前言
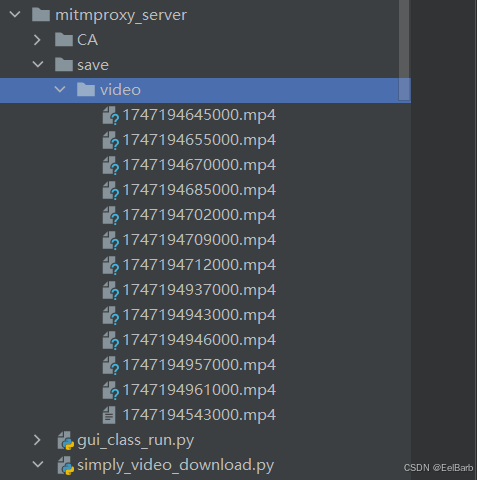
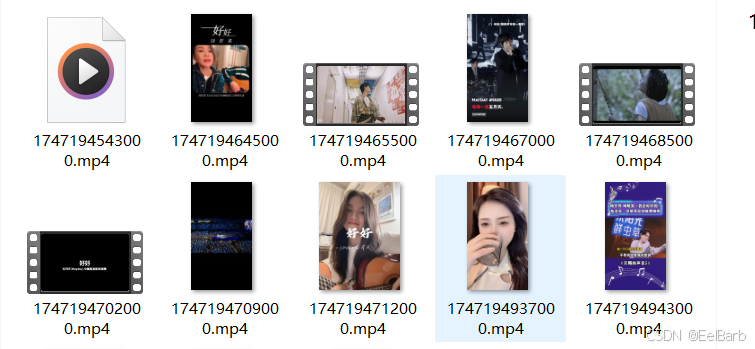
一个mitmproxy代理服务应用,作用是监听系统流量,并自动下载可能的video媒体文件到本地。
如果你没有安装mitmproxy或没有做完准备工作,请参考我的这篇文章:
文件架构目录
源码
python
import os
import time
import threading
import requests
from mitmproxy import http
SAME_DOWNLOADS = []
# 设置代理
proxies = {
'http': 'http://127.0.0.1:9099',
'https': 'http://127.0.0.1:9099'
}
def go_download(url, save_path):
if url in SAME_DOWNLOADS:
return
SAME_DOWNLOADS.append(url)
r = requests.get(url, proxies=proxies, verify=False)
with open(save_path, 'wb') as f:
f.write(r.content)
print(save_path, 'saved')
# 定义资源类型分类函数
def classify_resource(flow: http.HTTPFlow):
url = flow.request.url
content_type = flow.response.headers.get('Content-Type', '')
# 媒体资源
if any(ext in url for ext in ['.mp4', '.avi', '.mov', '.mkv', '.mp3', '.wav']):
extensions = ['.mp4', '.avi', '.mov', '.mkv', '.mp3', '.wav']
for ext in extensions:
if ext in url:
filename = str(int(time.time()) * 1000) + ext
print(filename, 'downloading')
a = threading.Thread(target=go_download, args=(url, os.path.join('save/video', filename)))
a.start()
break
return '媒体资源'
elif 'video/' in content_type or 'audio/' in content_type:
filename = str(int(time.time()) * 1000) + '.' + content_type.split('/')[-1]
print(filename, 'downloading')
a = threading.Thread(target=go_download, args=(url, os.path.join('save/video', filename)))
a.start()
return '媒体资源'
# 图片资源
if any(ext in url for ext in ['.jpg', '.jpeg', '.png', '.gif', '.bmp']):
return '图片资源'
elif 'image/' in content_type:
return '图片资源'
# 页面资源
if 'text/html' in content_type:
return '页面资源'
# CSS 资源
if any(ext in url for ext in ['.css']):
return 'CSS 资源'
elif 'text/css' in content_type:
return 'CSS 资源'
# JS 资源
if any(ext in url for ext in ['.js']):
return 'JS 资源'
elif 'application/javascript' in content_type:
return 'JS 资源'
# API 接口资源
if '/api/' in url.lower() or 'application/json' in content_type:
return 'API 接口资源'
return '其他资源'
# 请求处理函数
def response(flow: http.HTTPFlow) -> None:
if flow.response:
resource_type = classify_resource(flow)
print(f"URL: {flow.request.url}")
print(f"Resource Type: {resource_type}")
print("-" * 50)
# 将资源类型添加到请求的注释中
flow.request.comment = resource_type运行指令:
python
mitmdump -s simply_run.py -p 9099结果展示: