PixArt-α
仅使用 28400 美元,28M 训练数据,训练时长为 SD 1.5 的 10.8%,只有 0.6B 参数量,达到接近商业应用的水准。
现有数据集存在的缺陷:图文匹配偏差、描述信息不完整、词汇多样性不足(长尾效应显著)、低质量数据。
为了实现低成本训练,华为采用了三阶段的训练策略 :第一个阶段是学习像素依赖关系 ,简单来说是先学习生成真实的图像,这里是用ImageNet数据集训练一个基于类别的条件扩散模型;然后是学习文本和图像的对齐 ,即学习文本作为条件下的图像生成,这里的一个关键是采用 LVLM (Large Vision-Language Model) 来给图像生成更详细的文本描述;最后一个阶段是高质量微调 ,即采用高分辨率和高美学图像对模型进行微调。
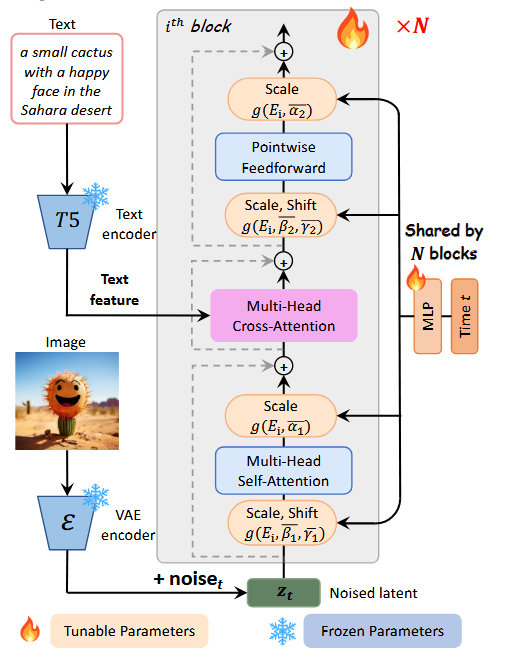
由于 Transformer 块中有 3 个 MLP,6 个参数,占总参数量的 27%,由于是训练一个文本引导的图像扩散模型,不需要类别标签,那么所有的 MLP 本质上在学习相似的时序模式。