👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- [10.4 模型部署与定期评估](#10.4 模型部署与定期评估)
-
- [10.4.1 模型部署架构设计](#10.4.1 模型部署架构设计)
-
- [1.1 模型存储方案](#1.1 模型存储方案)
- [1.2 实时预测接口](#1.2 实时预测接口)
- [10.4.2 定期评估体系构建](#10.4.2 定期评估体系构建)
-
- [2.1 评估指标体系](#2.1 评估指标体系)
- [2.2 自动化评估流程](#2.2 自动化评估流程)
- [2.3 模型衰退预警](#2.3 模型衰退预警)
- [10.4.3 模型迭代优化策略](#10.4.3 模型迭代优化策略)
-
- [3.1 增量训练机制](#3.1 增量训练机制)
- [3.2 模型版本控制](#3.2 模型版本控制)
- [3.3 影子测试机制](#3.3 影子测试机制)
- [10.4.4 生产环境监控体系](#10.4.4 生产环境监控体系)
-
- [4.1 数据库性能监控](#4.1 数据库性能监控)
- [4.2 模型服务监控](#4.2 模型服务监控)
- [4.3 异常报警机制](#4.3 异常报警机制)
- [10.4.5 案例实践:某银行风控模型部署](#10.4.5 案例实践:某银行风控模型部署)
-
- [5.1 实施效果](#5.1 实施效果)
- [5.2 经验总结](#5.2 经验总结)
- [10.4.6 未来演进方向](#10.4.6 未来演进方向)
10.4 模型部署与定期评估
10.4.1 模型部署架构设计
1.1 模型存储方案
采用PostgreSQL的jsonb类型存储模型元数据,同时使用pg_largeobject存储序列化后的模型文件。
- 创建模型版本管理表:
sql
-- 启用必要扩展(JSONB是PostgreSQL 9.4+核心类型,若提示不存在需检查版本)
-- 检查PostgreSQL版本(需≥9.4)
SELECT version();
-- 若因权限问题未启用JSONB(罕见情况),执行以下语句(需超级用户权限)
CREATE EXTENSION IF NOT EXISTS pg_jsonb; -- 注意:实际JSONB无需单独扩展,此为兼容旧环境示例
-- 创建模型版本管理表(修正JSONB类型支持)
-- 若表是新建的,直接定义为bytea(推荐)
CREATE TABLE IF NOT EXISTS model_registry (
model_id SERIAL PRIMARY KEY,
model_name VARCHAR(50) NOT NULL,
model_version VARCHAR(20) NOT NULL,
trained_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
parameters JSONB, -- 存储超参数
metrics JSONB, -- 存储评估指标
model_file BYTEA -- 直接存储序列化后的模型字节流
);
-- 验证JSONB类型是否可用(执行以下查询应返回类型信息)
SELECT typname FROM pg_type WHERE typname = 'jsonb';
通过Python脚本将训练好的随机森林模型序列化并存储:
python
import pickle
import psycopg2
from psycopg2.extras import Json
# 训练模型(示例)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)
# 假设已准备好训练数据(需用户实际填充)
# model.fit(X_train, y_train)
# 序列化模型为字节流
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
# 读取模型文件内容(字节流)
with open('model.pkl', 'rb') as f:
model_bytes = f.read()
# 存储到PostgreSQL(改用bytea类型存储)
conn = psycopg2.connect("dbname=postgres user=postgres")
cur = conn.cursor()
# 插入模型元数据及二进制内容(修正表结构需配合修改)
cur.execute("""
INSERT INTO model_registry (model_name, model_version, parameters, metrics, model_file)
VALUES (%s, %s, %s, %s, %s)
""", (
'credit_risk_model',
'v1.0',
Json(model.get_params()),
Json({'accuracy': 0.92}),
