感谢 GPT,对很多问题的理解有机会更深。
大家攻击 Lambda 架构,常说的一个点就是 "实时离线指标存在差异"。"实时离线指标存在差异",是一个真实困扰运营方的问题吗?
答案:是的,这是一个真实生活中的痛点。
原因如下,特别是第一条,会让业务运营存在不确定性,为了应对这种不确定性,可能需要预留出业务余量,造成浪费。
-
实时数据偏差引发错误判断
• 运营团队可能在实时看板上看到用户注册数为 900,以为目标还没达成,于是推送通知、加大预算。
• 结果第二天离线数据跑完,真实注册是 1100,实际早就达成了。
• 这会造成 资源浪费、判断误差。
-
数据不一致影响信任
• 运营问:"实时看板显示新增 900,日报却说新增 1100,这是哪个错了?"
• 数据团队解释:"实时数据有水位延迟、数据乱序、去重不完整......"
• 非技术同学听不懂,久而久之就对系统失去信任。
-
多方依赖相同指标,版本不一致
• 实时系统和离线系统往往使用不同代码、不同计算链路:
• 实时:Kafka → Flink → Redis/ClickHouse
• 离线:Hive/Spark → HDFS → 数据仓库
• 一点小的业务逻辑差异、时间处理方式不同、清洗策略不同,就会让指标产生偏差。
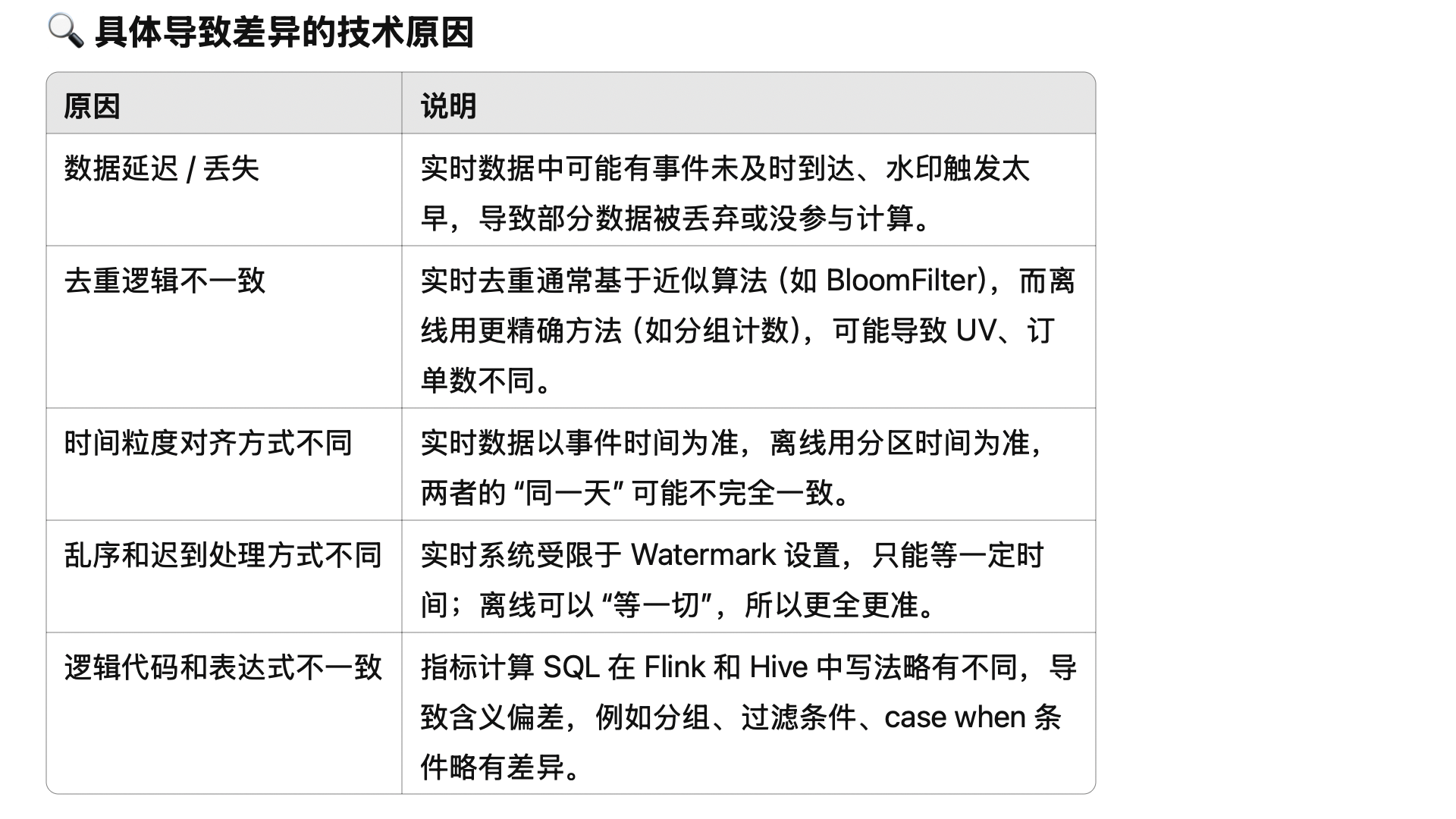
附1:实时指标为什么可能不对?
答:因为 Flink 的计算有时间窗口的概念,比如:每个整点,计算上一个小时的销售额。因为队列延迟、网络出错、重试导致数据重复等原因,会让 Kafka 等队列中的数据不能完全被信任,上一个小时的数据不一定真的全了,可能有一些数据要等几分钟才到,也有可能永远不到。
为了解决这个问题,一般会延迟几分钟,等等跑慢了的数据。但也不能无限等下去。理论上总是可能有数据来晚了。
附2:批处理系统(离线) + 流处理系统(实时) + Serving 层合并结果为什么不准?
简而言之:因为实时数据不准确,那么 Serving 的到的数据肯定也不准确。
Lambda 架构:批处理系统(离线) + 流处理系统(实时) + Serving 层合并结果
我之前的疑问:Serving 层如何合并?如何保证离线+实时,得到准确的全量数据?
一般大家说得不到,原因就在于
(1)流处理系统拿到的数据可能是不准确的
(2)离线、实时数据的边界可能有模糊的地方。