导读:大语言模型(LLM)在当今技术领域中扮演着越来越重要的角色,但其"幻觉输出"问题却成为实际应用中的痛点。本文将带你深入剖析这一现象的定义、表现形式及成因,并探讨如何通过RAG(检索增强生成)技术有效缓解这一问题。文章不仅详细分析了幻觉输出对医疗、金融等领域的潜在影响,还提供了具体的技术改进策略,如微调对齐、强化学习以及用户侧提示词优化等。
此外,本文还重点介绍了RAG技术的核心思想及其工作流程,结合Java和Python代码示例,展示了如何将RAG应用于智能客服、医疗问答和金融报告生成等场景。例如,在医疗领域,RAG能够通过实时检索权威数据库生成基于循证医学的答案,显著提升合规性和可靠性。
你是否好奇,为什么RAG可以有效减少模型的"胡编乱造"?加载文件、切割文档和向量数据库的作用分别是什么?这些问题将在文中逐一解答。如果你希望了解如何利用RAG技术快速搭建一个智能AI医生系统,或想探索更多实战案例,那么这篇文章绝对值得你深入阅读!
第1部分:什么是大模型的幻觉输出?
引言:
随着人工智能技术的飞速发展,大语言模型(LLM)如GPT、Llama等逐渐成为我们日常生活中不可或缺的一部分。然而,这些强大的工具并非完美无缺。其中,"幻觉输出"是大模型在实际应用中面临的一大挑战。本文将深入探讨这一问题的定义、表现形式、产生原因以及应对策略。
一、幻觉输出的定义与表现形式
-
定义:
幻觉输出(Hallucination)是指大语言模型生成的内容看似合理但实际上错误、虚构或脱离事实的现象。这种现象类似于人类的"臆想",即模型基于不完整或错误的知识生成了逻辑通顺但内容失实的回答。
-
表现形式:
- 虚构事实:
- 示例1:生成不存在的书籍(如称《时间简史》是鲁迅所写)。
- 示例2:编造错误的历史事件(如"秦始皇于公元前200年统一六国")。
- 错误推理:
- 示例:回答数学问题时,步骤正确但结果错误(如"2+3=6")。
- 过度泛化:
- 示例:将特定领域的知识错误迁移到其他领域(如用医学术语解释物理现象)。
- 矛盾内容:
- 示例:同一段回答中前后逻辑冲突(如先说"地球是平的",后又说"地球绕太阳公转")。
- 虚构事实:
二、幻觉输出的根本原因
-
训练数据的局限性:
- 数据噪声:模型训练数据可能包含错误、过时或偏见信息(如互联网上的谣言)。
- 知识截止:模型训练后无法获取新知识(如GPT-3的数据截止到2021年)。
-
模型生成机制:
- 概率驱动:模型通过预测"最可能的下一词"生成文本,而非验证事实。
- 缺乏常识判断:无法区分"合理表达"与"真实事实"。
-
模型策略的副作用:
- 创造性模式:模型在开放生成任务中更易"放飞自我"(如写小说时虚构细节)。
三、典型案例分析
-
医疗问答:
- 问题:用户问"新冠疫苗会导致自闭症吗?"
- 幻觉输出:模型可能生成"有研究表明两者存在相关性"(错误)。
- 解决方案:使用RAG检索WHO官方声明,生成"无科学证据支持此说法"。
-
金融咨询:
- 问题:"2024年比特币会涨到10万美元吗?"