故改用单个 MLP 生成基准参数 S = f ( t ) S=f(t) S=f(t),为每个块引入可训练嵌入 E ( i ) E(i) E(i),每个块最终的参数为 S ( i ) = f ( t ) + E ( i ) S(i)=f(t)+E(i) S(i)=f(t)+E(i),同时为了保证与原来 3 个不同 MLP 的一致性,强制 t = 500 t=500 t=500 时,与原设计输出一致。
在第二阶段,文本-图像对齐时,之前部分文生图模型都是基于 LAION 数据集训练,但其噪声过大,图片对应的文本描述不准确。采用了 LLaVA 为图片生成更详细的描述,并采用包含丰富物体的 SAM 数据集," Describe this image and its style in a very detailed manner.",认为质量比数据量更重要,采用 256×256 分辨率训练。
第三阶段,对高分辨率和高质量图像微调。采取和 SDXL 一样的渐进式训练策略:256×256->512×512->1024×1024
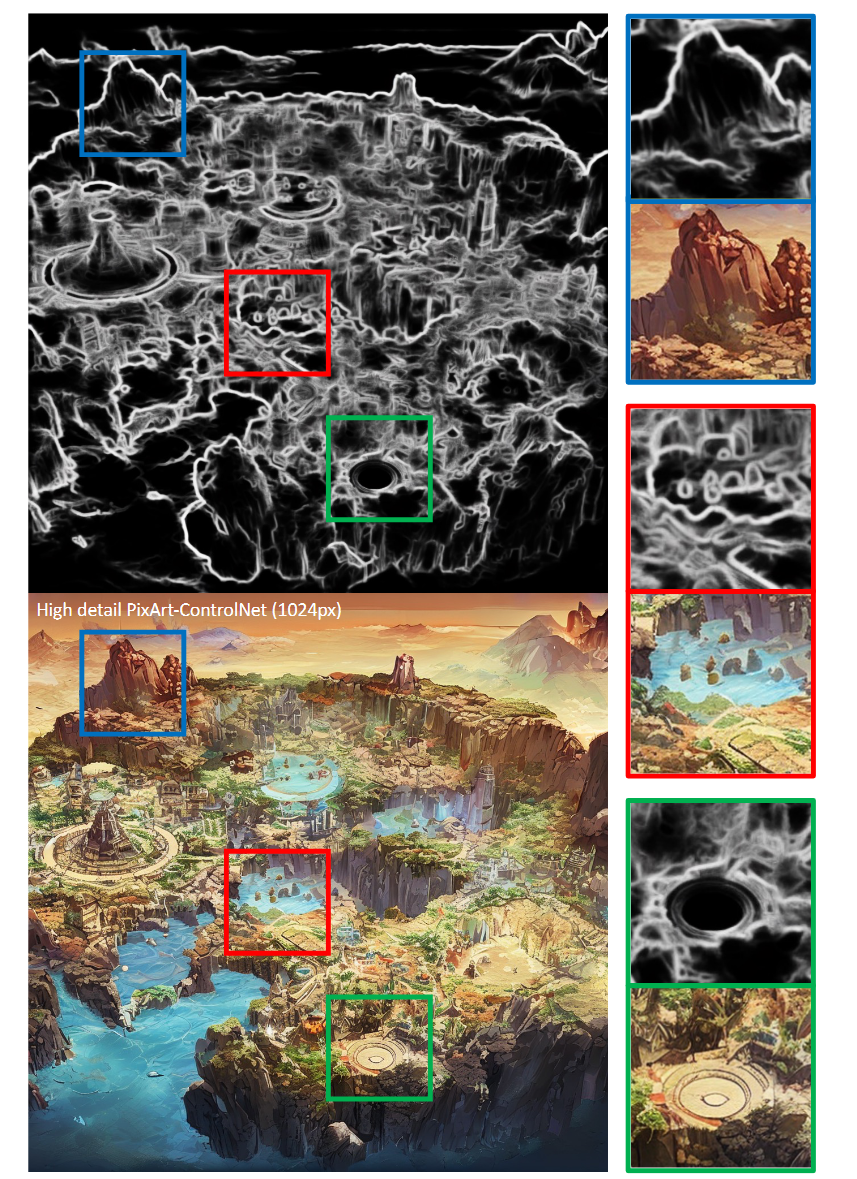
生成结果

PixArt-δ
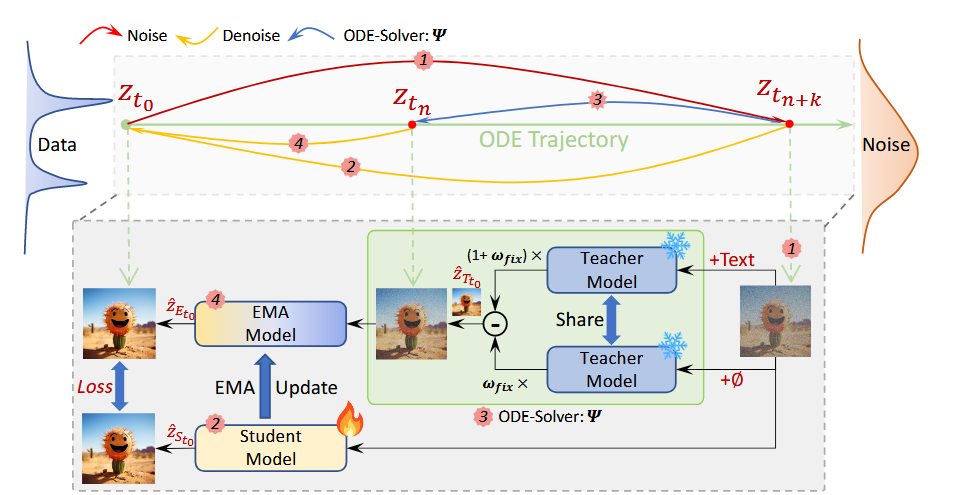
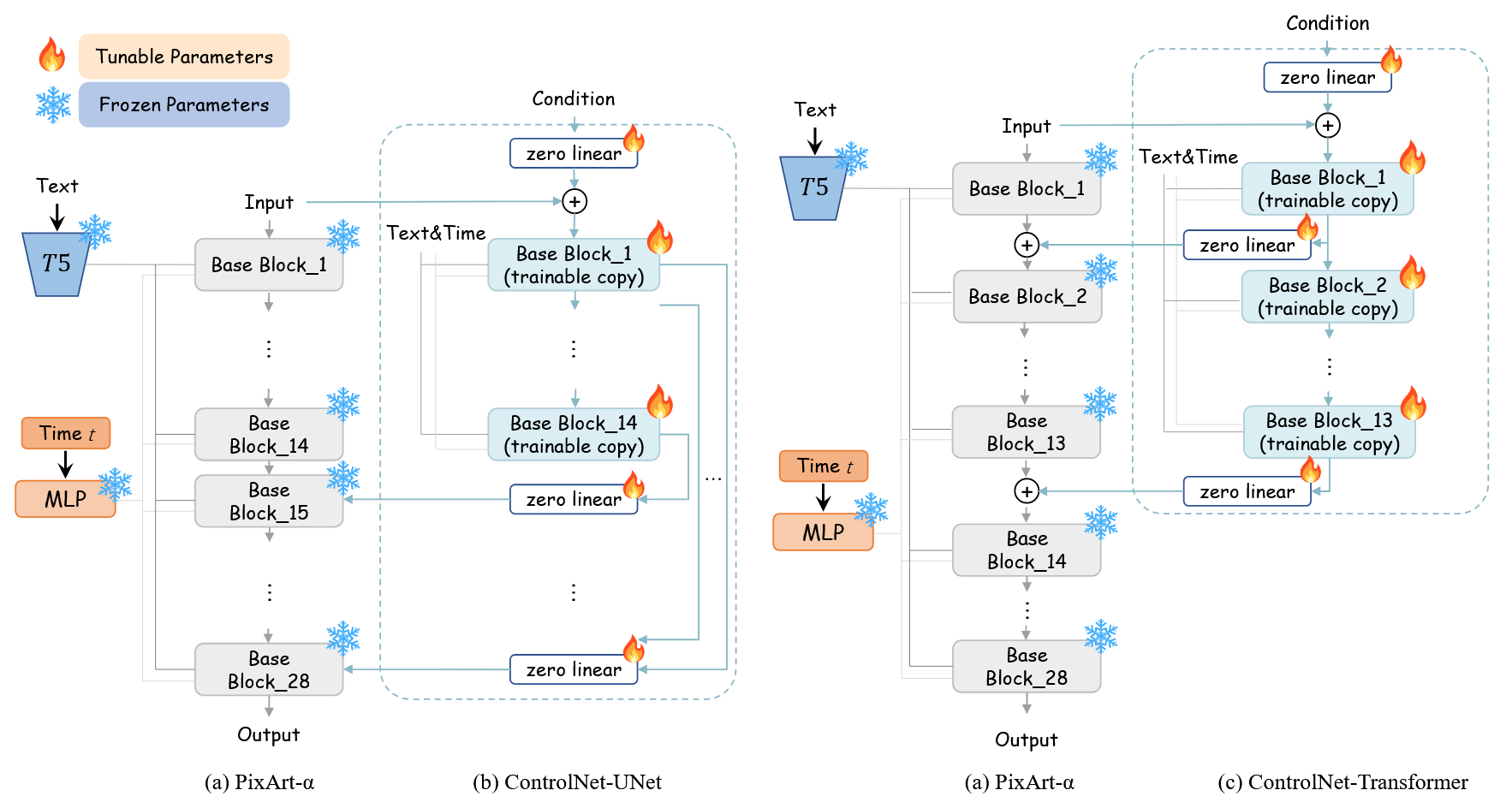
将 Latent Consistency Model (LCM) 集成到 PixArt-α,显著加快推理速度,生成 1024×1024 图像只需要 0.5s, 在 32GB V100 GPU 上仅用一天完成训练。使用 ControlNet 实现细粒度的文本控制。
对于 LCD 算法采取三模型:EMA、Teacher、Student,分别作为 ODE 求解器 Φ \Phi Φ, f θ f_\theta fθ 和 f θ − f_{\theta^-} fθ− 的去噪器。通过固定 CFG 系数,简化 LCM 的动态引导策略,减少训练复杂度。(4 步采样加速)
生成结果