前言
面向长时间跨度的机器人操作任务,强化学习仍然面临巨大挑战,其根源在于稀疏奖励只能为信用分配提供有限指引
因此,实际中的策略提升往往依赖更丰富的中间监督信号,例如密集的进度奖励,但这类信号获取成本高昂,并且并不适用于诸如回溯与恢复等非单调行为
- 为此,来自1 LimX Dynamics、2 Beijing University of Posts and Telecommunications、3 Zhejiang University的研究者提出优势奖励建模(Advantage Reward Modeling,ARM)框架,将建模难度较大的绝对进度估计,转化为对相对优势的估计
- 即作者引入了一种具有成本效益的三状态标注策略------"前进(Progressive)""后退(Regressive)"与"停滞(Stagnant)"------在降低人类标注认知负担的同时,保证了跨标注者的一致性
通过利用这些直观信号进行训练,ARM 可以为完整示范数据以及分段的 DAgger 式数据自动生成进度标注
将 ARM 集成到离线 RL 流水线中后,可实现对动作-奖励的自适应重加权,有效过滤次优样本。作者的方法在一个具有挑战性的长时间跨度毛巾折叠任务上达到了99.4% 的成功率
第一部分
1.1 引言与相关工作
1.1.1 引言
如原论文所言,目前大多数现有的 VLA 方法严重依赖模仿学习(Imitation Learning, IL)*26-An algorithmic perspective on imitation learning*
- 从而要想落地效果好,不得不要求海量数据集,并在大规模数据采集过程中带来可观的人力和物理资源成本
3-Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems
10- Robomind 2.0: A multimodal, bimanual mobile manipulation dataset for generalizable embodied intelligence
14-Droid: A large-scale in-the-wild robot manipulation dataset
27-OpenX
35- Algorithms for inverse reinforcement learning
36-Robomind: Benchmark on multiembodiment intelligence normative data for robot manipulation - 且除了数据量之外,人类示范中固有的次优性和噪声------尤其在复杂、长时间跨度任务中,往往会阻碍策略的收敛
强化学习*33-Reinforcement learning: An introduction* 通过使策略能够在专家示范之外实现自主改进,提供了一种有前景的替代方案 *12-π∗0.6: A VLA that learns from experience,18-Gr-rl: Going dexterous and precise for long-horizon robotic manipulation*
- 然而,要在长时序操作任务中实现高效的强化学习,关键在于具有足够信息量的奖励信号。尽管稀疏奖励(例如二值成功指示)在定义上相对简单,但它们往往难以提供有效的学习信号,在长时序操作任务中经常导致收敛困难
- 因此,高质量的稠密奖励或具有丰富信息的价值函数至关重要,以便提供连续的监督信号并促进有效的信用分配
现有框架 *6-Sarm: Stage-aware reward modeling for long horizon robot manipulation,12-π∗0.6* 试图通过优势估计或样本重加权来利用稠密信号
然而,它们依赖于高精度的过程奖励模型来缓解众所周知的"信用分配"问题。这种依赖构成了普遍存在的"奖励工程瓶颈",限制了 VLA 在非结构化环境中的可扩展性和稳定性
设计一种具备成本效益、同时能提供稳定且高频反馈的奖励函数,仍然是一项极具挑战性的任务
尤其是,现有基于绝对进度的评估范式受到多个关键瓶颈的限制
6-SARM
12-π*0.6
19- Robometer: Scaling general-purpose robotic reward models via trajectory comparisons
23- Vision language models are in-context value learners
34- Robo-dopamine: General process reward modeling for high-precision robotic manipulation
37-Large reward models: Generalizable online robot reward generation with vision-language models
39- Rewind: Language-guided rewards teach robot policies without new demonstrations
首先,零样本 VLM 存在显著的不可靠性和高昂成本;它们不仅推理开销巨大,而且由于缺乏空间-几何基础而产生低精度标注,这会在奖励信号中表现为非单调的振荡 *6,23,32-Roboclip*
其次,当前方案在失败状态下存在量化歧义
由于将进度建模建立在严格单调性假设之上,并依赖简单的视频回放 6,34,39 来模拟退步,这些方法无法全面刻画真实存在的非线性操作错误此外,对粗粒度子任务划分的传统依赖 6,34 无法捕捉到长时任务------例如关键的恢复和纠正机动11- Rac: Robot learning for long-horizon tasks by scaling recovery and correction------最终会产生失配的奖励信号以及不稳定的策略更新
为了解决这些挑战,来自1 LimX Dynamics、2 Beijing University of Posts and Telecommunications、3 Zhejiang University的研究者提出了 Advantage Reward Modeling(ARM,优势奖励建模)

作者的核心洞见在于:要定义绝对进度,往往需要依赖临时设计的、针对具体任务的启发式规则,而这类规则难以扩展
相比之下,不同状态之间的相对优势为标注提供了一种更加直观、简洁且与任务无关的基础表示
尽管最新工作 VLAC 38 也采用了区间增益预测,其方法论是建立在"任务进度与时间正相关"这一假设之上,但通过将进度奖励与全局时间锚点解耦,ARM 自然地容纳了回退行为和错误恢复
具体而言,作者的核心贡献如下
- 三态优势标注策略
作者提出了一种基于三种基本类别------"前进(Progressive)"、"后退(Regressive)"和"停滞(Stagnant)"------的标注方法
该方案与具体任务无关(task-agnostic)、认知负担低,并且天然兼容异构且碎片化的数据集 - 优势奖励模型(Advantage Reward Model, ARM)
作者构建了一个多模态奖励模型,将时间序列视频与机器人本体感知状态相结合,用于评估轨迹片段的相对进展收益
通过使用任务完成头作为锚点,ARM 能够从离散的三态标签中自动重建出全局一致的密集进度轨迹 -
Advantage-Weighted Behavior Cloning (AW-BC)
通过利用预测的区间增益进行具备优势感知的重加权,AW-BC 能够有效过滤次优样本,并优先保留高价值的恢复轨迹
作者在 Reward-Aligned Behavior Cloning(RA-BC) 范式 *6-Sarm* 的基础上进行扩展
通过引入自适应缩放系数以确保与碎片化的 DAgger 数据*31-A reduction of imitation learning and structured prediction to no-regret online learning* 兼容
1.1.2 相关工作
首先,对于操纵奖励
传统RL在很大程度上依赖人工奖励塑形,这往往既耗费人力又高度依赖具体任务
-
为缓解这一问题
逆向强化学习IRL*25-Algorithms for inverse reinforcement learning*
和
基于人类反馈的强化学习RLHF*8-Deep reinforcement learning from human preferences*
通过推断奖励函数来实现学习但前者存在可辨识性问题
后者则面临可扩展性问题 -
诸如
VIP *21-Vip: Towards universal visual reward and representation via value-implicit pre-training*
和
LIV *22-Liv: Language-image representations and rewards for robotic control*之类的视觉-语言模型(VLMs)能够提供自监督的目标距离信号,但在精细、富接触的操作任务中却缺乏所需的精度
正如 SARM6 中所指出的,单目标的距离度量无法捕捉长期任务中的中间进展GVL 23、ReWiND 39、SARM6 和 VIP 21 等方法的一个共同局限在于,它们依赖严格的单调性假设,即将任务进度与时间顺序直接等同起来
然而,现实世界中的离线演示往往包含错误、重试以及阶段性的倒退,这会在基于时间启发式的方法下导致奖励错设
------------
说白了,同样1min内,一台机器在进行无效的折腾 即便折腾了1min才崩溃 但任务进展实际只为20%,但不如另一台机器:"进行有效折腾到45s便崩溃 可把任务进展实际推到了50%" -
其他替代方法也存在权衡:例如 Robo-Dopamine 34 这类基于"跳跃"的机制会牺牲对动作的细粒度刻画,而零样本的 VLM 提示方法
5- ELEMENTAL: Interactive learning from demonstrations and vision-language models for reward design in robotics
7-Topreward: Token probabilities as hidden zero-shot rewards for robotics
17-Roboreward: Generalpurpose vision-language reward models for robotics则受到预测噪声、高延迟和推理成本的影响
为了解决这些问题,作者提出了 Advantage Reward Model(ARM),它通过相对于历史视觉和本体感受状态来评估相对进度,从而放宽了时间单调性的限制,即便在轨迹出现短暂偏离的情况下,也能够实现有效的优势估计
其次,对于回报对齐行为克隆(RA-BC)
从次优示范中学习是大规模机器人学习中的关键瓶颈。为了解决这一问题,重加权行为克隆(BehaviorCloning, BC)的范式被广泛研究
源自经典基线方法,如
- 优势加权回归(Advantage-WeightedRegression, AWR)28
- 优势加权 Actor-Critic(Advantage-Weighted Actor-Critic, AWAC)24
- 隐式 Q 学习(Implicit Q-Learning, IQL)16
这些方法通过施加基于优势函数的标量权重来压制次优轨迹,从而提取更优的策略
- 然而,传统的加权范式受到一个关键瓶颈的限制:它们在本质上依赖显式的环境回报来拟合全局价值函数,而在基于视觉的真实世界场景中,这类回报往往极难获取
- 为绕过这一问题,近期方法如SARM 6 引入了 Reward-Aligned BehaviorCloning(RA-BC,回报对齐行为克隆)框架,利用阶段感知的回报模型来替代环境回报
尽管这在缓解数据质量问题方面行之有效,SARM 却用新的约束替代了回报瓶颈:它极大地依赖成本高昂的人工语言标注
相比之下,作者提出的 ARM 则通过纯粹基于相对进展的比较来提取优势信号,从而消除了对显式回报工程的需求
1.2 ARM的优势奖励建模
如图1所示,所提出的框架将范式从"绝对进度建模"转变为"相对优势估计"。该系统由三个协同工作的组件构成:
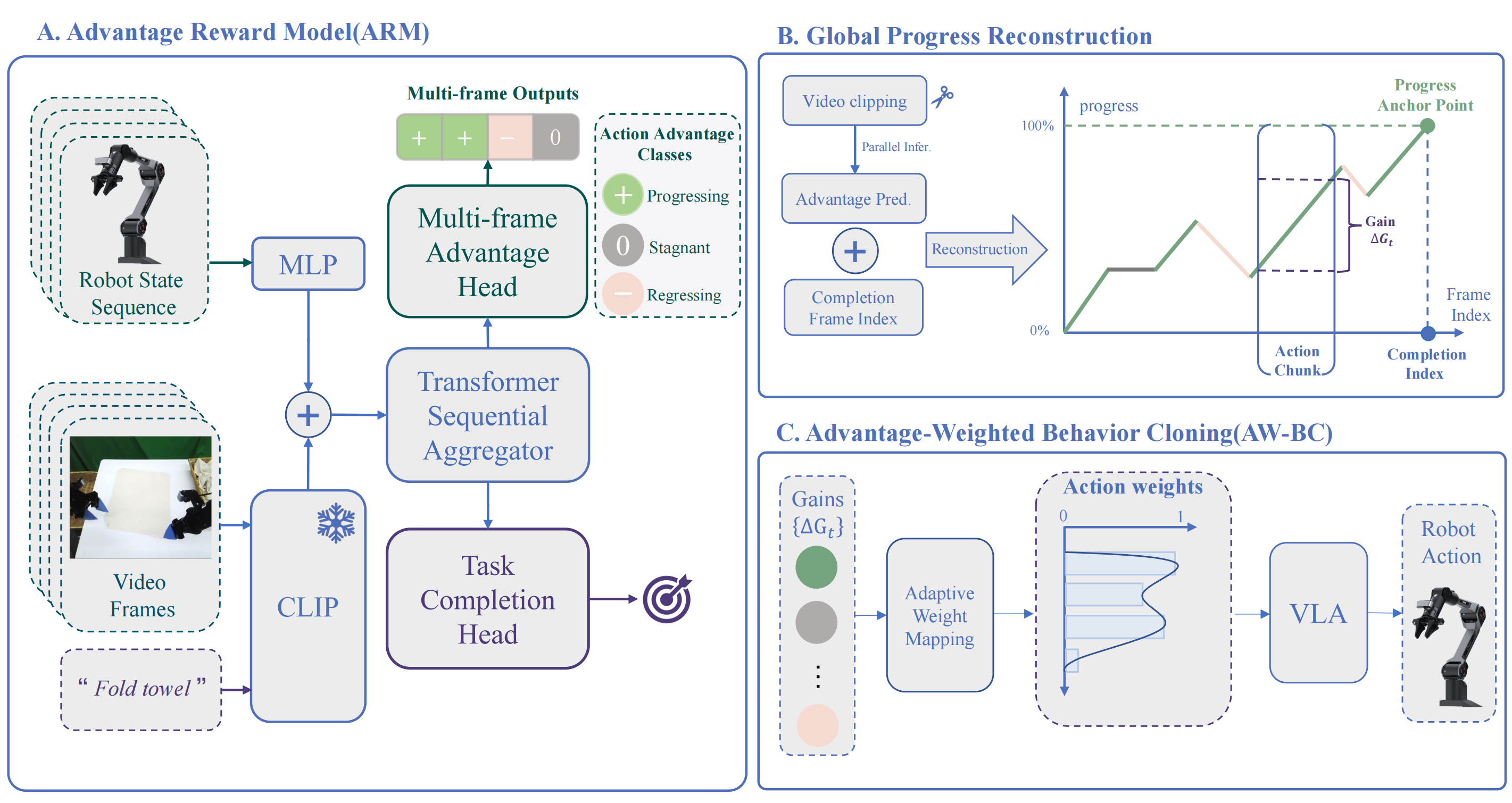
-
A) 优势奖励模型
一种多输入多输出(MIMO)的时序Transformer,旨在从多模态观测中捕获细粒度的相对优势(见图1A)该模型由一种轻量级的三态标注方案进行监督,该方案将状态转换分类为:进步progressive、退步regressive*,或停滞stagnant三类,提供了一种经济高效且与任务无关的训练信号*
-
B) 全局进度重建
一条自动化流水线,用于将 ARM 预测的离散区间增益综合为连贯且在全局上一致的奖励轨迹(图 1B)
该过程有效地将局部相对预测转化为稠密且高保真度的进度信号,从而适用于后续的下游学习 -
C) 通过 AW-BC 进行策略优化
AW-BC 框架将重构后的奖励整合进来,用于判别式的样本重加权(图 1C)
通过利用对轨迹长度自适应的增益来优先强化高价值的恢复行为并滤除次优片段,AW-BC 在嘈杂且异质的数据集上促成了类似离线强化学习的稳定策略精炼
1.2.1 MIMO Transformer 架构
作者采用SARM 6 中的Transformer Sequential Ag-gregator 作为他们的骨干网络,对其进行重新设计以支持多帧因果推理和相对优势估计
ARM 在一个因果窗口内并行处理一系列历史观测。通过将感受野限制在过去帧,这种基于窗口的方法确保预测在提供足够运动线索的同时,还能保持实时推理能力
关键在于,这种因果公式化设计确保了与在线和离线强化学习范式的无缝兼容,因为它能够即时生成奖励,而无需依赖未来的轨迹片段
首先,对于多模态融合
对于每个时间步,ARM 融合三种不同的信号:
- 基于CLIP 30 的视觉特征
- 机器人本体感受状态
- 任务指令
这些输入被投影到一个统一的 维潜在空间中,以形成融合的多模态嵌入
,定义为
得到的序列随后由一个8 层的Transformer编码器进行处理,以产生时间上增强的潜在表示
其中每个 编码了该任务在该特定时刻的历史演化和运动学状态
其次,对于双头学习目标
为了平衡对本地状态转换的敏感度与对全局任务目标的认知,ARM 通过两个协同作用的输出头进行了优化
- 多帧优势分类
interval head 推断相邻隐藏状态之间的优势变化
该分支通过标准交叉熵损失进行优化,记为
通过将奖励估计从连续回归重新表述为离散分类任务,模型在应对示范中固有的非线性噪声和时间随机性方面表现出显著增强的鲁棒性 - 任务完成预测
为了将相对优势估计锚定到绝对的任务度量上,完成头
这种解耦式设计不仅有助于识别任务的成功执行,还能从预测中提取进度锚点。当与多帧优势分类结果联合使用时,这些锚点能够实现高度一致且稠密的进度重建
此外,由于在长时域的连续轨迹中,成功的终止帧极为罕见,该分支面临严重的类别不平衡问题。为有效解决这一问题,作者使用Focal Loss 20 来优化 completion head:
总目标被定义为。这种联合训练使模型不仅能够恢复连续的进度曲线,还能准确识别倒退行为和关键任务完成时刻
1.2.2 轻量级三态自动标注策略
传统的机器人操作奖励工程通常需要标注者为每一帧视频分配一个归一化标量值。这一连续标注过程对认知负担要求很高,并且容易出现标注者之间的不一致,因为" 进展" 的定义往往是主观的
此类监督信号中的噪声经常导致策略收敛次优,以及大量的工程开销
为了解决这些问题,作者将标注任务重新定义为相对优势的三状态类别分类
如图3 所示

对于任意观测对(st, st+k),作者根据以下规则定义一个基于进度的优势标签y ∈{−1, 0, +1}:
- +1(进展中):该状态有效地朝任务目标推进
- -1(退步中):该状态偏离目标、遇到错误或导致失败
- 0(停滞):没有取得实质性进展,对应于等待或空闲行为
通过在这种简化范式下获取初始的人类标注,作者可以高效地对模型进行冷启动。随后,利用已训练好的模型对大量未标注的轨迹进行推理,自动生成大规模的伪标注数据,以用于后续训练
1.3 全局进度重建
如图 1B 所示
借助 MIMO 架构,ARM 能够将完整的视频演示分解开来,并系统地聚合所得预测结果,从而重建出一个稠密的、覆盖完整序列的进度曲线:
- 并行推理效率:而传统方法与在重叠帧上存在冗余计算的滑动窗口方法不同,MIMO 架构在其上下文窗口内直接预测序列
通过利用视频剪辑,将冗长的情节轨迹划分为相互独立、非重叠的片段
这些片段可以在一次前向传播中,作为并行批次被并发处理,从而显著加速整体推理过程 - 序列对齐与填充:对于长度小于模型指定窗口大小的末端视频片段,采用尾帧复制填充策略
在对完整情节进行最终聚合时,对应这些人工填充区域的预测将被丢弃,以保持时间一致性 - 连贯进度生成:为了生成全局稠密进度曲线
具体来说,将
总之,该流程巧妙地将离散的、局部的相对预测转化为连贯且高密度的全局进度信号,从而为后续的策略学习提供一致且高质量的监督
// 待更
第二部分 SARM:面向长时间跨度机器人操作的阶段感知奖励建模
1.1 引言与相关工作
1.1.1 引言
如原论文所述,让机器人无缝协助人类完成家务这一由来已久的愿景,数十年来一直激励着机器人学领域的研究。从整理居住空间到准备餐食,这类能力有望解放人类时间、提升生活质量
- 近年来,机器人基础模型(foundation models for robotics),更广义地说机器人行为模型(Robot Behavior Models,RBMs)的发展,使人们对这一目标重新燃起乐观态度
- 通过在统一框架下融合视觉感知、运动控制以及(可选的)语言处理,RBMs
Chi et al.,2023
Zhao et al., 2023
Chen et al., 2025
Sun et al., 2024
Huang et al., 2024
Yu et al.,2024
Wang et al., 2023a
Black et al.
Team et al., 2024
Zitkovich et al., 2023
Shentuet al., 2024
Huang et al., 2025a;b
使机器人能够执行复杂任务,从而有可能在非结构化的家庭环境中完成这些任务
尽管展现出巨大前景,RBM 在处理长时域、富含接触的操作任务时仍然表现不佳,尤其是诸如 T 恤这类可变形物体。这类任务要求模型能够应对不断变化的几何形状、遮挡、布料差异,以及实现无误的多步规划------而在这些方面,现有模型(通常为短时域、刚体操作任务进行调优)明显力有不逮
-
它们难以泛化到精心整理数据之外的情形,随时间推移会丧失一致性,并且会误判中间状态。虽然以往许多 RBM 相关工作主要集中在扩充数据规模
Barreiros 等, 2025
Lin 等, 2024但对数据质量本身的关注却少得多
-
然而,高质量数据本身极难获取:专家示范代价高昂且耗时,而更大规模的数据集往往包含来自经验较少操作者的噪声轨迹或次优轨迹
更具挑战性的是,演示质量本身是一个难以量化的指标,因为它取决于诸如动作一致性、接触稳定性等无法直接测量的隐性因素,除了像任务持续时间这样简单的替代性经验法则之外尽管已经存在更为复杂的数据建模方法,可以在策略训练之后用于评估数据质量并筛选轨迹Belkhale 等,2023
Dass 等,2025
Agia 等,2025
但在实际中评估示范质量仍然具有相当大的挑战性
鉴于上述挑战,作者提出了一种基于视频的奖励建模框架 ,利用自然语言标注来分配任务进度标签,从而实现对多步任务的稳定奖励估计。所学习到的奖励模型驱动一个"***奖励对齐行为克隆"(Reward-Aligned Behavior Cloning,RA-BC)***框架,用于筛选更高质量的数据,并在仿真和真实环境中提升策略性能
如下图所示,包括 (a) 数据处理,(b) 奖励模型训练,以及 (c) 使用奖励信号进行策略训练
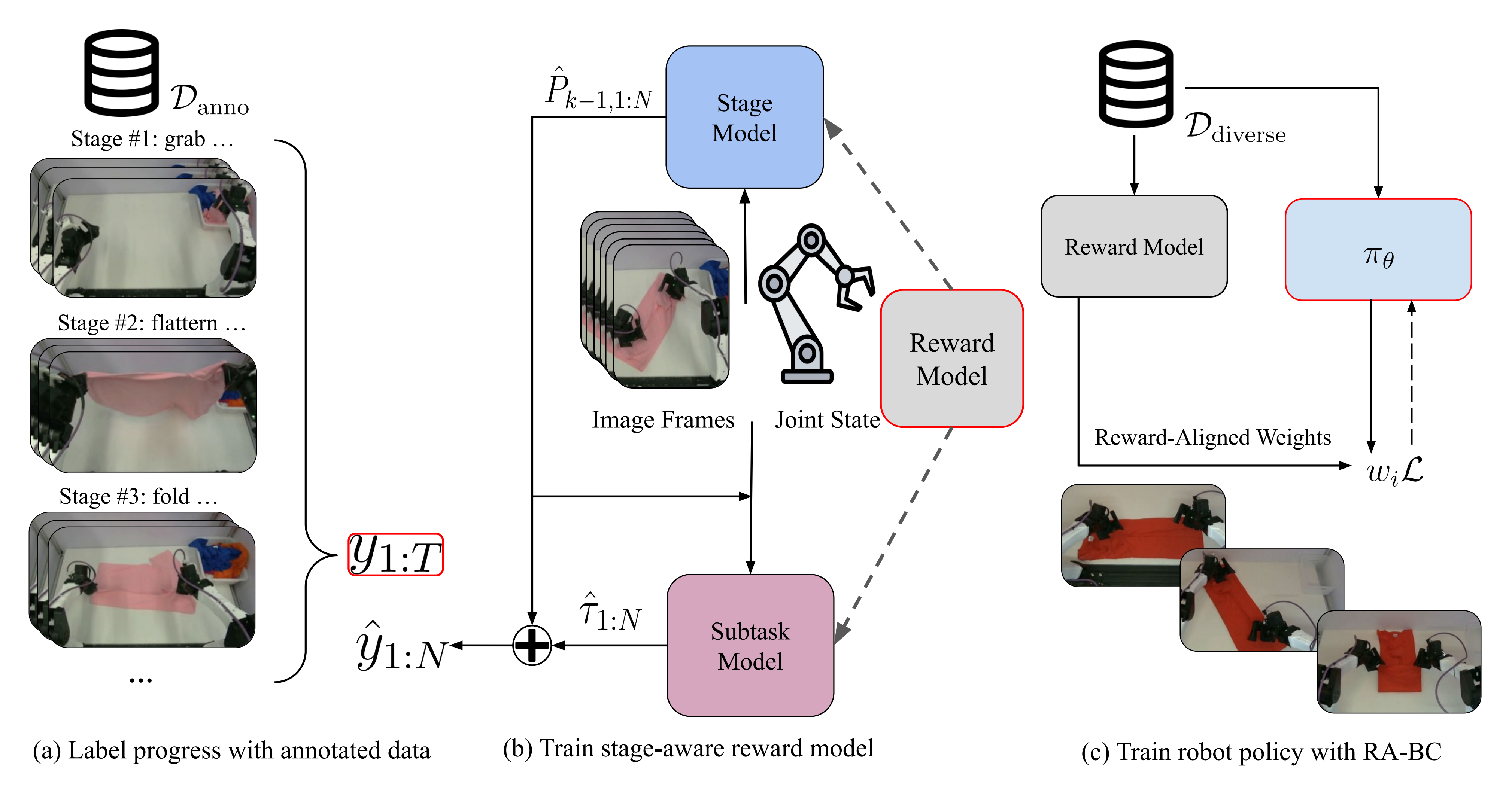
以折叠 T 恤任务为重点,作者宣称,他们的实验表明,将奖励模型与 RA-BC 结合能够显著提升表现,凸显了数据质量在长时序操作任务中的重要性
1.1.2 相关工作
首先,对于用于机器人技术的学习型奖励模型
第一,以往关于学习奖励函数的工作包括逆强化学习
- Ng 等,2000
- Abbeel 和 Ng,2004
- Ramachandran和 Amir,2007
- Ziebart 等,2008
- Finn 等,2016
该方法从示范中推断奖励,但会受到奖励不可识别性以及对部分可观测性的敏感性影响,从而阻碍其在高维、长时间跨度问题上的可扩展性
第二,从人类反馈中学习(例如,偏好排序、量化偏好、干预)已被证明在训练大语言模型(LLM)方面非常有效(Christiano 等,2017;Ziegler 等,2019)
- 近年来,RLHF 在机器人领域也越来越受到关注,但仍然需要大量针对具体任务的输入,并且受到标注者不一致性的影响(Sadigh 等,2017;Liu 等,2023)
- 另一种互补的方向是利用大语言模型(LLM)合成奖励函数或塑形代码(Ma et al., 2024a;Shentu et al., 2024),这可以加速初始训练过程,但往往假设具有特权或结构化的状态信息,而这类信息在仿真环境之外很少可用,并且在传感器噪声和领域偏移下性能会退化
第三,先前的一些研究(Lee 等, 2021;Ma 等, 2022;Escontrela 等, 2023)通过计算当前状态与目标状态的特征距离来估计奖励,从而无需人工标注即可进行自监督的奖励模型训练
- 虽然这一方法在具有单一目标的简单任务上效果良好,但在长时序场景中却表现不佳,此类任务通常会自然分解为多个子任务或阶段
在这种情况下,单一的目标距离无法刻画中间过程中的阶段性进展,往往导致奖励信号变得缺乏信息量甚至具有误导性 -
另一条研究路线是使用视觉-语言模型(VLM),直接从视觉观测与任务文本的组合中计算奖励
在实际应用中,许多基于 VLM 的奖励模型在长时程、高动态性以及高度接触密集的操作任务上表现欠佳,因为它们需要从初始帧开始处理完整轨迹以捕捉时间依赖关系,这大幅增加了数据与计算需求,从而阻碍了模型的扩展性
在这些工作中
LIV(Ma et al., 2023)
VLC(Alakuijala et al., 2024)
GVL(Ma et al., 2024b)
VICtoR(Hung et al., 2024)
REDS(Kim et al., 2025)
ReWiND(Zhang et al., 2025)
以及SARM
都是直接基于视觉感知为机器人操作任务提供奖励
第四,已有一些先前工作,如 DrS(Mu 等,2024)和 REDS(Kim 等,2025),在长时序任务中采用具备阶段感知(stage-aware)的奖励模型
- 然而,DrS 在本质上不同于基于视觉的 SARM:它是纯粹基于状态的,依赖完整的模拟器状态作为阶段指示信号,并且需要为每个阶段单独训练一个判别器,因此难以扩展
- REDS 也与 SARM 不同:它不是对连续的逐帧进度曲线建模,而是学习一种带有单调性正则的半稀疏阶梯型奖励,这在不同轨迹具有不同推进速度时难以实现良好的泛化
