
一、GPU 与显卡的概念澄清
首先需要明确一个容易误解的概念:GPU 不等同于显卡。
显卡和GPU是两个不同的概念。
【概念区分】
在讨论图形计算领域时,需首先澄清一个常见误区:GPU(图形处理单元)与显卡(视频卡)并非等同概念。通俗理解,GPU是显卡的核心计算单元,二者是包含关系而非全等关系。
【核心组件解析】
显卡作为计算机与显示器的连接枢纽,是由以下组件构成的完整硬件系统:
□ GPU计算芯片(核心处理单元)
□ 显存(VRAM,存储图形数据)
□ 主板接口及供电模块
□ BIOS固件(控制硬件运行)
□ 输出接口(HDMI/DP等)
这一系统通过显卡将计算机处理后的图形数据转换为显示器可识别的信号。
【技术功能演进】
GPU作为专为图形计算设计的微处理器,其技术演进呈现明显分化:
- 基础功能:实现并行图形运算(如3D建模、视频解码)
- 技术扩展:利用并行计算优势,涉足科学计算(如分子建模)、AI训练(如NPU辅助训练)等领域
- 架构革新:从固定功能管线发展到可编程着色器,支持光线追踪等高级渲染技术
【精简类比说明】
若将显卡类比为"图形工作站",GPU则相当于其中的"超级计算核心":
显卡 = GPU + 辅助系统(显存、电源、接口等)
GPU = 专注图形/通用计算的专业处理器
这一区别类似于中央处理器(CPU)与主板的关系------重要组件而非完整系统。
简单来说,显卡是带图形输出功能的 GPU 组件集合,而 GPU 泛指具有计算功能的图形处理器芯片。
【延伸阅读】
(一)本质定义与硬件构成
显卡(Graphics Card)
- 属性 :是计算机系统中独立的硬件组件,必须具备图形输出功能,用于将数字信号转换为图像信号并输出至显示器。
- 核心构成 :
▶ GPU 芯片 :负责图形渲染与并行计算(如 NVIDIA Ada Lovelace 架构 GPU);
▶ 显存(VRAM) :独立存储空间(如 GDDR6 显存),用于缓存图形数据;
▶ 电路板(PCB) :集成供电模块、接口芯片(如 HDMI/DP 控制器)等;
▶ BIOS 固件:存储硬件配置信息,控制初始化流程。
GPU(英文全称:Graphics Processing Unit)
- 属性 :是专注于并行计算的处理器芯片,早期以图形渲染为核心功能,现代 GPU 已扩展至通用计算(GPGPU)领域。
- 应用场景 :
▶ 传统场景 :图形渲染(如游戏、CAD 设计);
▶ AI 场景:深度学习训练 / 推理(如 CUDA 加速的 PyTorch 模型)、科学计算(如气象模拟)。
(二)关键差异对比
| 维度 | 显卡 | GPU |
|---|---|---|
| 功能完整性 | 完整的图形输出解决方案 | 仅为计算核心(需搭配其他组件) |
| 硬件独立性 | 可独立安装于主板 PCIe 插槽 | 可能集成于 CPU(如核显 GPU)或独立存在 |
| AI 计算适配性 | 依赖显存容量与计算单元配置 | 核心计算能力决定 AI 性能(如 Tensor Core 数量) |
| 典型产品 | NVIDIA RTX 4080 显卡 | NVIDIA A100 GPU(计算卡核心) |
(三)AI 开发场景的特殊意义
在人工智能开源项目中,GPU 的 "计算属性" 被高度放大,而显卡的 "显示属性" 退居次要地位:
- 独立显卡的双重角色 :
当用于 AI 计算时,显卡的 GPU 芯片承担张量运算任务(如矩阵乘法),但显存容量、带宽等参数的重要性远超图形渲染性能。例如:
▶ RTX 4090 显卡的 24GB GDDR6X 显存更适合中小型模型训练,而 RTX A6000 专业卡的 48GB 显存则适用于高精度可视化与计算混合场景。 - 核显的 GPU 属性 :
主板集成的核显(如 Intel UHD Graphics)本质上是集成于 CPU 的低功耗 GPU,虽计算性能弱于独显,但可通过 OpenCL 等框架参与轻量级 AI 任务(如图像预处理),同时承担系统显示功能。
(四)常见认知误区
❌ 误区 1:GPU = 显卡
→ 正解:显卡是包含 GPU 的完整硬件系统,而 GPU 可以是独立芯片(如独显 GPU)或集成芯片(如核显 GPU)。
❌ 误区 2:AI 计算只需显卡无需核显
→ 正解:当显卡(如计算卡)专注 AI 计算时,核显的显示功能成为系统交互的必需组件,尤其在显存满载时保障桌面流畅性。
二、核显在 AI 开源项目中的独特价值
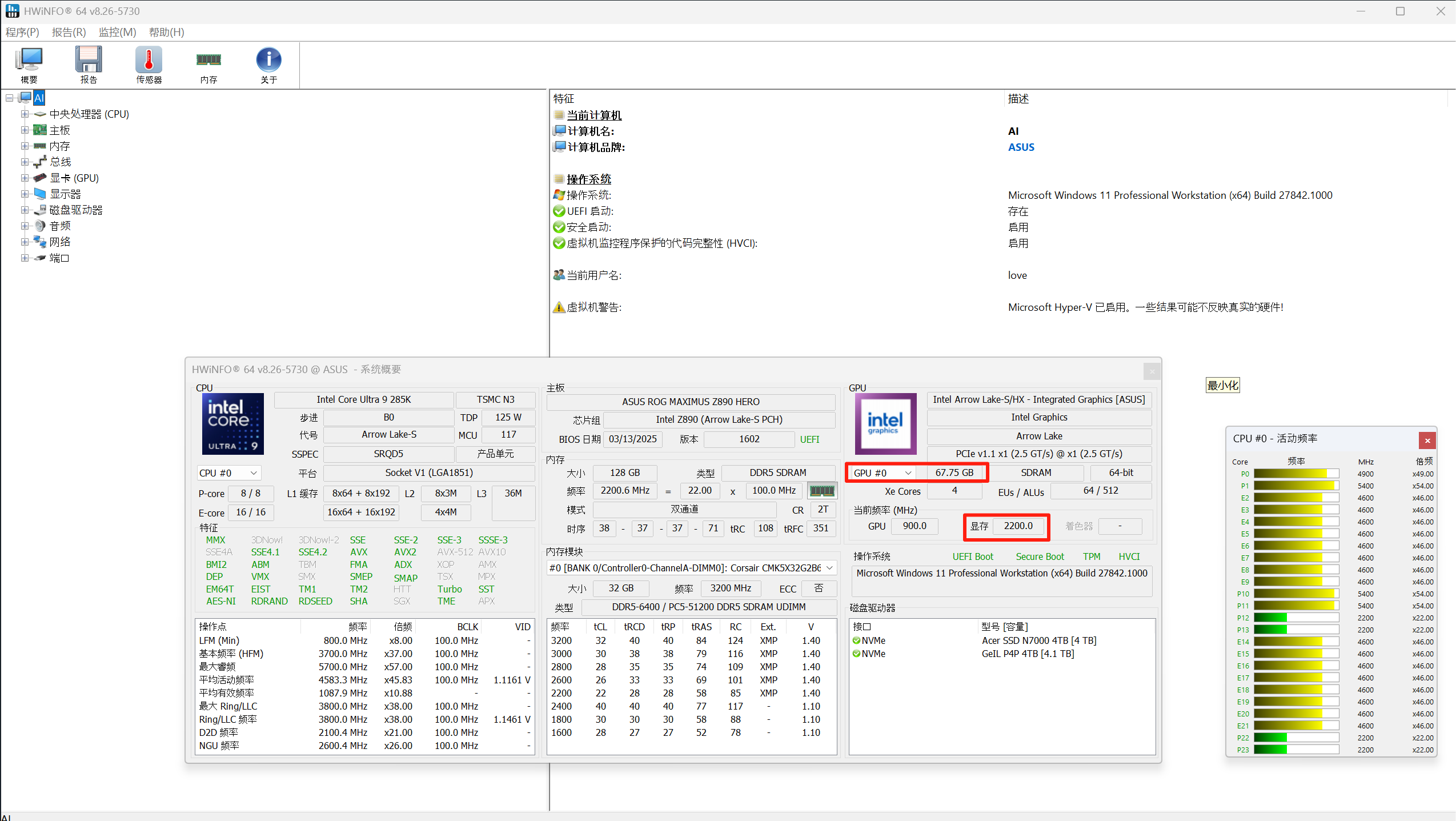
在家用或办公 Windows 电脑运行人工智能开源项目时,即使已配备独立显卡,保留或配备核显仍具有显著必要性,这主要体现在以下方面:
(一)显存瓶颈下的系统流畅性保障
人工智能开源项目(如深度学习框架 TensorFlow、PyTorch 等)对显存资源具有高度依赖性。当独立显卡的显存占用逼近或超过 100% 时,会导致以下问题:
- 系统响应卡顿:独显因全力处理 AI 计算任务,难以兼顾图形输出任务,导致桌面操作、窗口切换等交互操作延迟明显。
- 程序稳定性风险:显存溢出可能引发程序崩溃、系统蓝屏等极端情况,影响开发调试效率。
若将显示器通过光纤 HDMI 2.1 线或 DP 光纤线连接至核显 ,则可构建独显专注计算、核显负责图形输出的分工模式:
- 计算与显示解耦:核显独立承担桌面渲染、视频输出等任务,释放独显的全部显存资源用于 AI 计算,避免因显存竞争导致的系统卡顿。
- 热插拔兼容性优势:部分主板支持核显输出与独显计算的动态切换,即使独显因高负载暂时 "冻结",核显仍能维持显示器正常输出,保障用户对电脑的实时操控。
 核心显卡
核心显卡
(二)多任务协同与能效优化
核显的存在可进一步提升 Windows 系统在 AI 开发场景下的多任务处理能力:
- 异构计算支持:部分 AI 框架(如 OpenCL)支持核显与独显的混合计算,可将轻量化任务(如图像预处理、模型推理)分配至核显执行,充分利用硬件资源。
- 低负载场景能效比优势:在非 AI 计算任务(如日常办公、网页浏览)中,核显的功耗显著低于独显,可延长笔记本电脑续航,或降低台式机的整体功耗。
(三)兼容性与调试便利性
- 驱动与系统兼容性:部分老旧 AI 开源项目或特定框架版本对独显驱动兼容性存在限制,核显可作为备用图形方案,避免因驱动冲突导致项目无法运行。
- 调试环境隔离:在调试 AI 模型时,核显可独立输出调试界面(如 TensorBoard 可视化窗口),避免因独显计算任务中断导致调试信息丢失。
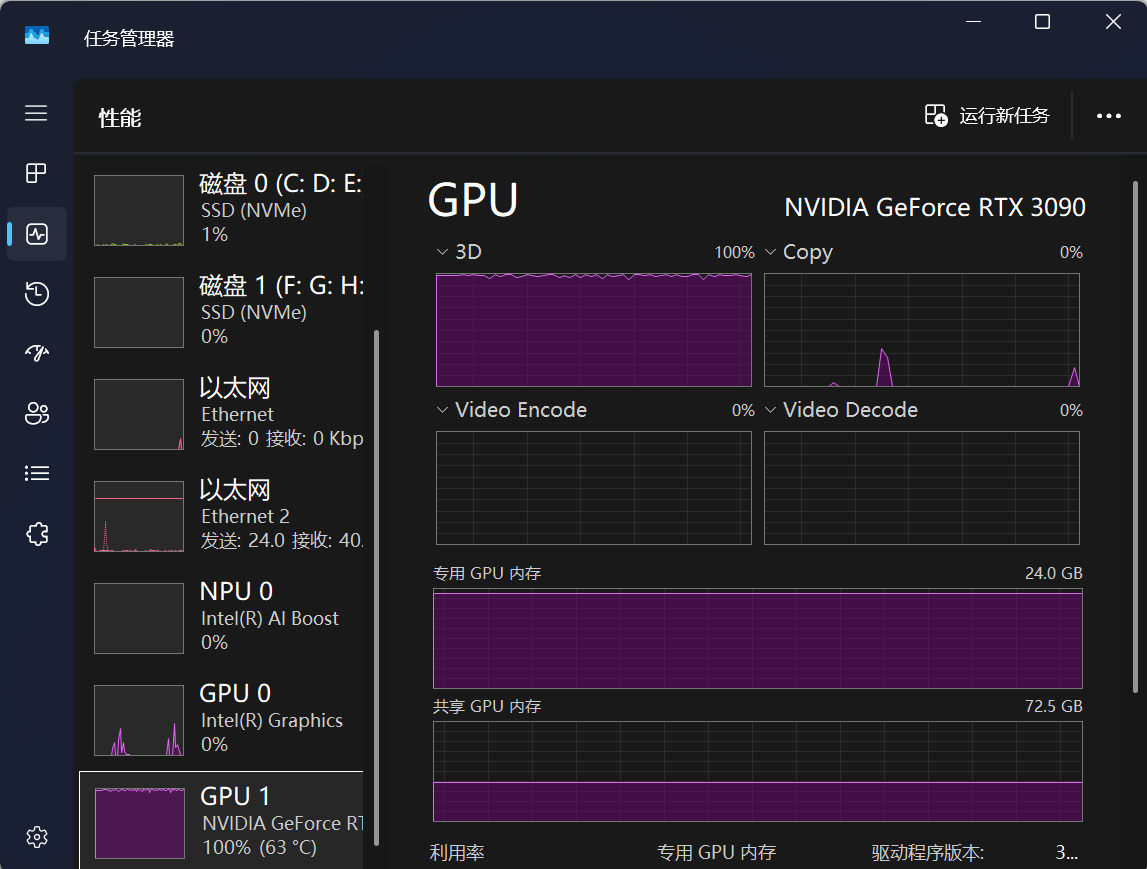 独立显卡显存占用逼近100%影响电脑显示及操纵体验
独立显卡显存占用逼近100%影响电脑显示及操纵体验
三、NPU 的引入:AI 计算的专用加速单元
(一)NPU 的定义与特性
NPU(神经网络处理单元)是专为人工智能任务设计的专用计算芯片,基于张量运算架构(如矩阵乘法)优化,相比传统 GPU 的通用计算架构,在深度学习模型推理任务中具备更高能效比与更低延迟。例如:
- 英特尔第 12 代酷睿处理器集成的 NPU 可加速 Stable Diffusion 图像生成任务,推理速度提升约 30%。
- 部分 AMD 锐龙 APU(如 Ryzen 7 7840HS)通过 VCN(视频编码单元)与 NPU 协同,可实现 AI 视频降噪与编码同步处理。
(二)核显与 NPU 的协同场景
当核显与 NPU 集成于同一 CPU 芯片时(如 Intel UHD Graphics + NPU),可构建轻量级 AI 加速方案:
- 端侧推理优化:在边缘计算场景(如家用安防摄像头数据处理)中,核显负责视频流解码与渲染,NPU 独立执行目标检测模型推理,减少对独显的依赖。
- 低功耗 AI 应用:笔记本电脑在电池模式下,可通过 NPU 运行轻量化模型(如 MobileNet),避免唤醒独显导致的续航骤降。
 NPU
NPU
四、专业卡、游戏卡、计算卡的差异化适配分析
(一)硬件设计目标差异
|---------|----------------|----------------------------|--------------------------|
| 类型 | 核心架构优化方向 | 显存配置特点 | 驱动支持重点 |
| 专业卡 | 图形渲染精度、API 兼容性 | 高容量显存(如 32GB GDDR6) | 支持 OpenGL/DirectX 专业图形接口 |
| 游戏卡 | 实时图形渲染速度 | 中高容量显存(8-24GB GDDR6) | 侧重游戏引擎优化 |
| 计算卡 | 并行计算效率、双精度浮点 | 超大容量显存(如 A100 的 80GB HBM3) | 深度优化 CUDA/ROCm 计算框架 |
(二)对 AI 开源项目的适配性对比
1. 专业卡(如 NVIDIA RTX A 系列)
- 优势场景:需高精度图形渲染的 AI 可视化项目(如 3D 点云标注、医学影像重建),支持 CUDA 与 OptiX 库协同加速。
- 局限性:显存容量虽大但成本高昂,通用计算性能略低于同价位计算卡。
