单目视觉测距原理
单目视觉测距有两种方式。
第一种,是通过深度神经网络来预测深度,这需要大量的训练数据。训练后的单目视觉摄像头可以认识道路上最典型的参与者------人、汽车、卡车、摩托车,或是其他障碍物(雪糕桶之类),然后对识别到的物体进行距离估计。
第二种,是结合车辆的运动信息,用时序上的相邻帧进行"类双目视觉"的检测,这种方法也被称为motion stereo或structure from motion。
单目摄像头的算法思路是先识别后测距:首先通过图像识别,然后根据图像大小和高度进一步估算障碍物与本车距离。
单目深度估计
双目测距
双目摄像头的算法思路是先测距后识别:首先利用视差直接测量物体与车的距离,然后在识别阶段,双目仍然要利用单目一样利用深度学习算法,进一步识别障碍物到底是什么。
根据双目视觉的测距原理,通常将其实现过程分为五个步骤:相机标定,图像获取,图像预处理,特征提取与立体匹配,三维重构。其中,相机标定是为了得 到相机的内外参数和畸变系数等,可以离线进行;而左右相机图像获取的同步性,图像预处理的质量和一致性,以及立体匹配(获取视差信息)和三维重构(获取距离信息)算法的实时性要求带来的巨大运算量,对在嵌入式平台上实现双目视觉ADAS提出了挑战。
与单目视觉相比,双目视觉测距精度较高。
双目相机需要同步。
立体匹配计算量大。
受光影响大:在大雨天气或者前方强光源的情况下,前视摄像头有可能看不清车道线,环视摄像头斜向下看车道线且可 以提供多个角度,基本不会受到地面积水反光的影响,功能可以比前视做得更稳定。但同时也要考虑侧向 无车灯照射时,摄像头的夜间表现。
左右镜头的光照不同,环境光照过强过弱,不均匀等。
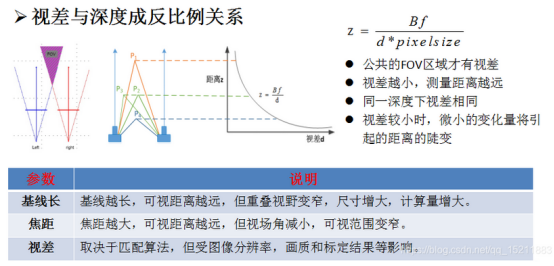
相机间距越小,检测距离越近;相机间距越大,检测距离越远。
遮挡、弱纹理和重复纹理区域、深度不连续区域难以获取高精度和高鲁棒的视差信息,自动标定算法不成熟。
首先,和单目视觉相比双目视觉的成本会更高(无论是多一个摄像头,还是对计算深度图算力的要求),但实话实说还是在可接受的范围内,毕竟和激光雷达比都是小钱,也不需要为单目视觉庞大的训练集买单。
其次,双目视觉本身对于目标的纹理是有要求的,既不能太简单,也不能太复杂。一堵大白墙对于双目视觉来说识别是有风险的,而激光雷达等传感器则可以很好地进行检测。但话说回来,真实场景中也不太可能有一堵大白墙横在路中间,再看看激光雷达的价格,哎,算了吧。
再次,双目视觉对于远距离物体探测的精度是弱于激光雷达的。双目深度的误差是与距离的平方成正比的,而激光雷达的精度基本上和距离无关。
双目立体匹配
PatchMatch SGBM SGM AD-census
【论文阅读】(2023 奥比中光 综述)双目立体视觉研究进展与应用 - 仓颉ZL - 博客园

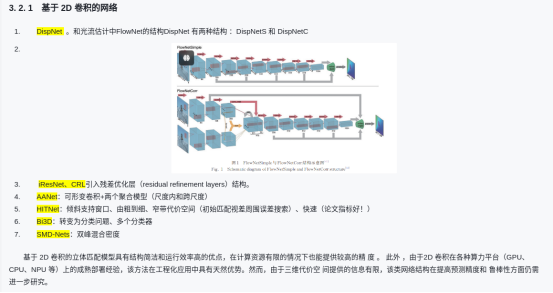


单目深度估计
zeroDepth 2023
depth-any
单目3D mono
smoke
MonoDLE
CenterNet
Lite-FPN for keypoint-based Monocular 3D object detect
https://www.zhihu.com/question/516518724/answer/3060443825?utm_id=0
qd-3dt
Complex YOLO
https://zhuanlan.zhihu.com/p/483833539?utm_id=0
MonoDLE
【论文解读】单目3D目标检测 MonoDLE(CVPR2021)-CSDN博客
MonoFlex 2021
【论文解读】单目3D目标检测 MonoFlex(CVPR 2021)-CSDN博客
【单目3D目标检测】MonoFlex论文精读与代码解析-CSDN博客
MonoCD 2024
https://zhuanlan.zhihu.com/p/691322485
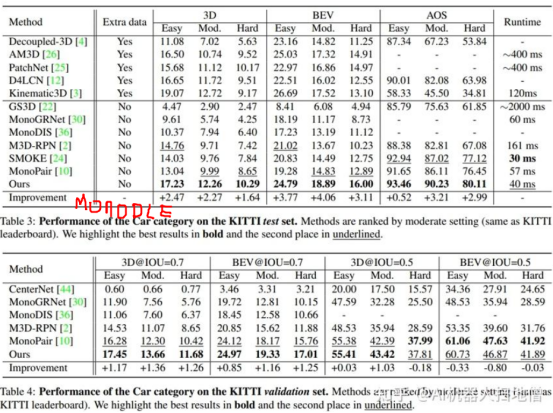

