博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
以Python语言为核心,基于Django框架开发,搭配MySQL数据库存储数据,运用协同过滤推荐算法、Echarts可视化工具,结合HTML搭建前端交互界面。
功能模块
- 电影数据可视化分析
- 用户好评占比和点赞前十用户评论分析
- 电影详情信息
- 电影热度排行榜
- 后台数据管理
- 注册登录界面
- 数据采集界面
项目介绍
本项目是基于Python语言、Django框架构建的豆瓣电影推荐系统,采用MySQL数据库存储豆瓣电影相关数据。系统借助协同过滤推荐算法分析用户行为与喜好,为用户提供个性化电影推荐;通过数据采集模块抓取电影数据,依托Echarts实现电影评分分布、影评热度等维度的可视化展示;同时配备注册登录、后台数据管理等功能,前端以HTML搭建交互界面,整体实现从数据采集、分析推荐到可视化展示的完整流程。
2、项目界面
(1)电影数据可视化分析
左侧导航栏含电影信息、推荐、排行榜等功能模块。页面展示电影相关词云图,呈现热门影片关键词;同时包含好评电影柱状图、评论评分占比饼图,可直观查看电影数据分布,辅助用户了解电影评价与热门趋势。
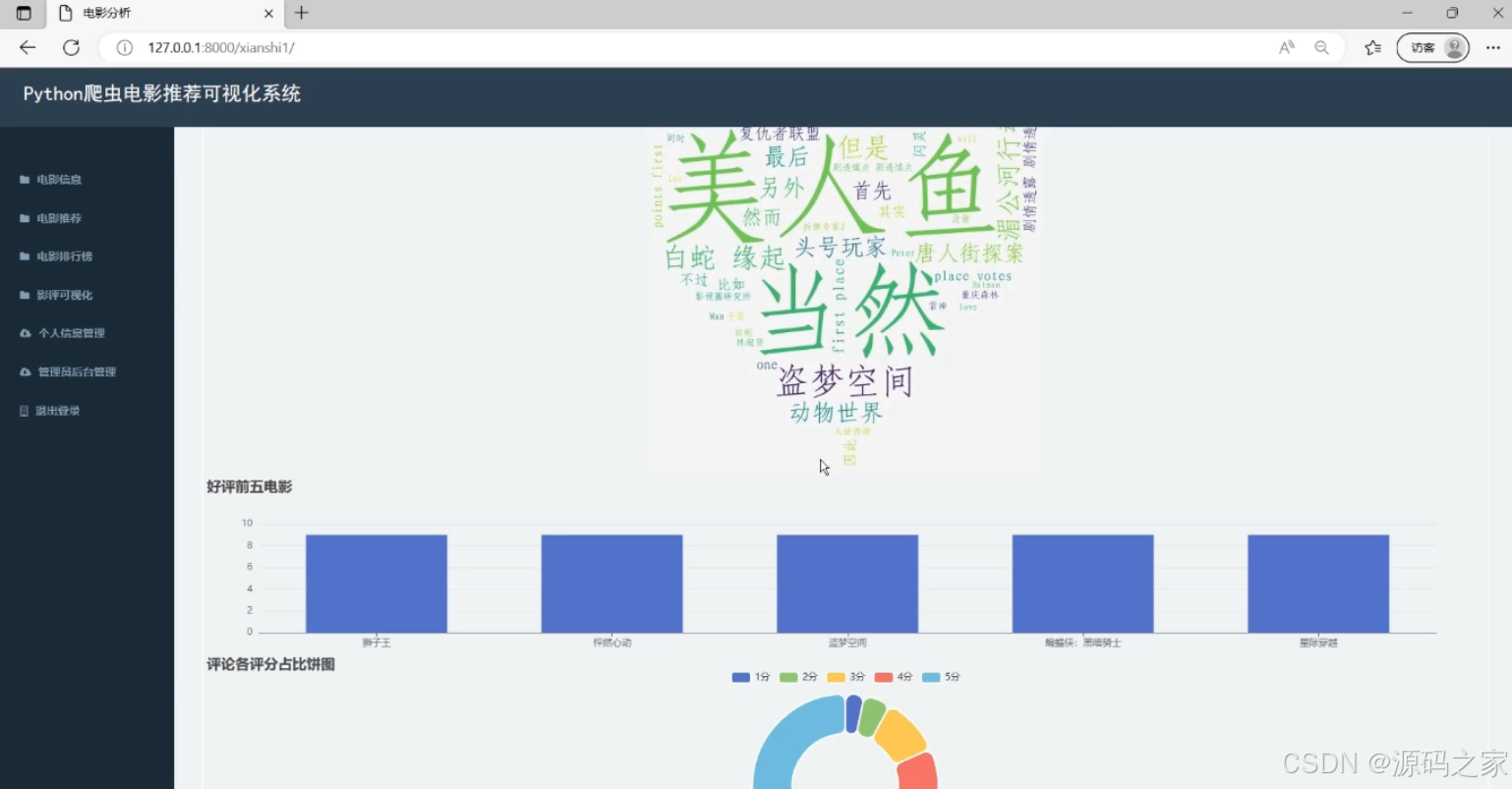
(2)用户好评占比和点赞前十用户评论分析
左侧导航栏涵盖电影信息、推荐等功能模块。页面展示电影相关词云图,呈现影片关联关键词;同时包含用户好评占比饼图,直观呈现评价分布;还有点赞数前十用户评论的柱状图,可查看高互动评论的用户数据,辅助分析影评热度与用户反馈。
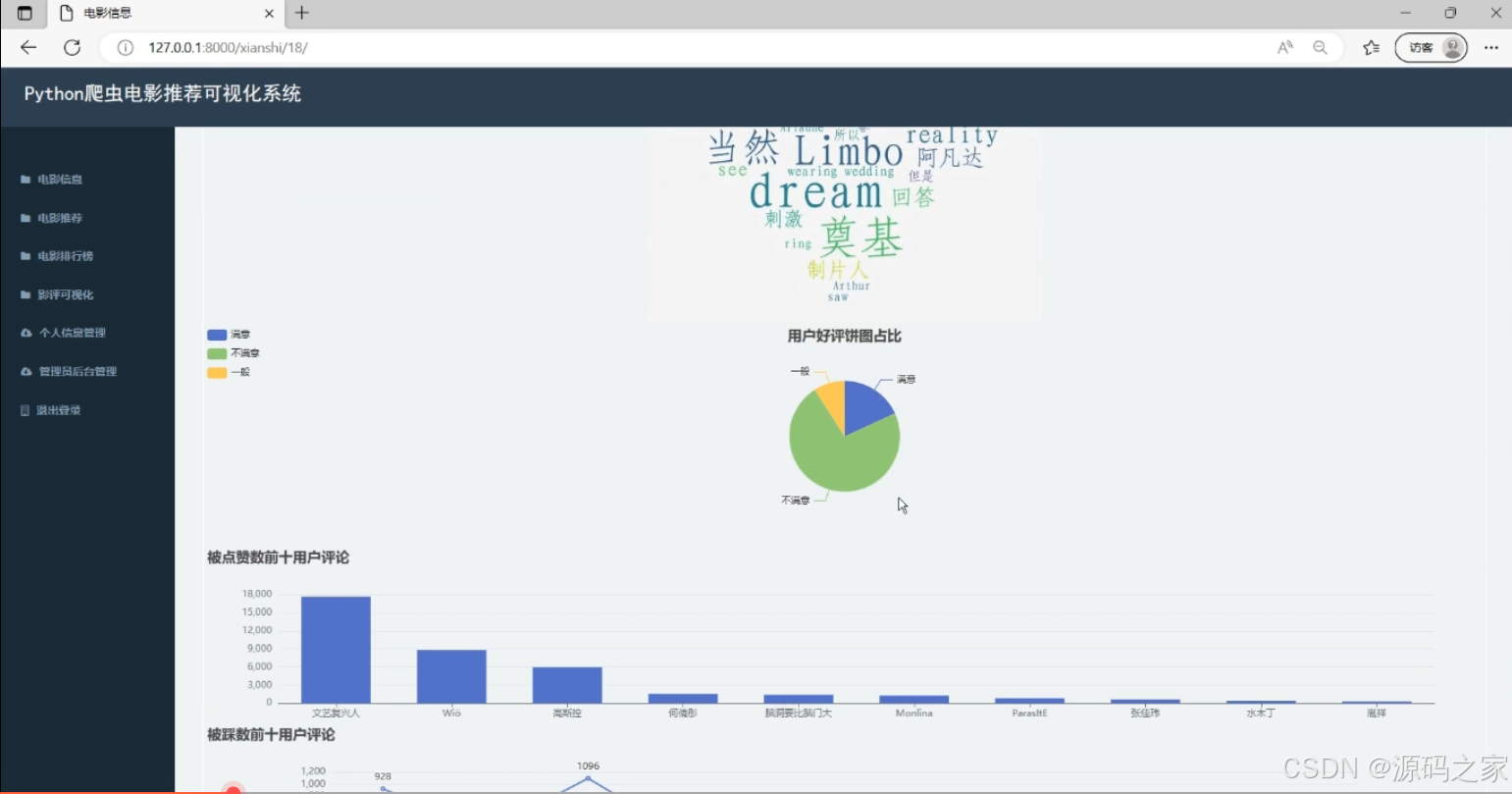
(3)电影详情信息
左侧导航栏包含电影信息、推荐等功能模块。页面展示单部电影的核心详情,包括导演、类型、上映时间等基础信息,搭配影片海报,同时呈现影评分析板块,展示用户评论内容及互动数据,支持查看影片的详细信息与用户反馈。
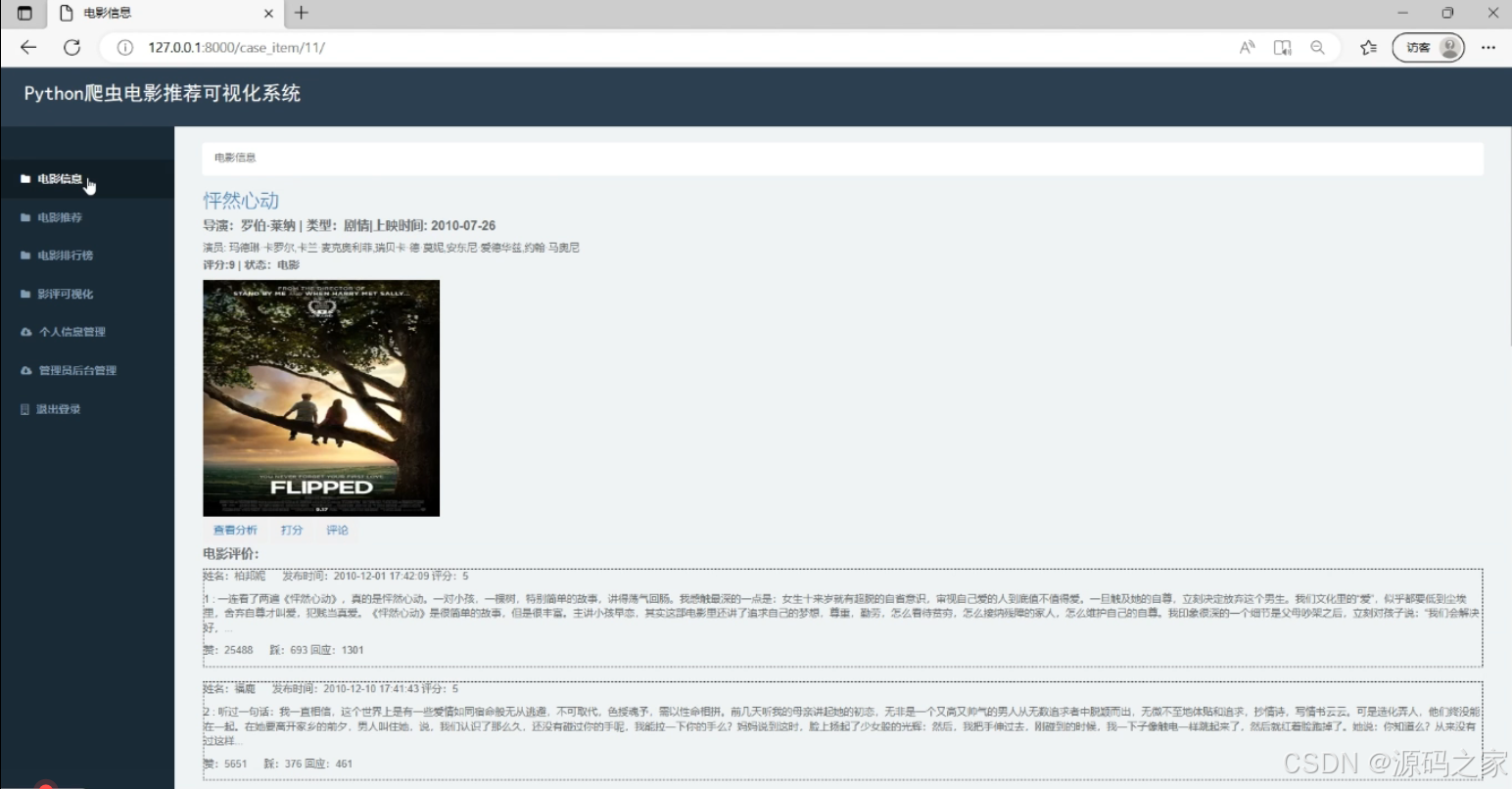
(4)电影热度排行榜
左侧导航栏涵盖电影信息、推荐等功能模块。页面展示电影热度排行榜单,以表格形式呈现影片的名称、评分、类型、上映时间、热度等信息,每部影片旁设有 "查看" 入口,支持点击查看对应电影的详细信息,便于用户了解热门影片的核心数据。
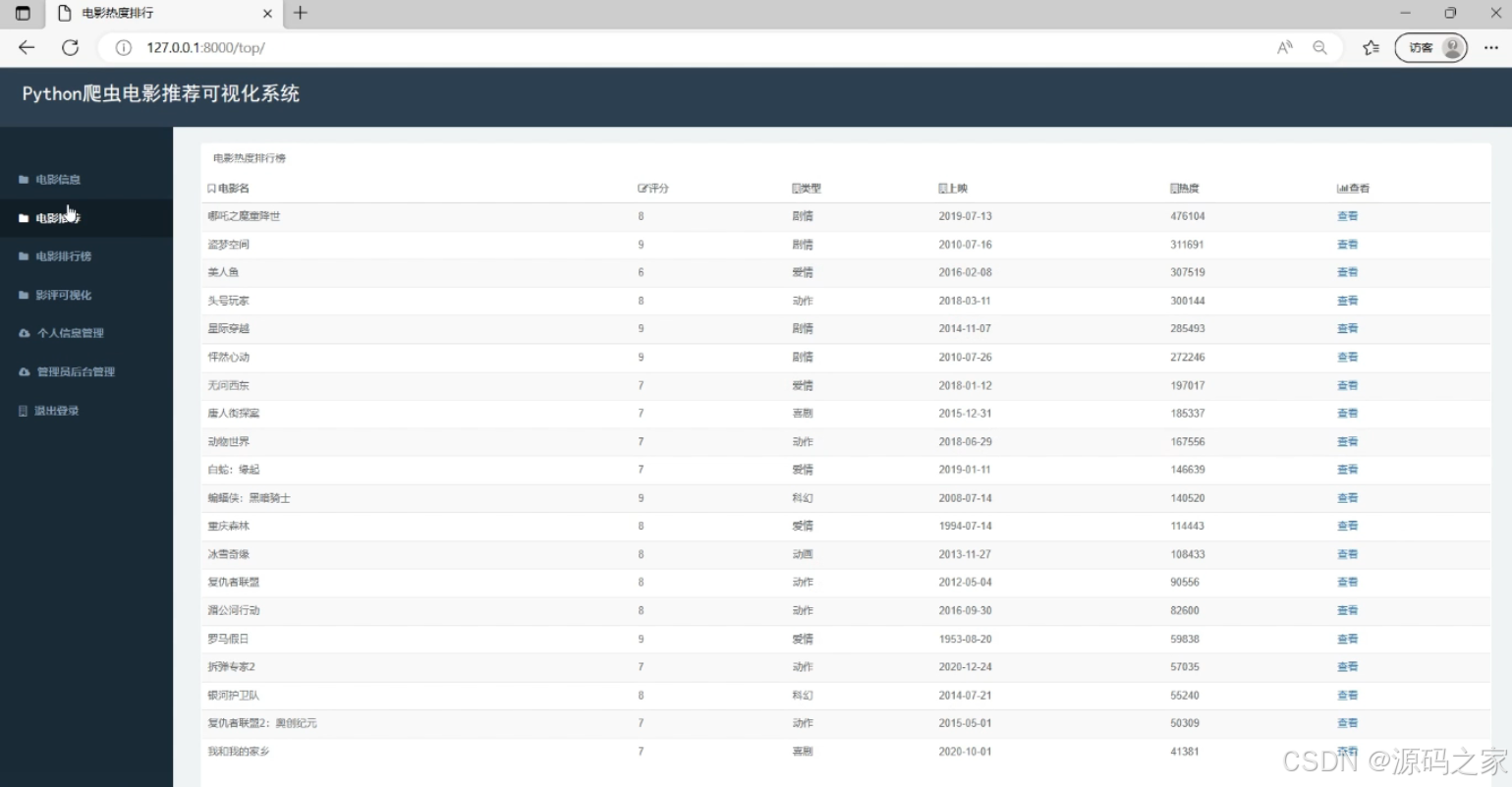
(5)后台数据管理
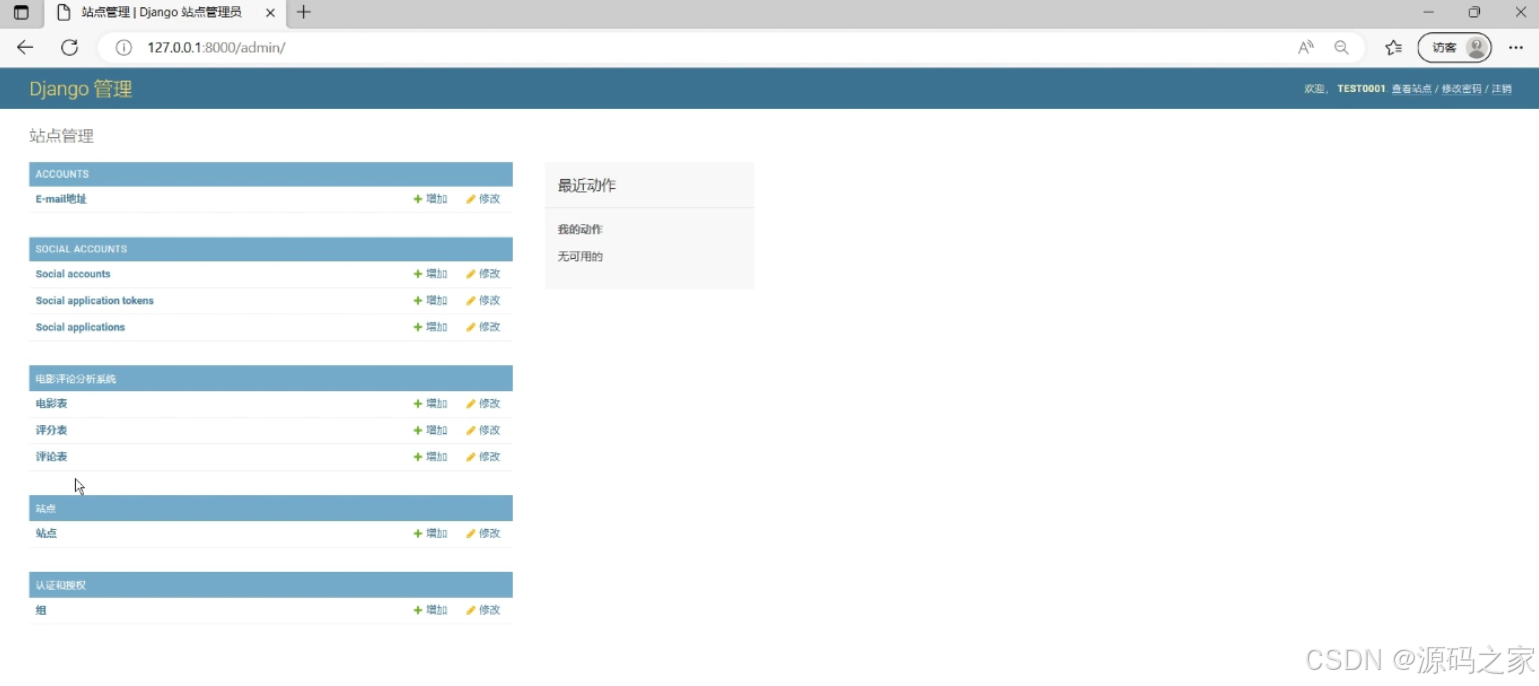