2. 游戏卡(如 NVIDIA RTX 40 系列)
- 优势场景:中小型深度学习模型训练(如 ResNet-34 图像分类),凭借 CUDA 核心数量与显存性价比(如 RTX 4090 的 24GB 显存)成为入门级首选。
- 局限性:缺乏 ECC 显存纠错机制,长时间高负载训练可能因数据位错误导致模型崩溃。
3. 计算卡(如 NVIDIA A10/A40)
- 优势场景:大规模模型训练(如 GPT-2 级别自然语言处理)、科学计算模拟,HBM 显存带宽是 GDDR6 的 3-5 倍,支持多卡 NVLink 互联。
- 局限性:无视频输出接口,必须依赖核显或专业卡实现桌面输出,且功耗较高(如 A100 单卡 300W),需配套散热系统。
 计算卡(GPU)
计算卡(GPU)
(三)核显在异构计算中的桥梁作用
无论使用何种类型显卡,核显均可作为系统图形输出的 "基础锚点":
- 专业卡 + 核显组合:在 CAD 设计与 AI 算法开发并行场景中,核显输出设计界面,专业卡运行 AI 驱动的自动化建模任务。
-
计算卡 + 核显组合:纯计算卡(如 NVIDIA Tesla 系列)无显示功能,必须通过核显实现系统初始化与调试界面输出,避免 "有卡无显" 的尴尬局面。
-
计算卡的图形输出依赖问题:
以 NVIDIA Tesla 系列为代表的专业计算卡(如 A100、V100)完全剥离图形输出功能,仅保留 PCIe 计算接口。这类显卡在 Linux/Windows 服务器中运行 AI 训练任务时,必须通过核显或独立专业卡实现系统显示。例如:
某用户配置的数万元级 AI 服务器采用 NVIDIA A40 计算卡,因无视频接口导致系统初始化时无法输出画面,最终通过主板核显(Intel UHD Graphics)连接显示器完成驱动调试。
计算卡高负载运行时,若未连接核显,用户将无法通过本地显示器监控任务状态,只能依赖远程 SSH 调试,增加操作复杂度。
- 核显对计算卡的必要性延伸 :
即使在 Linux 服务器场景中,核显仍可作为 "带外管理" 的硬件基础 ------ 当计算卡因显存溢出或程序崩溃导致系统无响应时,核显输出的控制台界面(如 GRUB 引导菜单、SSH 登录界面)仍是唯一可交互的本地通道。
