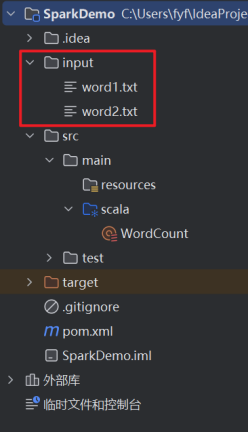
8.准备待统计的词频文件。在项目根目录下建立文件夹input,并穿件两个文本文件:word1.txt, word2.txt。如下图。
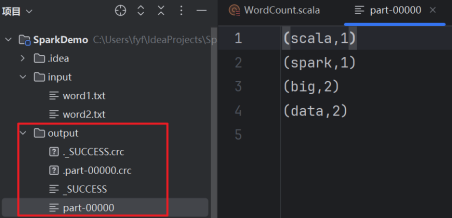
9.运行代码。点击运行代码。
10生成结果如上右图。