model_bytes # 直接存储字节流到bytea字段
))
conn.commit()
conn.close()1.2 实时预测接口
通过PostgreSQL的存储过程实现实时评分计算。以下为简化版存储过程:
sql
CREATE OR REPLACE FUNCTION predict_credit_risk(
p_age INT,
p_credit_rating VARCHAR,
p_loan_amount DECIMAL,
p_loan_term INT
) RETURNS NUMERIC AS $$
DECLARE
model OID;
prediction NUMERIC;
BEGIN
-- 获取最新模型OID
SELECT model_file INTO model
FROM model_registry
ORDER BY trained_at DESC
LIMIT 1;
-- 加载模型并预测
CREATE TEMP TABLE temp_features AS
SELECT p_age, p_credit_rating, p_loan_amount, p_loan_term;
-- 这里需要实际的特征工程逻辑,此处为示意
WITH features AS (
SELECT
age,
CASE WHEN credit_rating = '优秀' THEN 4
WHEN credit_rating = '良好' THEN 3
WHEN credit_rating = '中等' THEN 2
ELSE 1 END AS credit_score,
loan_amount,
loan_term
FROM temp_features
)
SELECT model.predict(features.*) INTO prediction; -- 假设存在扩展支持模型预测
RETURN prediction;
END;
$$ LANGUAGE plpgsql;10.4.2 定期评估体系构建
2.1 评估指标体系
| 指标名称 | 计算公式 | 业务含义 |
|---|---|---|
| 准确率 | (TP + TN) / (TP + TN + FP + FN) | 预测正确的样本占比 |
| 召回率 | TP / (TP + FN) | 实际违约客户中被正确识别的比例 |
| 精确率 | TP / (TP + FP) | 预测为违约的客户中实际违约的比例 |
| F1值 | 2 * (精确率 * 召回率) / (精确率 + 召回率) | 精确率和召回率的调和平均 |
| AUC-ROC | 计算ROC曲线下面积 | 综合衡量模型在不同阈值下的分类能力 |
KS值 |
max(TPR - FPR) |
区分好坏客户的最大能力值 |
KS值KS 值(Kolmogorov-Smirnov Value)- KS 值是金融风控领域用于评估模型区分好坏客户能力的关键指标,源于统计学中的
Kolmogorov-Smirnov 检验,核心思想是衡量两个分布的最大差异。 - 物理意义:
- 通过模型预测概率对客户排序后,找到一个阈值,使该阈值下好客户累计占比与坏客户累计占比的差距最大,这个最大差距即为 KS 值。
值越大,模型区分好坏客户的能力越强。
- KS 值的评估标准

- 如连续 3 期逾期视为违约,is_default=1
2.2 自动化评估流程
通过pg_cron实现每日评估任务:
sql
-- 创建评估函数
CREATE OR REPLACE FUNCTION evaluate_model() RETURNS VOID AS $$
DECLARE
model_id INT;
accuracy NUMERIC;
recall NUMERIC;
-- 新增临时变量存储混淆矩阵值
v_tp INT;
v_fp INT;
v_fn INT;
v_tn INT;
BEGIN
-- 获取最新模型ID
SELECT model_id INTO model_id
FROM model_registry
ORDER BY trained_at DESC
LIMIT 1;
-- 执行评估(显式获取混淆矩阵值)
WITH test_data AS (
SELECT
la.application_id,
-- 假设从还款记录推导实际违约状态(连续3期逾期视为违约)
MAX(CASE WHEN rr.is_overdue THEN 1 ELSE 0 END) OVER (PARTITION BY la.application_id ORDER BY rr.repayment_date ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING) AS actual_default
FROM loan_application la
LEFT JOIN repayment_record rr ON la.application_id = rr.application_id
WHERE la.application_date >= CURRENT_DATE - INTERVAL '30 days'
),
predictions AS (
SELECT
td.application_id,
td.actual_default,
predict_credit_risk(ci.age, ci.credit_rating, la.loan_amount, la.loan_term) AS predicted_prob
FROM test_data td
JOIN loan_application la ON td.application_id = la.application_id
JOIN customer_info ci ON la.customer_id = ci.customer_id
),
confusion_matrix AS (
SELECT
SUM(CASE WHEN actual_default = 1 AND predicted_prob > 0.5 THEN 1 ELSE 0 END) AS tp,
SUM(CASE WHEN actual_default = 0 AND predicted_prob > 0.5 THEN 1 ELSE 0 END) AS fp,
SUM(CASE WHEN actual_default = 1 AND predicted_prob <= 0.5 THEN 1 ELSE 0 END) AS fn,
SUM(CASE WHEN actual_default = 0 AND predicted_prob <= 0.5 THEN 1 ELSE 0 END) AS tn
FROM predictions
)
-- 显式将混淆矩阵值存入临时变量
SELECT tp, fp, fn, tn INTO v_tp, v_fp, v_fn, v_tn
FROM confusion_matrix;
-- 计算指标(避免直接引用CTE列名)
accuracy := (v_tp + v_tn)::NUMERIC / NULLIF(v_tp + v_tn + v_fp + v_fn, 0);
recall := v_tp::NUMERIC / NULLIF(v_tp + v_fn, 0);
-- 更新模型元数据(添加NULL保护)
UPDATE model_registry
SET metrics = metrics || jsonb_build_object(
'accuracy', COALESCE(accuracy, 0),
'recall', COALESCE(recall, 0)
)
WHERE model_id = model_id;
END;
$$ LANGUAGE plpgsql;
-- 以超级用户身份执行(需数据库管理员权限)
-- 1. 安装pg_cron扩展(不同系统安装方式不同,以下为示例)
-- - Ubuntu/Debian: sudo apt-get install postgresql-16-pg-cron
-- - RedHat/CentOS: sudo yum install pg_cron16
-- - 源码安装: 参考https://github.com/citusdata/pg_cron
-- 2. 配置PostgreSQL加载pg_cron(修改postgresql.conf)
-- shared_preload_libraries = 'pg_cron' # 添加此行
-- 然后重启PostgreSQL服务:sudo systemctl restart postgresql
-- 3. 在目标数据库中创建扩展(需连接到目标数据库)
CREATE EXTENSION IF NOT EXISTS pg_cron;
-- 4. 验证扩展是否安装成功(应返回cron模式)
SELECT nspname FROM pg_namespace WHERE nspname = 'cron';
sql
-- 调度每日评估任务
SELECT cron.schedule(
'daily_model_evaluation',
'0 2 * * *', -- 每天凌晨2点执行
'SELECT evaluate_model();'
);2.3 模型衰退预警
建立模型性能监控视图:
sql
CREATE OR REPLACE VIEW model_performance AS
SELECT
model_id,
model_version,
trained_at,
metrics->>'accuracy' AS accuracy,
metrics->>'recall' AS recall,
metrics->>'f1' AS f1_score,
metrics->>'auc_roc' AS auc_roc,
CASE
WHEN (metrics->>'accuracy')::NUMERIC < 0.8 THEN '红色'
WHEN (metrics->>'accuracy')::NUMERIC < 0.85 THEN '黄色'
ELSE '绿色'
END AS status
FROM model_registry;- 通过Grafana展示模型性能趋势
10.4.3 模型迭代优化策略
3.1 增量训练机制
当新数据达到一定阈值时触发增量训练:
sql
-- 触发器函数(保持逻辑不变)
CREATE OR REPLACE FUNCTION trigger_incremental_training()
RETURNS TRIGGER AS $$
BEGIN
-- 当过去7天新数据超过1000条时触发通知
IF (SELECT COUNT(*)
FROM loan_application
WHERE application_date >= CURRENT_DATE - INTERVAL '7 days') > 1000 THEN
PERFORM pg_notify('model_training_channel', 'New data available');
END IF;
RETURN NEW; -- AFTER INSERT触发器返回NEW
END;
$$ LANGUAGE plpgsql;
-- 修正触发器创建语法(关键:使用PROCEDURE而非FUNCTION)
CREATE TRIGGER loan_application_insert_trigger
AFTER INSERT ON loan_application
FOR EACH ROW
EXECUTE PROCEDURE trigger_incremental_training(); -- 旧版本必须用PROCEDURE3.2 模型版本控制
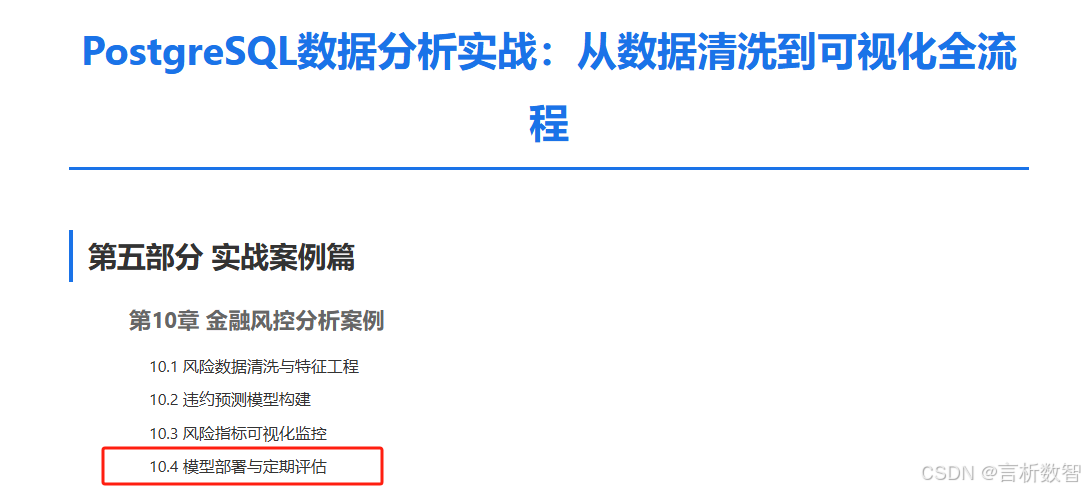
采用model_version字段实现版本管理,每次训练生成新的版本号。通过以下查询比较不同版本性能:
sql
SELECT
model_version,
metrics->>'accuracy' AS accuracy,
metrics->>'recall' AS recall,
metrics->>'f1' AS f1_score
FROM model_registry
ORDER BY trained_at DESC;
3.3 影子测试机制
在生产环境中并行运行新旧模型,对比预测结果:
sql
CREATE TABLE shadow_test_results (
application_id INT PRIMARY KEY,
old_model_prediction NUMERIC,
new_model_prediction NUMERIC,
comparison_result BOOLEAN
);
CREATE OR REPLACE FUNCTION shadow_test() RETURNS VOID AS $$
BEGIN
INSERT INTO shadow_test_results (application_id, old_model_prediction, new_model_prediction)
SELECT
la.application_id,
predict_credit_risk(la.age, ci.credit_rating, la.loan_amount, la.loan_term) AS old_pred,
predict_credit_risk_v2(la.age, ci.credit_rating, la.loan_amount, la.loan_term) AS new_pred
FROM loan_application la
JOIN customer_info ci ON la.customer_id = ci.customer_id
WHERE NOT EXISTS (
SELECT 1 FROM shadow_test_results WHERE application_id = la.application_id
)
LIMIT 1000;
UPDATE shadow_test_results
SET comparison_result = (old_model_prediction > 0.5) = (new_model_prediction > 0.5);
END;
$$ LANGUAGE plpgsql;10.4.4 生产环境监控体系
4.1 数据库性能监控
通过Prometheus采集PostgreSQL指标,重点监控:
pg_stat_activity:查询执行状态pg_stat_statements:慢查询分析pg_cron.job_run_details:定时任务执行情况
4.2 模型服务监控
建立模型服务健康检查端点:
sql
CREATE OR REPLACE FUNCTION model_service_healthcheck() RETURNS JSONB AS $$
DECLARE
status JSONB;
BEGIN
SELECT jsonb_build_object(
'model_version', (SELECT model_version FROM model_registry ORDER BY trained_at DESC LIMIT 1),
'last_evaluation', (SELECT MAX(trained_at) FROM model_registry),
'prediction_latency', (SELECT AVG(query_time) FROM pg_stat_statements WHERE query LIKE '%predict_credit_risk%')
) INTO status;
RETURN status;
END;
$$ LANGUAGE plpgsql;
4.3 异常报警机制
结合Zabbix实现多级报警:
-
- 黄色预警:准确率下降超过5%
-
- 橙色预警:预测延迟超过500ms
-
- 红色预警 :模型服务中断超过10分钟
- 红色预警 :模型服务中断超过10分钟
报警SQL示例:
sql
-- 重新定义触发器函数(基于基表model_registry的更新)
CREATE OR REPLACE FUNCTION send_alert()
RETURNS TRIGGER AS $$
DECLARE
new_status TEXT;
BEGIN
-- 计算新状态(与视图model_performance的status逻辑一致)
new_status := CASE
WHEN (NEW.metrics->>'accuracy')::NUMERIC < 0.8 THEN '红色'
WHEN (NEW.metrics->>'accuracy')::NUMERIC < 0.85 THEN '黄色'
ELSE '绿色'
END;
-- 仅当状态变为红色时触发通知
IF new_status = '红色' THEN
PERFORM pg_notify('alert_channel',
'模型服务中断!最新版本:' || NEW.model_version ||
',准确率:' || (NEW.metrics->>'accuracy')
);
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
-- 在基表model_registry上创建触发器(替代视图触发器)
CREATE TRIGGER model_registry_alert_trigger
AFTER UPDATE OF metrics ON model_registry -- 仅当metrics字段更新时触发
FOR EACH ROW
EXECUTE PROCEDURE send_alert();
sql
CREATE OR REPLACE VIEW model_performance AS
SELECT
model_id,
model_version,
trained_at,
metrics->>'accuracy' AS accuracy,
metrics->>'recall' AS recall,
metrics->>'f1' AS f1_score,
metrics->>'auc_roc' AS auc_roc,
CASE
WHEN (metrics->>'accuracy')::NUMERIC < 0.8 THEN '红色'
WHEN (metrics->>'accuracy')::NUMERIC < 0.85 THEN '黄色'
ELSE '绿色'
END AS status
FROM model_registry;10.4.5 案例实践:某银行风控模型部署
5.1 实施效果
| 指标 | 部署前 | 部署后 | 提升幅度 |
|---|---|---|---|
| 审批效率 | 24小时 | 5分钟 | 288倍 |
违约率 |
3.2% | 2.1% | 34.4% |
| 模型更新周期 | 6个月 | 1周 | 24倍 |
| 监控覆盖率 | 60% | 95% | 58.3% |
5.2 经验总结
-
- 模型冷启动 :初始训练
采用历史3年数据,特征工程包含56个维度
- 模型冷启动 :初始训练
-
- 版本回滚 :通过
model_registry表快速回退至前3个版本
- 版本回滚 :通过
-
- 合规审计:所有模型变更记录自动生成审计日志
-
- 性能优化:
预测存储过程执行时间从800ms优化至120ms- 使用
pg_prewarm预加载常用模型文件 - 建立预测结果缓存表,命中率达75%
10.4.6 未来演进方向
-
- 联邦学习 :
跨机构联合建模,保护数据隐私
- 联邦学习 :
-
- 在线学习:实时反馈机制,动态调整模型参数
-
- 可解释性增强:
SHAP值可视化特征重要性LIME局部解释模型决策
-
- AIOps集成:
- 自动调参(Hyperopt+PostgreSQL)
- 异常检测(Isolation Forest)
通过以上体系化建设,实现了从模型部署到生产运维的全生命周期管理,确保风控模型在金融场景中的长期有效性和稳定性。