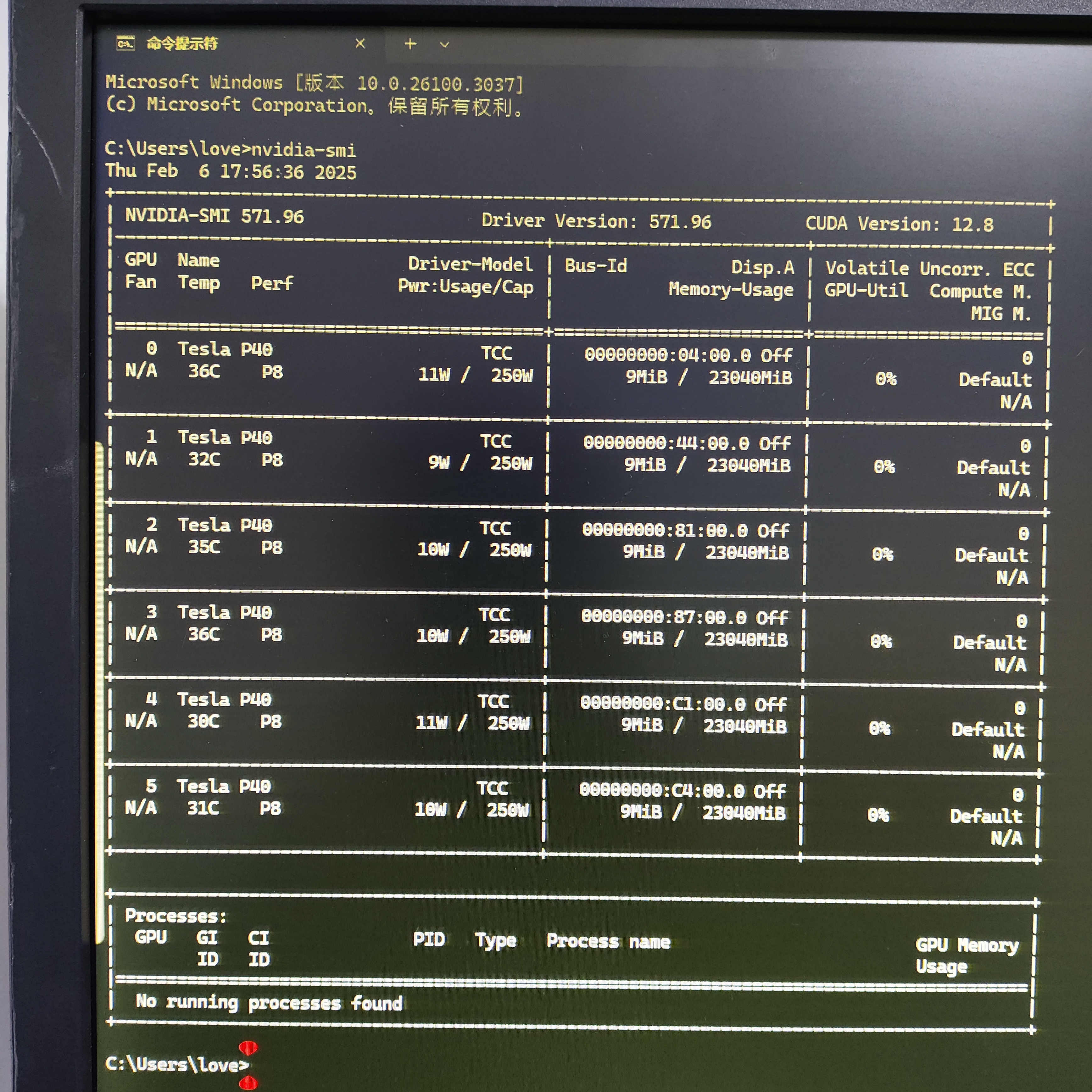 多张计算卡在Windows中,在无优化的情况下,无法完全发挥多卡性能
多张计算卡在Windows中,在无优化的情况下,无法完全发挥多卡性能
如果需要图形支持,需要另外安装GRID驱动,且效果不是很完美
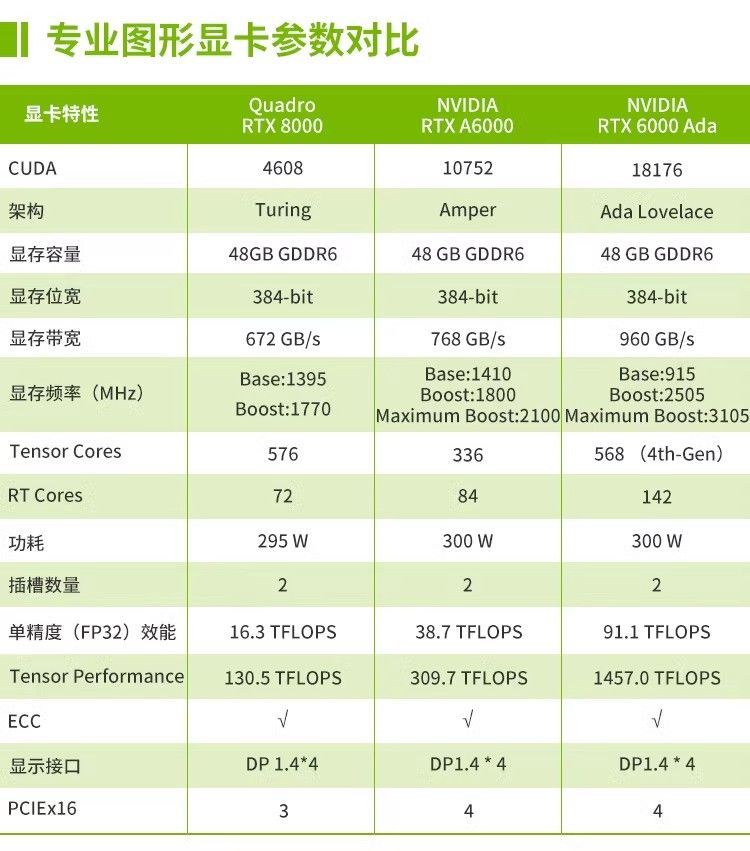 小部分专业卡参数一览
小部分专业卡参数一览
五、硬件配置与连接方案建议(扩展内容)
(一)NPU 兼容 CPU 选择
- Intel 阵营:优先选择带 "P" 或 "U" 后缀的处理器(如 i5-1340P),集成 NPU 与核显,支持 OpenVINO 工具链加速。
- AMD 阵营:Ryzen 7000 系列 APU(如 7840HS)通过 AMD VCN 单元实现视频处理与 NPU 联动,适合多媒体 AI 项目。
(二)显卡类型与核显协同策略
- **游戏卡用户:**核显承担日常显示任务,游戏卡专注 AI 计算,通过 NVIDIA Optimus 技术动态切换(需在 BIOS 中启用核显输出)。
- **计算卡用户:**强制将显示器连接核显,计算卡通过 PCIe 插槽专用于 AI 训练,避免因显示驱动占用计算资源。
- 计算卡服务器用户 :
无论操作系统为 Windows 或 Linux,必须确保主板 CPU 支持核显输出 ,并将显示器物理连接至核显接口。例如:- 使用 AMD Ryzen 9 7950X(带 Vega 核显)搭配 NVIDIA A10 计算卡时,核显负责输出系统桌面,计算卡通过 CUDA 工具链专用于模型训练。
- 避免因 "计算卡无显示功能" 导致的 "黑屏调试" 困境,尤其在 BIOS 设置、驱动安装等关键环节,核显是不可替代的交互入口。
六、典型应用场景扩展(含 NPU 与显卡类型)
- 多模态 AI 开发:核显渲染文本 - 图像联合模型的可视化界面,NPU 加速文本嵌入计算,独显执行图像生成任务,形成 "显示 + 预处理 + 计算" 的流水线架构。
- 边缘 AI 服务器:使用计算卡(如 A10)运行推理模型,核显输出服务器管理界面,NPU 实时处理传感器数据预处理,降低整体功耗。
七、总结
对于 AI 开发硬件架构而言,核显是连接 "计算任务" 与 "人机交互" 的底层枢纽:
