目录
[2.std::operator>>(istream& in, string& s)的改进](#2.std::operator>>(istream& in, string& s)的改进)
[3.getline(istream& is,string& str,char delim='\n')的模拟实现](#3.getline(istream& is,string& str,char delim='\n')的模拟实现)
[4.string(const string& s)的改进(拷贝构造)](#4.string(const string& s)的改进(拷贝构造))
[5.string::swap(string& s)的模拟实现](#5.string::swap(string& s)的模拟实现)
[6.string::operator=(const string& s)的改进](#6.string::operator=(const string& s)的改进)
[(1) 什么是写时拷贝?](#(1) 什么是写时拷贝?)
[(2) 适用场景](#(2) 适用场景)
[(1) 引用计数(Reference Counting)](#(1) 引用计数(Reference Counting))
[示例:简单 COW 字符串](#示例:简单 COW 字符串)
[(2) 智能指针 + COW](#(2) 智能指针 + COW)

1.序言
我们在用之前的代码的时候总是会出现这个或那个限制或问题,所以需要优化代码,提升效率,这一讲将围绕>>运算符、swap、拷贝构造、=运算符重载等部分进行改进或模拟实现,并且会额外介绍一下其余的知识比如:写时拷贝。这讲内容还是比较重要的,所以建议还是看一下。
2.std::operator>>(istream& in, string& s)的改进
2.1原始代码
cpp
istream& operator>>(istream& in, string& s)
{
char ch;
in >> ch;
while (ch != ' ' && ch != '\n')
{
s += ch;
in >> ch;
}
return in;
}2.2问题分析
用以下代码进行测试
cpp
void test1()
{
string s;
cin >> s;
cout << s << endl;
string s1;
cin >> s1;
cout << s1 << endl;
}如果输入:
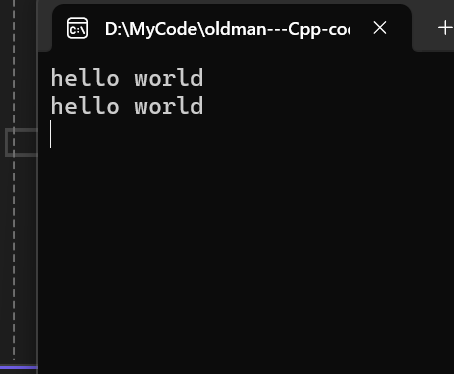
那么是不会结束输入的,因为我们那样写,不管怎么样都拿不到空格和换行,因为本身cin和scanf是拿不到空格和换行的!,所以我们不能这样写,要用另外一个函数叫get(),这个函数的解释我们可以通过deepseek来了解:

我们现在只要了解第一个即可,所以我们可以把这个形式改为:
cpp
istream& operator>>(istream& in, string& s)
{
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}用刚刚的代码进行测试,则结果为:
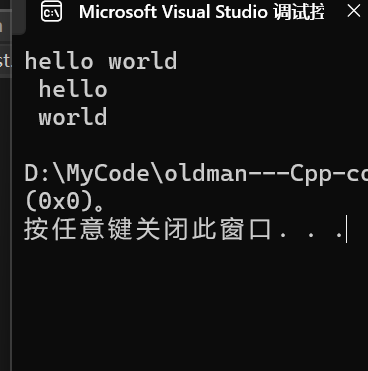
第一行为输入的,后面两行是输出的。但是如果我们用+=的方式是会出问题的,只是在这里演示不出来,如果在其他编译器上这样输入,可能会导致输入Hello world结果打印
Hello
Hello world world
了,所以我们要在开始加:s.clear();
所以变成:
cpp
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
s += ch;
ch = in.get();
}
return in;
}2.3最终改进
如果我们一个一个字符加,要不断扩容,有效率的损失,我们可以参考之前的string的优化,加一个buff来进行存储,但是这个buff,我们把buff这个数组的空间开辟成1024个字符即:char buff1024;因为若提前s.reserve(1024)则可能会有空间的浪费,未知扩容我们最好还是别做;所以最终代码可以改为:
cpp
istream& operator>>(istream& in, string& s)
{
s.clear();
//好处
// 输入短串,不会浪费空间
// 输入长串,避免不断扩容
const size_t N = 1024;
char buff[N];
int i = 0;
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 1023)
{
buff[1023] = '\0';
s += buff;
i = 0;
//这样就不用扩容了
}
}
//可能还有数据没有插入
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}3.getline(istream& is,string& str,char delim='\n')的模拟实现
这个实现之前是讲不了的,因为这个函数也是需要用到我刚刚讲过的知识的,这个函数与>>的区别仅仅是遇到delim时就停止输入了,所以我们只要稍微改变一点代码即可:
cpp
//.cpp
istream& getline(istream& in, string& s, char delim)
{
s.clear();
//好处
// 输入短串,不会浪费空间
// 输入长串,避免不断扩容
const size_t N = 1024;
char buff[N];
int i = 0;
char ch = in.get();
while (ch != delim)
{
buff[i++] = ch;
if (i == N - 1)
{
