我们读取解析Excel入库经常会遇到这种场景,那就是行的拆分,如图:
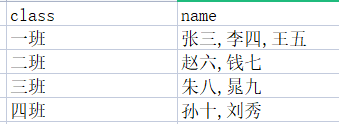
比如我们入库,要以name为主键,可是表格name的值全是以逗号分割的多个,这怎么办呢?这就必须拆成多行了啊。
代码如下:
python
from sqlalchemy import create_engine
import numpy as np
import pandas as pd
conn = create_engine("mysql+pymysql://user:pass@host:3306/db")
df = pd.read_excel("test.xlsx")
df.dropna(subset=["name"]) #删除空行
droplist=[] #记录带逗号的行号
for i in df.index: #遍历每一行
df_line = df.loc[[i]] #本行
names = df.loc[i,'name']
name_list = names.split(',')
#逗号分割超过一条,拆成多行
if(len(name_list)>1):
droplist.append(i) #删除原来的行
for name in name_list:
name = name.strip()
df_line.loc[i,'name'] = name #修改本行的字段值 也就形成了新行
df = pd.concat([df,line],ignore_index=True) #拆分的新行附加到最后面
df.drop(droplist,axis=0,inplace=True) #删除原来有逗号的行这样我们就得到了新的df,已经完成了重组,如图
