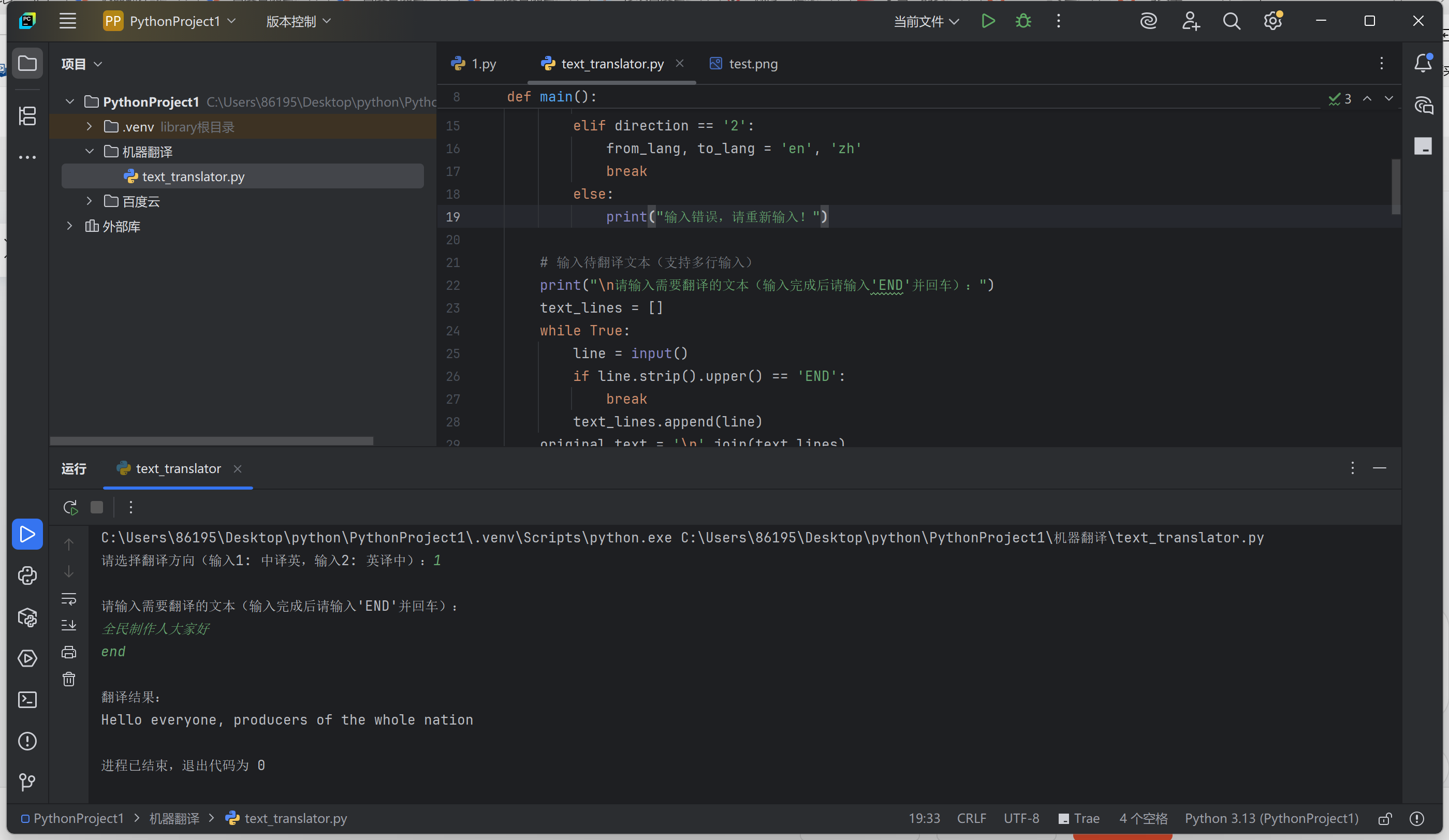
新建Python文件,叫
text_translator.py输入
import requests
import json
API_KEY = "glYiYVF2dSc7EQ8n78VDRCpa" # 替换为自己的API Key
SECRET_KEY = "kUlhze8OQZ7xbVRp" # 替换为自己的Secret Key
def main():
# 选择翻译方向
while True:
direction = input("请选择翻译方向(输入1: 中译英,输入2: 英译中):").strip()
if direction == '1':
from_lang, to_lang = 'zh', 'en'
break
elif direction == '2':
from_lang, to_lang = 'en', 'zh'
break
else:
print("输入错误,请重新输入!")
# 输入待翻译文本(支持多行输入)
print("\n请输入需要翻译的文本(输入完成后请输入'END'并回车):")
text_lines = []
while True:
line = input()
if line.strip().upper() == 'END':
break
text_lines.append(line)
original_text = '\n'.join(text_lines)
if not original_text.strip():
print("错误:输入的文本不能为空!")
return
# 调用翻译API
try:
url = f"https://aip.baidubce.com/rpc/2.0/mt/texttrans/v1?access_token={get_access_token()}"
payload = json.dumps({
"from": from_lang,
"to": to_lang,
"q": original_text
}, ensure_ascii=False)
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.post(url, headers=headers, data=payload.encode('utf-8'))
response.raise_for_status() # 检查HTTP状态码是否正常
result = response.json()
if 'error_code' in result:
print(f"\n翻译失败!错误码:{result['error_code']},错误信息:{result['error_msg']}")
else:
translated_text = result['result']['trans_result'][0]['dst']
print("\n翻译结果:")
print(translated_text)
except requests.exceptions.RequestException as e:
print(f"\n网络请求异常:{str(e)}")
except KeyError as e:
print(f"\n解析结果失败,可能API返回格式变化:{str(e)}")
except Exception as e:
print(f"\n发生未知错误:{str(e)}")
def get_access_token():
"""获取API访问凭证"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": API_KEY,
"client_secret": SECRET_KEY
}
try:
response = requests.post(url, params=params)
response.raise_for_status()
return response.json().get("access_token")
except Exception as e:
print(f"获取access_token失败:{str(e)}")
return None
if __name__ == '__main__':
main()运行结果如图