目录
[2.安装ElasticSearch Head](#2.安装ElasticSearch Head)
前言:本篇主要介绍ElasticSearch、ElasticSearch相关概念、语法、ElasticSearch的使用以及SpringBoot集成ElasticSearch。
今天为什么要写这篇文章呢?主要是项目中使用ElasticSearch时的出现的一个小问题,顺手复习一下。
引入
为什么要使用ElasticSearch?
其实很简单,在以前没有使用ElasticSearch的时候,当我们搜索内容时会出现这样的情况,只能按照我们搜索的关键词去查找,当我们忘了部分内容时,我们想要通过仅剩的记忆找寻内容,怎么找也找不到,就很崩溃。当ElasticSearch出现后,就很好的解决了这一痛点。
概述
ElasticSearch,简称ES,是一款非常强大的开源 的高扩展 的分布式全文检索引擎,可以帮助我们从海量数据中快速找到我们需要的内容。可以近乎实时的存储、检索数据。还可以实现日志统计、分析、系统监控等功能。
举个例子,各大购物电商、新闻资讯等平台的站内搜索。
ES安装搭建
在安装搭建之间我们先来了解几个插件/组件。
1.ElasticSearch Head
一个数据可视化界面,本质上是一个前端项目,只能查看数据,不能修改。
2.Kibana
是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。
使用Kibana,可以通过各种图表进行高级数据分析及展示。
简而言之,Kibana让海量数据变得更加容易理解。
3.ik分词器
在搜索时,需要对用户输入内容进行分词。但默认的粉刺规则对中文处理不太友好;
ik分词器,提供标准分词、最少切分、最细粒度划分
1.安装ES
ES下载官网:https://www.elastic.co/cn/downloads/elasticsearch
1.下载安装
2.打开bin目录
3.点击elasticsearch.bat启动
4.登录http://127.0.0.1:9200进行访问
2.安装ElasticSearch Head
安装数据可视化界面ElasticSearch Head
前提条件:下载安装node js
官网:GitHub - mobz/elasticsearch-head: A web front end for an elastic search cluster
1.下载安装ElasticSearch Head
2.打开文件进入config目录修改elasticsearch.yml配置
# 开启跨域
http.cors.enabled: true
# 所有人访问
http.cors.allow-origin: "*"3.下载项目依赖
首先打开命令行进入文件根目录
bash
#下载项目依赖
npm install4.启动
bash
# 启动ES head
npm run start5.访问测试
登录http://127.0.0.1:9100进行访问
3.安装可视化Kibana组件
1.下载
官网:Download Kibana Free | Get Started Now | Elastic
2.汉化kibana
修改 config 目录下的 kibana.yml 文件
bash
# 中文
i18n.locale: "zh-CN" 3.启动
双击bin目录kibana.bat启动
4.访问测试
4.安装ik分词器插件
1.下载并解压
官网:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.1/elasticsearch- analysis-ik-7.6.1.zip
- 在ElasticSearch的plugins目录下创建ik文件夹
将解压后的文件复制到ik目录
3.自定义ik分词器
在ik目录下的config目录中添加my.dic文件定义词组(要求uft-8编码格式)
在IKAnalyzer.cfg.xml文件添加自定义的分词器文件
XML
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>到此我们的ES环境基本搭建完成,下面我们试试进行操作。
ES相关概念
ElasticSearch是面向文档存储的,可以理解为数据库中的一条记录,文档数据会被序列化为JSON格式后存储在ElasticSearch中。

**索引:**同类型文档的集合
**文档:**一条数据就是一个文档,ES中是JSON格式
**字段:**JSON中的字段
**映射:**索引中文档的约束,比如字段名称、类型
elasticsearch 采用倒排索引:
文档(document):每条数据就是一个文档
词条(term):文档按照语义分成的词语
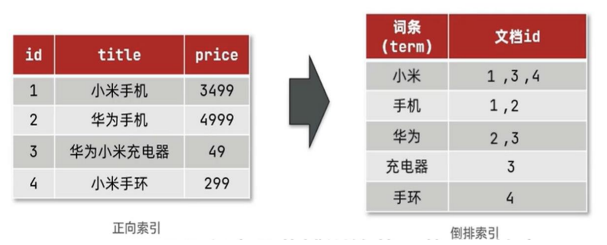
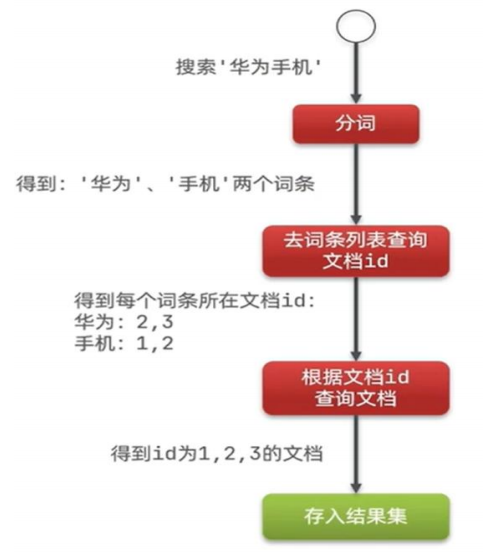
MySql对照ElasticSearch

-
MySQL
-
定位:关系型数据库(RDBMS),支持事务处理(OLTP)。
-
核心场景:结构化数据存储、复杂查询、ACID事务(如订单管理、金融交易)。
-
-
Elasticsearch
-
定位:分布式搜索与分析引擎(NoSQL),近实时(NRT)数据处理。
-
核心场景:全文搜索、日志分析、实时指标聚合(如日志监控、商品检索)。
-
数据模型与存储结构
| 特性 | MySQL | Elasticsearch |
|---|---|---|
| 数据模型 | 表格结构,支持关系型数据(行与列) | 文档型存储(JSON格式),扁平化结构 |
| 索引机制 | B+树索引,适合范围查询 | 倒排索引 + Doc Values,优化全文搜索 |
| Schema约束 | 强Schema(需预定义字段类型) | 动态Mapping(自动推断类型) |
| 事务支持 | 完整ACID(如BEGIN; COMMIT;) |
不支持事务(仅单文档原子性) |
性能与扩展性
| 维度 | MySQL | Elasticsearch |
| 写入吞吐量 | 高(单机万级TPS) | 中(依赖分片和副本配置) |
| 查询性能 | 复杂JOIN较慢,索引优化后高效 | 全文检索/聚合极快(毫秒级响应) |
| 扩展方式 | 垂直扩展(硬件升级)或水平分库分表 | 天生分布式,水平扩展(自动分片) |
| 高可用 | 主从复制(半同步/异步) | 分片副本(自动故障转移) |
|---|
查询能力对比
MySQL
-
支持标准SQL(
JOIN、子查询、窗口函数)。 -
适合精确匹配、范围查询、事务性操作。
Elasticsearch
-
提供DSL查询(全文搜索、模糊匹配、聚合分析)。
-
适合文本检索、模糊查询、多维聚合。
选型建议
-
选择MySQL当:
-
需要严格的事务和复杂SQL。
-
数据结构稳定,关系模型明确。
-
数据量较小(单表千万级以下)。
-
-
选择ES当:
-
需要全文搜索或非结构化数据处理。
-
高写入吞吐量(如日志流)。
-
实时聚合分析(如监控大盘)。
-
-
混合使用:
- 核心业务用MySQL,搜索/分析用ES(互补短板)。
ES语法
索引库操作
对比Mysql而言就是对表的操作
mapping属性
mapping是对索引库文档的约束,包括:
type:字段数据类型
text(可分词文本),keyword(精确值,像,品牌、国家等)
数值型:long、integer、short、byte、double、float
布尔型:boolean
日期型:date
对象型:object
index:是否创建索引参与搜索,默认true
analyzer:指定分词器类型
下面进行举例,新手对照MySQl更好理解
注:以下操作均在Kibana dev tools中操作
创建索引库
PUT /索引库名
{
"mappings":{
"properties":{
"字段1":{
"type":"数据类型",
"index": false
},
"字段2":{
"type": "数据类型",
"analyzer": "分词器类型"
}
}
}
}
PUT /student
{
"mappings":{
"properties":{
"id":{
"type":"integer",
"index": false
},
"name":{
"type": "text",
"analyzer": "standard"
},
"gender":{
"type": "text",
"index": false
},
"address":{
"type": "text",
"analyzer": "ik_max_word"
},
"phone":{
"type": "integer",
"index": false
}
}
}
}这样就创建了一个student索引,对照Mysql就是建立了一张student表,包含id,name,gender,address,phone这几个字段。
查询索引库
# GET /索引库名
GET /student查询结果
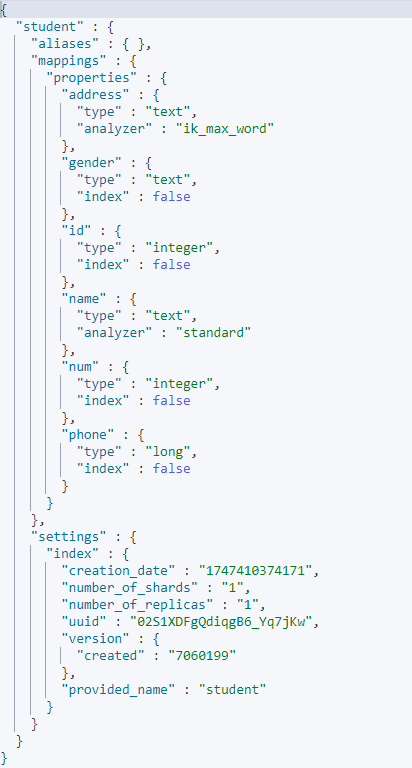
删除索引库
# DELETE /索引库名
DELETE /student修改索引库
索引库一旦创建就无法修改,但是可以添加新的字段
PUT /索引库名/_mapping
{
"properties":{
"新增字段":{
"type":"数据类型",
"index": false
}
}
}
PUT /student/_mapping
{
"properties":{
"num":{
"type":"integer",
"index": false
}
}
}文档操作
文档操作对比Mysql而言就是对数据操作
新增文档
这样就新增了一条文档
POST /索引库名/_doc/文档id
{
"字段1":"值",
"字段2":"值"
}
POST /student/_doc/1
{
"id":1,
"name":"张三",
"gender":"男",
"address":"陕西西安",
"phone":15635624568,
"num":1001
}查询文档
GET /索引库名/_doc/文档id
GET /student/_doc/1查询结果
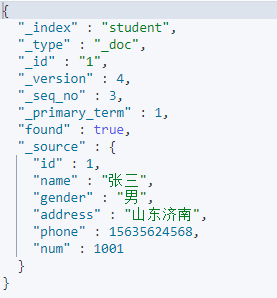
删除文档
# DELETE /索引库名/_doc/文档id
DELETE /student/_doc/1修改文档
#
POST /索引库名/_update/文档id
{
"doc":{
"修改字段":"新的值"
}
}
POST /student/_update/1
{
"doc":{
"address":"山东济南"
}
}搜索文档
GET /索引库名/_search
{
"query": {
"match": {
"索引字段": "搜索值"
}
}
}
GET /student/_search
{
"query": {
"match": {
"address": "陕西"
}
}
}结果集
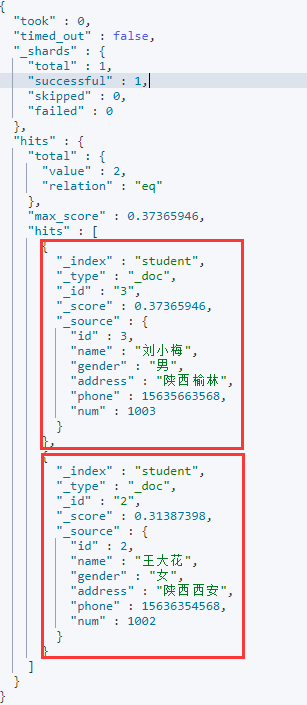
可以看到住址在陕西的有两名学生。
SpringBoot集成ES
环境搭建
1.指定版本,版本必须与安装的 ES 版本一致
XML
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>2.添加依赖
XML
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>3.初始化RestHighLevelClient类
java
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}索引库操作/文档操作
这里我就不分条分点细说,一个Controller搞定一切,同时结合API接口测试模块,通过接口对ES进行索引库操作/文档操作。
这里的一切操作都是在ES处于运行状态下进行的
java
@RestController
@RequestMapping(path = "/es")
public class EsController {
//集成ElasticSearch及高亮展示
@Autowired
RestHighLevelClient restHighLevelClient;
@RequestMapping("/indexOper1")
public String indexOper1() throws IOException {
//创建索引库
CreateIndexRequest createIndexRequest = new CreateIndexRequest("users");
restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
//判断库为例
GetIndexRequest getIndexRequest = new GetIndexRequest("users");
boolean users = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(users);
return "success";
}
@RequestMapping("/indexOper2")
public String indexOper2() throws IOException {
//删除库
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("users");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
//判断库为例
GetIndexRequest getIndexRequest = new GetIndexRequest("users");
boolean users = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(users);
return "success";
}
@GetMapping(path = "/saveOper")
public String docOper() throws IOException {
//新增到ES
//模拟从前端传递过来的数据
News news = new News();
news.setId(1);
news.setTitle("美国今年要总统选择,拜登着急了");
news.setImg("aaaaasssss.jpg");
news.setContent("少时诵诗书所所所所所所所所所所所所所所所");
news.setCount(300);
//把News中的数据封装到NewsES
NewsES newsES = new NewsES();
//对象数据复制
BeanUtils.copyProperties(news,newsES);
//创建请求对象
IndexRequest indexRequest = new IndexRequest("newss").id(newsES.getId().toString());
indexRequest.source(new ObjectMapper().writeValueAsString(newsES), XContentType.JSON);
//执行
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
return "success";
}
@GetMapping(path = "/updateOper")
public String updateOper() throws IOException {
//修改ES
//模拟从前端传递过来的数据
News news = new News();
news.setId(1);
news.setTitle("修改修改修改修改修改修改,美国今年要总统选择,拜登着急了");
news.setImg("aaaaasssss.jpg");
news.setContent("少时诵诗书所所所所所所所所所所所所所所所");
news.setCount(300);
//把News中的数据封装到NewsES
NewsES newsES = new NewsES();
//对象数据复制
BeanUtils.copyProperties(news,newsES);
//创建请求对象
UpdateRequest updateRequest = new UpdateRequest("newss",newsES.getId().toString());
updateRequest.doc(new ObjectMapper().writeValueAsString(newsES), XContentType.JSON);
//执行
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
