序言
谈到 Go 语言就一定离不来他的高并发能力 ,谈到他的高并发能力 就一定离不开一个概念 --- 协程 。这对大家可能是一个陌生的概念,我们在操作系统中学习到了进程,线程,但是很少听过协程。通过这篇文章,让大家理解 Go 语言这个重要的拼图。
一、协程是什么
1. 回顾发展历史
高并发能力的发展,其实就是一个既要又要的过程。在提供高性能的同时,我还希望能够尽量的节约系统资源。从原来的多进程、多线程实现高并发,到现在的多协程实现高并发也确实实现了模型越来越轻量,能力越来越强大。让我们来看看发展历程吧:
1.1 多进程的出现
随着多核 CPU 的出现,最开始是使用多进程来并发处理任务,解决单任务顺序执行效率低的问题。但是多进程的缺点也非常明显:
- 创建和销毁的开销非常大。进程是资源分配的单位,每创建一个进程都需要分配对应的资源
- 进程切换开销大。开销主要在上下文的切换和恢复,以及 CPU 缓存实效
- 进程间通信复杂。因为进程间是相互独立的,所以不具备直接通信的环境
那是不是多进程没有优点呢?非也:
- 安全性高。进程间是相互独立的,所以一个进程的崩溃不会影响到其他进程
为了解决上述多进程存在的问题,多线程出现了。
1.2 多线程的出现
现在对于一个线程的定义是,线程是进行调度的单位,一个进程中可以包含多个线程,多个线程共享同一个进程下的资源。多线程的出现大大降低了并发的成本,比起进程一个线程只需要创建私有的资源(寄存器状态以及私有栈)其他的资源都是共享进程的。优点如下:
- 比进程轻量,创建和销毁的开销小
- 切换的成本比进程小,只需要切换私有的数据
- 具有天然互相通信的环境,因为线程间共享同一个进程的资源
但是线程也存在不可忽视的缺点:
- 多线程竞争资源容易引发死锁、竞态条件
- 线程数量过多时切换成本依然很高
- 线程栈占用较大内存(通常1MB左右)