buff[i] = '\0';
s += buff;
i = 0;
//这样就不用扩容了
}
//一定要记得(我自己也忘记写了)
ch = in.get();
}
//可能还有数据没有插入
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}这两个函数(>>和getline)我们都可以不置为友元函数。
用以下函数进行测试:
cpp
//.cpp
void test1()
{
string s;
td::getline(cin, s);
cout << s << endl;
string s1;
td::getline(cin, s1, '!');
cout << s1 << endl;
}则运行结果为:
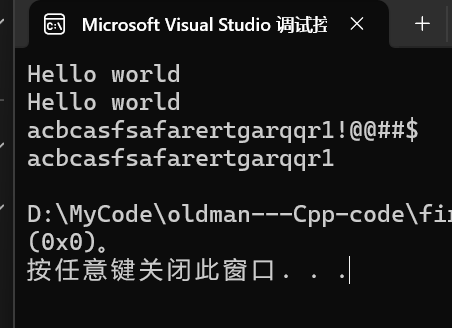
4.string(const string& s)的改进(拷贝构造)
4.1原始版本
cpp
//.cpp
string::string(const string& s)
{
//我们需要多申请一块空间,因为我们还要存储\0
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}这个拷贝构造是用深拷贝的方式,借用了strcpy函数,俗称传统写法,而现代写法更好一些(里面用了swap函数等下我会实现string类专门的swap函数):
4.2现代版本
cpp
//.cpp
//现代版本
string::string(const string& s)
{
string tmp(s._str);
swap(_str, tmp._str);
swap(_size, tmp. _size);
swap(_capacity, tmp._capacity);
}这种方法没有提高效率,只是创建了一个临时对象,由于通过tmp来进行交换,所以tmp的改变不会影响s,但是如果我们直接string tmp(s)则会造成死循环!
如果我们用之后实现的swap那么就可以直接这样写:
cpp
//.cpp
//现代版本(改进)
string::string(const string& s)
{
string tmp(s._str);
swap(tmp);
}我们要使用的时候可以直接string s;string s1(s);即可。
5.string::swap(string& s)的模拟实现
这个东西的实现如果直接创建三个临时变量(_str,_capcity,_size的类型),这样写法太麻烦了,而且我们实现的时候可以用库里面的swap,不过一定要指定类域,否则会直接从该类域找函数了,这样会导致参数不匹配而报错!
cpp
//.h
void swap(string& s);
//.cpp
void string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}6.string::operator=(const string& s)的改进
我们也可以根据拷贝构造的改进写出赋值运算符重载函数的改进:
6.1原始版本
cpp
//.cpp
//原始版本
string& string::operator=(const string& s)
{
//开辟新空间,释放旧空间
delete[] _str;
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
return *this;
}6.2现代版本
cpp
//.cpp
//现代版本
string& string::operator=(const string& s)
{
//开辟新空间,释放旧空间
if (this != &s)
{
string tmp(s._str);
swap(tmp);
}
return *this;
}当然还有第二种方式:
cpp
//.cpp
//现代版本(2)
string& string::operator=(string s)
{
swap(s);
return *this;
}因为s是形参,不是实参的别名,故可以直接交换,建议用第二种写法。但是一定不要把第二种写法的形参改为引用了!
7.*引用计数的写时拷贝(扩展)
这里涉及到的内容非常多,到deepseek的搜索结果后可以跳过到总结部分。
我们先看引用计数,这个的意思是有几个对象指向一块相同的空间就用引用计数,也就是说假设s1、s2都是s3的别名,那么这个就是s3的引用计数就是2,这样拷贝对象的代价就低很多了,因为不用开辟空间拷贝数据了,而且析构时也不是直接delete\[\]了,而是看是否有另外一个对象指向这块空间了,若s1、s2指向同一块空间,若s2先析构,则引用计数--,如果引用计数不是0,则代表还有对象指向这个空间,则这个时候不能释放该空间。这种方式保证了不会一块空间被释放多次的问题了!
但是这样还会存在一个对象修改还会影响另外一个的问题,如果s1修改了,那s2也修改了,我们不希望这样的情况发生,这个就需要写时拷贝,假设我要把s1修改,然后要看引用计数,如果引用计数为1,则能直接修;否则s1改变,我就需要拷贝,把引用计数--后再进行深拷贝。写时拷贝就是谁写谁先深拷贝再修改,本质就是延迟拷贝。但是这样很麻烦了。
因此这种方式本质上是一种赌博,只要对象不修改就赚大了(拷贝后不进行修改就赚了),因为若编译器未在拷贝构造时优化,比如我们string func(){string ret="abcdef";return ret;}再用string s = func();那么就会有三次拷贝,这个之前说过(讲类的构造的时候,之前写过博客);如果编译器没有优化,那么这种引用计数的写时拷贝就赚麻了,因为它不一定会修改的,就算要修改要深拷贝,代价也差不多。
在string部分,这个技术已经被淘汰了,但是其他的地方可能还会用,比如Liunx、智能指针里面会用到!
如果想要详细了解这个部分的话我们可以看一下Deepseek的搜索结果:
写时拷贝(Copy-On-Write, COW )是一种延迟拷贝 的优化技术,在对象被多个引用共享时,只有在真正需要修改数据时才进行实际的拷贝。这种技术广泛应用于字符串、智能指针、文件系统等场景,以减少不必要的内存复制。
(1) 什么是写时拷贝?
-
默认共享:多个对象引用同一块内存(避免立即拷贝)。
-
修改时分离:当某个对象尝试修改数据时,才进行真正的拷贝(深拷贝)。
-
节省资源:减少不必要的内存复制,提高性能。
(2) 适用场景
-
不可变数据(如字符串、只读文件)。
-
多引用共享 (如
std::shared_ptr的引用计数)。 -
大对象优化(避免频繁深拷贝)。
实现方式
(1) 引用计数(Reference Counting)
-
每个对象维护一个引用计数器,记录有多少个引用指向它。
-
引用增加 :计数器
+1。 -
引用减少 :计数器
-1,如果count == 0,释放内存。 -
修改时检查 :如果
count > 1,先拷贝再修改。
示例:简单 COW 字符串
cpp
#include <iostream>
#include <cstring>
class CowString {
private:
char* data; // 实际字符串数据
int* ref_count; // 引用计数器
public:
// 构造函数
CowString(const char* str = "") {
data = new char[strlen(str) + 1];
strcpy(data, str);
ref_count = new int(1); // 初始引用计数=1
}
// 拷贝构造函数(共享数据,不拷贝)
CowString(const CowString& other)
: data(other.data), ref_count(other.ref_count) {
(*ref_count)++; // 引用计数+1
}
// 写时拷贝:修改数据时才真正拷贝
char& operator[](size_t index) {
if (*ref_count > 1) { // 如果被共享,先拷贝
char* new_data = new char[strlen(data) + 1];
strcpy(new_data, data);
(*ref_count)--; // 旧数据引用-1
data = new_data; // 指向新数据
ref_count = new int(1); // 新数据引用=1
}
return data[index]; // 返回可修改的引用
}
// 析构函数
~CowString() {
if (--(*ref_count) == 0) { // 引用计数归零时释放
delete[] data;
delete ref_count;
}
}
// 打印字符串和引用计数
void print() const {
std::cout << "String: " << data << " (Refs: " << *ref_count << ")" << std::endl;
}
};
int main() {
CowString s1 = "Hello"; // s1 引用计数=1
CowString s2 = s1; // s2 和 s1 共享数据,引用计数=2
s1.print(); // String: Hello (Refs: 2)
s2.print(); // String: Hello (Refs: 2)
s2[0] = 'J'; // 写时拷贝!s2 现在独立,s1 仍指向原数据
s1.print(); // String: Hello (Refs: 1)
s2.print(); // String: Jello (Refs: 1)
return 0;
}输出:
cpp
String: Hello (Refs: 2)
String: Hello (Refs: 2)
String: Hello (Refs: 1)
String: Jello (Refs: 1)(2) 智能指针 + COW
std::shared_ptr 本身已经实现了引用计数,可以结合 COW 优化:
cpp
#include <memory>
#include <iostream>
class BigObject {
public:
BigObject() { std::cout << "BigObject created\n"; }
~BigObject() { std::cout << "BigObject destroyed\n"; }
void modify() { std::cout << "BigObject modified\n"; }
};
int main() {
std::shared_ptr<BigObject> ptr1 = std::make_shared<BigObject>();
std::shared_ptr<BigObject> ptr2 = ptr1; // 共享,引用计数=2
if (!ptr1.unique()) { // 检查是否唯一引用
ptr1 = std::make_shared<BigObject>(*ptr1); // 写时拷贝
}
ptr1->modify(); // 现在 ptr1 是独立的
return 0;
}


也可以进入以下链接去看内容:
https://coolshell.cn/articles/12199.html
8.总结
该讲主要是把一些补充的知识添加了一下,真正讲解的不是很多,到此,所有关于string类的内容已经讲解完全了,下一讲内容是vector,需要到下一周去了,之后可能会把一些string类的练习题的博客发出来,这个是不确定时间的!
喜欢的可以一键三连哦!下讲再见!

