前期准备:
新建 Scrapy项目
scrapy startproject mySpider # 项目名为mySpider
进入到spiders目录
cd mySpider/mySpider/spiders
创建爬虫
scrapy genspider heima bbs.itheima.com # 爬虫名为heima ,爬取域为bbs.itheima.com
制作爬虫
import scrapy
class heimaItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()import scrapy
from scrapy.selector import Selector
from mySpider.items import heimaItem
class HeimaSpider(scrapy.Spider):
name = 'heima'
allowed_domains = ['bbs.itheima.com']
start_urls = ['http://bbs.itheima.com/forum-425-1.html']
def parse(self, response):
print('response.url: ', response.url)
selector = Selector(response)
node_list = selector.xpath("//th[@class='new forumtit'] | //th[@class='common forumtit']")
for node in node_list:
# 文章标题
title = node.xpath('./a[1]/text()')[0].extract()
# 文章链接
url = node.xpath('./a[1]/@href')[0].extract()
# 创建heimaItem类
item = heimaItem()
item['title'] = title
item['url'] = url
yield item
# 获取下一页的链接
if '下一页' in response.text:
next_url = selector.xpath("//a[@class='nxt']/@href").extract()[0]
yield scrapy.Request(next_url, callback=self.parse)连接MySQL数据库并保存数据
首先需要在数据库中(使用workbench或者shell)创建数据库heima_db(如果不存在):
CREATE DATABASE IF NOT EXISTS heima_db;
from itemadapter import ItemAdapter
# 需要在终端中安装pymysql包: pip install pymysql
import pymysql
class MyspiderPipeline:
def open_spider(self, spider):
# 简单直接的MySQL连接
self.connection = pymysql.connect(
host='localhost',
user='root',
