一、
使用鸢尾花数据训练多项式朴素贝叶斯模型,并评估模型
代码展示:
python
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
iris = load_iris()
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.3,random_state=42)
model = MultinomialNB()
model.fit(x_train,y_train)
y_pred = model.predict(x_test)
print("预测率:",accuracy_score(y_test,y_pred))结果展示:
python
预测率: 0.9555555555555556二、
电影评论情感分析
项目背景:
你在一家电影评论网站工作,需要开发一个情感分析系统来自动分类用户评论是正面还是负面。使用Kaggle上的"IMDB Dataset of 50K Movie Reviews"数据集。
数据集链接:
IMDB Dataset of 50K Movie Reviews | Kaggle
练习题要求:
- 使用Pandas加载并预处理数据
- 使用Numpy进行特征工程
- 比较不同朴素贝叶斯变体(高斯、多项式、伯努利)的性能
- 使用matplotlib绘制性能比较图表
代码展示:
python
import re
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
import matplotlib.pyplot as plt
df = pd.read_csv("./data/IMDB Dataset.csv",encoding="utf-8")
print(df.head())
print(df.shape)
df["sentiment"] = df["sentiment"].map({"positive":1,"negative":0})
# print(df.head())
comment = df["review"]
# print(comment.head())
comment_lists = []
for i in comment:
# print(i)
i = i.lower()
i = re.sub(r'<.*?>', '', i)
i = re.sub(r'[^a-zA-Z]', ' ', i)
words = i.split()
words = [word for word in words if len(word) > 2]
comment_list = " ".join(words)
comment_lists.append(comment_list)
# print(comment_list)
df["clean_review"] = comment_lists
transfer = TfidfVectorizer(max_features=5000,ngram_range=(1,2))
x = transfer.fit_transform(df["clean_review"])
y = df["sentiment"]
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=42)
mu_model = MultinomialNB()
mu_model.fit(x_train,y_train)
mu_y_pred = mu_model.predict(x_test)
mu_accuracy = accuracy_score(y_test,mu_y_pred)
print("多项式朴素贝叶斯:",mu_accuracy)
be_model = BernoulliNB()
be_model.fit(x_train,y_train)
be_y_pred = be_model.predict(x_test)
be_accuracy = accuracy_score(y_test,be_y_pred)
print("伯努利朴素贝叶斯:",be_accuracy)
transfer = CountVectorizer(max_features=5000)
x = transfer.fit_transform(comment_lists)
x_dense = x.toarray()
x_train = x_dense[:4000, :]
good_or_bad = df["sentiment"].values
y_train = good_or_bad[:4000]
x_test = x_dense[4000:, :]
y_test = good_or_bad[4000:]
ga_model = GaussianNB()
ga_model.fit(x_train,y_train)
ga_y_pred = ga_model.predict(x_test)
ga_accuracy = accuracy_score(y_test,ga_y_pred)
print("高斯朴素贝叶斯:",ga_accuracy)
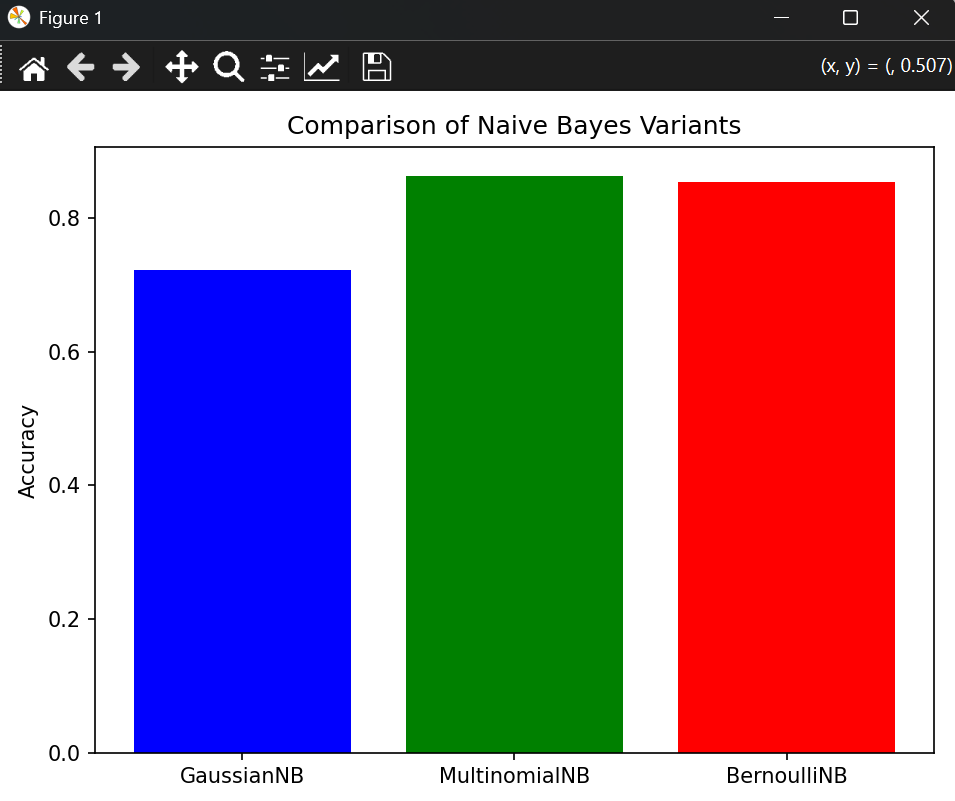
models = ['GaussianNB','MultinomialNB','BernoulliNB']
values = [ga_accuracy,mu_accuracy,be_accuracy]
plt.bar(
models,
values,
color=['blue','green','red']
)
plt.title("Comparison of Naive Bayes Variants")
plt.ylabel("Accuracy")
plt.tight_layout()
plt.show()结果展示:
python
多项式朴素贝叶斯: 0.8628666666666667
伯努利朴素贝叶斯: 0.8533333333333334
高斯朴素贝叶斯: 0.7214347826086956