- 对游戏卡 / 专业卡用户,核显通过功能分工提升系统流畅性;
- 对计算卡用户,核显是物理显示的刚需组件,甚至在服务器场景中决定了本地运维的可行性。
这一设计逻辑在 Windows 办公环境与 Linux 服务器中具有一致性 ------核显的价值远超 "备用显卡" 范畴,而是现代 AI 开发平台的基础组成部分。
核显的价值已从单纯的 "备用显示" 延伸为 AI 硬件生态中的系统级协调组件 :与 NPU 协同实现轻量级计算,为专业卡 / 计算卡提供显示兜底,与游戏卡形成 "日常 - 计算" 分工。在选择显卡类型时需明确:游戏卡适合快速验证,专业卡适合图形 - AI 融合场景,计算卡是大规模训练的终极方案,但三者均需核显作为系统交互的基础支撑。对于家用或办公场景,建议优先选择带核显的 CPU(如 i5-14600K 或 Ryzen 5 7600G),再根据项目规模叠加对应类型显卡,构建性价比与扩展性兼备的 AI 开发平台。
参考资料(扩展内容)
全文总结 :
在 2025 年人工智能蓬勃发展的背景下,用户对电脑及服务器的 AI 性能期望提升。作者因工作需要完成服务器与前端配置,过程中发现硬件从业者与软件应用间存在认知鸿沟,为突破困境编制 "硬件卡尺" 量表。该量表为硬件选购提供清晰实用评估标准,以不同硬件组件为分类,详细阐述各组件关键参数、示例产品及适用场景。如处理器关键参数包括核心数、主频等,主板涉及芯片组、内存支持等,内存涵盖内存类型、容量等,显卡有显存、GPU 架构等,存储则区分存储类型、接口类型等,全方位为硬件选购者提供全面、可靠参考依据。
重要亮点
- 硬件知识学习的背景与动机:在 2025 年科技浪潮中,AI 技术发展促使人们对设备 AI 性能要求提高。作者在服务器与前端配置工作里,发现硬件从业者与软件应用存在认知隔阂,为解决硬件在特定 AI 场景适配性问题,通过查阅大量资料与真机测试,编制 "硬件卡尺" 量表,助力硬件选购者做出更优决策。
- 处理器选购要点:处理器关键参数多样。核心数和线程数影响并行处理能力,主频关乎单线程性能,不同架构各有优势,缓存大小影响数据处理效率,TDP 与散热功耗相关,集成显卡满足不同图形需求,NPU 支持用于 AI 加速,ECC 支持保障数据可靠性,PCIe 通道支持决定数据传输速率。如 Intel Core Ultra 9 285K 适合多任务与 AI 推理,AMD Ryzen 9 7950X 适用于专业视频编辑等。