password='修改为自己的数据库密码',
db='heima_db',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
self.cursor = self.connection.cursor()
# 创建表(如果不存在)
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS heima_news (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255),
url VARCHAR(512),
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
# 清空现有数据
self.cursor.execute("TRUNCATE TABLE heima_news") # 用于快速清空heima_news表中的所有数据。
self.connection.commit()
print("爬虫启动,数据库已准备就绪")
# Scrapy会自动调用 process_item() 方法处理每一个抓取到的 item。
# 每生成一个item(例如在爬虫的 parse 方法中 yield 一个item),Scrapy就会调用一次这个方法。
def process_item(self, item, spider):
# 插入数据
self.cursor.execute(
"INSERT INTO heima_news (title, url) VALUES (%s, %s)",
(item['title'], item['url'])
)
self.connection.commit()
return item
# 当爬虫处理完所有 start_urls 和后续发现的链接
# 没有更多请求需要处理时,此函数会被调用
def close_spider(self, spider):
# 显示数据数量
self.cursor.execute("SELECT COUNT(*) AS total FROM heima_news")
result = self.cursor.fetchone()
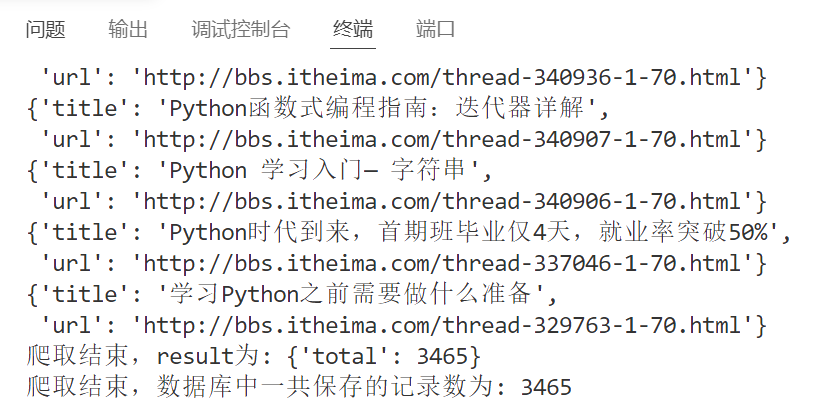
print("爬取结束,result为:", result)
print("爬取结束,数据库中一共保存的记录数为:", result['total'])
# 关闭连接
self.cursor.close()
self.connection.close()settings.py,解开ITEM_PIPELINES的注释,并修改其内容:
ITEM_PIPELINES = {
"mySpider.pipelines.MyspiderPipeline": 300,
}
运行
在终端转到 mySpider/mySpider文件夹,根据你自己的路径写:
cd mySpider/mySpider
在终端中运行:
scrapy crawl heima -s LOG_ENABLED=False
结果
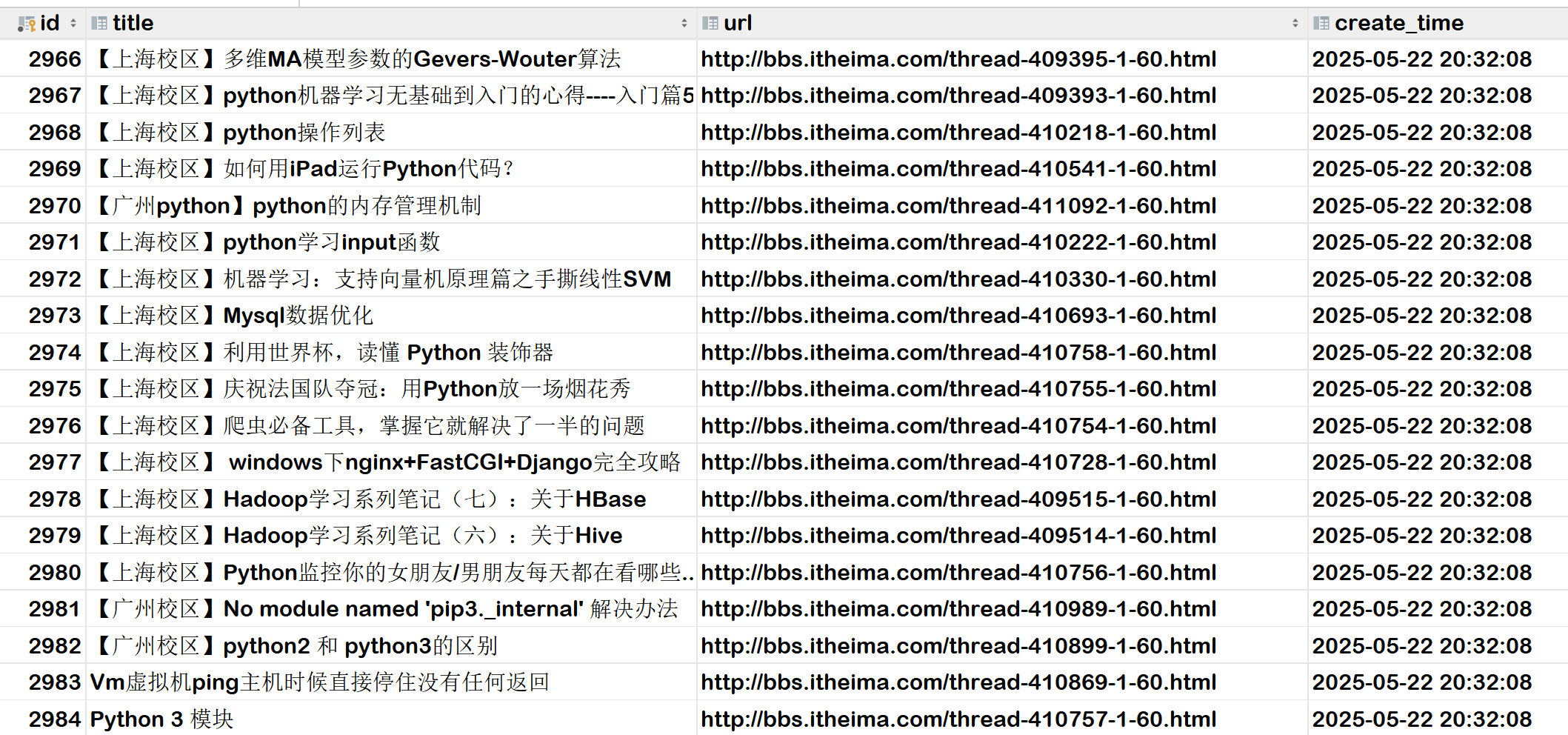
数据库信息: