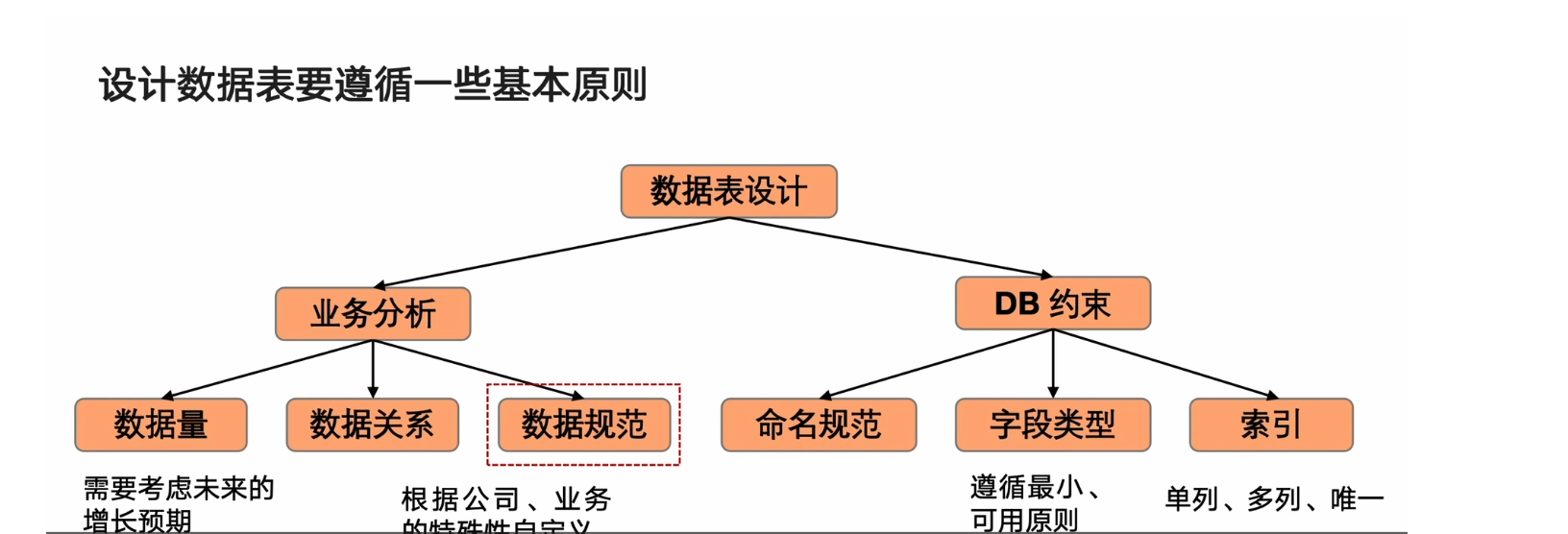
设计高性能数据表的原则
数据库设计经验和技巧
-
单张数据表的字段不宜过多(20个),如果确实存在大量field,考虑拆成多张表或json text存储
-
数据表字段都是not null的,即使没有数据,最好也使用无意义的值填充,并在业务代码中特殊处理
-
索引不应该过多(6个),且是随着业务迭代逐步的修改与优化
-
不追求严格的数据精简(灵活调整),通过字段冗余来优化查询,减少表关联
索引的优化
索引的类型和匹配原则(InnoDB)
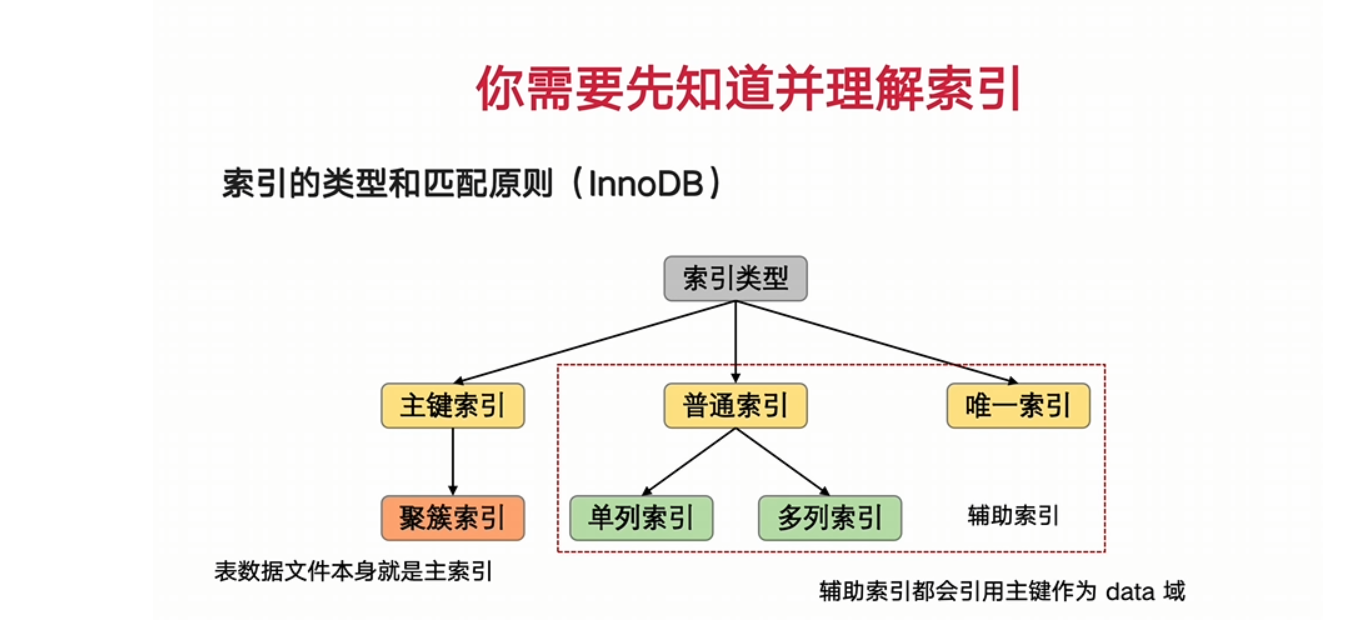
主键索引和辅助索引
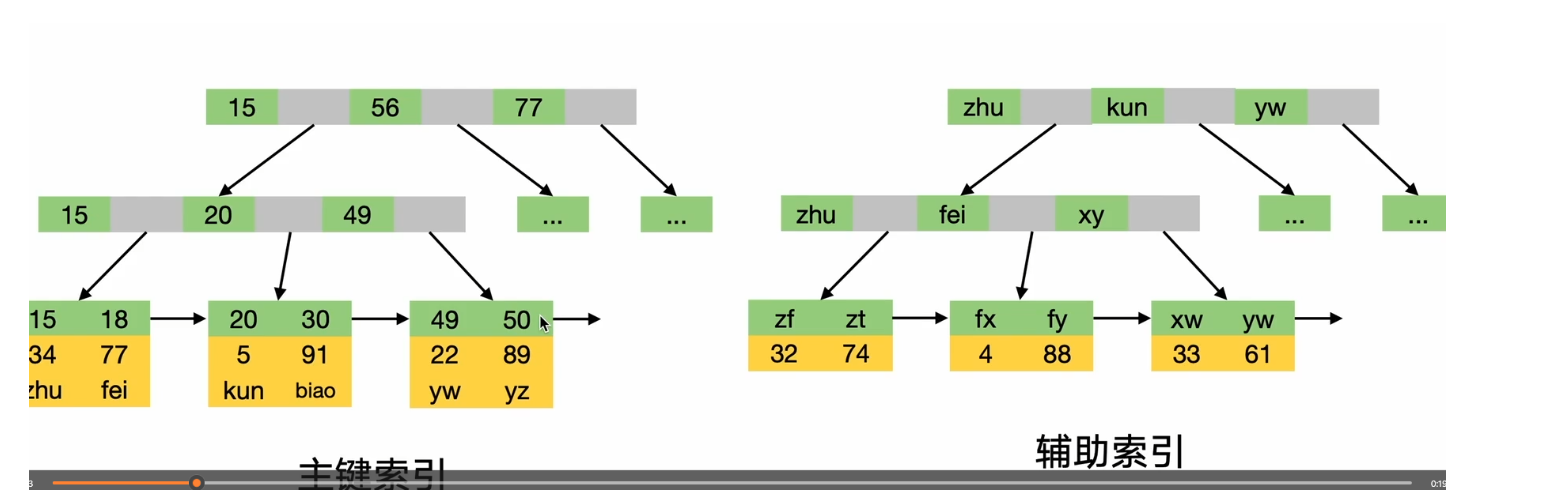
辅助索引的叶子节点存储的是主键值
索引匹配原则
-
索引遵循【最左前缀匹配原则】(针对于多列索引,或者叫联合索引);但是要注意索引字段的顺序
-
触发索引覆盖,不需要回表,速度最优
-
善于使用explain,desc分析执行计划

合理使用乐观锁和悲观锁
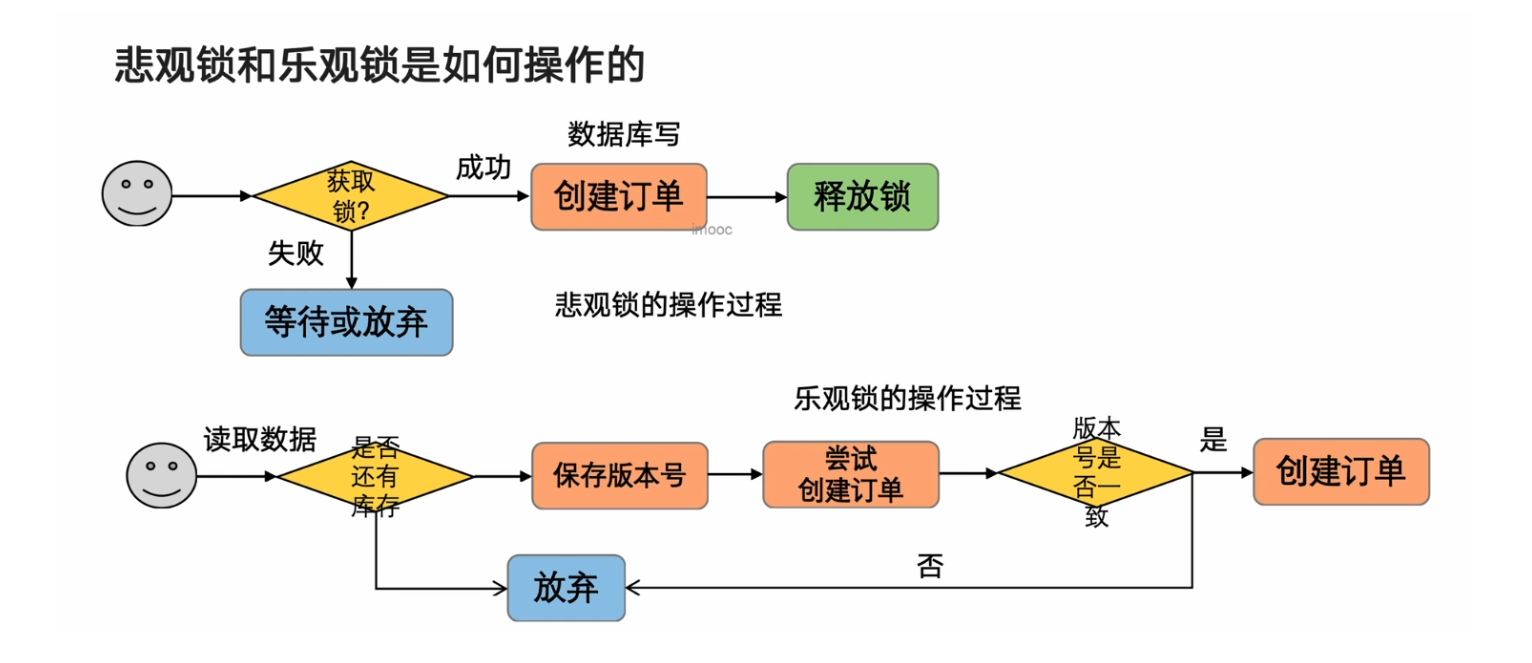
实现乐观锁的三种方法
-
使用数据版本,更新之前对比version是否相同
-
使用时间戳,和version的实现方式类似,更新之前对比时间戳是否相同
-
使用特定的业务字段(例如库存值),更新数据时检查字段值是否满足预期