此外,REDS 通过图像--子任务嵌入相似度来推断阶段,而不是使用专门的阶段估计网络,当子任务描述在语义上相似时,这种方式会变得不可靠
其次,对于次优示范下的模仿学习
已有研究在次优数据集条件下探索了模仿学习
- 一类方向采用自举式(boot-strapped)框架(Sasaki & Yamashina, 2020; Belkhale et al., 2023; Dass et al., 2025;Agia et al., 2025),在训练过程中基于对当前策略梯度、rollout 或学习目标的分析,主动改变数据集分布。尽管这类方法行之有效,但其计算开销巨大,并且需要大量的超参数调优
- 另一类研究则侧重于对示范进行显式标注和分类(Wu et al., 2019; Wanget al., 2023b),然而这种方法依赖于一个小规模的高质量数据集作为先验知识
另一种研究方向是通过离线强化学习(RL)技术对加权 BC 进行研究(Wang et al.,2018; Chen et al., 2020; Siegel et al., 2020; Xu et al., 2022),其中利用对优势函数的估计来对数据集中动作进行优先级排序
- 然而,这些方法通常假设可以获得完整状态反馈以及一个训练良好的评论家(critic),并且尚未在真实世界、基于视觉的、长时间跨度的操作任务上得到验证
- 相比之下,作者认为,他们的 RA-BC 框架利用一个预训练的、基于视觉的奖励模型来生成鲁棒且精确的 K 步优势估计,并以此指导加权 BC 的训练
1.2 SARM的完整方法论
1.2.1 奖励模型训练
首先,对于数据处理
如何提取密集的奖励标签仍然是一个挑战,尤其是在长时间跨度、复杂的任务中。以往的工作通常依赖于使用帧索引作为标签(Zhang 等,2025)
虽然对于诸如"拿起杯子"这类时长固定的短任务来说,这种做法可能已经足够,但在一些任务中则会失效,比如在"折叠 T 恤"这一类任务中,轨迹变化巨大、任务持续时间不固定、不同示范之间的动作序列也各不相同
- 以折叠 T 恤为例,在整理摊平的阶段,具体需要多少次动作取决于 T恤的初始放置位置或布料形态;然而,基于帧的标注只能反映已经过去的时间
- 结果是,相同的任务状态(例如,一件已经完全摊平的 T 恤)可能会被赋予从 0.2 到 0.8 不等的进度值,从而引入严重的标签噪声,进而损害奖励模型的学习效果以及后续策略训练
为了解决这一问题,作者利用了机器人轨迹数据上的子任务标注。收集到的轨迹由三个视频流(俯视、左手腕和右手腕)、关节状态和关节动作组成
在标注之前,作者通过将每个任务分解为语义上有意义的子任务来设计标注协议
对于T-shirt 折叠任务,作者开发了两套不同的协议:
- 一套用于稀疏标注
- 另一套用于密集标注,如表A.3 和图5 与图6 所示
- 在标注过程中,仅标注协议中定义的子任务,且任何不包含协议所规定的完整子任务序列的轨迹都会被丢弃
标注人员观看俯视视频,并通过记录起始和结束帧索引将每条轨迹划分为子任务- 如果在执行过程中出现严重错误(例如机械臂严重撞击桌面或执行完全相反的动作序列),也会标注其起始和结束帧;包含错误的轨迹会在后续的模型训练中被排除
最终,作者利用带标注的数据,计算了整个数据集中每个子任务在时间上的平均占比,从而自动为每个子任务的起始和结束帧分配进度值
且在每个子任务内部,作者通过在帧索引上进行线性插值来生成更细粒度的进度标签。该过程既保证了进度标签与动作的语义含义保持高度一致,又在整个数据集范围内维持了标注的一致性
接下来
-
通过子任务先验进行标注:令一条轨迹i 的总长度为Ti,并被划分为K 个子任务,其长度为
其中 -
逐帧进度目标:对于位于子任务
作者指定归一化进度目标
使得
其次,对于模型架构
作者采用双重奖励模型架构,其由共享的骨干网络和两个任务特定的头部组成
- 阶段模型(stage model)预测当前的高层阶段
- 而子任务模型(subtaskmodel)则在阶段预测的条件下估计细粒度的进度
SARM 的整体架构如图 2 所示『左:SARM 总览,包含++阶段估计器和子任务估计器++。首先根据观测预测任务所处的阶段。该阶段预测结果还会被传递给子任务估计器,用于预测该阶段内当前进度的尺度值。右:估计器架构概览,该架构同时用于阶段估计器和子任务估计器,并在二者之间复用』
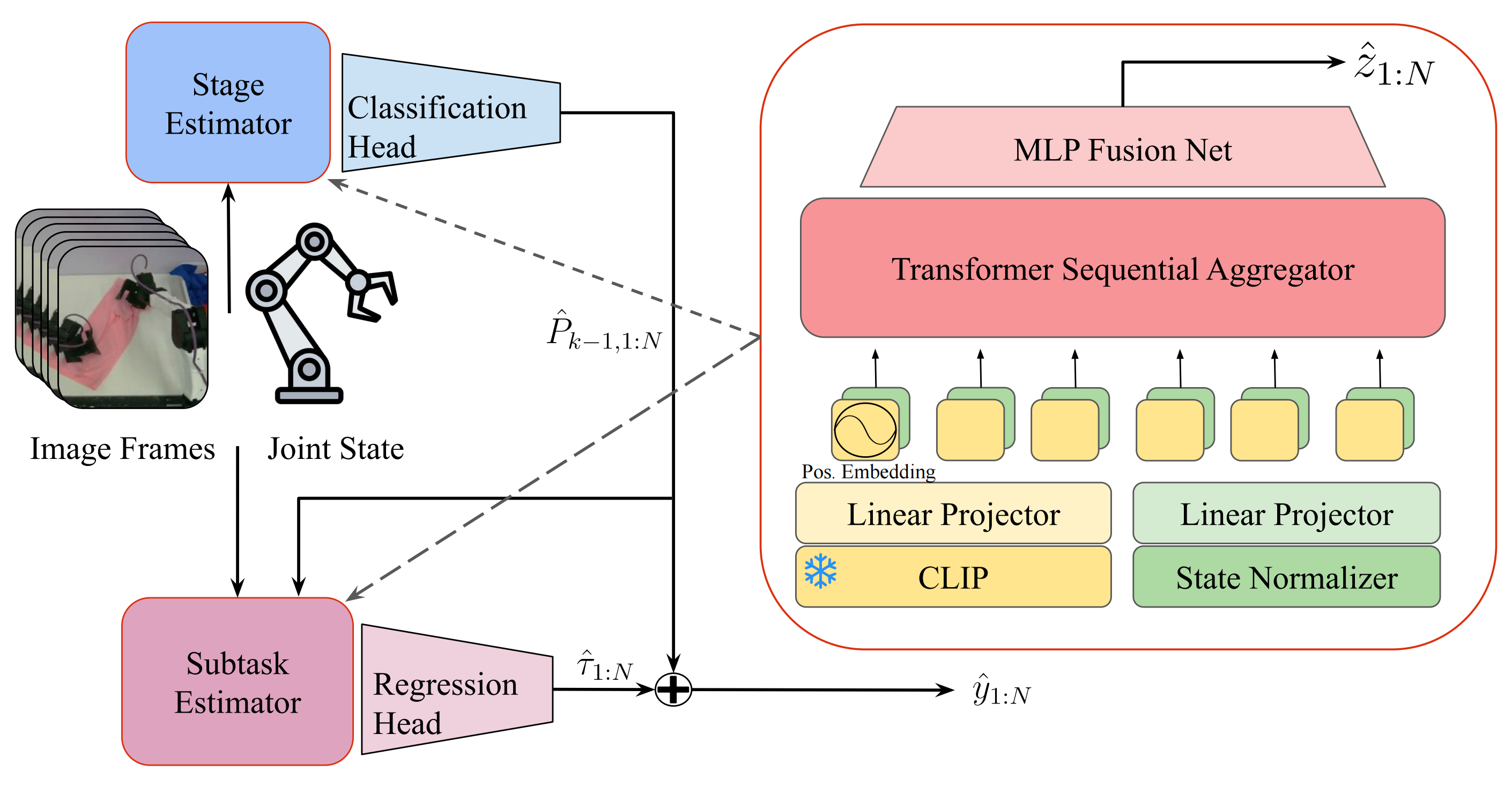
这两个模型按顺序工作:子任务模型使用预测出的阶段作为先验上下文,以细化最终的进度估计。阶段模型输出离散任务阶段上的概率分布,为机器人的进度提供粗粒度的定位;而子任务模型利用阶段嵌入(stage embedding)生成区间为0,1 的连续进度值
二者结合,既提供高层阶段分类,又实现细粒度进度估计,从而在长时序操作任务中实现稳定的奖励建模
输入管线的处理过程如下:
-
将一序列N 张图像输入冻结的CLIP 编码器进行编码,生成在两个模型之间共享的视觉嵌入
-
将视觉嵌入和关节状态投影到一个公共的
-
然后通过transformer 编码器处理该多模态序列,以捕获时间依赖和跨模态交互
-
一个轻量级的MLP 头部融合聚合后的特征,并输出
阶段
或
标量进度预测其中后者显式地以预测阶段为条件来细化进度估计
阶段概率通过
获得据此计算离散阶段预测和归一化进度为
1.2.2 奖励对齐行为克隆(RA-BC)
// 待更