1.使用正则完成下列内容的匹配
-
匹配陕西省区号 029-12345
-
匹配邮政编码 745100
-
匹配身份证号 62282519960504337X
python
import re
print(bool(re.fullmatch(r'^029-\d+$', '029-12345')))
print(bool(re.fullmatch(r'^\d{6}$', '745100')))
print(bool(re.fullmatch(r'^\w+@\w+\.\w+$', 'lijian@xianoupeng.com')))
print(bool(re.fullmatch(r'^\d{17}[\dXx]$', '62282519960504337X')))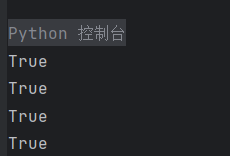
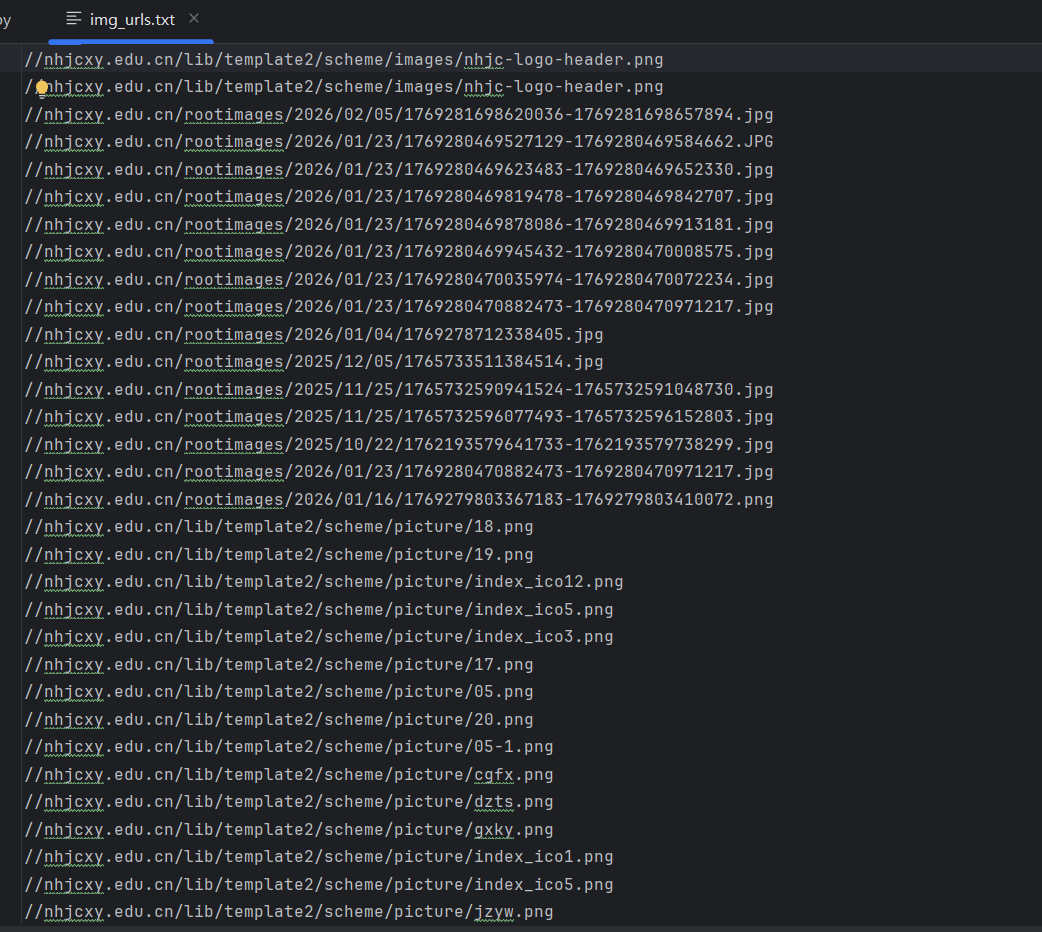
2.爬取学校官网,获取所有图片途径并将路径存储在本地文件中,使用装饰器完成
python
import requests
from bs4 import BeautifulSoup
import time
def log(f):
def w(url):
urls = f(url)
print(f'[{time.strftime("%Y-%m-%d %H:%M:%S")}] 共爬取{len(urls)}张图片')
return urls
return w
@log
def get_imgs(url):
try:
res = requests.get(url, headers={'User-Agent':'Mozilla/5.0'}, timeout=10)
soup = BeautifulSoup(res.text, 'html.parser')
imgs = [i.get('src') for i in soup.find_all('img') if i.get('src')]
with open('img_urls.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(imgs))
return imgs
except:
print('爬取失败')
return []
get_imgs('https://nhjcxy.edu.cn/')