1索引模版
添加索引
XML
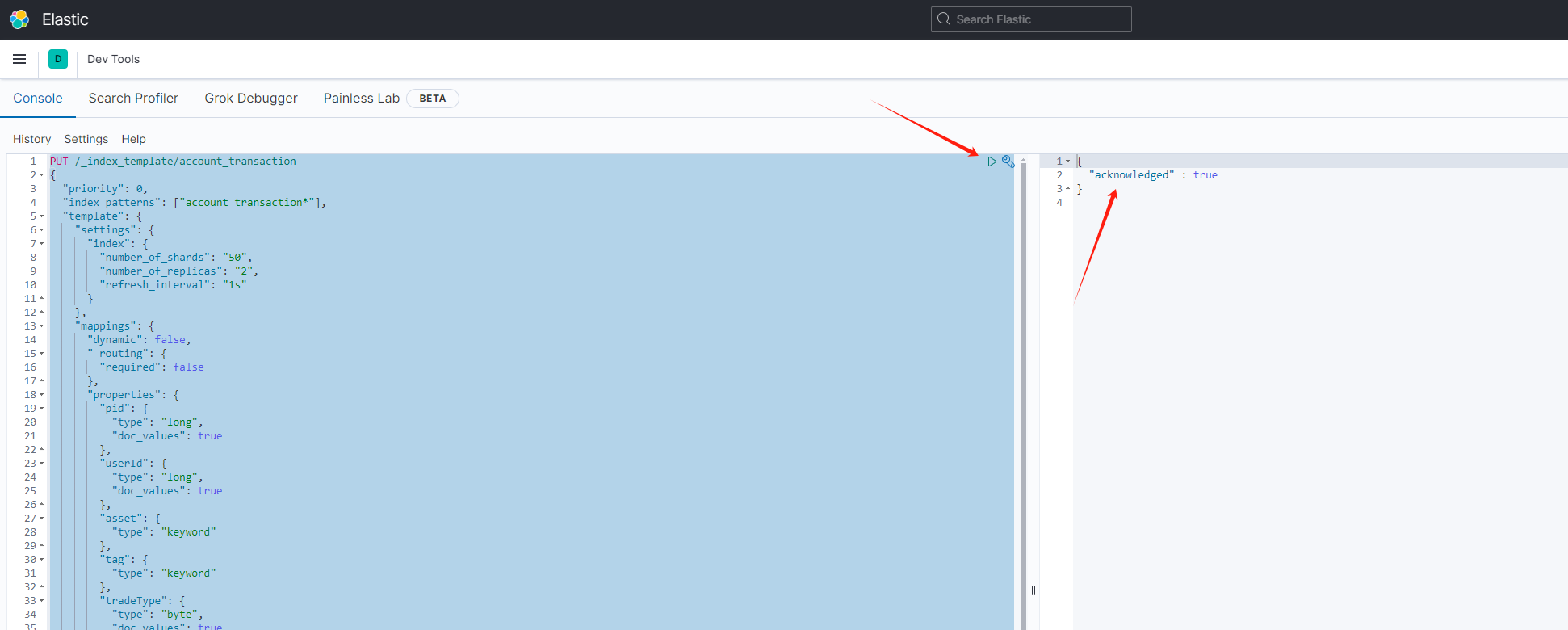
PUT /_index_template/account_transaction
{
"priority": 0,
"index_patterns": ["account_transaction*"],
"template": {
"settings": {
"index": {
"number_of_shards": "50",
"number_of_replicas": "2",
"refresh_interval": "1s"
}
},
"mappings": {
"dynamic": false,
"_routing": {
"required": false
},
"properties": {
"pid": {
"type": "long",
"doc_values": true
},
"userId": {
"type": "long",
