畅游Diffusion数字人(0):专栏文章导航
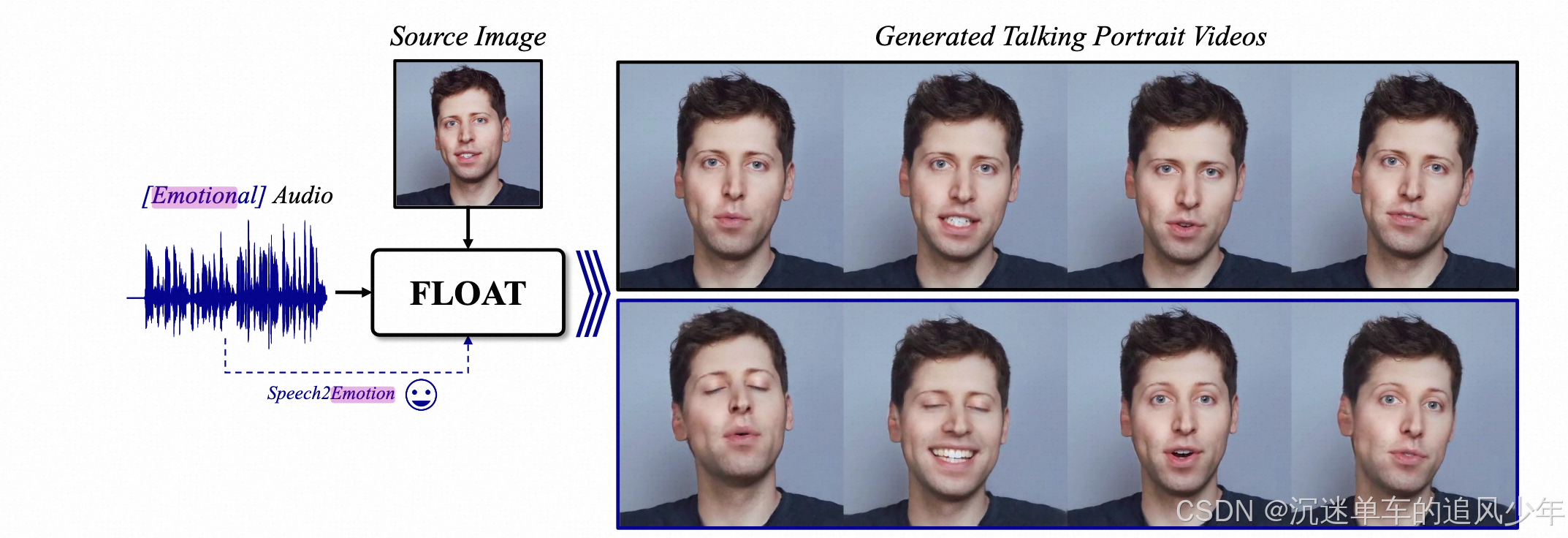
前言:仅从音频生成此类运动极具挑战性,因为它在音频和运动之间存在一对多的相关性。运动视频的情绪是多元化的选择,之前的工作很少考虑情绪化的数字人生成。今天解读一个最新的工作FLOAT,可以生成制定情绪化的数字人视频。
目录
贡献概述
一种基于流匹配生成模型的音频驱动的会说话肖像视频生成方法。我们将生成建模从基于像素的潜在空间转变为学习的运动潜在空间,从而能够高效设计时间一致的运动。为了实现这一目标,我们引入了一个基于 transformer 的向量场预测器,它具有简单而有效的帧级调节机制。此外,我们的方法支持语音驱动的情感增强,从而能够自然地结合富有表现力的动作。
动机
仅从音频生成此类运动极具挑战性,因为它在音频和运动之间存在一对多的相关性。在这个领域的早期阶段,许多工作专注于依靠学习到的音频-嘴唇对齐损失来产生准确的嘴唇运动。为了全面扩展运动的范围,一些工作结合了概率生成模型,例如 VAE 和归一化流,将运动生成转化为概率采样。但是,由于这些生成模型的能力有限,这些模型在生成的运动中仍然缺乏表现力。
EMO为该领域引入了一种很有前途的方法,它采用了强大的预训练图像扩散模型(即StableDiffusion)并将其提升到视频生成中。但是,它在生成时间相干视频和实现采样效率方面仍然存在挑战,几秒钟的视频需要几十分钟。此外,它们严重依赖辅助面部先验,如边界框 、2D 地标和骨骼 或 3D 网格,由于它们具有很强的空间偏差,这极大地限制了头部运动的多样性和保真度。
在本文中,我们提出了 FLOAT,这是一种基于流匹配生成模型的音频驱动的有声肖像视频生成模型。流匹配由于其快速和高质量的采样,已成为扩散模型的有前途的替代方案。通过在学习到的运动潜伏空间中对说话的运动进行建模,我们可以更有效地对时间一致的运动潜伏物进行采样。这是通过一个简单而有效的基于transformer的矢量场预测器实现的,该预测器的灵感来自DiT,它还能够实现由语音驱动的自然情感感知运动生成。
-
我们提出了 FLOAT、基于流匹配的音频驱动的有声肖像生成模型,该模型使用学习到的运动潜在空间,它比基于像素的潜在空间更高效。
-
我们引入了一个简单而有效的基于 transformer 的流矢量场预测器,用于时间一致的运动潜在采样,这也支持语音驱动的情绪控制。
相关工作
EAMM将情绪视为面部运动的互补位移,并从从图像中提取的情绪标签中学习这些位移。
Eamm: One-shot emotional talking face via audio-based emotion-aware motion model.