这里我们具体关注第二个问题,线程切换成本。当系统中的线程数量增多时,操作系统会不断的切换线程保证每一个线程都能够得到执行,所以大部分的时间花在了切换线程上这自然是一种浪费,线程的切换成本不可忽视:

线程切换是一个复杂但必要的过程,它涉及到用户态 ↔ 内核态的切换、线程上下文的保存与恢复、调度器的选择等多个步骤。
1.3 多协程的出现
为了进一步提升并发能力,产生了现在的协程,他也有一个熟悉的名字 用户级线程 。所谓的用户级线程也就是创建、调度、切换等操作都是在用户态下进行的,不需要陷入到内核态。并且协程比起线程还更加的轻量!主要体现在一个线程的栈大小在 1MB 左右,但是一个协程的初始化栈大小在 2KB 左右(Go 语言初始大小,可动态拓展),这也是协程在十万级别的量级依然抗打的原因!来比较一下协程和线程吧:
| 对比维度 | 线程 | 协程 |
|---|---|---|
| 大小 | 1MB左右 | 2KB左右(可动态拓展) |
| 操作系统感知 | YES |
NO |
| 切换成本 | 涉及到用户态和内核态切换 | 纯用户态 |
2. 协程的三种实现模型
也许大家对与上面描述的 操作系统感知 会产生疑惑?回顾下,线程是调度的基本单位,他的创建,切换,销毁等一些列操作都是需要内核参与的,但是用户级线程的一系列操作是在用户态下进行的,对于内核来说我只是在执行程序,不关心程序的具体内容是什么,自然也不会感知到协程的存在。
那么协程总归还是依赖线程来执行,他们之间的关系有三种:1:1, 1:N, M:N依次来介绍下:
2.1 1:1 模型
这是最简单的模型,一个协程对应一个线程:
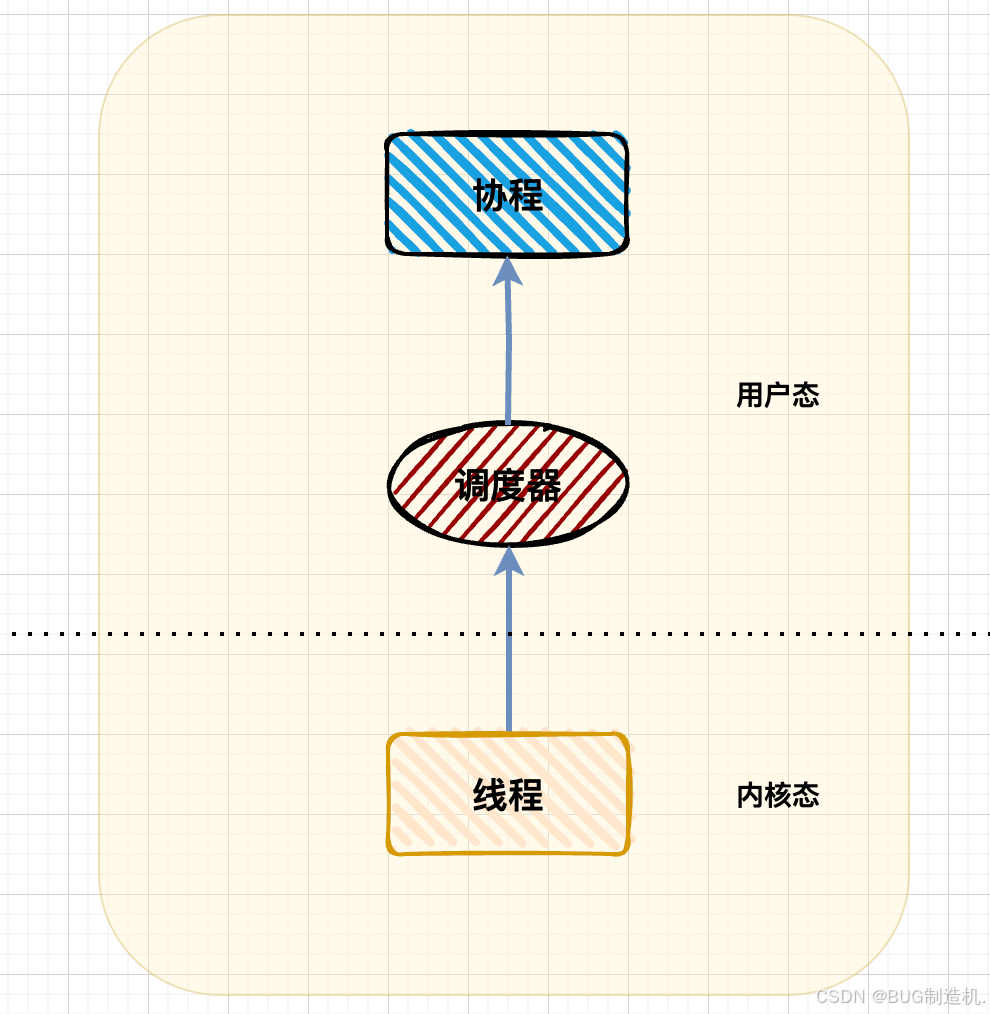 优点是简单,协程之间不会相互阻塞;缺点也很明显,太奢侈了,每创建一个协程就要创建一个线程,仿佛回到了问题的起点...
优点是简单,协程之间不会相互阻塞;缺点也很明显,太奢侈了,每创建一个协程就要创建一个线程,仿佛回到了问题的起点...