- 主板选购要点:主板关键参数包括芯片组,不同芯片组对内存、PCIe 及处理器适配有别;内存支持需关注 DDR5 相关参数及插槽数量;PCIe 插槽带宽影响显卡等设备性能发挥;存储接口涉及 M.2 和 SATA,满足不同存储需求;网络接口分 Wi - Fi 和有线,满足不同场景;扩展接口提供高速传输与设备扩展;供电设计保障电力稳定;BIOS/UEFI 支持方便系统设置;版型分 ATX、Micro - ATX 和 Mini - ITX,适配不同机箱与用户需求。
- 内存选购要点:内存类型上,DDR5 带宽高、功耗低,适合高端应用,DDR4 价格亲民,适用于普通场景。容量选择依使用场景而定,日常办公 16GB 通常足够,专业工作需 32GB 或更高。频率决定数据传输速度,但要与主板、处理器匹配。内存时序中 CL 值越低响应越快,需综合考量。ECC 内存用于对数据准确性要求高的场景,普通用户用非 ECC 内存即可。双通道提升带宽,部分高端主板支持四通道。散热片保证高频率内存稳定运行,兼容性确保与各硬件协同工作。
- 显卡选购要点:选购显卡需区分其与计算卡。关键参数里,显存容量决定处理复杂图形能力,不同分辨率和任务需求不同。GPU 架构是性能核心,NVIDIA 和 AMD 架构各有优势。CUDA 核心 / 流处理器数量影响并行计算能力。光线追踪支持带来逼真光影效果,DLSS 等技术提升游戏帧率。NVLink 支持多卡并行,提升专业领域计算性能。散热设计保障显卡性能稳定,接口类型决定连接方式,功耗影响电源与散热布局。不同型号显卡适用于不同游戏及专业场景。
- 存储选购要点:存储类型主要有机械硬盘(HDD)和固态硬盘(SSD)。HDD 容量大、成本低,适合长期存储不常用数据,但读写速度慢。SSD 以高速读写性能见长,适合做系统盘和常用程序安装盘。在 SSD 接口类型中,SATA 接口价格亲民但带宽受限,M.2 接口的 NVMe SSD 基于 PCIe 协议,能提供更高带宽,如 PCIe 5.0 接口的 NVMe SSD 顺序读取速度可达较高水平,满足对存储速度要求高的场景。