包含站点管理相关功能模块,分为多个分类板块:可管理账户、社交账号类信息,支持对电影评论分析系统的电影表、评分表、评论表等数据进行增加、修改操作,还能管理站点及认证授权相关内容,同时展示最近操作记录,是系统数据与功能的后台管理入口。
(6)注册登录界面
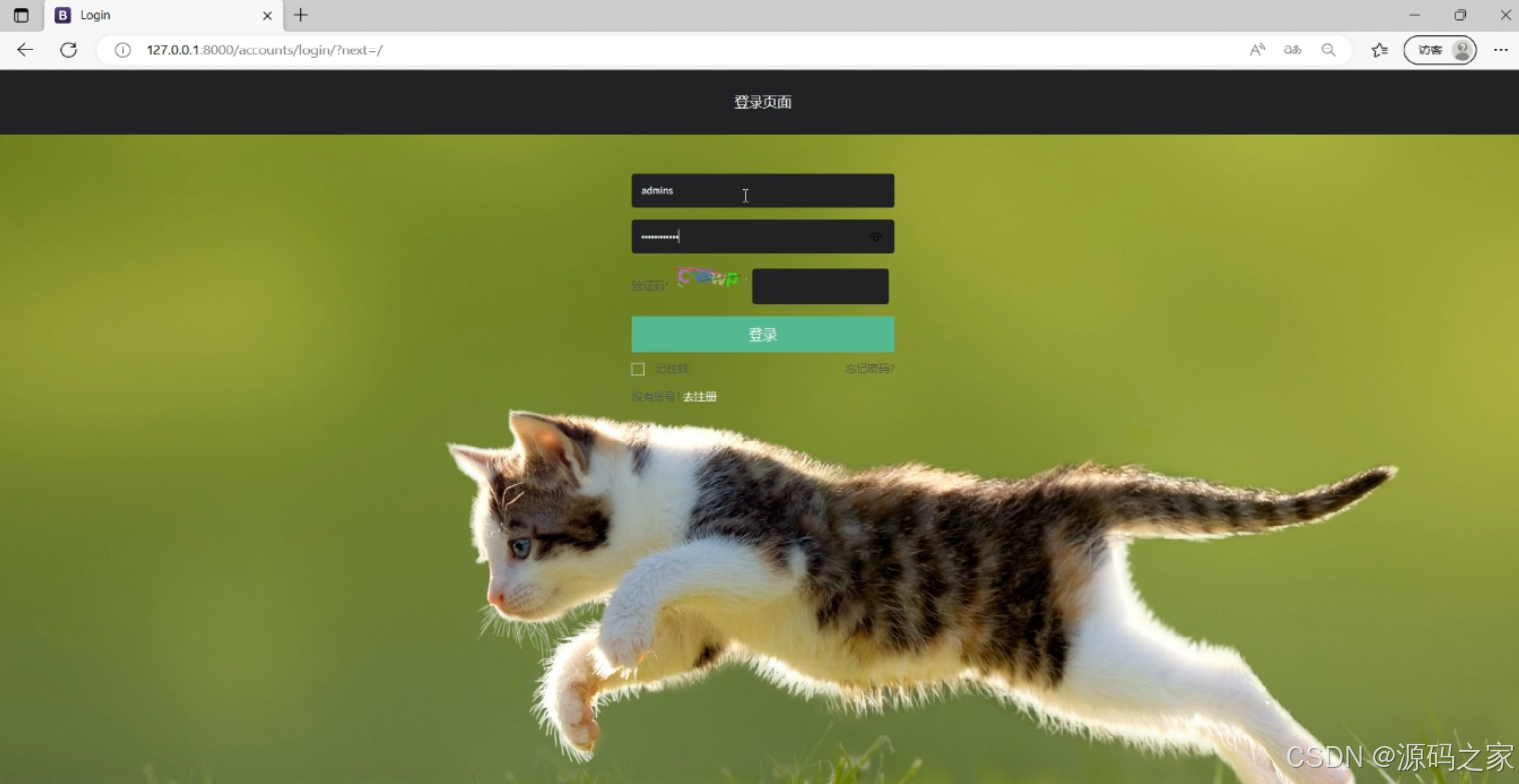
核心功能是支持用户登录操作:包含账号、密码输入框,验证码验证区域,以及 "登录" 按钮;同时提供 "记住我" 选项、"忘记密码" 找回入口,还有 "没有账号?去注册" 的跳转链接,是用户进入系统的身份验证入口,完成验证后可访问系统功能。
(7)数据采集界面
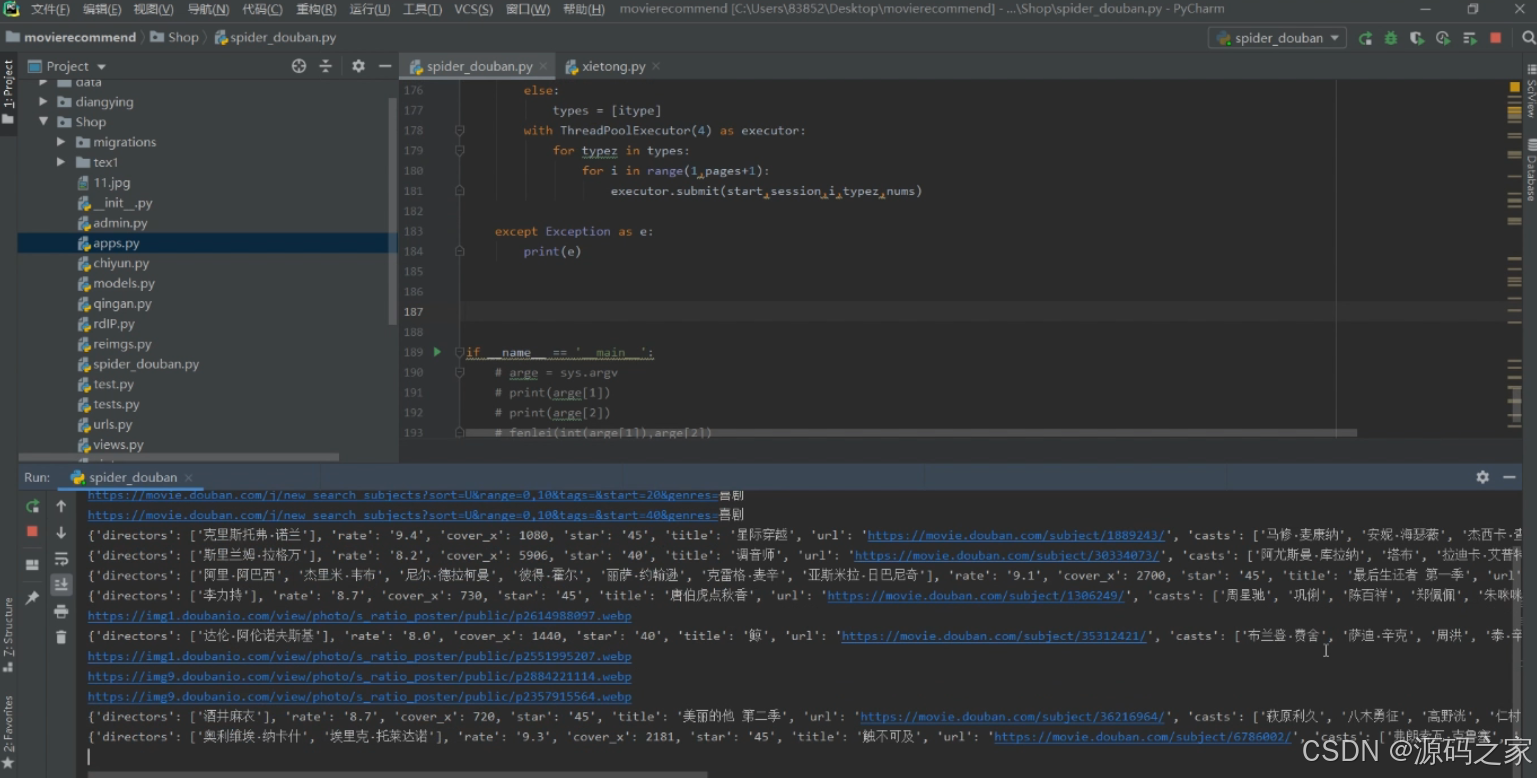
包含爬虫脚本文件,核心功能是通过代码实现数据采集:借助多线程等方式,定向抓取外部平台的电影数据(如导演、评分、标题等信息),同时对采集过程中的异常进行捕获处理,采集到的数据会结构化展示,为系统后续的分析、可视化等功能提供数据支撑。
3、项目说明
一、技术栈
本项目以Python语言为核心开发语言,基于Django框架搭建整体系统架构,采用MySQL数据库实现电影数据的持久化存储;引入协同过滤推荐算法分析用户行为偏好,借助Echarts可视化工具实现多维度数据图表展示,结合HTML完成前端交互界面的搭建,形成完整的技术体系。
二、功能模块详细介绍
- 电影数据可视化分析:左侧导航栏包含电影信息、推荐、排行榜等功能入口,页面展示电影相关词云图呈现热门关键词,搭配好评电影柱状图、评论评分占比饼图,直观呈现电影数据分布,帮助用户了解电影评价与热门趋势。
- 用户好评占比和点赞前十用户评论分析:左侧导航栏涵盖多核心功能模块入口,页面展示电影关联关键词词云图,同时呈现用户好评占比饼图、点赞数前十用户评论柱状图,辅助分析影评热度与用户反馈特征。
- 电影详情信息:左侧导航栏支持切换至电影信息、推荐等模块,页面展示单部电影的导演、类型、上映时间等核心详情及海报,搭配影评分析板块呈现用户评论与互动数据,支持查看影片完整信息与用户反馈。
- 电影热度排行榜:左侧导航栏包含多功能模块入口,页面以表格形式展示电影热度榜单,呈现影片名称、评分、类型、上映时间、热度等信息,每部影片配备"查看"入口,支持跳转查看详情。
- 后台数据管理:作为系统后台核心入口,包含多个分类管理板块,可管理账户、社交账号类信息,支持对电影表、评分表、评论表等数据进行增改操作,还能管理站点及认证授权内容,展示最近操作记录。
- 注册登录界面:作为系统身份验证入口,包含账号、密码输入框、验证码验证区域及登录按钮,提供"记住我""忘记密码"功能,配备注册跳转链接,验证通过后可访问系统全部功能。
- 数据采集界面:内置爬虫脚本文件,借助多线程技术定向抓取外部平台电影数据(导演、评分、标题等),捕获处理采集异常,结构化展示采集结果,为系统分析与可视化功能提供数据支撑。
三、项目总结
本豆瓣电影推荐系统围绕用户观影决策需求构建,基于Python+Django技术栈实现了从数据采集到分析推荐、可视化展示的完整流程。系统依托MySQL存储数据,通过协同过滤算法实现个性化推荐,借助Echarts完成多维度数据可视化呈现,同时配备完善的注册登录、后台数据管理功能。整体功能覆盖数据采集、分析、推荐、管理等核心环节,既通过可视化图表让用户直观了解电影数据特征,又能基于算法提供个性化推荐,兼顾用户体验与系统管理需求,具备较强的实用价值。
4、核心代码
python
from django.shortcuts import render,HttpResponse,redirect
from django.contrib.auth.decorators import login_required
from django.http import FileResponse
from django.shortcuts import get_object_or_404,HttpResponseRedirect
from . import models
from django.db.models import Q
from PIL import Image
import uuid
import os
import subprocess
from .xietong import UserCf
@login_required
def index(request):
if request.method == 'GET':
type = request.GET.get('type')
if type:
datas = models.Case_item.objects.all().order_by('-{}'.format(type))[:20]
else:
datas = models.Case_item.objects.all().order_by('-pingfen')[:20]
return render(request,'keshihua/index.html',locals())
if request.method == 'POST':
error = {}
data = request.POST
