- 创建新的maven项目。
- 创建input文件夹,在input下新建记事本文件,其中内容就是前面的实例数据。
- 在src下创建新的scala文件,开始写功能代码。
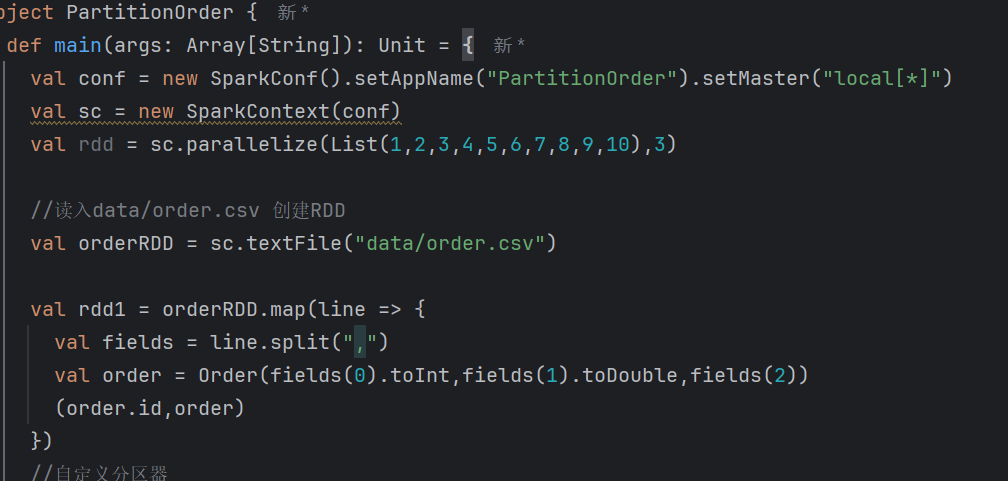
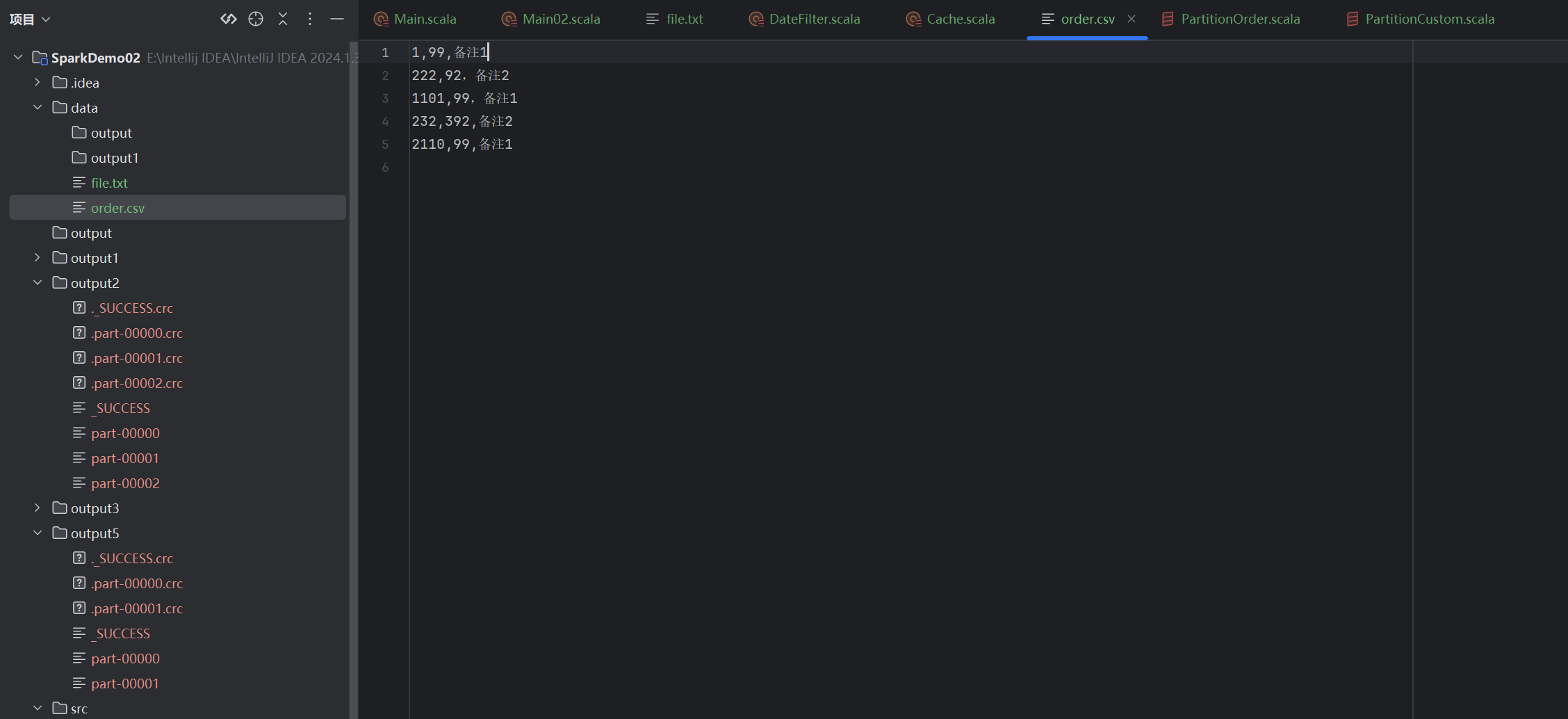
我们在编写代码时有以下几个过程
// 1. 实现自定义分区器
// 2. 读文件,生成RDD
// 3. RDD使用自定义分区器分区
// 4. 对分区的数据进行汇总计算
// 5. 保存计算之后的结果
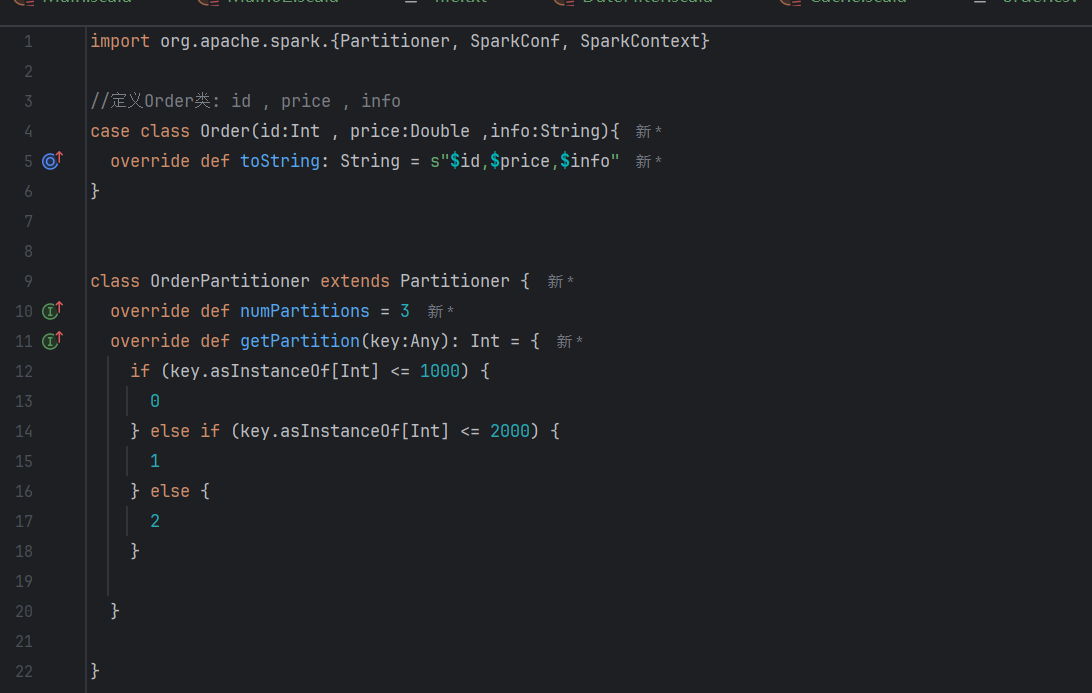
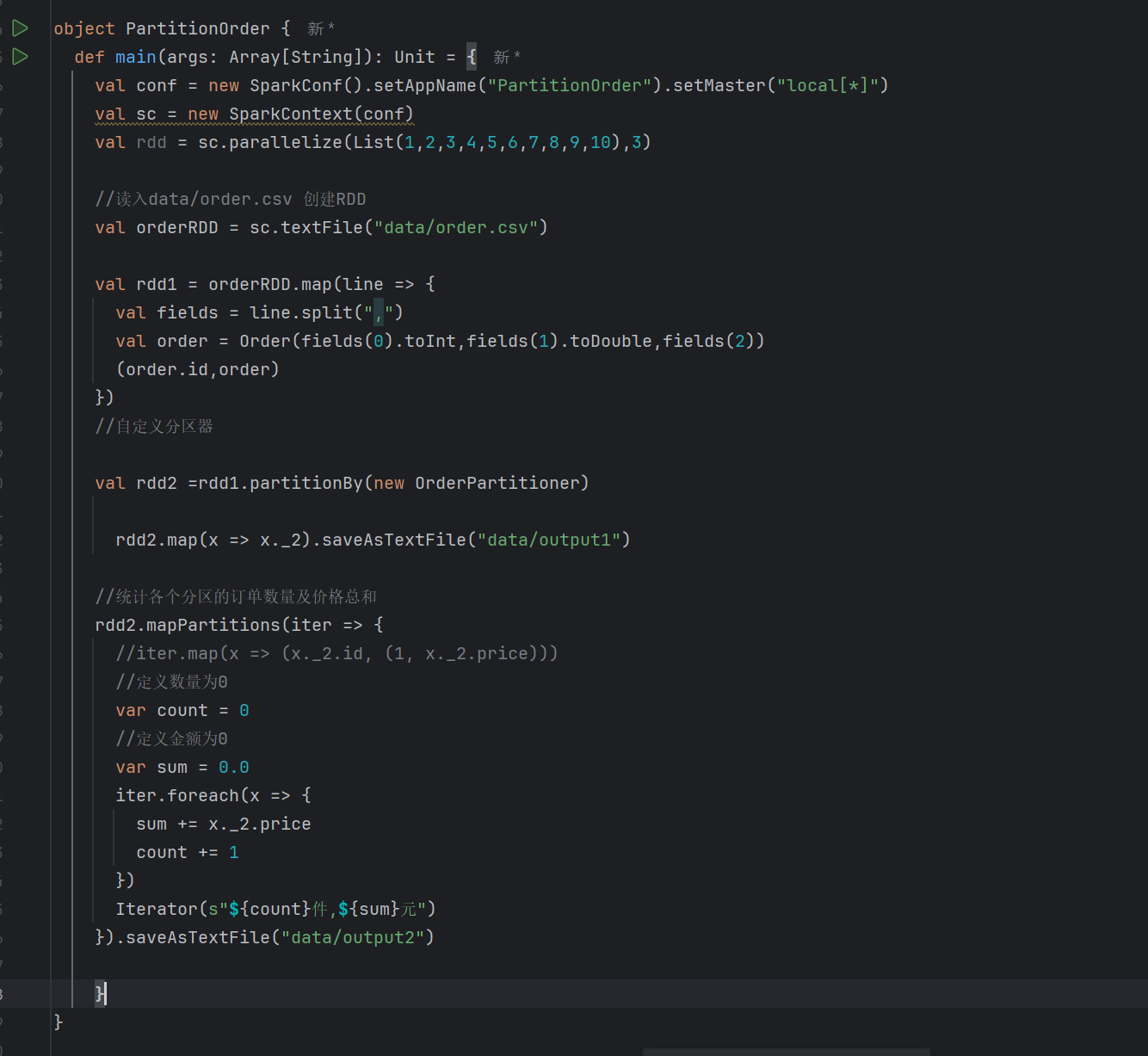
我们在编写代码时有以下几个过程
// 1. 实现自定义分区器
// 2. 读文件,生成RDD
// 3. RDD使用自定义分区器分区
// 4. 对分区的数据进行汇总计算
// 5. 保存计算之后的结果