"doc_values": true
},
"asset": {
"type": "keyword"
},
"tag": {
"type": "keyword"
},
"tradeType": {
"type": "byte",
"doc_values": true
},
"preBalance": {
"type": "long",
"doc_values": true
},
"balance": {
"type": "long",
"doc_values": true
},
"preLocked": {
"type": "long",
"doc_values": true
},
"locked": {
"type": "long",
"doc_values": true
},
"context": {
"type": "keyword"
},
"ctime": {
"type": "long",
"doc_values": true
},
"mtime": {
"type": "long",
"index": false
}
}
}
}
}操作结果
查看索引
XML
GET /_index_template/account_transaction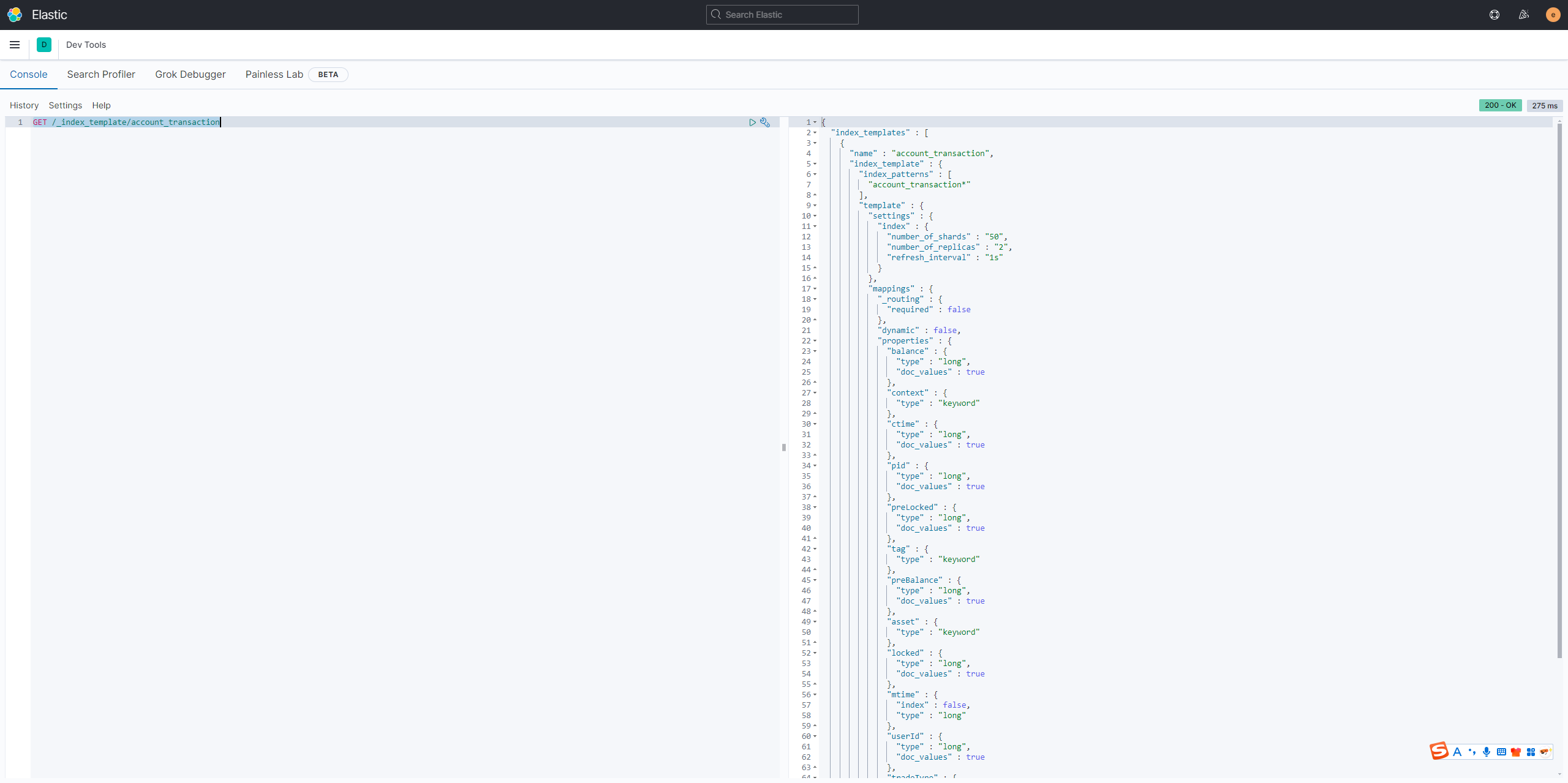
查看所有索引
XML
GET /_cat/indices?v2索引
创建索引
在有索引模版的情况下可以不需要创建操作,索引数据新增时会匹配是否存在对应的索引模版,例如我创建索引数据到account_transaction_001,
索引模版中的 "index_patterns": "account_transaction\*",会匹配上这个索引,索引会按索引模版进行创建,再把数据添加到新索引中
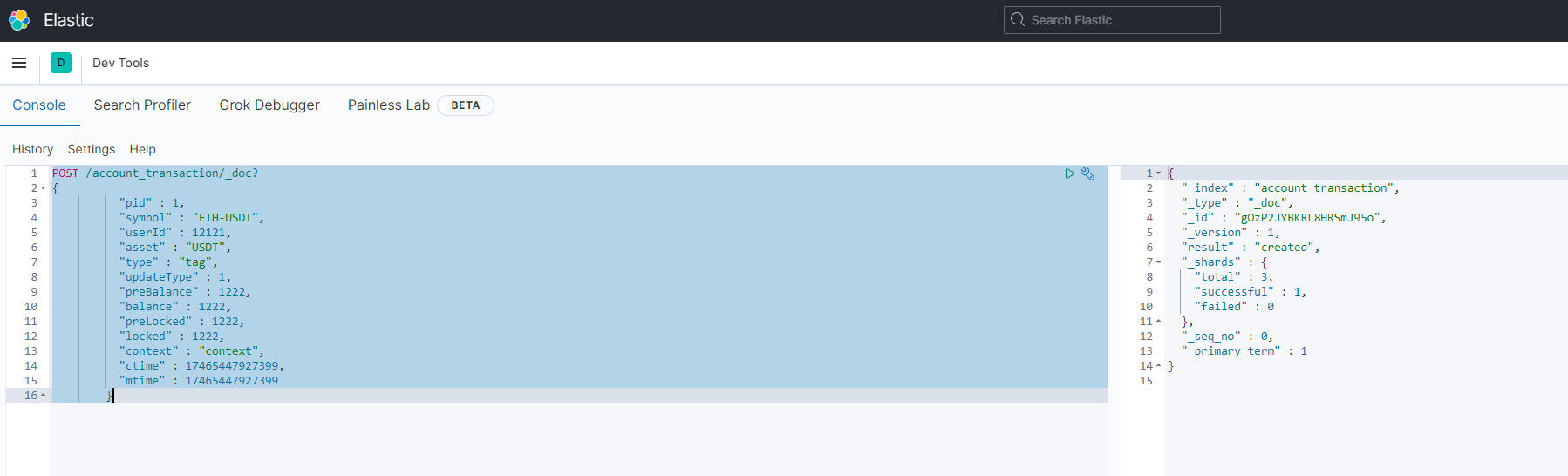
添加索引数据
XML
POST /account_transaction/_doc?
