HQL和SQL查询优化基础
简介与区别
SQL:管理关系型数据库,直接操作和访问数据库中的物理表(Tables)、视图(Views)、列(Columns)等物理结构
HQL:Hibernate 框架提供的面向对象的查询语言。它是 SQL 的一种面向对象变体,操作和访问应用程序中的 Java 对象及其属性,而不是直接操作数据库表
下面是主要区别
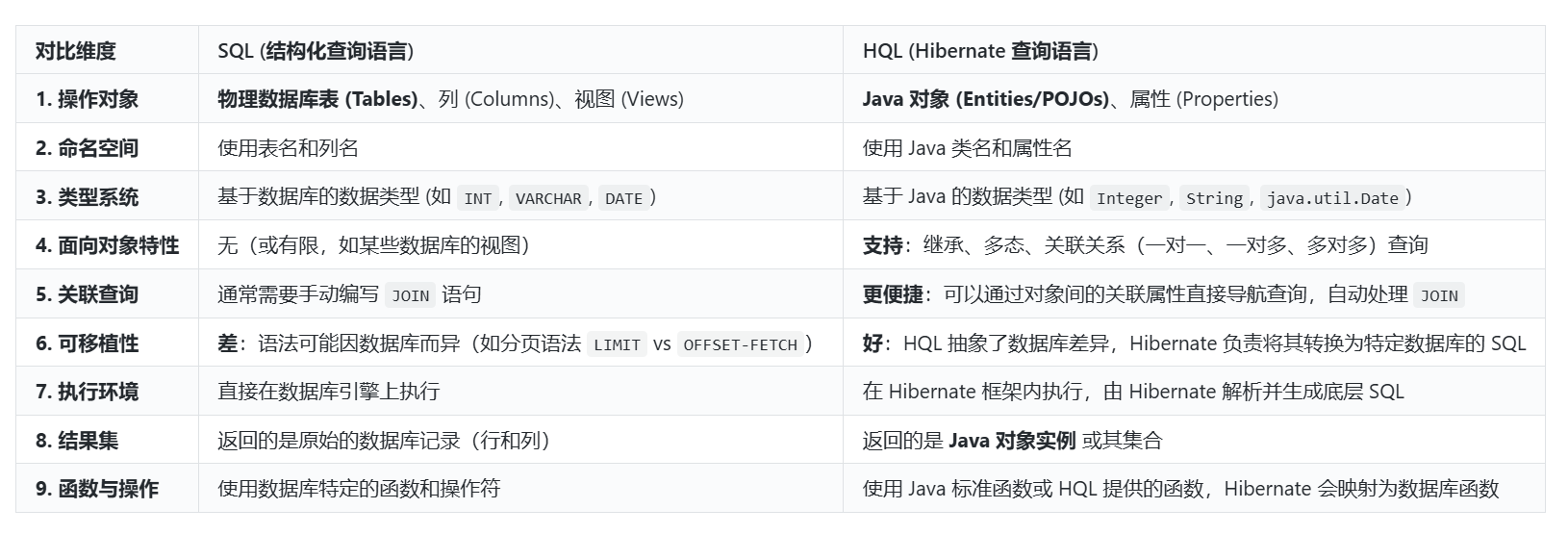
简单来说就可以总结为以下几点
1.SQL 是底层的、面向表的数据库语言,与具体数据库紧密相关
2.HQL 是面向对象的、面向实体的查询语言,运行在 Hibernate 框架之上,抽象了数据库差异
3.操作对象不同:SQL 操作表和列,HQL 操作对象和属性
4.HQL 在处理 继承、多态、关联导航等面向对象特性方面比 SQL 更自然、更强大
5.HQL 提供了更好的可移植性和更一致的分页、参数绑定等功能
6.需要关注 HQL 生成的 SQL 是否高效,理解 HQL 如何被解析并最终转换为 SQL 是进行 HQL查询优化的关键
技术点
命名差异
sql
SELECT column1,column2 FROM table1 WHERE condition eg.SELECT Name, Age FROM Customers WHERE Age >= 30;
hql
SELECT entity.property1, entity.property2 FROM com.example.EntityName entity WHERE entity.property1 = :param;补充:
找到名为 com.example.EntityName 的实体类所映射的数据库表
在这些数据中,筛选出 property1 属性的值等于你稍后会提供的 :param 值的那些行。
对于这些满足条件的行,只返回它们的 property1 和 property2 属性的值
对象:是 类(Class) 的一个具体的实例,类是定义对象行为和属性的蓝图或模板,而对象则是按照这个蓝图创建出来的、存在于内存中的具体"东西"
实体:代表了应用程序领域中的一个有独立生命周期的数据单元,通常直接映射到数据库中的一张表
属性:构成一个实体(或对象)的各个组成部分,每个部分都承载着关于这个实体某一方面的信息或数据
简单来说对象就是写代码时创建的各种"积木",可以在程序里构建功能,而实体是这些"积木"中的一种特殊类型,不仅仅在程序里有用,更重要的是它们的"样子"(数据)会被保存到数据库这个"仓库"里,以便下次程序启动时还能"拿出来"继续用,所以,使用 Hibernate 的 HQL 时,操作的是"实体"的属性,因为最终目的是要把这些实体的状态存入或取出数据库
类型系统
sql
WHERE age > 25 AND name LIKE 'A%';补充:
%是通配符(这个还是上个星期去取证集训才记住的,之前数据库学的有点烂)
A%:以A开头
%A%:带有A
%A:以A结尾
另外还有_也是sql中的通配符
A_C:会匹配AAC、ABC、ADC等,但不可能是AC、AAAC这类的
__at:会匹配什么什么at,比如what、boat等
hql
WHERE entity.age > 25 AND entity.name LIKE 'A%'; (直接使用 Java 对象属性和类型)entity.age 和 entity.name是java实体中的属性名
面向对象特性(继承与多态)
sql:查询继承层次结构通常需要复杂的UNION或CASE WHEN语句,或者依赖数据库特定的继承模式
hql: 可以轻松查询类的层次结构
FROM ParentClass - 查询 ParentClass 及其所有子类的实例
FROM ChildClass - 仅查询 ChildClass 的实例
SELECT c FROM ChildClass c WHERE c.parentProperty = :value - 利用多态性查询子类实例
关联查询
sql
SELECT e.name, d.department_name FROM employee e JOIN department d ON e.dept_id = d.id WHERE e.salary > 5000;e是employee表的别名,使用别名可以让查询语句更简洁,避免重复写完整的表名,.name表示从employee表中选择name列(也就是员工的姓名);d是department表的别名,.department_name表示从department表中选择department_name列(也就是部门的名称);FROM关键字指示要从哪个表开始查询,employee是表的名称,e是为employee表设置的别名;JOIN关键字用于连接两个或多个表,这里表示将employee表与department表连接起来;ON是JOIN子句的一部分,用于指定两个表之间连接的条件;e.dept_id = d.id告诉数据库如何将employee表的行与department表的行匹配起来,查找employee表中dept_id与department表中id相等的行,从而将员工与其对应的部门关联起来;后面是筛选条件,前面解释过了
从员工(employee)表和部门(department)表中获取信息,以查找工资超过 5000 的员工姓名及其所属部门的名称
hql
//假设 Employee 实体有一个 @ManyToOne 关联到 Department
方式一 (导航): SELECT e.name, e.department.name FROM Employee e WHERE e.salary > 5000; (Hibernate 会自动在底层生成 JOIN)
方式二 (显式 JOIN): SELECT e.name, d.name FROM Employee e JOIN e.department d WHERE e.salary > 5000; (更明确地表达了意图)方式一:
e.name表示选择Employee实体中的name属性(对应员工姓名);e.department 指的是Employee实体中名为department的那个关联属性(类型为 Department);.name 表示进一步访问这个Department对象的name属性(对应部门名称)。核心点是直接通过对象属性的链式调用(e.department.name)来访问关联实体的属性;Hibernate 会根据实体之间的 @ManyToOne 或 @OneToMany 等映射关系,自动在底层生成必要的 JOIN 语句。
Employee是实体类名(对应 Java 中的com.example.Employee类,如果有package,在这里通常直接写类名,除非有歧义);e是Employee 实体的别名,通常用于简化后续引用
方式二:
d.name表示选择Department实体的name属性;FROM Employee e是指定从Employee实体查询,别名为 e;JOIN是hql的关键字,明确表示要执行一个连接操作;e.department: 这次JOIN的是Employee实体中名为department的关联属性,在hql中,JOIN后面跟着的往往是实体的关联属性。核心点是明确地告诉Hibernate,通过e.department这个关联来执行一个连接,并将连接后的Department实体命名为d;这里的e.department实际上代表了Employee与Department之间的映射关系,Hibernate仍然会根据映射生成底层的SQL JOIN子句和ON条件
ps:我感觉这里就是sql中的表名在hql中是实体,列名是属性
Employee实体有一个@ManyToOne关联到Department实体,意味着在Employee实体类中,应该有一个类型为Department的属性(例如 private Department department;),并且这个属性上通常会有一个@ManyToOne注解,表明多个Employee可以关联到一个Department
集合操作
sql
SELECT * FROM order_items WHERE order_id IN (SELECT id FROM orders WHERE customer_id = 123);子查询应用,目的是查找ID为123的用户的所有订单中的所有商品项(或称订单详情)
hql
//假设Order有一个@OneToMany关联到OrderItem
SELECT item FROM OrderItem item WHERE item.order IN (FROM Order o WHERE o.customer.id = 123);
简洁版: SELECT item FROM Order o JOIN o.items item WHERE o.customer.id = 123;在 Order 实体类中,应该有一个集合类型的属性(例如Set<OrderItem> items; 或 List<OrderItem> items;),并且这个属性上通常会有@OneToMany注解;o是实体Order的别名
简洁版:
item代表了整个OrderItem实体对象;o.items是Order实体o中的一个属性;是一个集合属性,用于表示Order和OrderItem之间的一对多关系
分页
sql
MySQL: SELECT * FROM table LIMIT 10 OFFSET 20;
Oracle/SQL Server: SELECT * FROM table ORDER BY id OFFSET 20 ROWS FETCH NEXT 10 ROWS ONLY;mysql:
选择table表中所有的列;LIMIT关键字用于限制返回的行数,最多只返回10行数据;OFFSET关键字用于指定从结果集的第几行开始返回,跳过前20行数据,从第21行开始返回(因为是基于0的索引,所以20代表第21条)
oracle/sql server:
ORDER BY关键字用于对结果集进行排序,按照id列进行排序,20 ROWS表示跳过前 20 行数据;Workspace NEXT关键字用于限制返回的行数,10 ROWS ONLY 表示只返回接下来的10行数据
hql
SELECT e FROM Employee e ORDER BY e.id DESC (然后通过 Hibernate API 设置分页参数)
设置分页参数:
Query<Employee> query = session.createQuery("SELECT e FROM Employee e ORDER BY e.id DESC", Employee.class);
query.setFirstResult(20); // 对应 OFFSET
query.setMaxResults(10); // 对应 LIMIT/FETCH NEXT
List<Employee> employees = query.list();SELECT表示选择数据;FROM表示查询的源实体;ORDER BY表示对查询结果进行排序
e是Employee 实体(类)的别名,SELECT e的意思是选择并返回完整的Employee实体对象,类似于sql中的SELECT *,但返回的是Java对象而不是原始数据库行;.id 表示Employee实体中的id属性;DESC:是DESCENDING的缩写,表示降序排列,如果省略DESC或写ASC,则表示升序排列
设置分页参数:
session.createQuery(...)是Hibernate Session接口的一个方法,用于创建一个hql查询对象
Employee.class用于指定查询结果的类型会告诉Hibernate,期望返回的是Employee类型的实体对象列表,而不是通用的Object列表
query.setFirstResult(20); 对应上面sql中的OFFSET
setFirstResult(int startPosition)用于设置查询结果的起始位置(或偏移量)
query.setMaxResults(10); 对应 LIMIT/FETCH NEXT
List<Employee> employees = query.list();
query.list(): 执行配置好的 HQL 查询,并将结果封装成一个 List 返回,由于使用了TypedQuery,所以返回的列表类型是List<Employee>
参数绑定
sql
SELECT * FROM users WHERE username = 'alice' AND status = 'active';可以sql注入
hql
SELECT u FROM User u WHERE u.username = :username AND u.status = :status;
Query<User> query = session.createQuery("SELECT u FROM User u WHERE u.username = :username AND u.status = :status", User.class);
query.setParameter("username", "alice");
query.setParameter("status", "active");
List<User> users = query.list();u是User实体(类)的别名;User是Java 实体类名(例如,com.example.User 类)u.username是User实体u中的username属性;= :username: 这里 **: 开头的 :username** 是一个命名参数,是一个占位符,表示在执行查询时,需要为这个参数提供一个实际的值;AND: 逻辑运算符,要求两侧的条件都为真;u.status是User实体u中的status属性;= :status: 另一个命名参数,表示 status 属性的值也需要动态提供。
session.createQuery(...): 这是获取一个 HQL 查询对象的方法;第一个字符串参数是 HQL 查询本身;User.class指定查询返回的结果类型为User实体,提供了类型安全性;setParameter("parameterName", value)是Query对象的一个关键方法,用于为命名参数设置实际值;"username": 必须与 HQL 语句中 :username 冒号后面的名字完全匹配(不包含冒号);"alice": 这是要赋给 :username 参数的实际字符串值;query.setParameter("status", "active");为 :status 命名参数设置了值 "active";query.list(): 执行这个已经设置好参数的 HQL 查询,并将符合条件的所有 User 实体对象封装成一个 List 返回
投影与别名
sql
SELECT u.username AS name, u.email FROM users u WHERE u.id = 1;hql
SELECT u.username AS name, u.email FROM User u WHERE u.id = 1;AS name是为查询结果中的列设置一个别名,意味着在最终的结果中,username这一列将显示为name,只是是为了让结果更易读
u.id指的是User实体u中的id属性,id属性通常映射到数据库表中的主键列
结果通常是对象数组或使用@EntityResult/@SQLResult映射到特定类
简单查询对比
查询所有姓名以 "Z" 开头,年龄大于 30 的员工
sql
SELECT id, name, age FROM employees WHERE name LIKE 'Z%' AND age > 30;hql
//假设Employee是实体类
SELECT e FROM Employee e WHERE e.name LIKE 'Z%' AND e.age > 30;关联查询对比
查询所有订单金额超过 1000 元的订单,并显示订单号、客户姓名以及客户所属的部门名称
假设的实体关系:
Order (订单) - @OneToMany 关联到 OrderItem (订单项)
Order - @ManyToOne 关联到 Customer (客户)
Customer - @ManyToOne 关联到 Department (部门)
sql
//复杂的join
SELECT o.order_number, c.name AS customer_name, d.department_name
FROM orders o
JOIN customers c ON o.customer_id = c.id
JOIN departments d ON c.department_id = d.id
JOIN order_items oi ON o.id = oi.order_id
GROUP BY o.order_number, c.name, d.department_name
HAVING SUM(oi.quantity * oi.unit_price) > 1000;GROUP BY用于将在指定列中具有相同值的行分组为摘要行,使用聚合函数(如 SUM、COUNT、AVG 等)时,GROUP BY是必不可少的
HAVING用于筛选GROUP BY后的分组,类似于WHERE子句,但WHERE用于筛选原始行,而HAVING用于筛选分组,HAVING 可以在聚合函数上应用条件
SUM(oi.quantity * oi.unit_price)是一个聚合函数,计算每个分组内所有order_items的总金额,oi.quantity是商品数量,oi.unit_price是商品单价,乘积就是单个商品项的价值
hql
//利用对象导航
SELECT o.orderNumber, c.name, c.department.name
FROM Order o
JOIN o.customer c
JOIN c.department d
JOIN o.items oi
GROUP BY o.orderNumber, c.name, c.department.name
HAVING SUM(oi.quantity * oi.unitPrice) > 1000;
//更简洁的导航(如果只需要客户姓名和部门)
SELECT o.orderNumber, c.name, c.department.name
FROM Order o
JOIN o.customer c
WHERE o.id IN (
SELECT oi.order.id
FROM OrderItem oi
GROUP BY oi.order.id
HAVING SUM(oi.quantity * oi.unitPrice) > 1000
);对象导航:
c.department.name是hql中典型的关联导航,c.department指的是Customer实体c中名为department的关联属性(本身是一个Department实体),.name接着访问这个Department实体中的name属性(即部门名称),Hibernate会自动处理底层的JOIN操作来完成这种导航
JOIN o.customer c将每个 Order 实体与其关联的 Customer 实体连接起来
JOIN c.department d将每个Customer实体与其关联的Department实体连接起来
JOIN o.items oi将每个Order实体与其包含的各个OrderItem实体连接起来
简洁版:
SELECT oi.order.id FROM OrderItem oi GROUP BY oi.order.id HAVING SUM(oi.quantity * oi.unitPrice) > 1000是内部子查询,从所有订单项中,计算每个订单的总价值,然后找出所有总价值超过 1000 的订单的 ID
SELECT o.orderNumber, c.name, c.department.name FROM Order o JOIN o.customer c WHERE o.id IN (...)是外部主查询,只选择那些订单 ID 存在于子查询结果(即总金额超过 1000 的订单 ID 列表)中的订单