文章目录
-
- [🌟 引言](#🌟 引言)
- [🧰 环境准备](#🧰 环境准备)
- [📁 整体代码结构概览](#📁 整体代码结构概览)
- [🛠️ 核心函数详解](#🛠️ 核心函数详解)
-
- [1️⃣ 初始化 Milvus 客户端](#1️⃣ 初始化 Milvus 客户端)
- [2️⃣ 创建集合 Schema](#2️⃣ 创建集合 Schema)
- [3️⃣ 准备索引参数](#3️⃣ 准备索引参数)
- [4️⃣ 删除已存在的集合(可选)](#4️⃣ 删除已存在的集合(可选))
- [5️⃣ 创建集合并建立索引](#5️⃣ 创建集合并建立索引)
- [6️⃣ 插入数据](#6️⃣ 插入数据)
- [7️⃣ 加载集合并执行搜索](#7️⃣ 加载集合并执行搜索)
- [🧪 主程序逻辑](#🧪 主程序逻辑)
- [🧾 示例输出解析](#🧾 示例输出解析)
- [📝 总结](#📝 总结)
- [🔍 延伸学习建议](#🔍 延伸学习建议)
- [Milvus 完整使用示例(Python)](#Milvus 完整使用示例(Python))
🌟 引言
在大规模向量数据检索场景中,Milvus 是一个非常强大的开源向量数据库。它支持高效的相似性搜索、灵活的数据模型设计以及多语言接口。本文将通过 Python 客户端 pymilvus,带你一步步从零开始使用 Milvus 构建一个简单的向量数据库,并实现插入数据与相似性搜索的完整流程。
🧰 环境准备
依赖安装
首先确保你已经安装了 Milvus 及其 Python SDK:
bash
pip install pymilvus我们使用的是 Milvus 2.x 版本中的轻量级客户端模式(即 MilvusClient),适合本地测试和小型项目部署。
📁 整体代码结构概览
我们将实现以下核心功能模块:
- 初始化 Milvus 客户端
- 创建集合(Collection)及其 Schema
- 构建向量索引
- 插入数据
- 执行向量搜索
🛠️ 核心函数详解
1️⃣ 初始化 Milvus 客户端
python
def initialize_client(db_path):
"""
初始化 Milvus 客户端。
:param db_path: 数据库路径
:return: Milvus 客户端实例
"""
return MilvusClient(db_path)db_path:指定本地 SQLite 存储路径,用于单机版 Milvus 轻量运行。MilvusClient:适用于嵌入式或轻量级部署的客户端。
2️⃣ 创建集合 Schema
python
def create_collection_schema():
"""
创建集合的 schema。
:return: 集合的 schema
"""
return CollectionSchema([
FieldSchema("id", DataType.INT64, is_primary=True),
FieldSchema("text", DataType.VARCHAR, max_length=20000),
FieldSchema("embed", DataType.FLOAT_VECTOR, dim=3),
FieldSchema("source", DataType.VARCHAR, max_length=2000)
])CollectionSchema:定义集合的数据结构。FieldSchema:id:主键字段,必须为INT64类型。text:文本内容,最大长度 20000。embed:向量字段,维度为 3。source:数据来源信息,如 PDF 文件名。
3️⃣ 准备索引参数
python
def prepare_index_params(client):
"""
准备索引参数。
:param client: Milvus 客户端实例
:return: 索引参数
"""
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embed",
metric_type="COSINE",
index_type="", # 根据需要设置具体的索引类型
index_name="vector_index"
)
return index_paramsmetric_type:推荐使用"COSINE"表示余弦相似度。index_type:可选值如"IVF_FLAT","HNSW"等,不填时由系统自动选择。index_name:给索引起个名字,便于后续管理。
4️⃣ 删除已存在的集合(可选)
python
def drop_collection_if_exists(client, collection_name):
"""
如果集合存在,则删除集合。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
"""
if client.has_collection(collection_name):
client.drop_collection(collection_name)- 用于清理旧数据,方便调试。
5️⃣ 创建集合并建立索引
python
def create_and_index_collection(client, collection_name, schema, index_params):
"""
创建集合并为其创建索引。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
:param schema: 集合的 schema
:param index_params: 索引参数
"""
client.create_collection(collection_name=collection_name, schema=schema)
client.create_index(collection_name, index_params)create_collection:根据 schema 创建集合。create_index:应用之前配置好的索引参数。
6️⃣ 插入数据
python
def insert_data_into_collection(client, collection_name, data_list):
"""
向集合中插入数据。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
:param data_list: 数据列表(字典格式)
"""
for data in data_list:
client.insert(collection_name, data)- 支持逐条插入,也可以批量插入(传入 list of dict)。
7️⃣ 加载集合并执行搜索
python
def load_and_search_collection(client, collection_name, query_vector, output_fields, limit):
"""
加载集合并执行搜索。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
:param query_vector: 查询向量
:param output_fields: 输出字段
:param limit: 搜索结果数量限制
:return: 搜索结果
"""
client.load_collection(collection_name)
return client.search(
collection_name,
[query_vector],
output_fields=output_fields,
limit=limit
)load_collection:加载集合到内存以便搜索。search:执行向量搜索,返回最相似的结果。
🧪 主程序逻辑
python
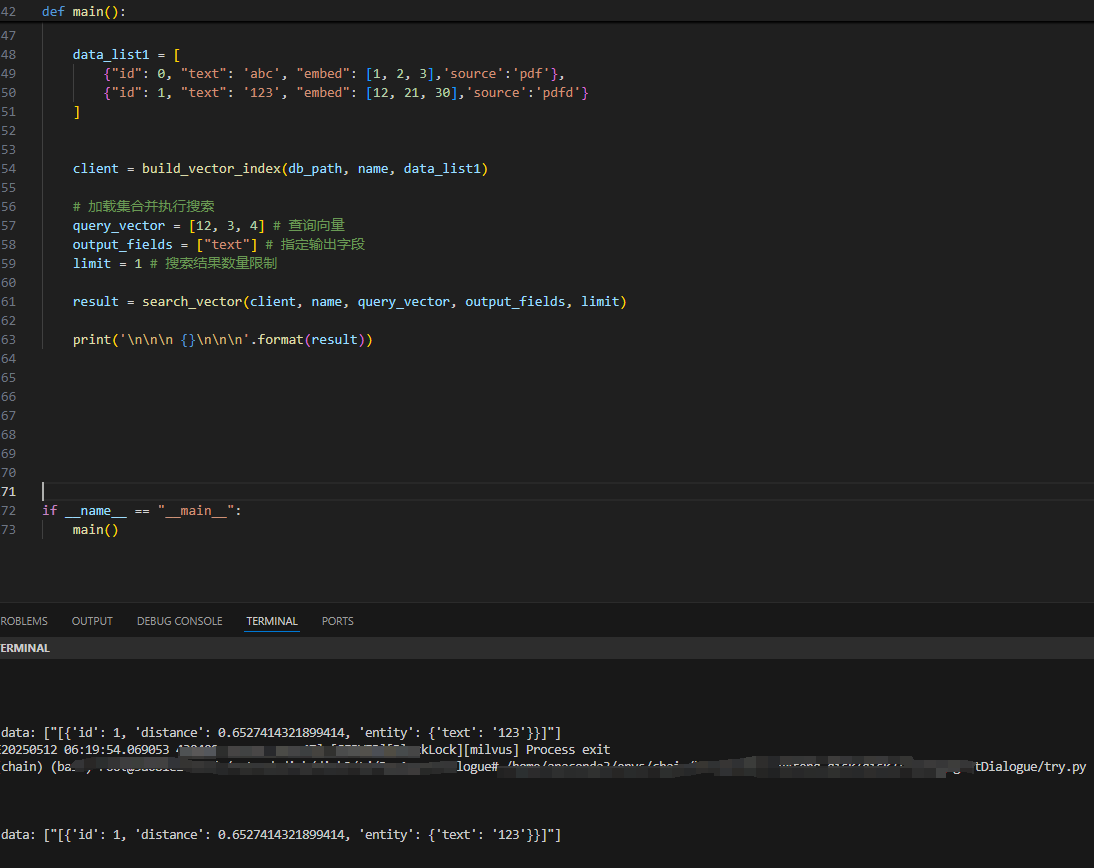
def main():
# 初始化客户端
db_path = 'database/milvus_database/milvus.db'
name = 'demo'
data_list1 = [
{"id": 0, "text": 'abc', "embed": [1, 2, 3], 'source': 'pdf'},
{"id": 1, "text": '123', "embed": [12, 21, 30], 'source': 'pdfd'}
]
client = build_vector_index(db_path, name, data_list1)
# 加载集合并执行搜索
query_vector = [12, 3, 4] # 查询向量
output_fields = ["text"] # 指定输出字段
limit = 1 # 搜索结果数量限制
result = search_vector(client, name, query_vector, output_fields, limit)
print('\n\n\n {}\n\n\n'.format(result))- 构建了一个包含两个向量记录的集合。
- 插入后进行一次基于
[12, 3, 4]的搜索,返回最相似的一条记录的text字段。
🧾 示例输出解析
假设搜索结果如下:
json
[
{
"id": 1,
"distance": 0.98,
"entity": {
"text": "123"
}
}
]id: 匹配记录的 ID。distance: 相似度距离(越小越近)。entity.text: 返回的原始文本内容。
📝 总结
通过上述步骤,我们完成了 Milvus 的基本操作流程:
| 步骤 | 功能 |
| ✅ 初始化客户端 | 连接本地 Milvus 数据库 |
| ✅ 创建 Schema | 定义数据结构 |
| ✅ 创建索引 | 提高向量检索效率 |
| ✅ 插入数据 | 添加向量及元数据 |
| ✅ 搜索向量 | 实现高效相似性匹配 |
🔍 延伸学习建议
- 多维向量支持 :将
dim=3改为你自己的 Embedding 维度(如 768)。 - 索引类型优化 :尝试不同索引类型如
IVF_FLAT,HNSW来提升性能。 - 持久化与集群:考虑升级到 Milvus Standalone 或 Cluster 模式。
- 结合 LangChain / LlamaIndex:将 Milvus 集成进 RAG 架构中。
Milvus 完整使用示例(Python)
完整代码如下:
python
from pymilvus import MilvusClient, CollectionSchema, FieldSchema, DataType
def initialize_client(db_path):
"""
初始化 Milvus 客户端。
:param db_path: 数据库路径
:return: Milvus 客户端实例
"""
return MilvusClient(db_path)
def create_collection_schema():
"""
创建集合的 schema。
:return: 集合的 schema
"""
return CollectionSchema([
FieldSchema("id", DataType.INT64, is_primary=True),
FieldSchema("text", DataType.VARCHAR, max_length=20000),
FieldSchema("embed", DataType.FLOAT_VECTOR, dim=3),
FieldSchema("source", DataType.VARCHAR, max_length=2000)
])
def prepare_index_params(client):
"""
准备索引参数。
:param client: Milvus 客户端实例
:return: 索引参数
"""
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embed",
metric_type="COSINE",
index_type="", # 根据需要设置具体的索引类型
index_name="vector_index"
)
return index_params
def drop_collection_if_exists(client, collection_name):
"""
如果集合存在,则删除集合。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
"""
if client.has_collection(collection_name):
client.drop_collection(collection_name)
def create_and_index_collection(client, collection_name, schema, index_params):
"""
创建集合并为其创建索引。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
:param schema: 集合的 schema
:param index_params: 索引参数
"""
client.create_collection(collection_name=collection_name, schema=schema)
client.create_index(collection_name, index_params)
def insert_data_into_collection(client, collection_name, data_list):
"""
向集合中插入数据。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
:param data_list: 数据列表(字典格式)
"""
for data in data_list:
client.insert(collection_name, data)
def load_and_search_collection(client, collection_name, query_vector, output_fields, limit):
"""
加载集合并执行搜索。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
:param query_vector: 查询向量
:param output_fields: 输出字段
:param limit: 搜索结果数量限制
:return: 搜索结果
"""
client.load_collection(collection_name)
return client.search(
collection_name,
[query_vector],
output_fields=output_fields,
limit=limit
)
def build_vector_index(db_path, db_name,data_dict_list):
"""
为指定字段构建向量索引。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
:param field_name: 字段名称
:param index_type: 索引类型
"""
client = initialize_client(db_path)
# 创建集合 schema 和索引参数
schema = create_collection_schema()
index_params = prepare_index_params(client)
# 删除已存在的集合(如果存在)
drop_collection_if_exists(client, db_name)
# 创建并索引集合
create_and_index_collection(client, db_name, schema, index_params)
# 插入数据
insert_data_into_collection(client, db_name, data_dict_list)
return client
def search_vector(client, collection_name, query_vector, output_fields, limit):
"""
加载集合并执行搜索。
:param client: Milvus 客户端实例
:param collection_name: 集合名称
:param query_vector: 查询向量
:param output_fields: 输出字段
"""
client.load_collection(collection_name)
return client.search(
collection_name,
[query_vector],
output_fields=output_fields,
limit=limit
)
def main():
# 初始化客户端
db_path = 'milvus_database/milvus.db'
name='demo'
data_list1 = [
{"id": 0, "text": 'abc', "embed": [1, 2, 3],'source':'pdf'},
{"id": 1, "text": '123', "embed": [12, 21, 30],'source':'pdfd'}
]
client = build_vector_index(db_path, name, data_list1)
# 加载集合并执行搜索
query_vector = [12, 3, 4] # 查询向量
output_fields = ["text"] # 指定输出字段
limit = 1 # 搜索结果数量限制
result = search_vector(client, name, query_vector, output_fields, limit)
print('\n\n\n {}\n\n\n'.format(result))
if __name__ == "__main__":
main()结果如下: