1. 复制粘贴搜索
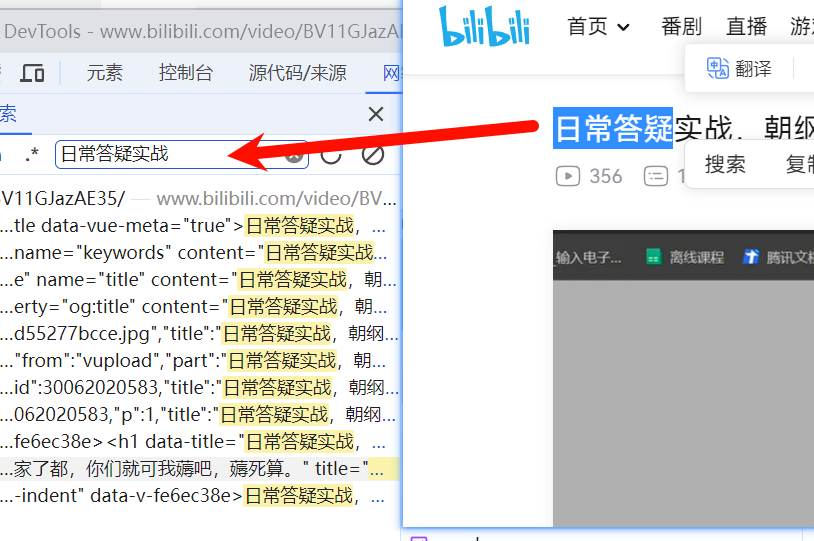
2. 利用工具写请求代码
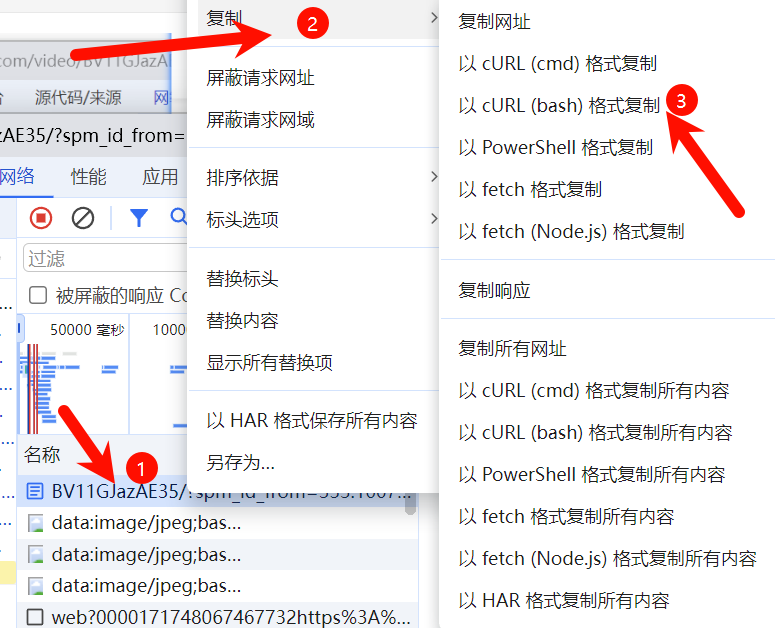
工具网址:Convert curl commands to code
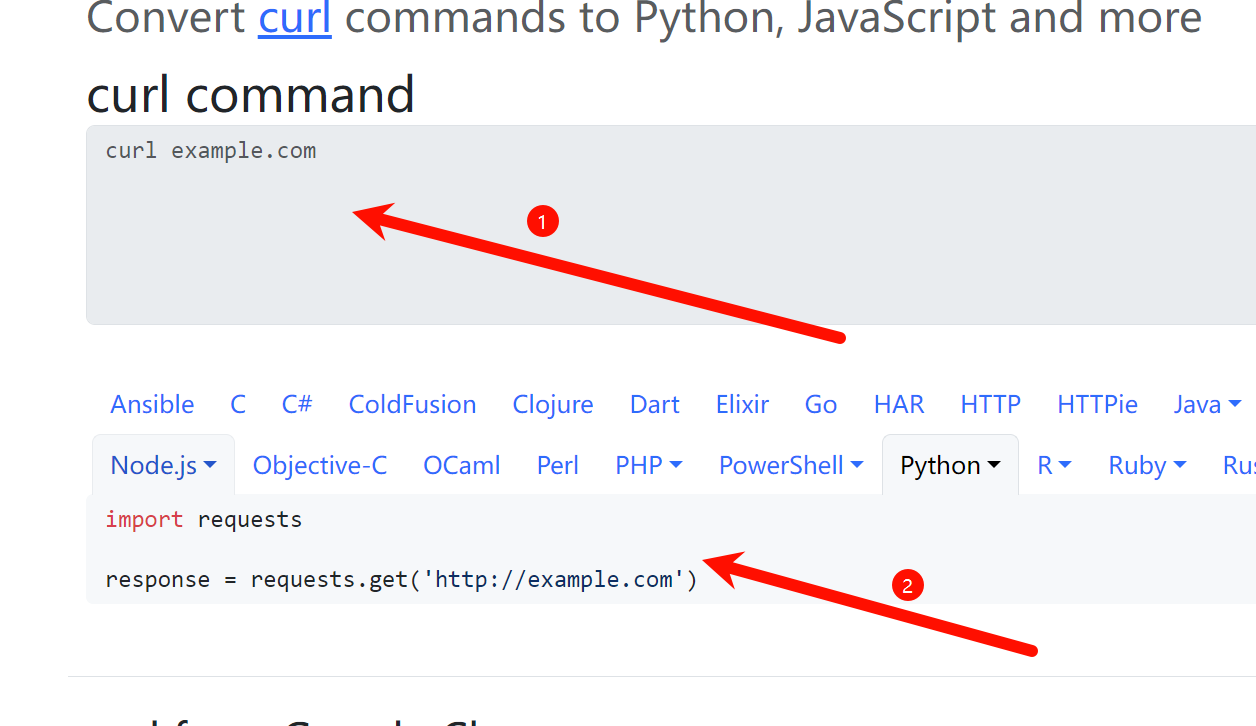
3. 把爬取内容喂给ai
先保存到txt文件
# 上面代码是第二部分复制粘贴的
with open('1.txt', 'w') as f:
f.write(response.text)问ai:根据txt的内容,查找并提取视频地址和音频地址
以下是ai返回的:
import requests
import re
import json
url = 'https://www.bilibili.com/video/BV11GJazAE35/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36',
'Referer': 'https://www.bilibili.com/'
}
response = requests.get(url, headers=headers)
html = response.text
# 方法1:从window.__playinfo__中提取
match = re.search(r'window.__playinfo__=(.*?)</script>', html)
if match:
play_info = json.loads(match.group(1))
# 视频地址
video_url = play_info['data']['dash']['video'][0]['baseUrl']
# 音频地址
audio_url = play_info['data']['dash']['audio'][0]['baseUrl']
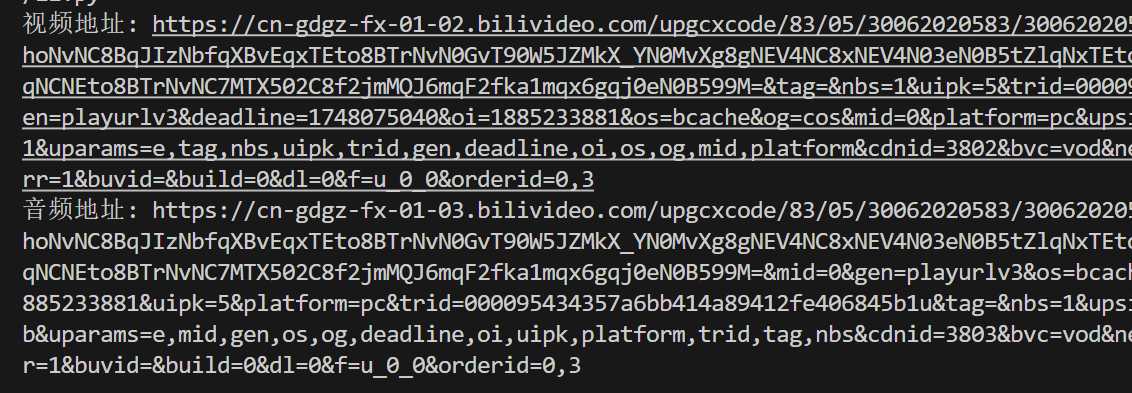
print(f"视频地址: {video_url}")
print(f"音频地址: {audio_url}")运行结果:
4. 合并视频和音频
这一步我直接 按tab键自动补全的,参考以下代码:
from moviepy import VideoFileClip, AudioFileClip
# 加载视频和音频文件
video_clip = VideoFileClip("视频.mp4")
audio_clip = AudioFileClip("视频.mp3")
# 将音频设置为视频的音频
video_clip = video_clip.with_audio(audio_clip)
