背景
项目中需要实现一个语音唤起的功能,选择sherpa-onnx进行调研,要求各端都要验证没有问题。个人负责ios这部分的调研。查询官方发现没有直接针对ios语音唤起的稳定,主要技术平台也没有相关的可以借鉴。经过调研之后补充了一个。
一、下载 sherpa-onnx
https://github.com/k2-fsa/sherpa-onnx
二、构建 iOS 版 Sherpa-onnx
根据官方说明文档,先把项目构建编译起来。地址:Build sherpa-onnx for iOS 。根据文档要求安装环境,要两个小时左右。最终的效果的代码可以编译起来并且可以正常使用demo。
demo构建起来只是实现了语音转文字功能,还没有语音唤起能力。
三、补充语音唤起能力
目前官方文档只有安卓语音唤起的说明文档,但是总文档中说支持ios系统。那么原理应该是想通的,在ios的demo中搜索关键词 Keyword 发现,已经实现相关api。那么只要找到语音唤起模型并实现调用。
以下是构建成功之后的demo源码地址:
1、sherpa-onnx-ios-demo 。构建后的 ios-swift demo。构建后的全部内容有好几个G,因此支持提交部分,该demo需要在第二步运行成功之后,把该demo与源目录替换即可编译运行。
四、demo介绍
1、目录结构
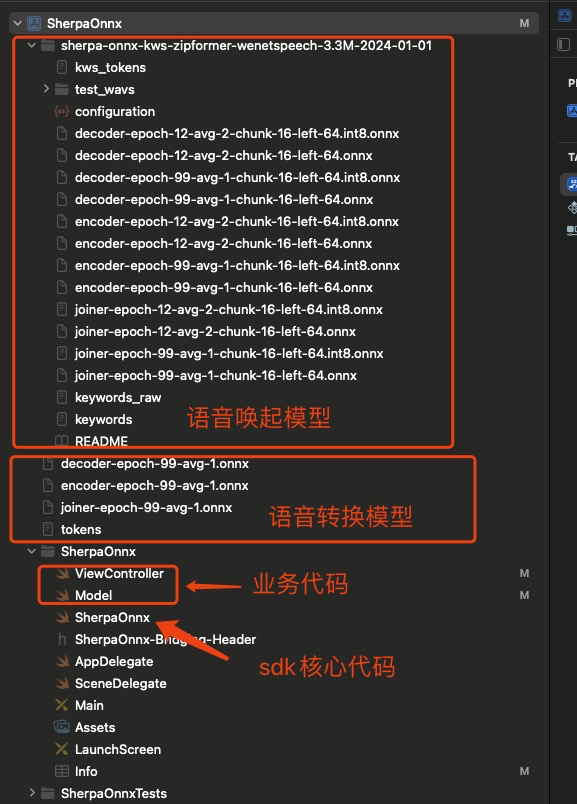
2、sdk调用
Model.swift
swift
// 在Model.swift中添加
func getKwsConfig() -> SherpaOnnxOnlineModelConfig {
// let encoder = getResource("encoder-epoch-99-avg-1", "onnx")
// let decoder = getResource("decoder-epoch-99-avg-1", "onnx")
// let joiner = getResource("joiner-epoch-99-avg-1", "onnx")
// let tokens = getResource("kws_tokens", "txt")
let encoder = getResource("encoder-epoch-12-avg-2-chunk-16-left-64", "onnx")
let decoder = getResource("decoder-epoch-12-avg-2-chunk-16-left-64", "onnx")
let joiner = getResource("joiner-epoch-12-avg-2-chunk-16-left-64", "onnx")
let tokens = getResource("kws_tokens", "txt")
return sherpaOnnxOnlineModelConfig(
tokens: tokens,
transducer: sherpaOnnxOnlineTransducerModelConfig(
encoder: encoder,
decoder: decoder,
joiner: joiner
),
numThreads: 2,
modelType: "zipformer2"
)
}
func getKeywordsFilePath() -> String {
return getResource("keywords", "txt") // 文件内容:小苗小苗
}
/// Please refer to
/// https://k2-fsa.github.io/sherpa/onnx/pretrained_models/index.html
/// to download pre-trained models
/// sherpa-onnx-streaming-zipformer-bilingual-zh-en-2023-02-20 (Bilingual, Chinese + English)
/// https://k2-fsa.github.io/sherpa/onnx/pretrained_models/zipformer-transducer-models.html
func getBilingualStreamZhEnZipformer20230220() -> SherpaOnnxOnlineModelConfig {
let encoder = getResource("encoder-epoch-99-avg-1", "onnx")
let decoder = getResource("decoder-epoch-99-avg-1", "onnx")
let joiner = getResource("joiner-epoch-99-avg-1", "onnx")
let tokens = getResource("tokens", "txt")
return sherpaOnnxOnlineModelConfig(
tokens: tokens,
transducer: sherpaOnnxOnlineTransducerModelConfig(
encoder: encoder,
decoder: decoder,
joiner: joiner
),
numThreads: 1,
modelType: "zipformer"
)
}ViewController.swift
swift
//
// ViewController.swift
// SherpaOnnx
//
// Created by fangjun on 2023/1/28.
//
import AVFoundation
import UIKit
extension AudioBuffer {
func array() -> [Float] {
return Array(UnsafeBufferPointer(self))
}
}
extension AVAudioPCMBuffer {
func array() -> [Float] {
return self.audioBufferList.pointee.mBuffers.array()
}
}
class ViewController: UIViewController {
@IBOutlet weak var resultLabel: UILabel!
@IBOutlet weak var recordBtn: UIButton!
var audioEngine: AVAudioEngine? = nil
var recognizer: SherpaOnnxRecognizer! = nil
// 新增关键词唤醒相关属性
var kwsSpotter: SherpaOnnxKeywordSpotterWrapper!
var isAwakened = false
/// It saves the decoded results so far
var sentences: [String] = [] {
didSet {
updateLabel()
}
}
var lastSentence: String = ""
let maxSentence: Int = 20
var results: String {
if sentences.isEmpty && lastSentence.isEmpty {
return ""
}
if sentences.isEmpty {
return "0: \(lastSentence.lowercased())"
}
let start = max(sentences.count - maxSentence, 0)
if lastSentence.isEmpty {
return sentences.enumerated().map { (index, s) in "\(index): \(s.lowercased())" }[start...]
.joined(separator: "\n")
} else {
return sentences.enumerated().map { (index, s) in "\(index): \(s.lowercased())" }[start...]
.joined(separator: "\n") + "\n\(sentences.count): \(lastSentence.lowercased())"
}
}
func updateLabel() {
DispatchQueue.main.async {
self.resultLabel.text = self.results
}
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
resultLabel.text = "ASR with Next-gen Kaldi\n\nSee https://github.com/k2-fsa/sherpa-onnx\n\nPress the Start button to run!"
recordBtn.setTitle("Start", for: .normal)
initRecognizer()
initKeywordSpotter()
initRecorder()
startRecorder()
}
// 关键词检测初始化
func initKeywordSpotter() {
let modelConfig = getKwsConfig()
let featConfig = sherpaOnnxFeatureConfig()
var config = sherpaOnnxKeywordSpotterConfig(
featConfig: featConfig,
modelConfig: modelConfig,
keywordsFile: getKeywordsFilePath(),
maxActivePaths: 4,
numTrailingBlanks: 2,
keywordsScore: 1.5,
keywordsThreshold: 0.25
)
kwsSpotter = SherpaOnnxKeywordSpotterWrapper(config: &config)
}
// 新增状态变量
private var isRecording = false
@IBAction func onRecordBtnClick(_ sender: UIButton) {
if recordBtn.currentTitle == "Start" {
isAwakened = true // 强制唤醒状态
startRecorder()
recordBtn.setTitle("Stop", for: .normal)
} else {
isAwakened = false
stopRecorder()
recordBtn.setTitle("Start", for: .normal)
}
}
// 初始化语音转文字模型
func initRecognizer() {
// Please select one model that is best suitable for you.
//
// You can also modify Model.swift to add new pre-trained models from
// https://k2-fsa.github.io/sherpa/onnx/pretrained_models/index.html
let modelConfig = getBilingualStreamZhEnZipformer20230220()
// let modelConfig = getZhZipformer20230615()
// let modelConfig = getEnZipformer20230626()
// let modelConfig = getBilingualStreamingZhEnParaformer()
let featConfig = sherpaOnnxFeatureConfig(
sampleRate: 16000,
featureDim: 80)
var config = sherpaOnnxOnlineRecognizerConfig(
featConfig: featConfig,
modelConfig: modelConfig,
enableEndpoint: true,
rule1MinTrailingSilence: 2.4,
rule2MinTrailingSilence: 0.8,
rule3MinUtteranceLength: 30,
decodingMethod: "greedy_search",
maxActivePaths: 4
)
recognizer = SherpaOnnxRecognizer(config: &config)
}
func initRecorder() {
print("init recorder")
audioEngine = AVAudioEngine()
let inputNode = self.audioEngine?.inputNode
let bus = 0
let inputFormat = inputNode?.outputFormat(forBus: bus)
let outputFormat = AVAudioFormat(
commonFormat: .pcmFormatFloat32,
sampleRate: 16000, channels: 1,
interleaved: false)!
let converter = AVAudioConverter(from: inputFormat!, to: outputFormat)!
inputNode!.installTap(
onBus: bus,
bufferSize: 1024,
format: inputFormat
) {
(buffer: AVAudioPCMBuffer, when: AVAudioTime) in
var newBufferAvailable = true
let inputCallback: AVAudioConverterInputBlock = {
inNumPackets, outStatus in
if newBufferAvailable {
outStatus.pointee = .haveData
newBufferAvailable = false
return buffer
} else {
outStatus.pointee = .noDataNow
return nil
}
}
let convertedBuffer = AVAudioPCMBuffer(
pcmFormat: outputFormat,
frameCapacity:
AVAudioFrameCount(outputFormat.sampleRate)
* buffer.frameLength
/ AVAudioFrameCount(buffer.format.sampleRate))!
var error: NSError?
let _ = converter.convert(
to: convertedBuffer,
error: &error, withInputFrom: inputCallback)
// TODO(fangjun): Handle status != haveData
let array = convertedBuffer.array()
// 并行处理关键词检测和ASR
self.processKeywordDetection(array)
if self.isAwakened || self.isRecording {
self.processASR(array)
}
}
}
var wakeupConfidence = 0
let requiredConfidence = 2
private func processKeywordDetection(_ samples: [Float]) {
kwsSpotter.acceptWaveform(samples: samples)
while kwsSpotter.isReady() {
kwsSpotter.decode()
let result = kwsSpotter.getResult()
let detected = result.keyword.lowercased().contains("小苗小苗")
print("demo----> result.keyword:\(result.keyword) detected:\(detected)")
wakeupConfidence = detected ?
min(wakeupConfidence + 1, requiredConfidence) :
max(wakeupConfidence - 1, 0)
if wakeupConfidence >= requiredConfidence && !isAwakened {
handleWakeupEvent()
wakeupConfidence = 0
}
}
}
private func processASR(_ samples: [Float]) {
if !samples.isEmpty {
recognizer.acceptWaveform(samples: samples)
while (recognizer.isReady()){
recognizer.decode()
}
let isEndpoint = recognizer.isEndpoint()
let text = recognizer.getResult().text
if !text.isEmpty && lastSentence != text {
lastSentence = text
updateLabel()
print(text)
}
if isEndpoint {
if !text.isEmpty {
let tmp = self.lastSentence
lastSentence = ""
sentences.append(tmp)
}
recognizer.reset()
}
}
}
private func handleWakeupEvent() {
isAwakened = true
DispatchQueue.main.async {
// self.resultLabel.text = "已唤醒,请开始说话..."
// 自动启动录音逻辑(可选)
if self.recordBtn.currentTitle == "Start" {
self.startRecorder()
self.recordBtn.setTitle("Stop", for: .normal)
}
}
// 重置ASR状态
recognizer.reset()
}
func startRecorder() {
lastSentence = ""
sentences = []
do {
try self.audioEngine?.start()
isRecording = true
} catch let error as NSError {
print("Got an error starting audioEngine: \(error.domain), \(error)")
}
print("started")
}
func stopRecorder() {
audioEngine?.stop()
kwsSpotter.reset()
recognizer.reset()
isRecording = false
print("stopped")
}
}