2.2 N:1 模型
多个协程对应一个线程:
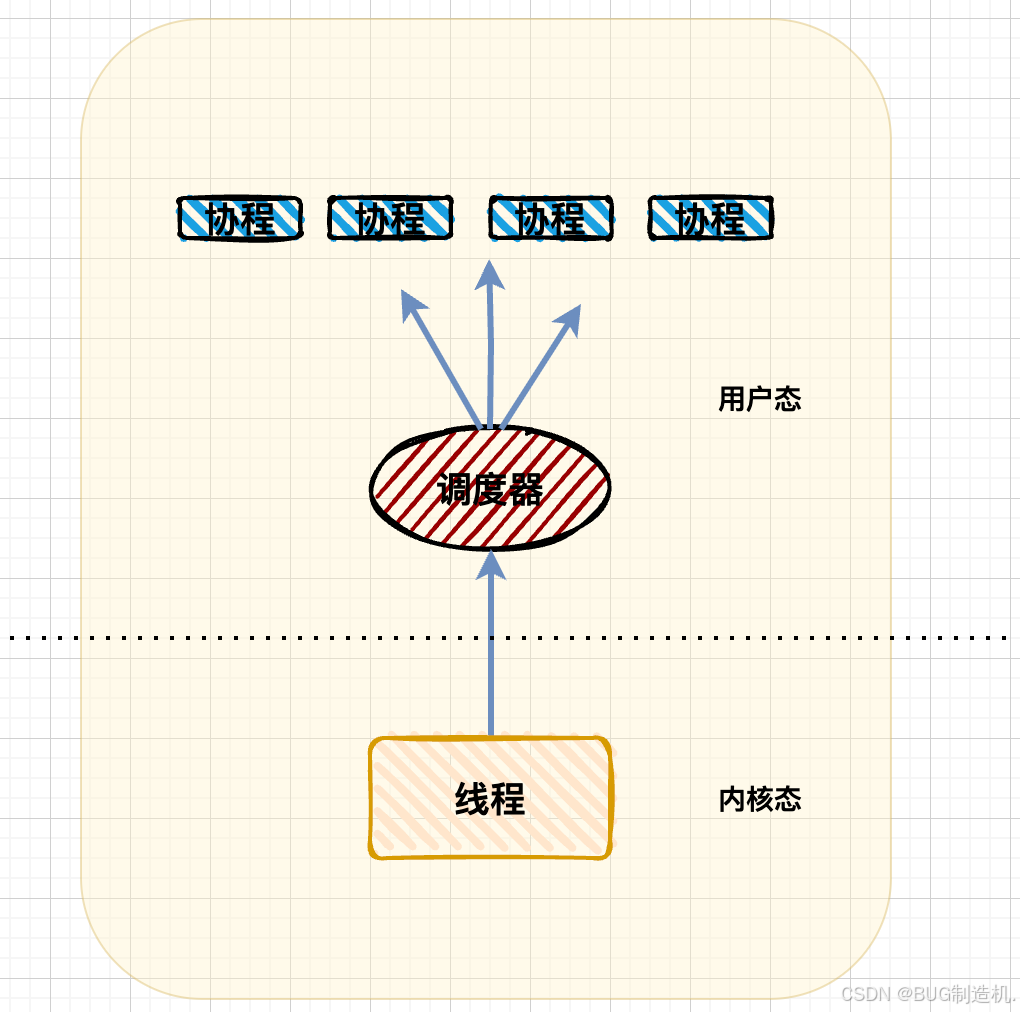 优点是很明显:
优点是很明显:
- 协程切换的效率很高,都在用户态下进行
缺点也不容小觑:
- 不能充分的利用多核 CPU
- 一个协程阻塞会影响其他协程的执行
- 多个协程共享一个线程的时间片,协程不能充分的执行
2.3 M:N 模型
这个模型是现在被 Go 语言 所采用的,虽然解决了上述两者现存的缺点,但是实现起来比较复杂:
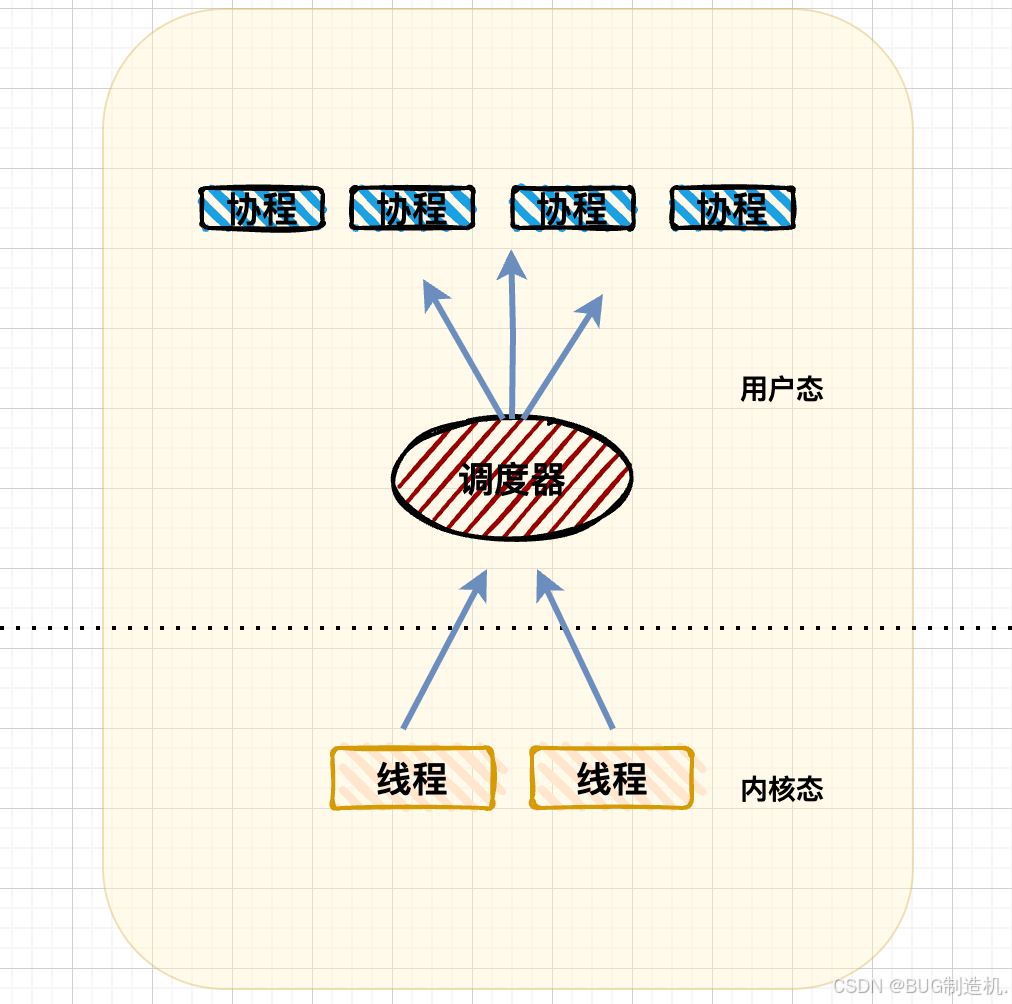
协程被分配到不同的线程上执行,除了兼具上述两种模型的优点,它还具备如下优点:
- 一个协程阻塞后,可以分配到其他线程执行
- 能够充分的利用多核CPU
现在我们了解了协程是什么,我们为什么需要协程,以及协程的三种模型,现在我们再来了解 Go 语言 的协程是怎么实现的。
二、GMP 模型
现在我们了解了 Go 语言 的协程是使用的 M:N 模型,但是具体是怎么实现的呢?线程是怎么调度协程的呢?
1. 被废弃 GM 模型
在正事介绍 GMP 模型之前,我们先来介绍一下他的前身 GM 模型:
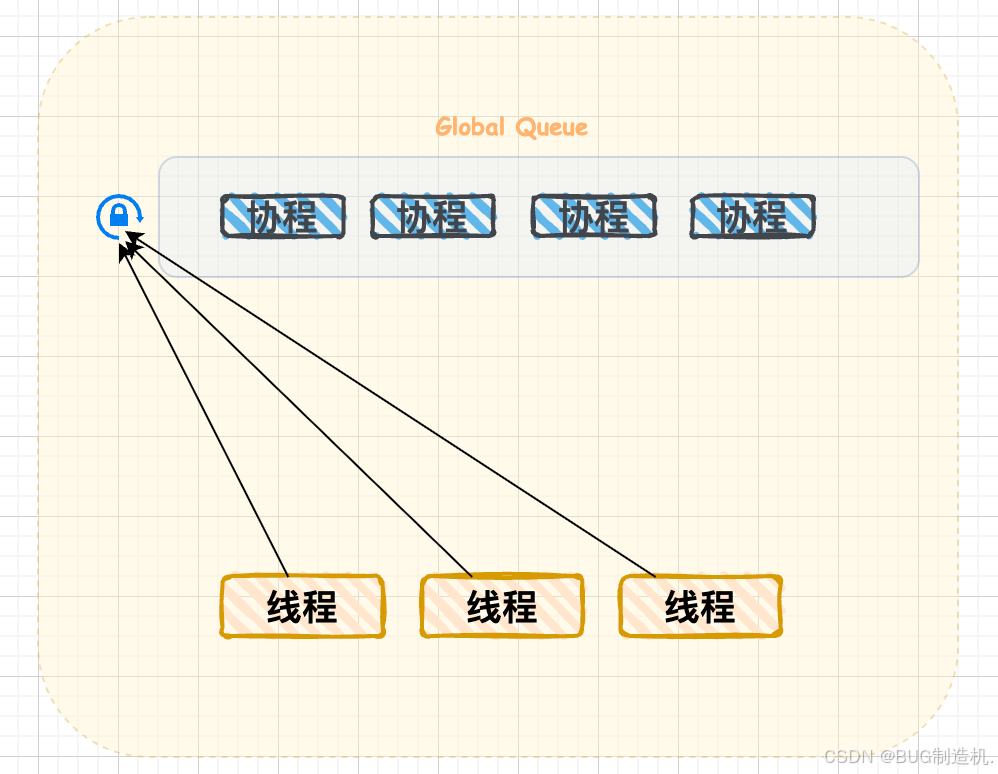
设置了一个全局的队列,队列中存储着需要执行的协程,每一个线程首先去获取锁,然后取出协程执行。这个模型的优点是很简单,但是缺点如下:
- 锁的竞争非常激烈,限制了整体的性能
- 局部性不强,当一个协程创建了另外的协程,有可能不在同一个线程上执行,没有充分利用的利用到缓存
对于大锁问题一般可以有两种思路,降低锁的颗粒度以及将资源分区。
2. GMP 模型
比起最初的 GM 新增了一个 P ,这给我们带来了什么呢?
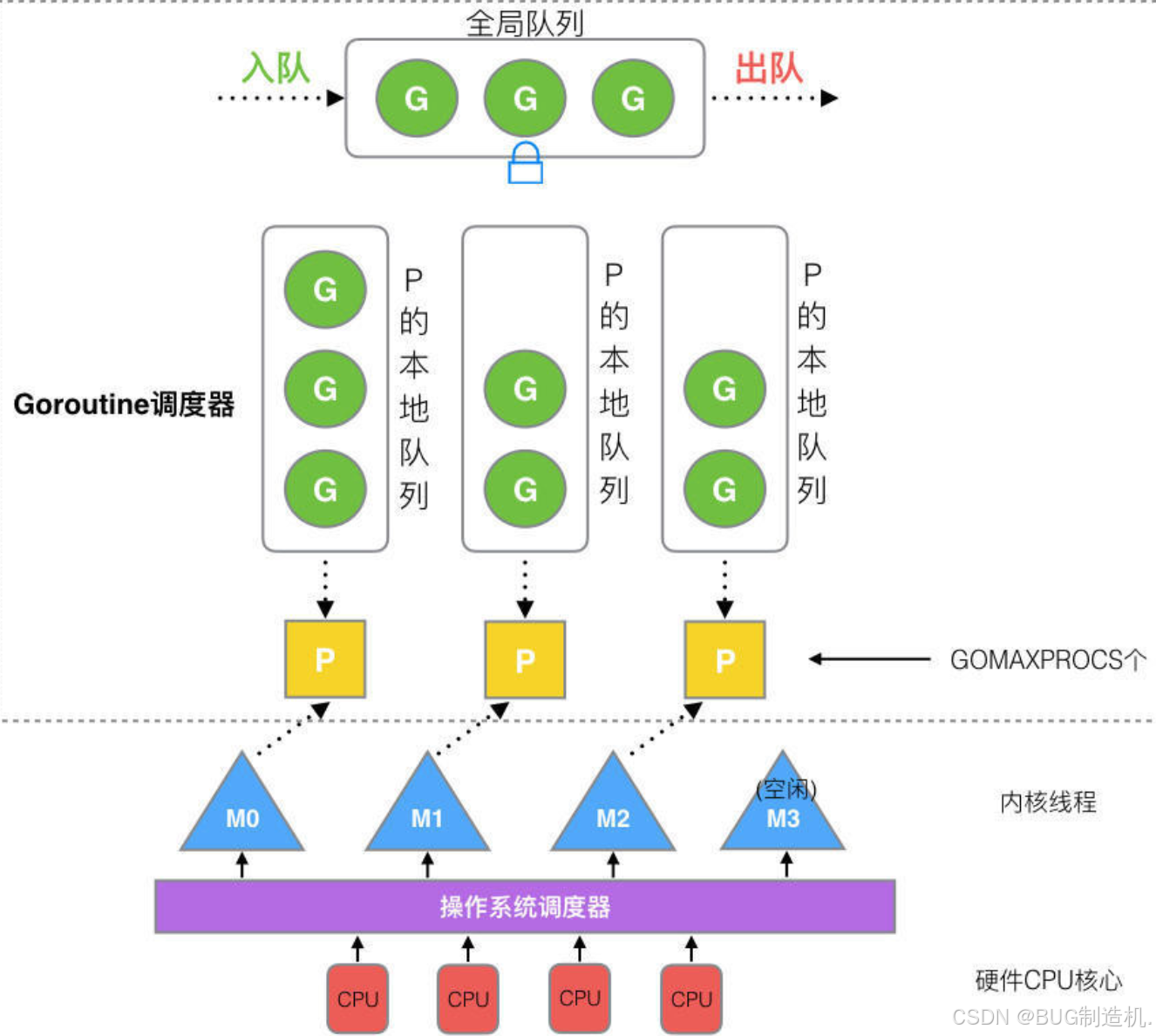
这里的 P 代表处理器,一个线程必须得到一个 P 才能获取协程执行。
这句话非常的重要!如果不考虑环境因素,Go 在运行的时候最多支持的并行数量取决于 P 的数量,P 的默认值也一般是 CPU 的核心数。
那这里有多少个 P 就对应多少个 M 哦?不是的,假设一个 M 在执行一个 G 时因为各种原因被阻塞了(IO、系统调用等 ),那么这个 P 就会和当前 M 解除,去寻找当前有无空闲的 M ,如果没有就创建一个 M 执行。
P 中存在一个本地队列,线程优先执行本地队列中的协程,当本地队列中的协程执行完了之后再会去获取全局队列中的协程,如果还没有就回去 偷取 其他 P 中的协程。
这属于上述解决上述解决大锁的第二个方法,资源分区。并且 *M * 寻找 G 执行逻辑是放在 G0 中的,每一个 M 创建的时候会自带一个 G0 ,所以一个 M 在执行的过程也是不断交替执行 G 和 G0 的过程。
3. 调度场景解析
3.1 创建新的协程
现在 M1 绑定了 P1 从本地队列中取出了 G1 执行,执行过程中 G1 创建了 G3 。那么首先会考虑本地队列是否有新的空间,如果有的话直接放在本地队列(更好的局部性,充分的利用 CPU 中的 Cache 缓存),但是本地队列满了(256)的话,就会将队列中的一部分 G 以及新创建的 G 转移到全局队列中。
3.2 获取新的协程
现在 M1 将 G1 执行完毕了,需要通过执行 G0 调度新的协程,过程如下:
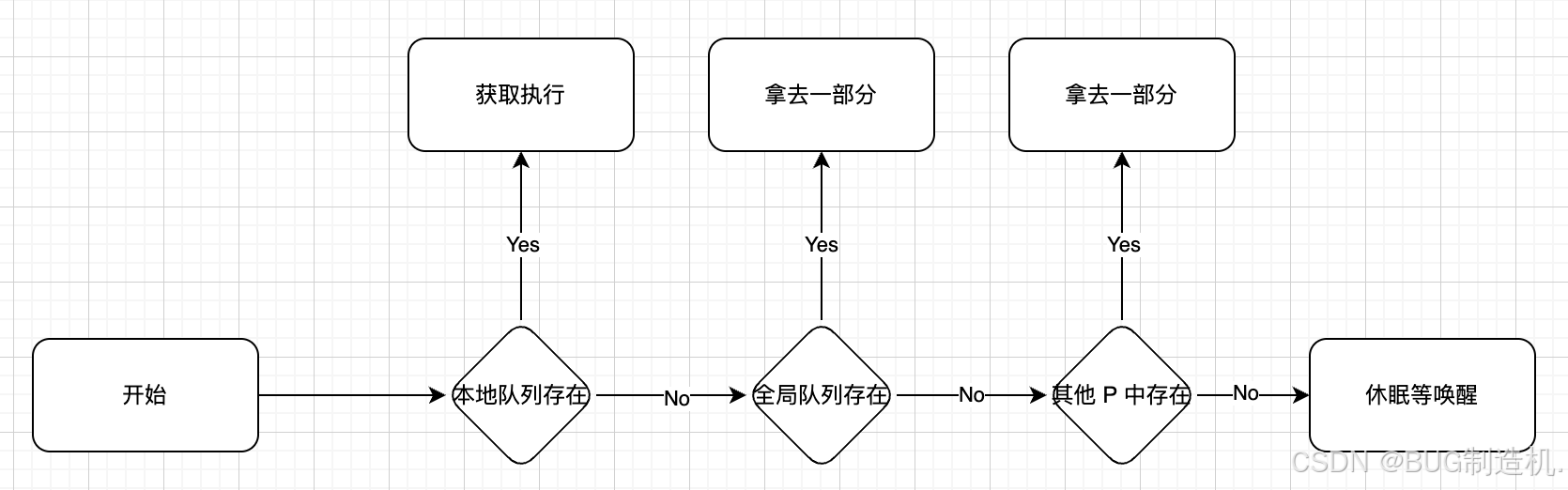