- 幻觉输出:模型虚构专家预测或历史数据。
- 解决方案:限定回答范围(如"截至2023年,比特币最高价格为...")。
四、幻觉输出的影响
- 误导用户: 在医疗、法律等专业领域可能引发严重后果。
- 信任危机: 用户对模型输出的可靠性产生质疑。
- 技术瓶颈: 暴露大模型在真实性、可解释性上的不足。
五、缓解幻觉输出的策略
-
技术改进方案:
- 检索增强生成(RAG): 通过实时检索外部知识库(如维基百科、专业数据库),为生成提供事实依据。
- 微调对齐: 使用高质量数据(如标注正确的问答对)调整模型输出偏好。
- 强化学习(RLHF): 通过人类反馈惩罚错误生成,奖励准确回答。
-
生成策略优化:
- 温度参数调整:降低随机性(temperature=0),减少"胡编乱造"。
- 后处理校验:添加事实核查模块(如调用知识图谱API验证答案)。
-
用户侧应对:
- 提示词设计:明确要求模型标注不确定性(如"回答需基于2023年数据")。
- 多源验证:对关键信息人工交叉核对(如学术论文、权威网站)。
第2部分:带你走进RAG检索增强生成和应用场景
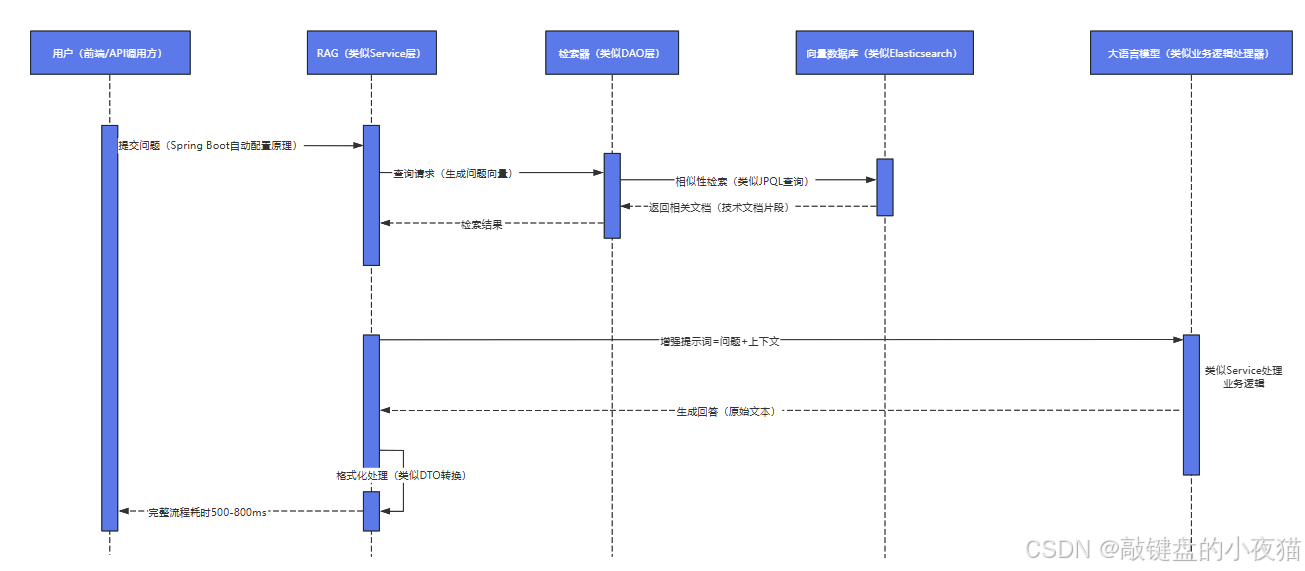
引言:
RAG(Retrieval-Augmented Generation)是一种结合信息检索与文本生成的AI技术架构。它通过检索系统找到与问题相关的知识片段,再将检索结果与问题共同输入生成模型得到最终答案。本文将详细介绍RAG的工作原理及其典型应用场景。
一、RAG技术的核心思想
-
核心思想:
- 先通过检索系统找到与问题相关的知识片段。
- 再将检索结果与问题共同输入生成模型得到最终答案。
- 类比人类解答问题的过程:遇到问题时先查资料(检索),再结合资料组织回答(生成)。
-
工作流程示例(Java代码描述):
java
public class JavaRAG {
public static void main(String[] args) {
// 1. 加载文档
List<Document> docs = FileLoader.load("data/");
// 2. 创建向量库(类似建立索引)
VectorDB vectorDB = new FAISSIndex(docs);
// 3. 处理用户问题
String question = "如何申请报销?";
List<Document> results = vectorDB.search(question, 3);
// 4. 生成回答
String context = String.join("\n", results.stream()
.map(Document::content)
.collect(Collectors.toList()));
String answer = LLM.generate(context + "\n问题:" + question);
System.out.println(answer);
}
}二、为什么需要RAG?
-
传统生成模型的局限性:
- 知识过时: 大模型(如GPT-3)训练数据截止于特定时间,无法覆盖实时信息。
- 幻觉问题: 生成内容可能包含不准确或虚构的信息。
- 领域局限性: 通用模型缺乏垂直领域的专业知识(如法律、医疗),企业私有数据无法写入公开模型。
-
检索与生成的互补性:
- 检索系统:擅长从海量数据中快速找到相关文档(实时、精准),实时从外部知识库检索信息。
- 生成模型:擅长语言理解和流畅输出。
- 结合优势:RAG通过检索外部知识库增强生成结果,提高准确性和可信度。
三、典型应用场景
-
智能客服系统:
- 传统问题:客服知识库更新频繁,模型无法实时同步。
- RAG方案:实时检索最新的产品文档、FAQ,生成个性化回答(如退货政策、故障排查)。
- 效果:减少人工干预,回答准确率提升30%以上。
-
医疗问答助手:
- 传统问题:通用模型缺乏专业医学知识,可能给出危险建议。
- RAG方案:检索权威医学数据库(如PubMed、临床指南),生成基于循证医学的答案,标注参考文献来源。
- 效果:合规性提升,避免法律风险。
-
金融研究报告生成:
- 传统问题:市场数据动态变化,模型无法实时分析。
- RAG方案:检索实时财报、新闻、行业数据→输入生成模型,自动生成带有数据支撑的投资建议。
第3部分:LLM智能AI医生+RAG系统案例实战
引言:
本部分通过一个具体的案例------智能AI医生,展示如何利用LLM大模型和RAG技术快速搭建智能客服系统。我们将逐步拆解每个步骤,并解答常见的疑问。
一、需求分析
-
目标:
- 快速搭建智能医生客服案例,基于LLM大模型+RAG技术。
- 方便直观地查看效果,并方便后续拆解每个步骤。
- 效果:根据用户的提问,检索相关私有数据,整合大模型,最终生成返回给用户。
-
数据准备:
- 文本加载:使用
TextLoader加载本地文件qa.txt。 - 分割文档:使用
RecursiveCharacterTextSplitter将文档分割成适合嵌入的块。
- 文本加载:使用
二、技术实现
-
加载文档:
pythonloader = TextLoader("data/qa.txt") docs = loader.load() -
分割文档:
pythontext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) splits = text_splitter.split_documents(docs) -
创建向量存储:
pythonembedding_model = DashScopeEmbeddings(model="text-embedding-v2", max_retries=3, dashscope_api_key="sk-xxxxxxxx") vectorstore = Chroma.from_documents(documents=splits, embedding=embedding_model, persist_directory="./rag_chroma_db") retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) -
定义模型:
pythonmodel = ChatOpenAI(model_name="qwen-plus", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", api_key="sk-xxxxxxxx", temperature=0.7) -
构建RAG链:
pythontemplate = """[INST] <<SYS>>\n你是一个有用的AI助手,请根据以下上下文回答问题:\n{context}\n<</SYS>>\n问题:{question} [/INST]""" rag_prompt = ChatPromptTemplate.from_template(template) rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | rag_prompt | model | StrOutputParser() ) -
执行查询:
pythonquestion = "饭后经常打嗝原因是?" response = rag_chain.invoke(question) print(f"问题:{question}") print(f"回答:{response}")
三、常见问题解答
-
为啥可以根据我们的提问,进行检索到对应的词条?
- RAG技术通过向量嵌入将文本转化为高维空间中的向量表示,然后利用相似度搜索找到最相关的文档片段。
-
为啥要加载文件?然后切割?什么是向量数据库?
- 加载文件是为了引入私有数据作为知识来源;切割是为了将长文档拆分为小片段,便于嵌入和检索;向量数据库用于存储这些嵌入后的向量,支持高效检索。
-
为啥检索到词条后,还可以用调整输出内容,更加友好?
- 通过模板化提示(Prompt Template)和大模型生成能力,可以将检索到的片段与用户问题结合起来,生成更加自然、友好的回答。
-
什么是嵌入大模型?和前面学的LLM大模型有啥区别?
- 嵌入大模型主要用于将文本转化为向量表示,而LLM大模型则负责生成自然语言文本。两者协同工作,前者负责检索,后者负责生成。
总结与展望
通过本文的讲解,我们深入了解了大模型的幻觉输出问题及其解决方案RAG技术。RAG不仅能够有效缓解幻觉输出,还能在多个领域(如智能客服、医疗问答、金融分析)中发挥重要作用。未来,随着技术的不断进步,我们可以期待更加智能化、可靠的大规模语言模型应用。