从wav2vec中提取情感:
Emotion recognition from speech using wav2vec 2.0 embeddings
方法详解
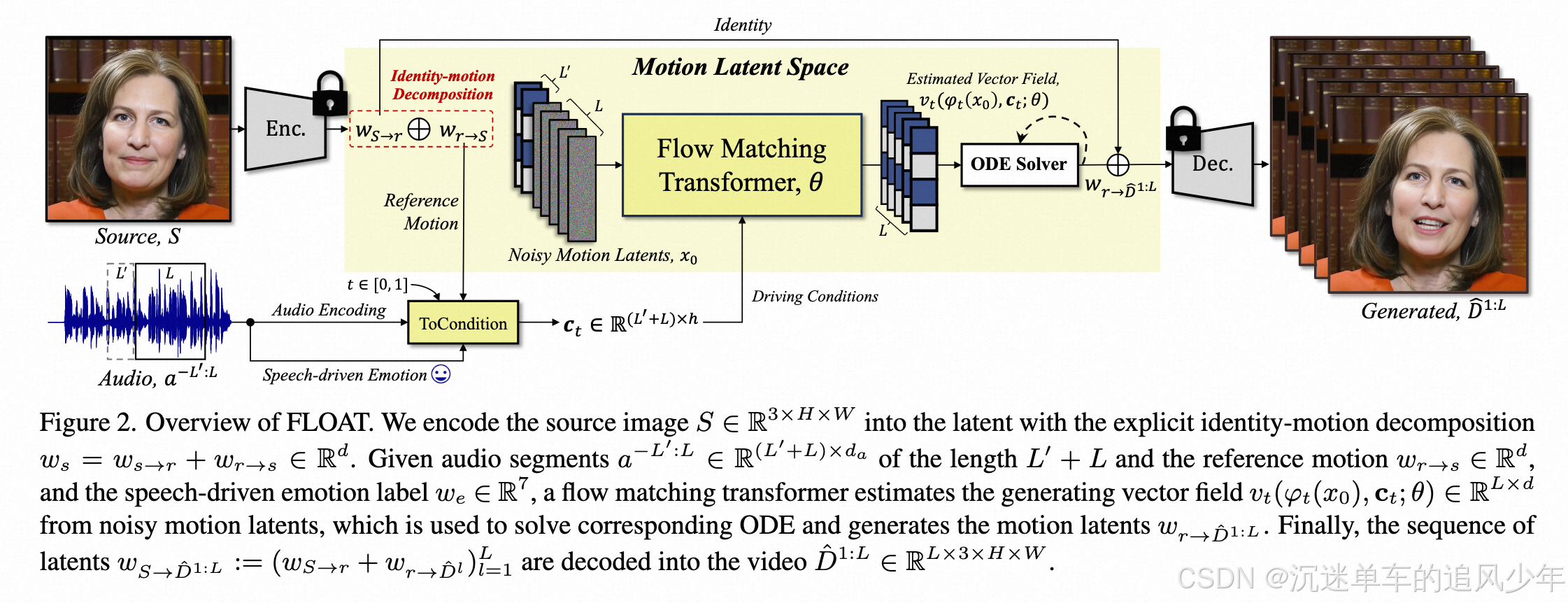
我们的方法包括两个阶段。首先,我们预先训练一个运动自动编码器,它为我们提供了有表现力和流畅的动作潜伏空间,用于制作会说话的肖像(第 4.1 节)。接下来,我们采用流匹配来生成一系列基于变压器的向量场预测器,使用驱动音频,该音频被解码为会说话的肖像视频(第 4.2 节)。得益于简单而强大的矢量场架构,我们还可以将语音驱动的情感作为驱动条件,从而实现情感感知的说话肖像生成。
情感控制
语音驱动的情感标签。我们如何使说话的动作更具表现力和自然性,在说话过程中,人类自然会通过声音反映自己的情绪,而这些情绪会影响说话的动作。例如,说话悲伤的人可能更有可能摇头并避免眼神接触。这种源自情感的非语言运动对会说话的肖像的自然性产生了关键影响。
现有工作 30, 81, 90 使用图像-情感配对数据或图像驱动的情感预测器 63 来生成情感感知运动。相比之下,我们加入了语音驱动的情绪,这是一种更直观的情感控制方式,用于音频驱动的说话肖像。具体来说,我们利用一个预先训练的语音情绪预测器,它产生七种不同情绪的softmax概率:愤怒、厌恶、恐惧、快乐、中立、悲伤和惊讶,然后将其输入到FMT中。
然而,由于人们并不总是带着单一、清晰的情感说话,因此仅从音频中确定情绪往往是模棱两可的。天真地引入语音驱动的情绪会使情绪感知运动生成更具挑战性。为了解决这个问题,我们在训练阶段将情绪与其他驾驶条件一起注入,并在推理阶段对其进行修改。