如果最后都没有获取到 G ,那么 M 并不会立刻被销毁,而是被缓存到全局的一个线程池当中,而 P 也会被存储到全局的一个 P 列表当中。当产生新的 G 时,会唤醒一个 M 去结合 P 然后去寻找 G 执行。
这里补充一下:当没有获取到新的协程的时候,有些说法是会允许部分的 M 处于一个自旋的状态(比如 1 / 4 P 的数量),当有新的 G 的时候可以提升调度响应速度,减少唤醒休眠开销
3.3 调用了系统调用或被阻塞
现在当 M1 结合 P1 正在执行 G1 ,G1 进行了系统调用,这时 P1 会立刻解除绑定,然后如果他自己的本地队列,或者全局队列,再或者其他 P 的本地队列存在着可执行的 G ,那么P1 就会绑定其他的 M 来继续执行,否则就会加入到全局的空闲 P 列表中。
首先会判断有无休眠的 M ,如果有的话唤醒再和 P1 绑定,如果没有就会创建一个 M。
当 M1 和 G1 从系统调用恢复后,会尝试获取一个 P 来继续执行,如果没有获取到的话,就会把 G1 放到全局队列,然后自己就会被休眠。
三、总结
GMP 模型通过轻量的 goroutine、智能的线程管理与高效的调度策略,实现了高并发、低开销、资源利用率高的极致并发性能。