0.简介
在分布式系统中,生成全局唯一的id是一个常见的需求。由于分布式系统的特性(多节点,网络分区,时钟不同步等),传统的单机ID生成方式不再适用,所以一些分布式生成方式应运而生,本文将对常见的几种分布式ID生成方法的原理和应用进行介绍。
1.分布式ID的生成要求
分布式ID的生成一般要满足以下要求:
1)全局唯一:生成的 ID 必须在整个系统中唯一。
2)高性能:ID 生成的速度要快,不能成为系统的瓶颈。
3)高可用:ID 生成服务必须高可用,不能因为单点故障导致系统不可用。
4)趋势递增:生成的 ID 最好具有递增趋势,便于数据库索引和排序。
2.数据库自增方式
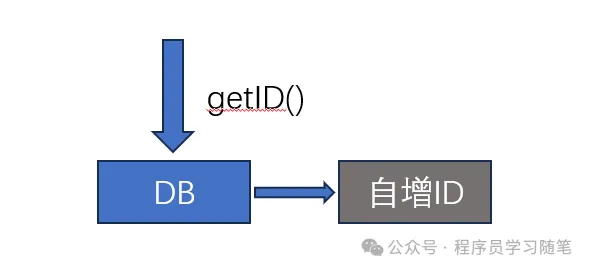
数据库的自增方式生成分布式ID就是使用数据库的自增列来实现,其优缺点如下:
优点:
1)使用简单,直接使用数据库已有的自增功能;
2)能够保证唯一性和递增性;
缺点:
1)性能瓶颈,在高并发场景下,数据库可能成为性能瓶颈;
2)可用性问题,存在单点故障可能;
使用场景:主要适用小规模分布式系统,对性能要求不高的场景。
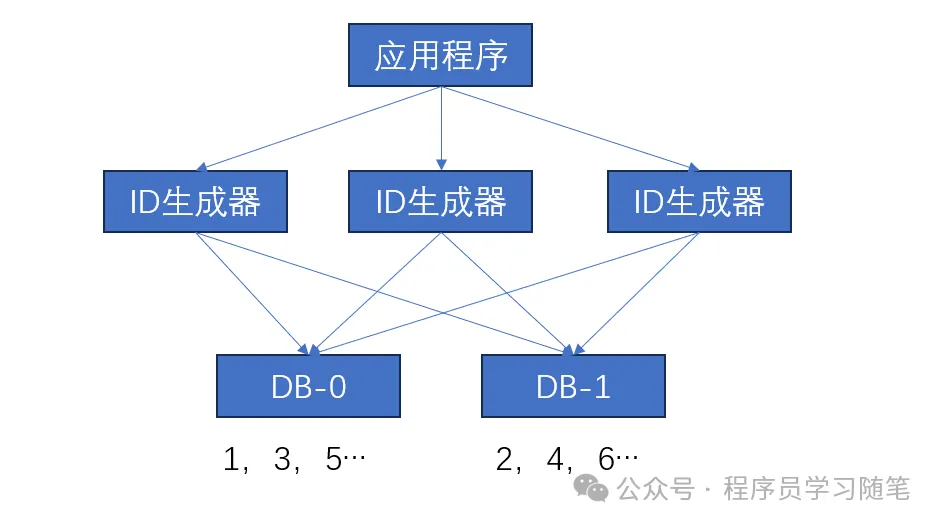
改进方式:
1)冗余主节点,避免单点写入。
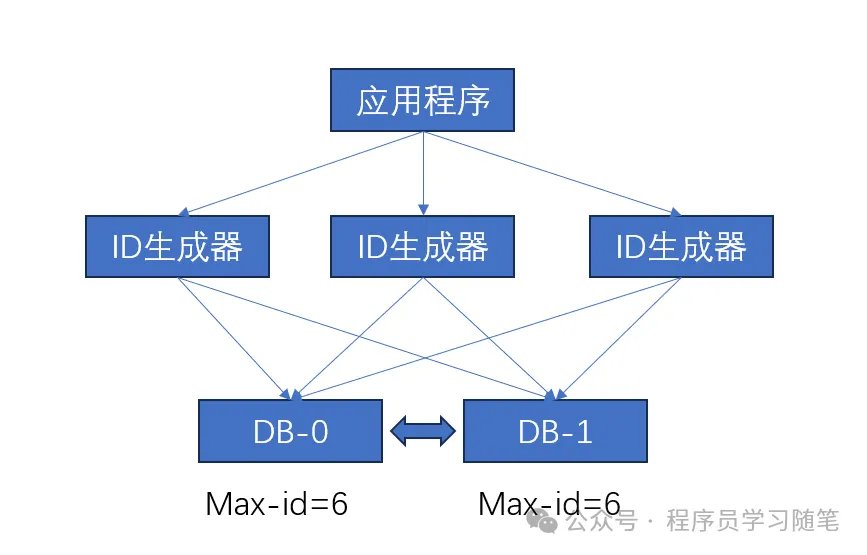
2)批量生成id,降低读写频率。其不需要挨个获取,一次获取多个同时更新max-id,下次就继续在max-id增加。
3.UUID
UUID(Universally Unique Identifier)是一个 128 位的全局唯一标识符,通常表示为 32 个十六进制字符,例如:
cpp
550e8400-e29b-41d4-a716-446655440000优点:
1)简单易用:无需中心化服务,每个节点都可以独立生成 UUID。
2)全局唯一:UUID 的生成基于时间戳、随机数和 MAC 地址,几乎不可能重复。
3)性能个扩展性好:本地生成,没有扩展和性能瓶颈。
缺点:
1)长度较长:128 位的 UUID 存储和传输以及查询开销较大,可以拆成两个uint64整数存储。
2)无序性:UUID 是随机生成的,不具备递增趋势,不利于数据库索引。
适用场景:对ID长度以及有序性要求不高的场景。
改进方式:
1)可以增加时间信息,如在开头增加毫秒数,优点就是能保证递增;缺点就是可能在同一时间的话可能会出现冲突。
4.Snowflake算法
4.1 原理
Snowflake 是 Twitter 开源的分布式 ID 生成算法,生成的 ID 是一个 64 位的整数,结构如下:
| 1 bit | 41 bits | 10 bits | 12 bits |
|---|---|---|---|
| sign | timestamp | machine ID | sequence |
sign:符号位,固定为 0。
timestamp:41 位的时间戳,表示从某个起始时间到当前时间的毫秒数。
machine ID:10 位的机器 ID,用于区分不同的节点。
sequence:12 位的序列号,用于同一毫秒内生成多个 ID。
优点:
1)高性能:本地生成 ID,无需网络通信。
2)趋势递增:ID 按时间戳递增,便于数据库索引。
3)高可用:无中心化服务,每个节点独立生成 ID。
缺点:
1)时钟回拨问题:如果系统时钟回拨,可能导致 ID 重复。
2)机器 ID 分配:需要手动或通过外部服务分配机器 ID。
适用场景:大规模分布式系统,对性能和有序性要求较高的场景。
改进方式:可以通过等待时间同步解决时钟回拨,通过扩展时间位来解决时间一出,通过动态机器id分配解决手动分配问题。
5.Redis自增ID
该方法是利用 Redis 的原子操作 INCR 或 INCRBY 生成全局唯一的 ID。
使用 Redis 的 INCR 命令生成自增 ID:
cpp
INCR id_generator如果需要生成更长的 ID,可以使用
cpp
INCRBY id_generator 1000优点:
1)高性能:Redis 的 INCR 操作是原子性的,性能较高。
2)简单易用:实现简单,无需复杂的算法。
缺点:
1)依赖 Redis:需要维护 Redis 服务,存在单点故障风险。
2)ID 长度有限:Redis 的 INCR 生成的 ID 是 64 位整数,可能不够用。
适用场景:中小规模分布式系统,对性能和有序性有一定要求的场景。
改进方式:可以参考数据库自增id方式优化。
6.Leaf算法
Leaf 是美团开源的分布式 ID 生成服务,结合了数据库和 Snowflake 算法的优点。它支持两种模式:
1)号段模式:从数据库批量获取 ID 段,缓存在本地。
2)Snowflake 模式:基于 Snowflake 算法生成 ID。
优点:
1)高性能:号段模式减少了数据库访问次数,Snowflake 模式本地生成 ID。
2)高可用:支持多节点部署,无单点故障。
3)灵活配置:支持号段模式和 Snowflake 模式切换。
缺点:
1)复杂度较高:需要部署和维护 Leaf 服务。
适用场景:大规模分布式系统,对性能和可用性要求较高的场景。
分布式id生成的五种方法