第一种和第二种在高并发的时候只有一个线程可以修改成功,存在大量的失败,吞吐率不高,第三种降低了乐观锁的粒度,只需要保证salary满足条件即可,提高了并发能力
实现悲观锁的方法与注意事项
- 要想使用悲观锁,那么必须关闭MySQL的自动提交
-
实现悲观锁的语法:select ... for update(MySQL InnoDB默认是Row-Level Lock(行锁))
-
扩展:select...Lock in share mode (共享锁)
慢查询
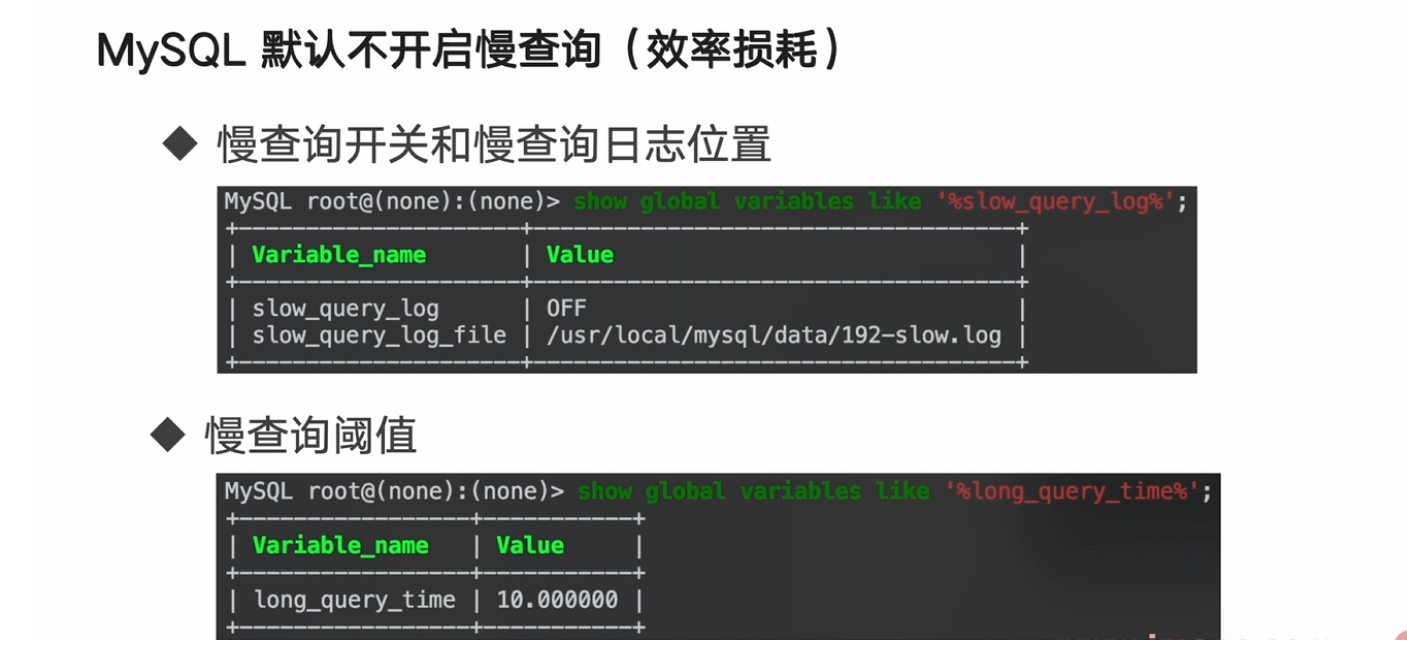
Mysql默认不开启慢查询(效率损耗)
慢查询危害
-
会将暴露出去的http接口拖慢、
-
慢查询存在往往会消耗更多的CPU和内存,影响数据库的整体性能
-
很多慢查询是由于行锁升级到表锁导致的,由此会造成DDL操作的阻塞
慢查询常见的场景与优化策略
-
查询字段没有加索引,或没有利用好索引,由此引发了全表扫描
- 解决思路:利用explain和desc命令查看
-
单表数据量太大,普通查询或limit深分页较慢
- 解决思路:在业务层面进行考虑
-
使用FileSort查询(order by)(排序字段没有加索引, 使用多字段排序,但是排序规则不同)
- 如果查询数据较少,没有超过系统的变量sort_buffer_size时候,则直接在内存中进行排序,是快排,如果超过了变量大小,则会用文件进行排序,也就是归并排序,会导致特别慢,因为涉及到磁盘间文件交换