return "success";
}
@GetMapping(path = "/deleteOper")
public String deleteOper() throws IOException {
//创建请求对象
DeleteRequest deleteRequest = new DeleteRequest("newss","1");
//执行
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
return "success";
}
@GetMapping(path = "/findOper")
public String findOper() throws IOException {
GetRequest getRequest = new GetRequest("newss", "1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//获取查询的内容,返回 json 格式
String json = getResponse.getSourceAsString();
//使用 jackson 组件将 json 字符串解析为对象
News news = new ObjectMapper().readValue(json, News.class);
System.out.println(news);
return "success";
}
@GetMapping(path = "/searchOper")
public String searchOper() throws IOException {
//创建一个搜索的请求
SearchRequest searchRequest = new SearchRequest("newss");
//设置关键字 高亮显示
searchRequest.source().highlighter(new HighlightBuilder().field("title").requireFieldMatch(false));
//封装搜索条件
searchRequest.source().query(QueryBuilders.termQuery("title","修改"));
//发送搜索请求, 接收搜索的结果
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
ArrayList<NewsES> arrayList = new ArrayList<>();
//拿到库
SearchHits hits = search.getHits();
//拿到文档
SearchHit[] hits1 = hits.getHits();
//对文档拆分
for (SearchHit searchHit : hits1){
String json = searchHit.getSourceAsString();
NewsES newsES = new ObjectMapper().readValue(json,NewsES.class);
//获取高亮名称
Map<String, HighlightField> highlightFields = searchHit.getHighlightFields();
HighlightField titleField = highlightFields.get("title");
String highttitle = titleField.getFragments()[0].string();
newsES.setTitle(highttitle);//用添加了高亮的标题替换原始文档标题内容
arrayList.add(newsES);
}
System.out.println(arrayList);
return "success";
}
@GetMapping(path = "/searchOper2")
public String searchOper2() throws IOException {
//创建一个搜索的请求
SearchRequest searchRequest = new SearchRequest("newss");
//封装搜索条件
searchRequest.source().query(QueryBuilders.termQuery("title","修"));
//发送搜索请求, 接收搜索的结果
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
ArrayList<NewsES> arrayList = new ArrayList<>();
//拿到库
SearchHits hits = search.getHits();
//拿到文档
SearchHit[] hits1 = hits.getHits();
//对文档拆分
for (SearchHit searchHit : hits1){
String json = searchHit.getSourceAsString();
NewsES newsES = new ObjectMapper().readValue(json,NewsES.class);
arrayList.add(newsES);
}
System.out.println(arrayList);
return "success";
}
}这里使用的是ik分词器最细粒度划分,而非标准分词,只有当搜索词条长度>2时才能正常搜索,但也符合正常用户使用细节,当然也可以使用标准分词器,二者各有特色。