一、概述
人工神经网络(Artificial Neural Network,ANN),是一种模拟生物神经网络结构和功能的计算模型,它通过大量的神经元相互连接,实现对复杂数据的处理和模式识别。从本质上讲,人工神经网络是对人脑神经细胞的数学抽象,试图模仿人类大脑处理信息的方式,以解决各种实际问题。
早在上世纪八九十年代,关于人工神经网络的研究已层出不穷,但限于当时的计算能力和数据能力,未能有效地显现其优势。近十几年以来,在许多新型复杂问题上,传统机器学习技术越发地难以满足需求,而随着计算能力不断提升、大数据不断涌现,人工神经网络凸显出了越来越强大的性能,在图像识别、语音识别、自然语言处理等方面取得了巨大的成功,并从此一发不可收拾,成为机器学习技术的一个重要方向。
二、模型原理
本质上来讲,人工神经网络也就是由多个神经元连接而成的一个多层感知机,通过对外部信息的感知,经过模型的一系列计算,得到预测的输出值。
1. 人工神经元
在人工神经网络中,一个典型的人工神经元接收多个输入信号,每个输入信号都对应一个权重,权重代表了该输入信号的重要程度。这些输入信号与对应权重相乘后进行求和,再加上一个偏置项,得到的结果会通过一个激活函数进行处理。
激活函数的作用是为神经元引入非线性特性,常见的激活函数有 Sigmoid 函数、ReLU(修正线性单元)函数等。以 Sigmoid 函数为例,它将输入映射到 0 到 1 之间,能够将任意实数压缩到这个区间内,适用于二分类问题的输出层;而 ReLU 函数则更为简单高效,当输入大于等于 0 时,输出等于输入,当输入小于 0 时,输出为 0,这种特性可有效解决梯度消失问题。通过激活函数的处理,神经元得到一个输出值,作为其他神经元的输入进行传递。一个典型神经元的结构示意图如下
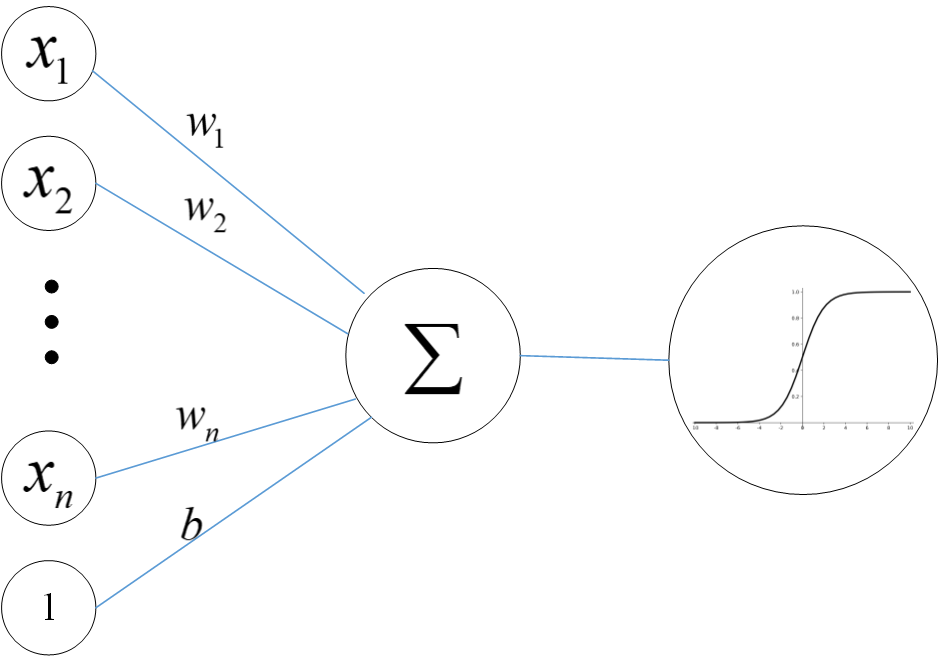
2. 网络结构
人工神经网络由大量神经元相互连接构成,根据连接方式的不同,组成不同的网络结构,其中一种典型的网络结构是全连接前馈式神经网络,它由多个神经元完全地逐层相互连接,也叫做多层感知机(Multilayer Perceptron,MLP),包括输入层、隐含层、输出层。一个典型的全连接前馈式神经网络的结构示意图为
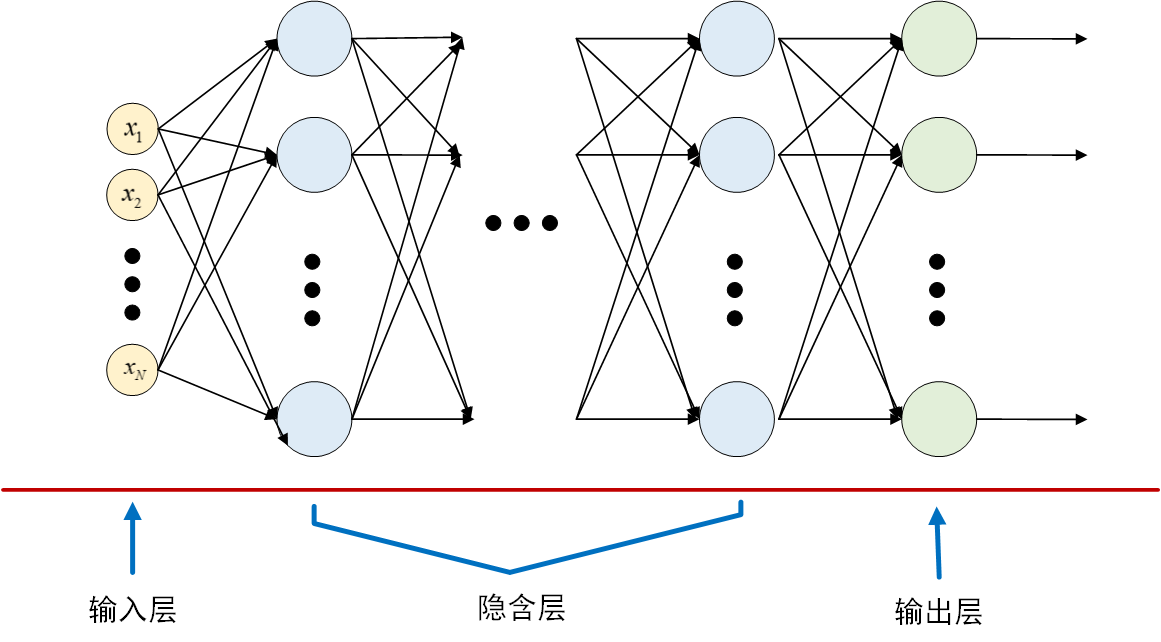
对于分类问题,输出层神经元个数通常对应于类别个数,再在输出层后面加上一个softmax计算,输出各个类别对应的概率,将概率最大的那个输出作为预测类别。假设神经网络输出层向量为\(Z=\left z_1,z_2,...,z_K \\right\),则softmax计算表达式为
\softmax(Z)_i=\\frac{e\^{z_i}}{\\sum_{k=1}\^{K}{e\^{z_k}}} \\
对于回归问题,输出层可直接设计为一个以线性函数为激活函数的神经元,其输出即为连续型变量输出。
3. 模型的训练
神经网络的训练就是训练网络中的参数(权重、偏置等),使得网络的输出能够尽可能地接近真实结果,这一过程通常是通过误差反向传播(Backpropagation,简称 BP)算法来完成。
首先将训练数据输入到网络中,经过前向传播计算得到网络的输出,然后通过损失函数计算网络输出与真实标签之间的误差。常见的损失函数如均方误差(Mean Squared Error,MSE),适用于回归问题;交叉熵损失函数,常用于分类问题。接下来从输出层开始,计算损失函数对每个参数的梯度,沿着负梯度的方向更新参数,可以使损失函数的值减小。在操作过程中,通常会使用优化器,如随机梯度下降(Stochastic Gradient Descent,SGD)及其改进版本 Adam、Adagrad 等,这些优化器通过不同的策略调整学习率(更新的步长),以更高效地找到使损失函数收敛的参数组合。
随着训练的进行,模型在训练数据上的误差逐渐减小,性能不断提升,最终具备对新数据准确预测的能力。
三、Python实现
(环境: Python 3.11,scikit-learn 1.5.1,PyTorch 2.4.0)
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 生成模拟数据
X, y = make_classification(
n_samples=1000, n_features=20, n_informative=10,
n_redundant=5, random_state=42
)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 转换为PyTorch张量
X_train_tensor = torch.FloatTensor(X_train)
y_train_tensor = torch.LongTensor(y_train)
X_test_tensor = torch.FloatTensor(X_test)
y_test_tensor = torch.LongTensor(y_test)
# 创建数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 定义全连接前馈神经网络
class FeedForwardNN(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(FeedForwardNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 初始化模型
input_size = 20 # 输入特征数
hidden_size = 50 # 隐藏层神经元数
num_classes = 2 # 分类类别数
model = FeedForwardNN(input_size, hidden_size, num_classes)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 50
for epoch in range(num_epochs):
for batch_X, batch_y in train_loader:
# 前向传播
outputs = model(batch_X)
loss = criterion(outputs, batch_y)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 评估模型
with torch.no_grad():
outputs = model(X_test_tensor)
_, predicted = torch.max(outputs.data, 1)
accuracy = (predicted == y_test_tensor).sum().item() / y_test_tensor.size(0)
print(f'Accuracy on test set: {accuracy:.4f}')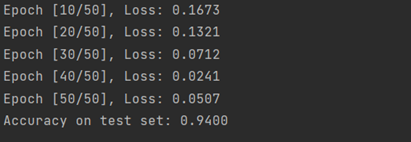
End.