开局叠甲,我们都爱nihui~
看到nihui老师的测评文章,里面评测了CPU,GPU,NPU的性能,关于NPU性能这一点看到如下结论:

就产生了一个疑问,NPU为什么在如此极端构造case的情况下还远不及理论的算力呢?
能不能尽可能深的去挖掘,去猜测导致如此的可能原因呢?
再叠个甲,由于本人能力有限,文章的信息不一定准确,如有纰漏请指正。其次,对NPU信息的挖掘,完全基于个人过去所学知识的合理推测。
1. 算力计算公式的问题
文中公式是:
print('gi8ops = ', 800 * 800 * 3 * 3 * 102 * 102 * 10.0 / (1024 * 1024 * 1024) / duration * 2)
我理解的是:总共有10个conv,每个conv输出是1*800*100*100,kernel size是3*3, 输入channel大小也是800,于是总的MAC量是:
10*800*100*100*3*3*800*2 MACs,就是总的计算量;
总的计算量除以真实跑的时间就得到了OPS(Operations Per Second),除以10^9就得到了TOPS。
所以我稍微改了下计算公式得到的结果就如下所示:

"性能无损猛涨5.6%"

2. 深入挖掘NPU信息
我们了解NPU架构信息的方式是看书《AI处理器硬件架构设计》,毕竟大家的架构都差不多;
了解具体某款NPU信息的方式是看文档《NPU_SDK_User_Guide.pdf》;
而,作为普通用户,要弄清性能问题时,则需要看profiler报告,接下来我么就基于SDK来一步一步看怎么生成profiler,并解读profiler信息,并基于perf信息来推断NPU的一些关键参数。
##2.1 如何配置profiler参数
Sdk文档中有说可以dump profile数据的,在build cfg里面设置profile = True;
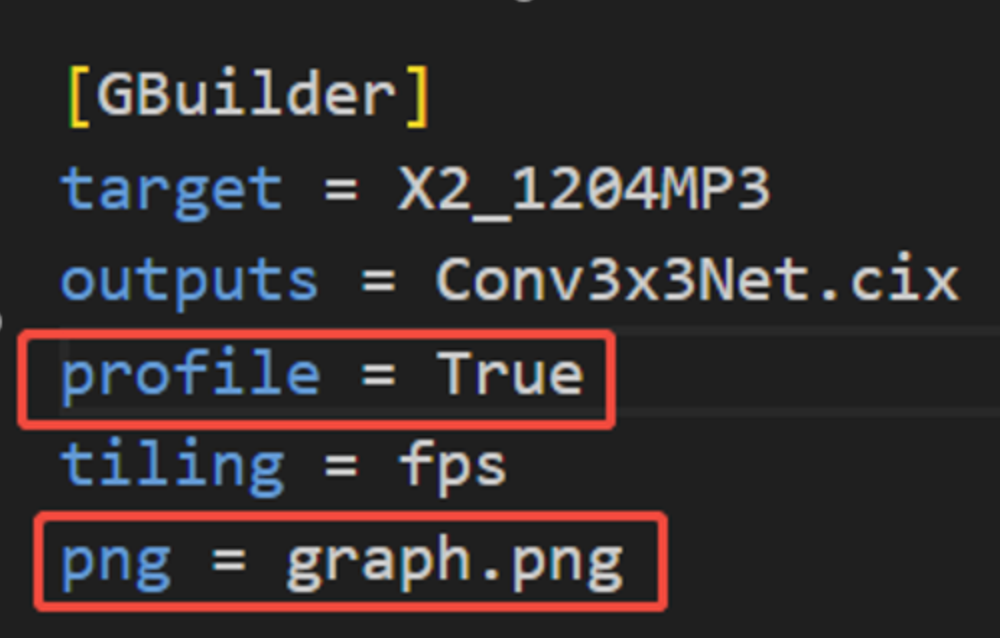
ps. 为了直接看最后生成的图长什么样子,我们要打开png输出选项,如上图所示。
这一步完成后,正常来说在执行指令cixbuild build.cfg之后,会生成最终的执行图,以及能输出profile报告的cix model文件,我们分两步走,先粗看下graph.png看下有什么端倪,其次带着这些疑问去生成最终的profiler报告,并在报告中找寻我们所需要的答案!
##2.2 解读graph.png
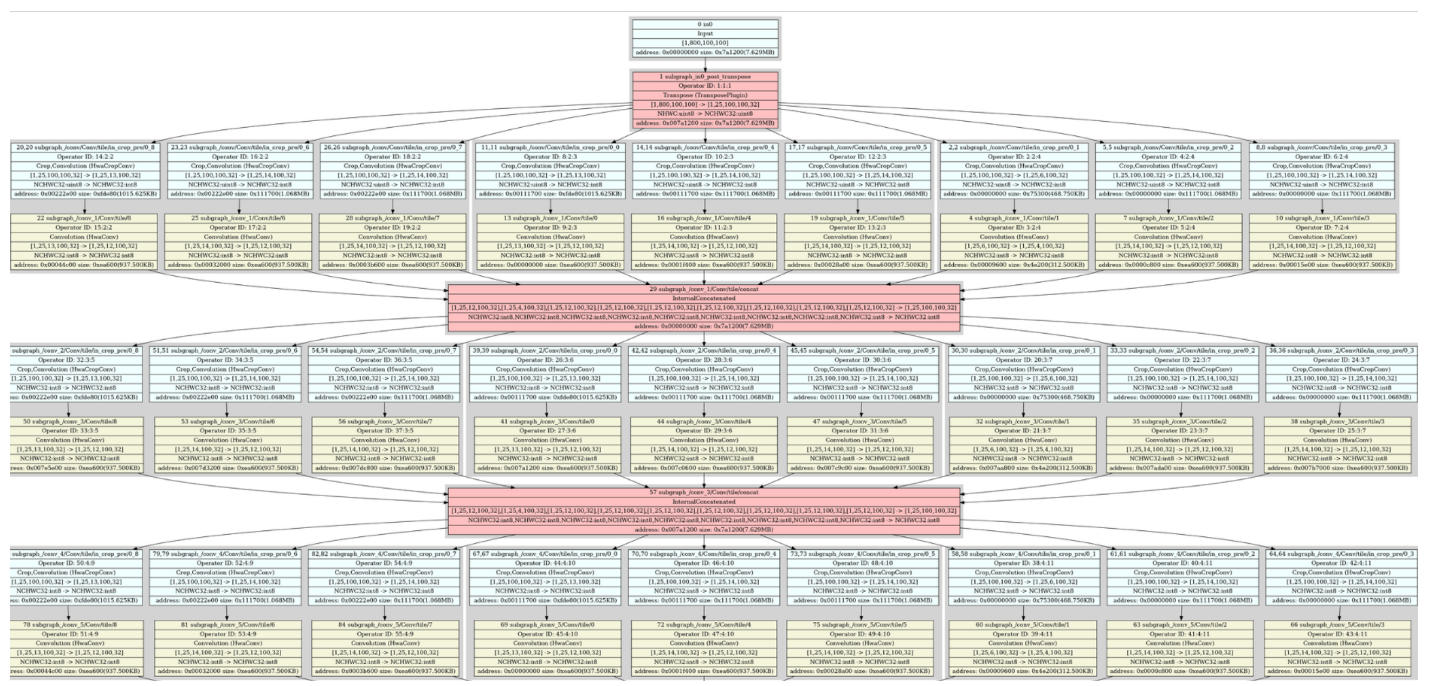
可以一打眼就看到的是,输入是多了个transpose,conv都有切分, 切分走的不是NHW而是Cout,为何图长这样?我们一个一个"推理"。
- transpose这里很好理解,是因为onnx支持data layout 为NCHW,而NPU这里是不支持NCHW,所以需要transpose层做转接,至于为什么不支持NCHW,这就是硬件架构相关的内容了,具体可参考《AI处理器硬件架构设计》。
这个transpose在整网中的占比多少?对算力的计算影响多大?我们留到后面章节的profiler报告解读环节解答。
- Conv之所以要做切分,是因为NPU是三核的,所以这里有切分,切Cout天然不会带入overlap,因此没选择切NHW;
但是切分就会涉及计算重叠、多核均衡、抢总线带宽等一系列问题,这些问题我们也等后面的profiler报告分析一并进行点评。
##2.3 生成profiler报告
来到了如何生成性能报告的部分了。
通常我认为在build.cfg里面设置了profiler=True,且板子上正常流程跑完后,是会输出一个性能原始数据,然后用cix_profiler就能生成性能报告;

实际情况是,默认跑完后并没有直接输出性能数据,而且我也不知道如何导出这个PerfData.bin数据,因此尝试去libnoe动态库内去看下API信息:
在开发板上我们找到/usr/lib/python3/dist-packages/libnoe.so动态库,查看CIX NOE UMD python APIs信息可以看到有Aipu_ioctl_tickcounter_t class接口, 而且有对应的IOCTL命令描述,

但遗憾的是折腾了好一会,并没有尝试成功。
因此,转向寻求其他方案,板子上找一下就能发现,有个aipu_profiler_test的工具,查看其使用方法,发现需要用到至少两个文件,aipu.bin/input.bin,现在问题是aipu.bin是怎么生成的?
直接说结论:cixbuild是一个封装脚本,我们看到里面就有aipu.bin的部分,cix打完包后就删除了,我们只要加点代码,提前把它抽出来就好了。
我们在~/anaconda3/envs/cix_npu/lib/python3.8/site-packages/AIPUBuilder/build_cix.py
下找到脚本源码, 稍微改下即可得到aipu.bin
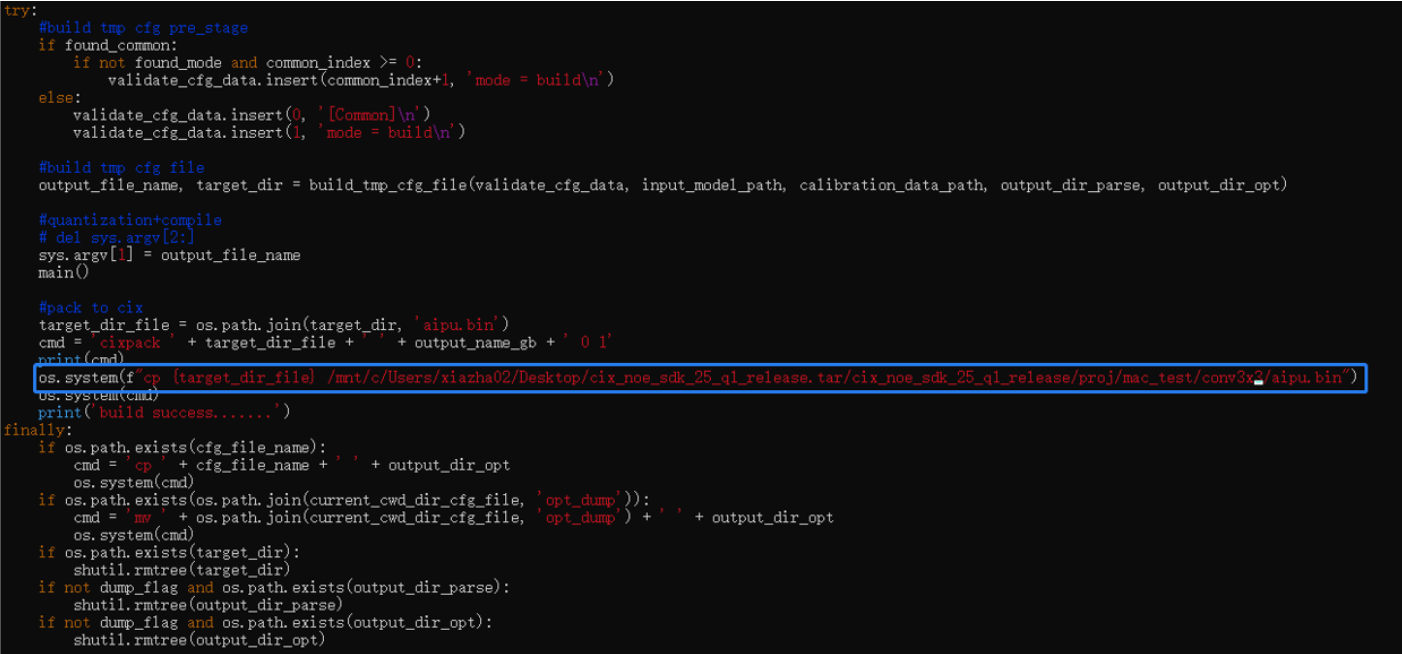
然后放到板子上生成profiler 数据:
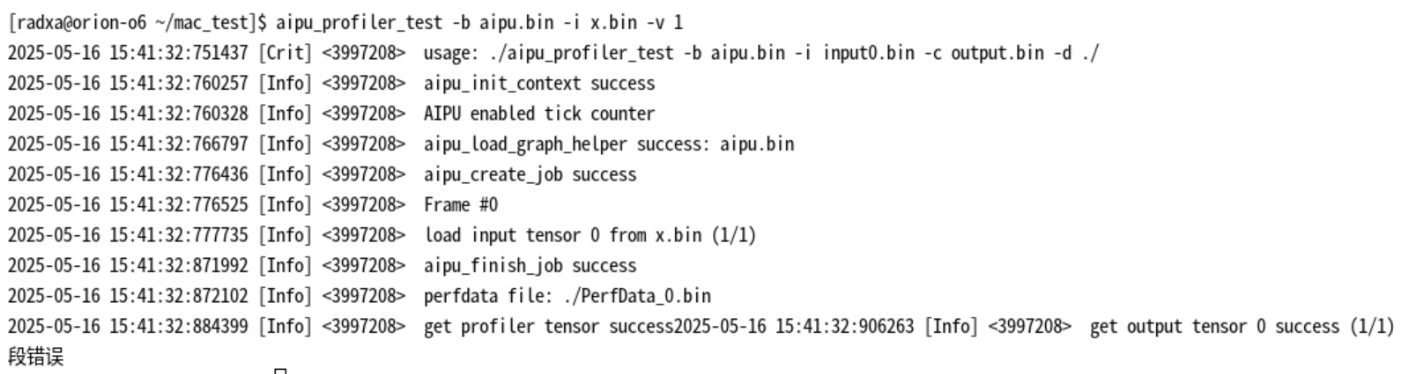
放回本地电脑生成报告,报告总览如下:
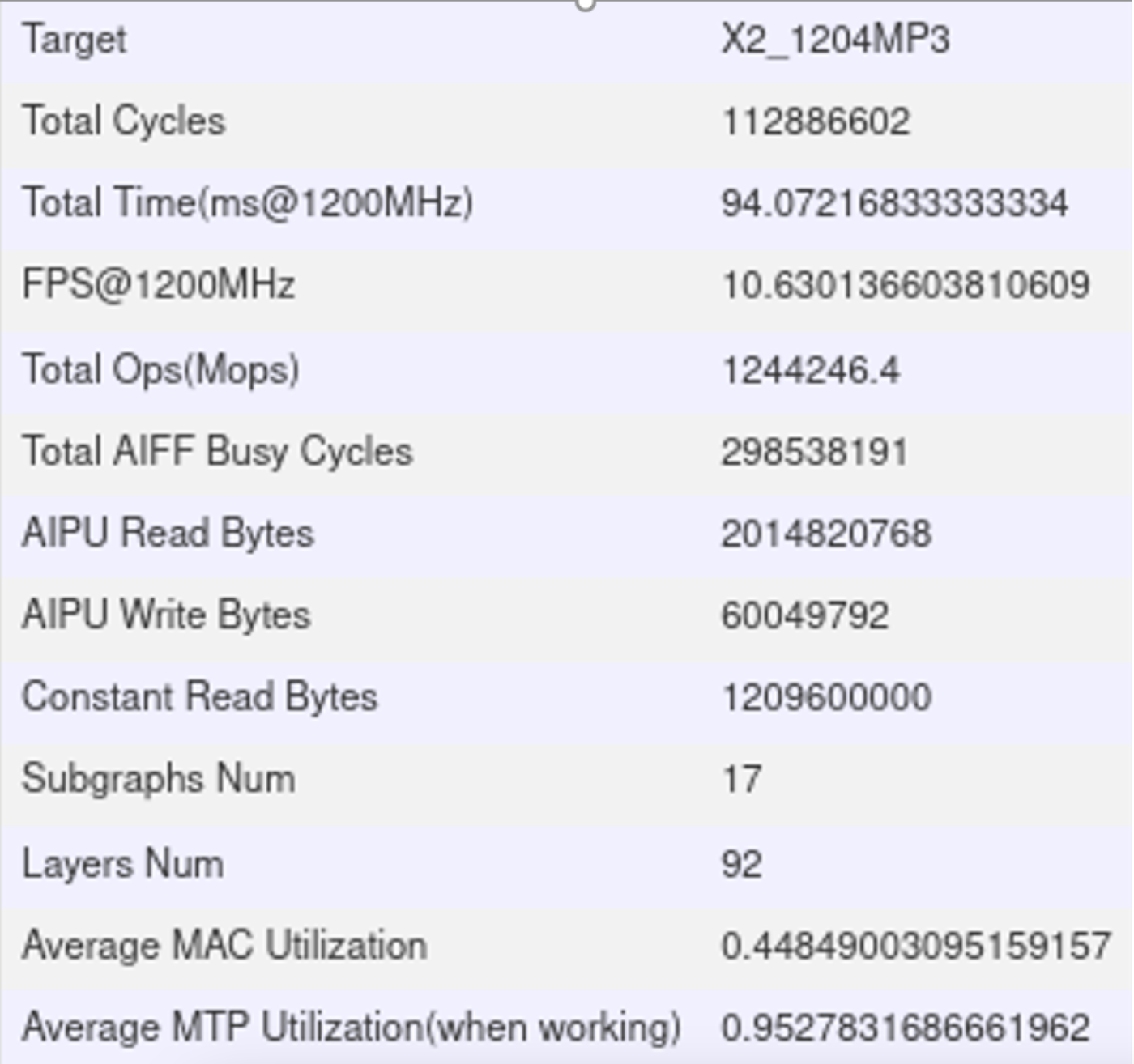
可以看到总耗时是94.072ms,与python推理耗时是94.531ms一致,得到的整网平均算力是:12.186TOPS
我们依次看下之前的几个问题:
######2.3.1 Transpose耗时总共3ms,对整网算力的计算影响不是很大;
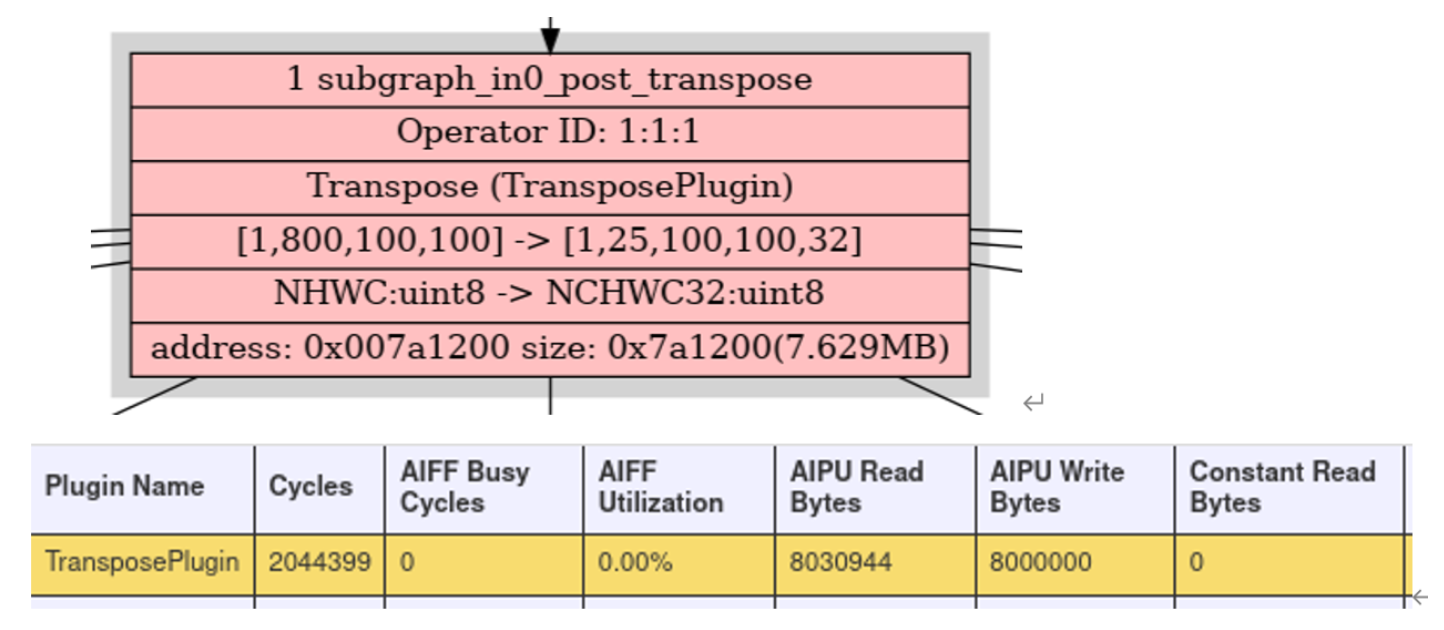
我们假设数据是一直在读,同时也一直在写,pipeline起来了,那么整个op的平均读带宽是: 7.629MB / (2044399/1.2)ns = 4.48 GB/s,假设三核均衡抢占带宽,那么总的NPU带宽就是3*4.48GB/s=13.44GB/s,说明两个问题,要么axi总线带宽soc分给npu的不足,要么就是。。。
######2.3.2 我们看到mac利用率有40%跟74%左右的,40%的是因为crop融合了
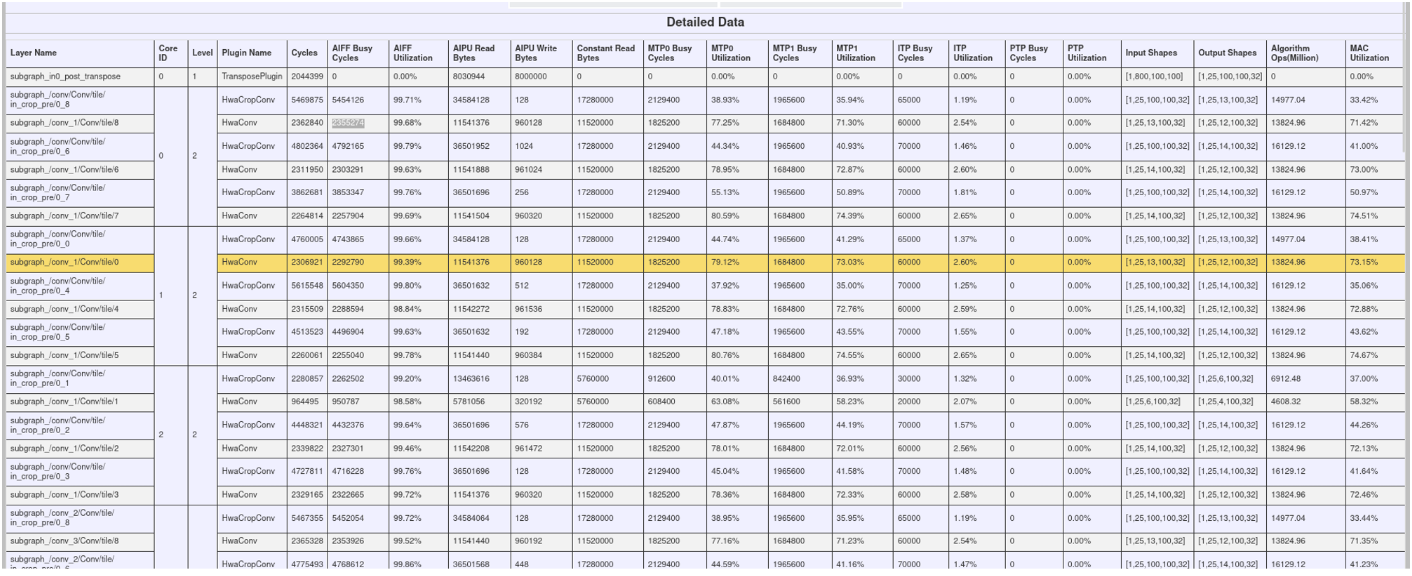
为了看下能达到的上限我们单看mac利用率达到74%的conv算子,

该算子总共需要的计算量为:12*100*800 * 3*3*800 *2 = 13.824*10^9 OPS
消耗的时间为:2255952 cycles / 1.2 GHz = 1.88*10^-3 second
因此实际跑出来的最高算力为:7.35TOPS,注意这是单核的性能。
三核心的话(不考虑多核均衡、多核竞争),极限最好能达到7.35TOPS*3=22.05TOPS,已经很接近理论算力了。
PS. 标称28.8TOPS算力是这么来的,主频1.2GHz,三核算力,换算下来每个核心8TOPS/1GHz, 支持的算力大小是8Kops per cycle,由此我们可以推断出一些信息(根据《AI处理器硬件架构设计》),这里我们不推算。
注意看这里的带宽利用率也是不足的,可以推知之所以没跑满算力,大概率是带宽受限了,具体NPU的带宽上限能达到多少呢?
其实我们是可以设计实验来推测的,适当设计网络模型使得axi总线上NPU prefetch的合适,outstanding数量足够,就有可能打满ddr latency,从而实现满带宽,这个留到下一篇文章再做。
越写越多,写不完了,打住打住,三核均衡,抢带宽,计算overlap,切分策略等问题我们后面有机会再说。
小结: 实测来看,算力达成率在算子层面能达到74%,但是整网情况下受到硬件架构、模型特点、系统带宽、编译参数等因素的影响,仅能达到41.6%;