# 保存合并后的视频
video_clip.write_videofile("合并后的视频.mp4")完整代码如下:
import requests
import re
import json
url = 'https://www.bilibili.com/video/BV11GJazAE35/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36',
'Referer': 'https://www.bilibili.com/'
}
response = requests.get(url, headers=headers)
html = response.text
# 方法1:从window.__playinfo__中提取
match = re.search(r'window.__playinfo__=(.*?)</script>', html)
if match:
play_info = json.loads(match.group(1))
# 视频地址
video_url = play_info['data']['dash']['video'][0]['baseUrl']
# 音频地址
audio_url = play_info['data']['dash']['audio'][0]['baseUrl']
print(f"视频地址: {video_url}")
print(f"音频地址: {audio_url}")
# 视频
with open('视频.mp4', 'wb') as f:
f.write(requests.get(video_url, headers=headers).content)
# 音频
with open('视频.mp3', 'wb') as f:
f.write(requests.get(audio_url, headers=headers).content)
from moviepy import VideoFileClip, AudioFileClip
# 加载视频和音频文件
video_clip = VideoFileClip("视频.mp4")
audio_clip = AudioFileClip("视频.mp3")
# 将音频设置为视频的音频
video_clip = video_clip.with_audio(audio_clip)
# 保存合并后的视频
video_clip.write_videofile("合并后的视频.mp4")效果如下:

视频也是有声音的。
说明:爬的视频不是高清的,想爬高清的得登陆,在代码中增加对应的参数与请求头等,比如cookie值等。