name = data.get('name', '')
if not name:
datas = models.Case_item.objects.all().order_by('-pingfen')[:20]
else:
datas = models.Case_item.objects.filter(name__icontains=name)
return render(request,'keshihua/index.html',locals())
@login_required
def tuijian(request):
if request.method == 'GET':
type = request.GET.get('type')
datas = models.Pinfen.objects.all()
dicts = {}
for data in datas:
if dicts.get(data.user.username, '') == '':
dicts[data.user.username] = {}
dicts[data.user.username][data.case.id] = data.fenshu
else:
dicts[data.user.username][data.case.id] = data.fenshu
userCf = UserCf(data=dicts)
r = userCf.recommend(request.user.username)
if not r:
if type:
datas = models.Case_item.objects.all().order_by('-{}'.format(type))[:10]
else:
datas = models.Case_item.objects.all()[::-1][:10]
else:
datas = []
for rs in r:
datas.append(get_object_or_404(models.Case_item, pk=rs[0]))
return render(request,'keshihua/tuijian.html',locals())
def itype_s(request,td):
if request.method=='GET':
list_data = models.Case_item.objects.filter(itype=td).order_by('-pingfen')
return render(request,'Shop/itypes_all.html',locals())
@login_required
def mydafen(request):
if request.method == 'GET':
list_data = []
datas = models.Pinfen.objects.filter(user=request.user)
return render(request, 'Shop/mydafen.html', locals())
#电影详细信息
import random
def case_item(request,id):
if request.method == 'GET':
data = get_object_or_404(models.Case_item,pk=id)
pingluns = []
datas = models.PinLun.objects.filter(case=data)
for da in datas:
pingluns.append(da)
return render(request,'keshihua/detailed.html',locals())
def renmen_item(request):
if request.method == 'GET':
return render(request,'Shop/fenxi1.html',locals())
def renmen_get(request):
path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) + os.sep + 'static' + os.sep + 'img'
pypath = os.path.dirname(os.path.abspath(__file__)) + os.sep + 'reimgs.py'
cmd = ['python',pypath,path]
aa = subprocess.Popen(cmd)
return HttpResponseRedirect('/renmen_item/')
@login_required
def xianshi(request,id):
if request.method == 'GET':
return render(request, 'keshihua/fram1.html', locals())
@login_required
def xianshi1(request):
if request.method == 'GET':
return render(request, 'keshihua/fram2.html', locals())
@login_required
def tubiao1(request):
if request.method == 'GET':
datas = models.Case_item.objects.all()
result1 = [{'name':data.name,'value':data.pingfen} for data in datas]
datas1 = sorted(result1, key=lambda st: st['value'], reverse=True)
print(datas1)
names = []
values = []
for data in datas1[:5]:
names.append(data.get('name'))
values.append(data.get('value'))
datas_ping = models.PinLun.objects.all()
datas2 = []
datas2.append({'value': len(datas_ping.filter(fenshu='1')), 'name': '1分'})
datas2.append({'value': len(datas_ping.filter(fenshu='2')), 'name': '2分'})
datas2.append({'value': len(datas_ping.filter(fenshu='3')), 'name': '3分'})
datas2.append({'value': len(datas_ping.filter(fenshu='4')), 'name': '4分'})
datas2.append({'value': len(datas_ping.filter(fenshu='5')), 'name': '5分'})
datas3 = [[data.zan,data.cai] for data in datas_ping ]
datas4 = [[data.zan, data.zheng] for data in datas_ping]
return render(request, 'keshihua/tubiao1.html', locals())
@login_required
def tubiao(request,id):
if request.method == 'GET':
case = get_object_or_404(models.Case_item,pk=id)
datas = models.PinLun.objects.filter(case=case)
zhen = 0
fu = 0
yiban = 0
for da in datas:
print(da.zheng)
print(da.fu)
if abs(da.zheng - da.fu) < 3 or abs(da.fu - da.zheng) < 3:
yiban += 1
elif da.zheng > da.fu:
zhen += 1
elif da.fu > da.zheng:
fu += 1
datas1 = [{'name':'满意','value':zhen},{'name':'不满意','value':fu},{'name':'一般','value':yiban}]
list1 = []
list2 = []
list3 = []
for da in datas[:10]:
list1.append(da.name)
list2.append(da.zan)
list3.append(da.cai)
datas3 = []
datas3.append({'value': len(datas.filter(fenshu='1')), 'name': '1'})
datas3.append({'value': len(datas.filter(fenshu='2')), 'name': '2'})
datas3.append({'value': len(datas.filter(fenshu='3')), 'name': '3'})
datas3.append({'value': len(datas.filter(fenshu='4')), 'name': '4'})
datas3.append({'value': len(datas.filter(fenshu='5')), 'name': '5'})
names = []
zans = []
cais = []
huiyings = []
for data in datas:
names.append(data.name)
zans.append(data.zan)
cais.append(data.cai)
huiyings.append(data.huiying)
return render(request, 'keshihua/tubiao.html', locals())
@login_required
def dafen(request,id):
if request.method == 'GET':
case = get_object_or_404(models.Case_item,pk=id)
data = models.Pinfen.objects.filter(Q(user=request.user) & Q(case=case))
return render(request, 'keshihua/dafen.html', locals())
elif request.method == 'POST':
case = get_object_or_404(models.Case_item, pk=id)
datas = request.POST
fenshu = datas.get('fenshu','-1')
if int(fenshu) > 5 or int(fenshu) < 0:
return HttpResponse(u'分数不规范')
if not models.Pinfen.objects.filter(Q(user=request.user)&Q(case=case)):
models.Pinfen.objects.create(
user=request.user,
case=case,
fenshu=fenshu
)
else:
models.Pinfen.objects.filter(Q(user=request.user) & Q(case=case)).update(
fenshu=fenshu
)
return redirect('Shop:case_item',id)
@login_required
def spiders(request):
if request.user.is_superuser:
if request.method == 'POST':
datas = request.POST
nums = datas.get('shuliang','0')
itype = datas.get('leixing','')
if itype == '':
itype = 'all'
path = os.path.dirname(os.path.abspath(__file__)) + os.sep + 'spider_douban.py'
cmd = 'python '+ path + ' ' + str(nums) + ' ' + itype
print(cmd)
subprocess.Popen(cmd,shell=True)
return HttpResponseRedirect("/")5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看 👇🏻获取联系方式👇🏻