{
"pid" : 1,
"symbol" : "ETH-USDT",
"userId" : 12121,
"asset" : "USDT",
"type" : "tag",
"updateType" : 1,
"preBalance" : 1222,
"balance" : 1222,
"preLocked" : 1222,
"locked" : 1222,
"context" : "context",
"ctime" : 17465447927399,
"mtime" : 17465447927399
}
查询索引数据
XML
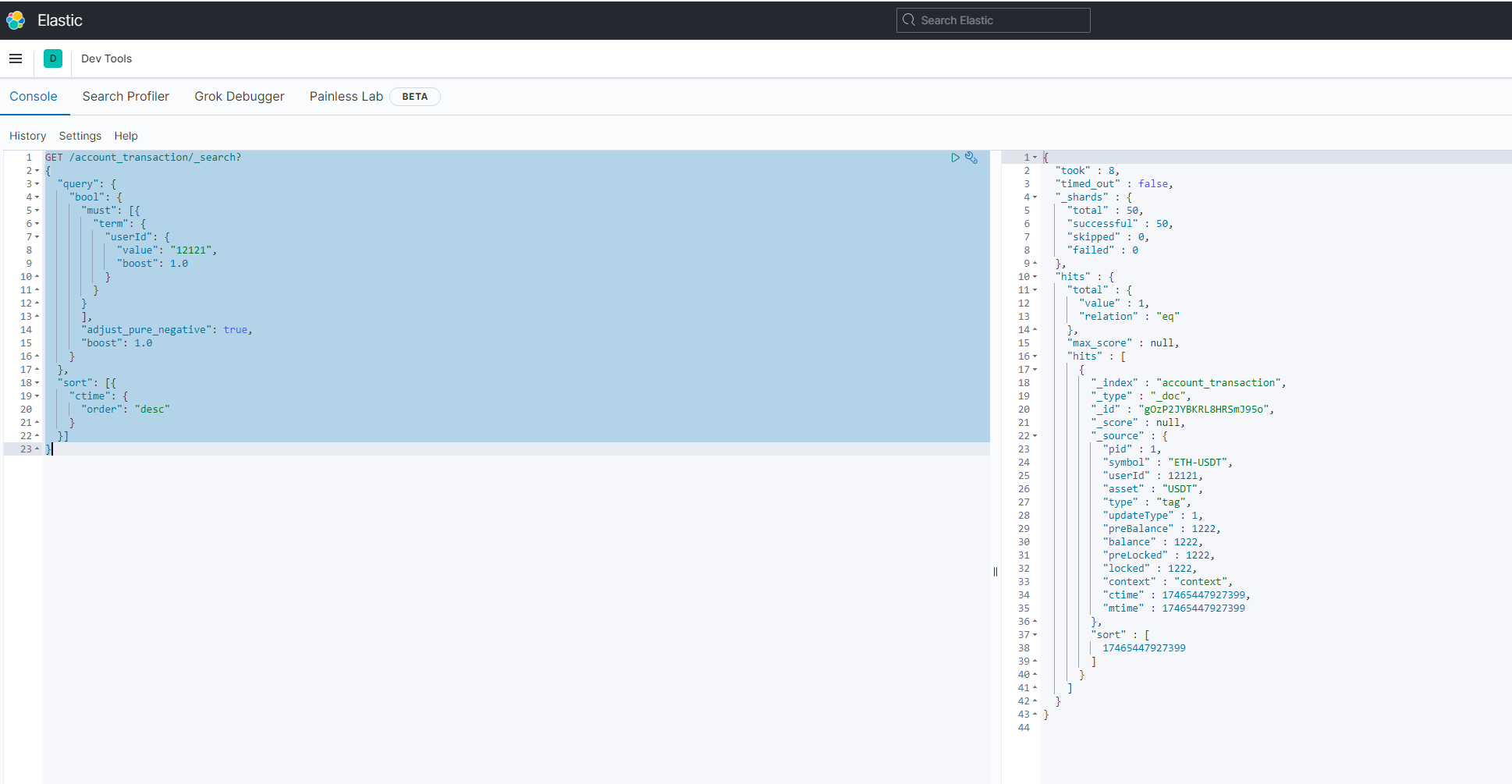
GET /account_transaction/_search?
{
"query": {
"bool": {
"must": [{
"term": {
"userId": {
"value": "12121",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"sort": [{
"ctime": {
"order": "desc"
}
}]
}