朝向预测运动轨迹
添加时序的模型比较大
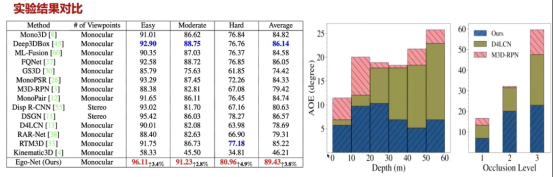

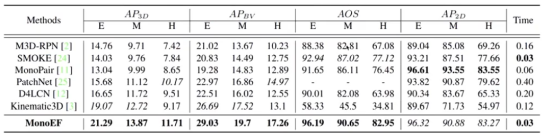
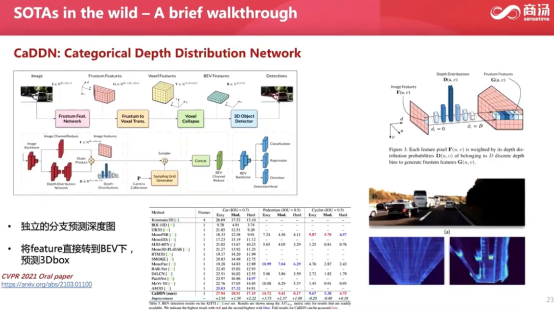

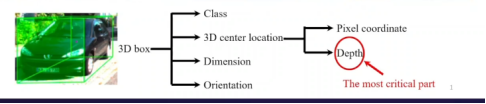
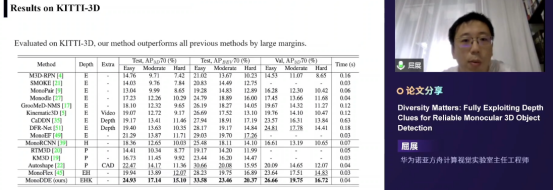
对深度信息的恢复是对3D目标检测最关键的任务
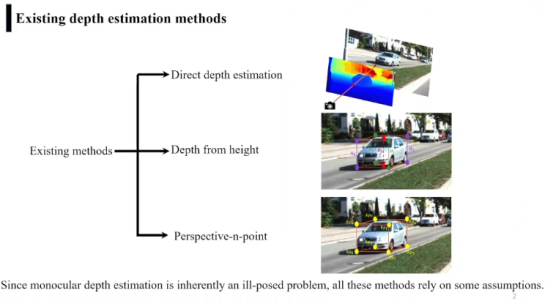
当前case与深度估计所依赖的假设相冲突,所深度估计结果会产生严重的退化。
对一个目标使用多种方法(依赖不同的假设)产生多种深度估计。
MonoDLE
单目3D目标检测------MonoDLE 模型训练 | 模型推理-CSDN博客
使用预训练权重推理
首先下载预训练权重:
https://drive.google.com/file/d/1jaGdvu_XFn5woX0eJ5I2R6wIcBLVMJV6/view
下载好的权重名称为:checkpoint_epoch_140.pth,新建一个文件夹monocon-pytorch-main/checkpoints/,存放权重
然后修改配置文件experiments/example/kitti_example.yaml
tester:
type: *dataset_type
mode: single # 'single' or 'all'
checkpoint: '../../checkpoints/checkpoint_epoch_140.pth' # for 'single' mode
checkpoints_dir: '../../checkpoints' # for 'all' model
threshold: 0.2 # confidence filter
python ../../tools/train_val.py --config kitti_example.yaml --e
推理完成后,结果存放在experiments/example/outputs/data
生成的结果,和kitii标签格式是一致的。
先将kitti 原始数据testing中label_2备份,将新生成的标签experiments/example/outputs/data复制到kitti 原始数据testing中label_2中,然后可视化。
单目3D检测入门!从图像角度分析3D目标检测场景:MonoDLE-CSDN博客
【论文解读】单目3D目标检测 MonoDLE(CVPR2021)-CSDN博客
https://zhuanlan.zhihu.com/p/452886061
查看工业界 https://www.zhihu.com/question/516518724/answer/3381421318
3D车道线

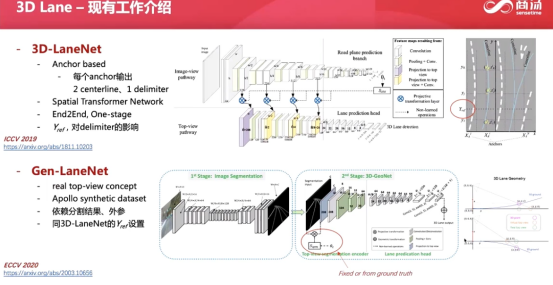

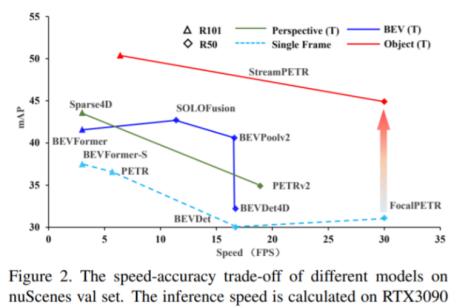
bev 感知算法
Depth-anything v2 深度估计
BEVDepth首次将纯视觉与激光雷达的差距缩到10%以内