1 全文搜索
全文搜索是一种在文本数据集中检索包含特定术语或短语的文档,然后根据相关性对结果进行排序的功能。该功能克服了语义搜索的局限性(语义搜索可能会忽略精确的术语),确保您获得最准确且与上下文最相关的结果。此外,它还通过接受原始文本输入来简化向量搜索,自动将您的文本数据转换为稀疏嵌入,而无需手动生成向量嵌入。
该功能使用 BM25 算法进行相关性评分,在检索增强生成 (RAG) 场景中尤为重要,它能优先处理与特定搜索词密切匹配的文档。
1.1 概述
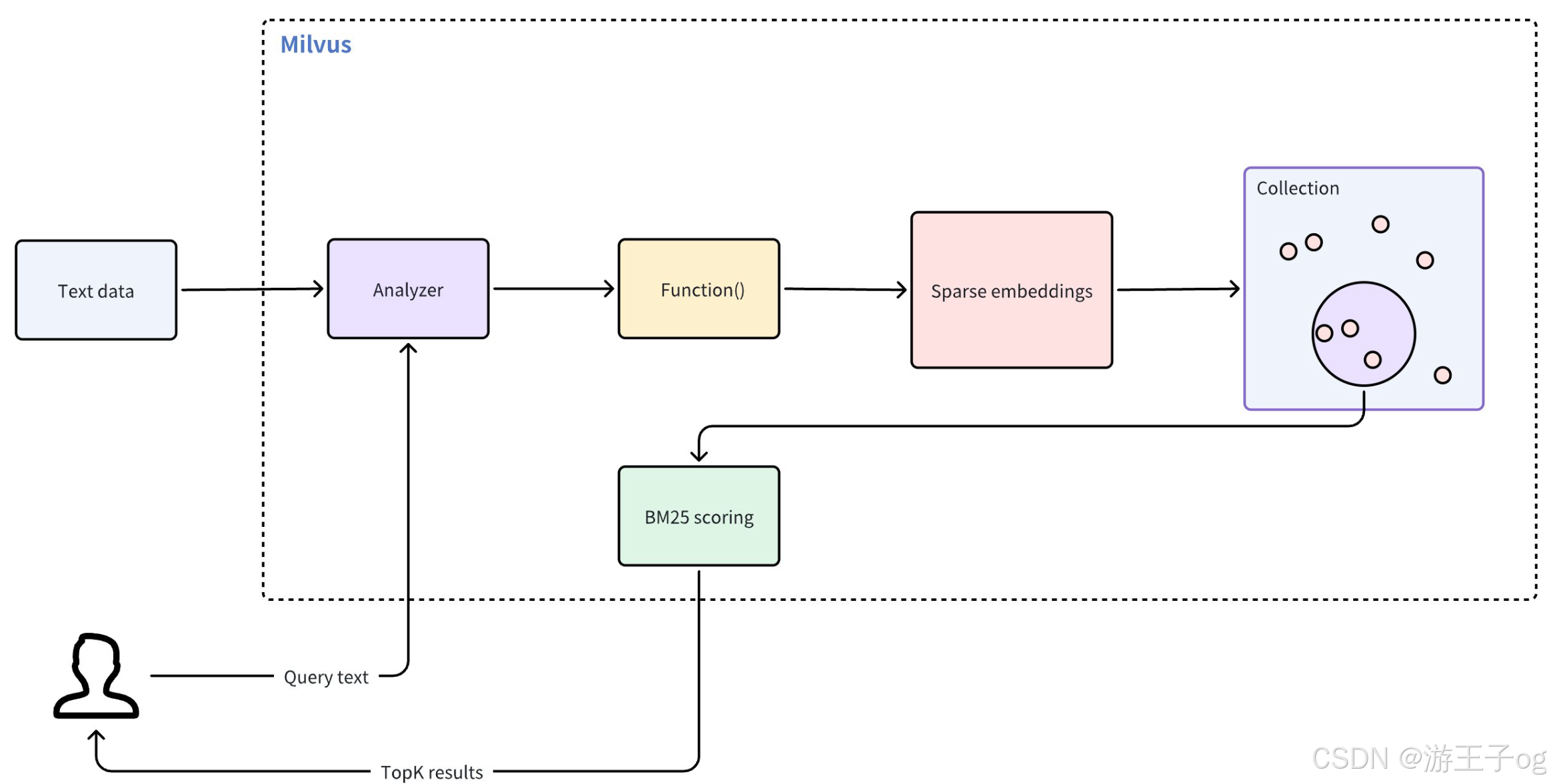
全文搜索无需手动嵌入,从而简化了基于文本的搜索过程。该功能通过以下工作流程进行操作符:
- 文本输入:插入原始文本文档或提供查询文本,无需手动嵌入。
- 文本分析:Milvus 使用分析器将输入文本标记为可搜索的单个术语。
- 函数处理:内置函数接收标记化术语,并将其转换为稀疏向量表示。
- Collections 存储:Milvus 将这些稀疏嵌入存储在 Collections 中,以便高效检索。
- BM25 评分:在搜索过程中,Milvus 应用 BM25 算法为存储的文档计算分数,并根据与查询文本的相关性对匹配结果进行排序。
1.2 创建用于全文搜索的 Collections
要启用全文搜索,请创建一个具有特定 Schema 的 Collections。此 Schema 必须包括三个必要字段:
- 唯一标识 Collections 中每个实体的主字段。
- 一个
VARCHAR字段,用于存储原始文本文档,其enable_analyzer属性设置为True。这允许 Milvus 将文本标记为特定术语,以便进行函数处理。 - 一个
SPARSE_FLOAT_VECTOR字段,预留用于存储稀疏嵌入,Milvus 将为VARCHAR字段自动生成稀疏嵌入。
1.2.1 定义 Collections 模式
首先,创建 Schema 并添加必要的字段:
python
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
schema = MilvusClient.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True)
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR)在此配置中
id: 作为主键,并通过auto_id=True自动生成。text:存储原始文本数据,用于全文搜索操作。数据类型必须是VARCHAR,因为VARCHAR是 Milvus 用于文本存储的字符串数据类型。设置enable_analyzer=True以允许 Milvus 对文本进行标记化。默认情况下,Milvus 使用standard分析器进行文本分析。sparse矢量字段:用于存储内部生成的稀疏嵌入的矢量字段,以进行全文搜索操作。数据类型必须是SPARSE_FLOAT_VECTOR。
现在,定义一个将文本转换为稀疏向量表示的函数,然后将其添加到 Schema 中:
python
bm25_function = Function(
name="text_bm25_emb", # 函数名
input_field_names=["text"], # 包含原始文本数据的VARCHAR字段的名称
output_field_names=["sparse"], # SPARSE_FLOAT_VECTOR字段的名称,用于存储生成的嵌入
function_type=FunctionType.BM25, # 设置为"BM25"
)
schema.add_function(bm25_function)| 参数 | 说明 |
|---|---|
name |
函数名称。该函数将text 字段中的原始文本转换为可搜索向量,这些向量将存储在sparse 字段中。 |
input_field_names |
需要将文本转换为稀疏向量的VARCHAR 字段的名称。对于FunctionType.BM25 ,该参数只接受一个字段名称。 |
output_field_names |
存储内部生成的稀疏向量的字段名称。对于FunctionType.BM25 ,该参数只接受一个字段名称。 |
function_type |
要使用的函数类型。将值设为FunctionType.BM25 。 |
对于有多个VARCHAR 字段需要进行文本到稀疏向量转换的 Collections,请在 Collections Schema 中添加单独的函数,确保每个函数都有唯一的名称和output_field_names 值。
1.2.2 配置索引
在定义了包含必要字段和内置函数的 Schema 后,请为 Collections 设置索引。为简化这一过程,请使用AUTOINDEX 作为index_type ,该选项允许 Milvus 根据数据结构选择和配置最合适的索引类型。
python
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
)| 参数 | 参数 |
|---|---|
field_name |
要索引的向量字段的名称。对于全文搜索,这应该是存储生成的稀疏向量的字段。在本示例中,将值设为sparse 。 |
index_type |
要创建的索引类型。AUTOINDEX 允许 Milvus 自动优化索引设置。如果需要对索引设置进行更多控制,可以从 Milvus 中稀疏向量可用的各种索引类型中进行选择。 |
metric_type |
该参数的值必须设置为BM25 ,专门用于全文搜索功能。 |
params |
特定于索引的附加参数字典。 |
params.inverted_index_algo |
用于构建和查询索引的算法。有效值: * "DAAT_MAXSCORE" (默认):使用 MaxScore 算法优化的一次文档 (DAAT) 查询处理。MaxScore 通过跳过可能影响最小的术语和文档,为高k值或包含大量术语的查询提供更好的性能。为此,它根据最大影响分值将术语划分为基本组和非基本组,并将重点放在对前 k 结果有贡献的术语上。 * "DAAT_WAND":使用 WAND 算法优化 DAAT 查询处理。WAND 算法利用最大影响分数跳过非竞争性文档,从而评估较少的命中文档,但每次命中的开销较高。这使得 WAND 对于k值较小的查询或较短的查询更有效,因为在这些情况下跳过更可行。 * "TAAT_NAIVE":基本术语一次查询处理(TAAT)。虽然与DAAT_MAXSCORE 和DAAT_WAND 相比速度较慢,但TAAT_NAIVE 具有独特的优势。DAAT 算法使用的是缓存的最大影响分数,无论全局 Collections 参数(avgdl)如何变化,这些分数都是静态的,而TAAT_NAIVE 不同,它能动态地适应这种变化。 |
params.bm25_k1 |
控制词频饱和度。数值越高,术语频率在文档排名中的重要性就越大。取值范围1.2, 2.0. |
params.bm25_b |
控制文档长度的标准化程度。通常使用 0 到 1 之间的值,默认值为 0.75 左右。值为 1 表示不进行长度归一化,值为 0 表示完全归一化。 |
1.2.3 创建 Collections
现在使用定义的 Schema 和索引参数创建 Collections。
python
client.create_collection(
collection_name='my_collection',
schema=schema,
index_params=index_params
)1.3 插入文本数据
设置好集合和索引后,就可以插入文本数据了。在此过程中,您只需提供原始文本。我们之前定义的内置函数会为每个文本条目自动生成相应的稀疏向量。
python
client.insert('my_collection', [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
])1.4 执行全文搜索
将数据插入 Collections 后,就可以使用原始文本查询执行全文检索了。Milvus 会自动将您的查询转换成稀疏向量,并使用 BM25 算法对匹配的搜索结果进行排序,然后返回 topK (limit) 结果。
python
search_params = {
'params': {'drop_ratio_search': 0.2},
}
client.search(
collection_name='my_collection',
data=['whats the focus of information retrieval?'],
anns_field='sparse',
limit=3,
search_params=search_params
)| 参数 | 说明 |
|---|---|
search_params |
包含搜索参数的字典。 |
params.drop_ratio_search |
搜索过程中要忽略的低重要性词的比例。 |
data |
原始查询文本。 |
anns_field |
包含内部生成的稀疏向量的字段名称。 |
limit |
要返回的最大匹配次数。 |
2 文本匹配
Milvus 的文本匹配功能可根据特定术语精确检索文档。该功能主要用于满足特定条件的过滤搜索,并可结合标量过滤功能来细化查询结果,允许在符合标量标准的向量内进行相似性搜索。
2.1 概述
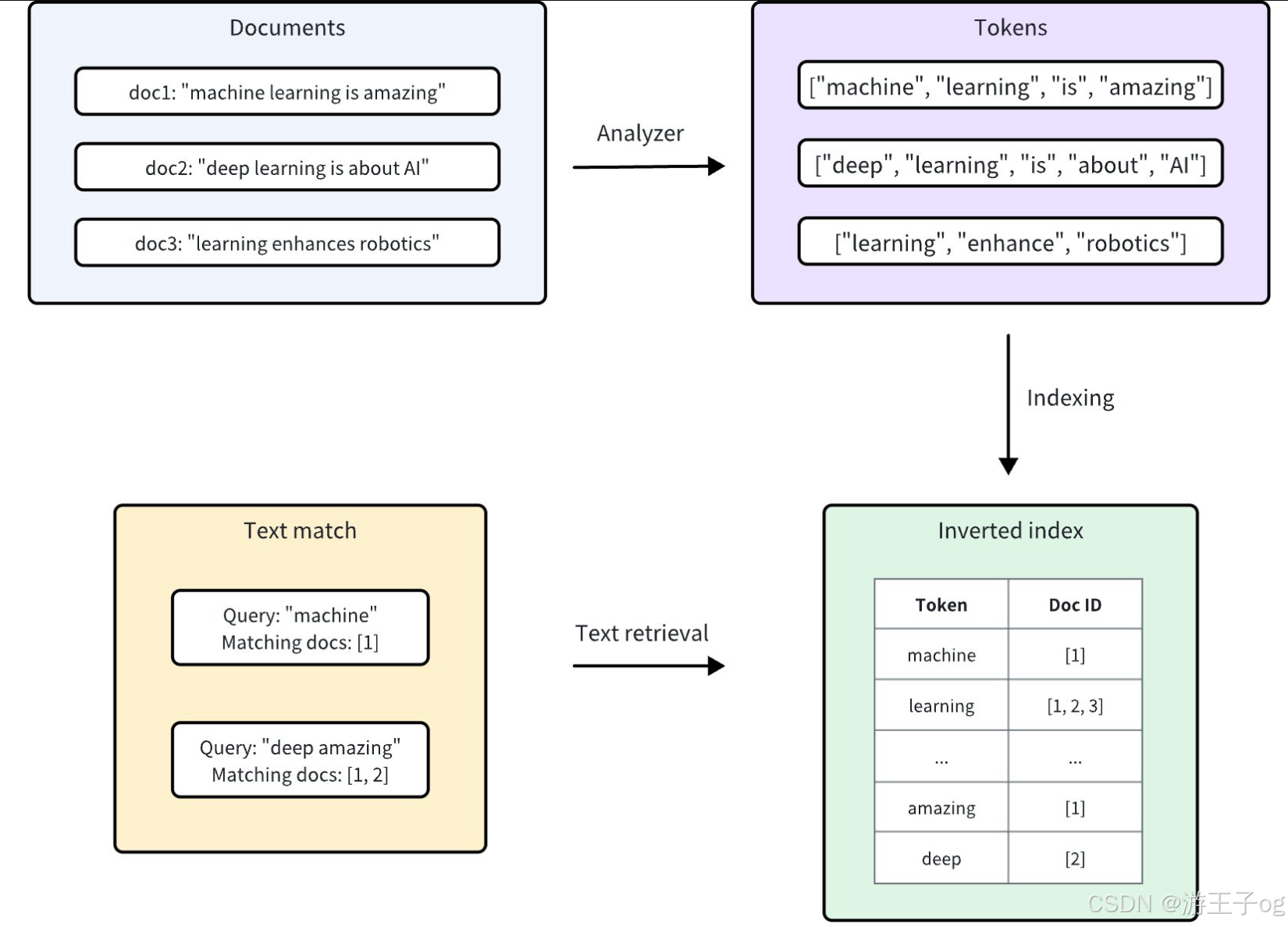
Milvus 整合了Tantivy来支持其底层的倒排索引和基于术语的文本搜索。对于每个文本条目,Milvus 都会按照以下程序建立索引:
- 分析器:分析器将输入文本标记化为单个词或标记,然后根据需要应用过滤器。这样,Milvus 就能根据这些标记建立索引。
- 编制索引:文本分析完成后,Milvus 会创建一个倒排索引,将每个独特的标记映射到包含该标记的文档。
当用户进行文本匹配时,倒排索引可用于快速检索包含该术语的所有文档。这比逐个扫描每个文档要快得多。
2.2 启用文本匹配
文本匹配适用于VARCHAR 字段类型,它本质上是 Milvus 中的字符串数据类型。要启用文本匹配,请将enable_analyzer 和enable_match 都设置为True ,然后在定义 Collections Schema 时选择性地配置分析器进行文本分析。
2.2.1 将enable_analyzer 和enable_match
要启用特定VARCHAR 字段的文本匹配,请在定义字段 Schema 时将enable_analyzer 和enable_match 参数设置为True 。这将指示 Milvus 对文本进行标记化处理,并为指定字段创建反向索引,从而实现快速高效的文本匹配。
python
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema(enable_dynamic_field=False)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True, # 是否为此字段启用文本分析
enable_match=True # 是否启用文本匹配
)
schema.add_field(
field_name="embeddings",
datatype=DataType.FLOAT_VECTOR,
dim=5
)2.2.2 可选:配置分析器
关键词匹配的性能和准确性取决于所选的分析器。不同的分析器适用于不同的语言和文本结构,因此选择正确的分析器会极大地影响特定用例的搜索结果。默认情况下,Milvus 使用standard 分析器,该分析器根据空白和标点符号对文本进行标记,删除长度超过 40 个字符的标记,并将文本转换为小写。应用此默认设置无需额外参数。
如果需要不同的分析器,可以使用analyzer_params 参数进行配置。例如,应用english 分析器处理英文文本:
python
analyzer_params = {
"type": "english"
}
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params = analyzer_params,
enable_match = True,
)2.3 使用文本匹配
为 Collections Schema 中的 VARCHAR 字段启用文本匹配后,就可以使用TEXT_MATCH 表达式执行文本匹配。
2.3.1 文本匹配表达式语法
TEXT_MATCH 表达式用于指定要搜索的字段和术语。其语法如下:
python
TEXT_MATCH(field_name, text)field_name:要搜索的 VARCHAR 字段的名称。text:要搜索的术语。根据语言和配置的分析器,多个术语可以用空格或其他适当的分隔符分隔。
默认情况下,TEXT_MATCH 使用OR 匹配逻辑,即返回包含任何指定术语的文档。例如,要搜索text 字段中包含machine 或deep 的文档,请使用以下表达式:
python
filter = "TEXT_MATCH(text, 'machine deep')"还可以使用逻辑操作符组合多个TEXT_MATCH 表达式来执行AND 匹配。要搜索text 字段中同时包含machine 和deep 的文档,请使用以下表达式:
python
filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"要搜索text 字段中同时包含machine 和learning 但不包含deep 的文档,请使用以下表达式:
python
filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"2.3.2 使用文本匹配搜索
文本匹配可与向量相似性搜索结合使用,以缩小搜索范围并提高搜索性能。通过在向量相似性搜索前使用文本匹配过滤 Collections,可以减少需要搜索的文档数量,从而加快查询速度。
在这个示例中,filter 表达式过滤了搜索结果,使其只包含与指定术语keyword1 或keyword2 匹配的文档。然后在这个过滤后的文档子集中执行向量相似性搜索。
python
# 匹配带有' keyword1 '或' keyword2 '的实体
filter = "TEXT_MATCH(text, 'keyword1 keyword2')"
# 假设'embeddings'是向量字段,'text'是VARCHAR字段
result = client.search(
collection_name="my_collection", # 集合名称
anns_field="embeddings", # 向量字段名
data=[query_vector], # 查询向量
filter=filter,
search_params={"params": {"nprobe": 10}},
limit=10, # Max。要返回的结果数
output_fields=["id", "text"]
)2.3.3 文本匹配查询
文本匹配也可用于查询操作中的标量过滤。通过在query() 方法的expr 参数中指定TEXT_MATCH 表达式,可以检索与给定术语匹配的文档。下面的示例检索了text 字段包含keyword1 和keyword2 这两个术语的文档。
python
# 匹配包含' keyword1 '和' keyword2 '的实体
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
result = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["id", "text"]
)2.4 注意事项
为字段启用术语匹配会触发反向索引的创建,从而消耗存储资源。在决定是否启用此功能时,请考虑对存储的影响,因为它根据文本大小、唯一标记和所使用的分析器而有所不同。
在 Schema 中定义分析器后,其设置将永久适用于该 Collections。如果您认为不同的分析器更适合您的需要,您可以考虑删除现有的 Collections,然后使用所需的分析器配置创建一个新的 Collections。
filter 表达式中的转义规则:
-
表达式中用双引号或单引号括起来的字符被解释为字符串常量。如果字符串常量包含转义字符,则必须使用转义序列来表示转义字符。例如,用
\\表示\,用\\t表示制表符\t,用\\n表示换行符。 -
如果字符串常量由单引号括起来,常量内的单引号应表示为
\\',而双引号可表示为"或\\"。 示例:'It\\'s milvus'。 -
如果字符串常量由双引号括起来,常量中的双引号应表示为
\\",而单引号可表示为'或\\'。 示例:"He said \\"Hi\\""