前言
在之前学习当中,我们了解了被打开的文件是如何管理的;磁盘,以及ext2文件系统是如何存储文件的。
那我们要打开一个文件,首先要先找到这个文件,操作系统又是如何去查找的呢?
理解操作系统搜索文件
1. 目录和文件名
我们知道:
- 文件名是不作为文件属性存储在文件
inode里的; - 在一个分区中,根据文件的
inode值就可以找到该文件。
但是在之前的文件操作时,一种都是使用文件名进行对文件的相关操作,没有使用过文件inode值;
还用目录它是文件吗?
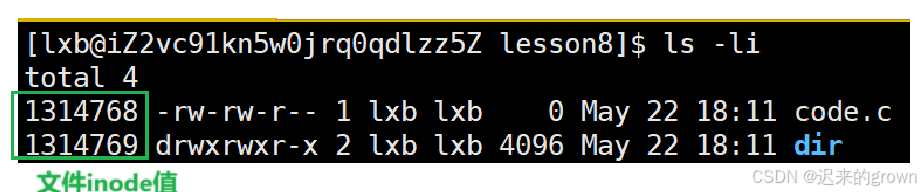
通过查看我们可以发现目录也是存在inode值的,那也就是说目录也是也文件;
文件 = 属性 + 内容,那目录的文件内容是什么呢?
首先属性不用多说;
目录文件的文件内容保存的是:文件名和
inode号的映射关系。
- 所以,访问文件时,必须打开当前工作目录,根据文件名获取对应的
inode号,然后进行文件访问。 - 所以,访问文件必须知道当前工作目录,本质就是必须打开当前工作目录文件,查看目录文件的内容获取要访问文件的
inode号。
2. 路径解析
知道了访问当前工作目录下文件,要打开当前目录文件,查看当前目录文件内容;
那要打开当前工作目录,就要获取当前工作目录文件的inode号啊,如何获得呢?
很简单,打开上级目录,查看上级目录文件内容;那上级目录也是文件啊,要打开它也要知道它的inode号,那也要打开它的上级目录啊?
所以就一直访问上级目录,直到/根目录。
所以说:实际上,任何文件都存在路径;
比如:
/home/lxb/linux/lesson8/code.c这都要从根目录开始一次打开每一个目录文件,依次访问每个目录下的指定目录直到
test.c文件(这个过程称之为Linux路径解析)
我们知道,访问文件本质就是进程去访问,在进程当中存在CWD当前工作路径;在我们open打卡指定文件时也给定了文件的路径。
所以我们访问文件必须要有目录+文件名(绝对路径)
3. 路径缓存
我们知道,文件都是在磁盘中存着的,那在Linux系统中存在真正的目录吗?
显而易见是不存在,只有文件;保存文件属性+内容。
在上述中,我们还了解到访问一个文件,都要从根目录/开始进行路径解析?
按道理来说是的,但是太慢了,在
Linux系统中会缓冲历史路径结构。
在Linux系统中,不存在目录,那在Linux系统中我们为什么可以看到目录路径结构?
打开的文件如果是目录,在系统中就在自己的内存中进行路径维护。
在Linux系统中,内核里维护树状路径结构的内核结构体叫做:struct dentry
c
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
/*The next three fields are touched by __d_lookup. Place them here
so they all fit in a cache line.
*/
struct hlist_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*d_child and d_rcu can share memory*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILING
struct dcookie_struct *d_cookie; /* cookie, if any */
#endif
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
- 每一个文件其实都有对应的
dentry结构,包含普通文件;所以被打开的文件,在内存中就可以形成树状结构。- 整个树形节点也会同时属于
LRU(Least Recently Used),在最近最少使用结构在,进行节点淘汰。- 同时也会属于
Hash表,方便快速查找。- 这样有了树状结构,整体就有了
Linux路径缓存结构,打开和访问任何文件,都先在该树下进行查找,找到了就返回inode和内容,没找到就从磁盘加载路径,添加到dentry结构中。
4. 挂载分区
在之前的描述中,都是在一个文件系统中,根据inode号查找文件,那inode号又不是跨分区的,如何根据inode确定是哪一个分区呢?
在分区写入文件系统后,我们没有办法直接使用;我们需要将文件系统与指定的目录进行关联(也就是挂载)才能使用
所以就可以根据我们访问目标文件的路径前缀来判断文件在哪一个分区。
这里关于挂载的相关操作,就不演示了;可以自己尝试一下。
软硬链接
1. 软链接
在Windows中,我们可以给一个文件创建快捷方式,然后放到桌面,这样打开桌面的快捷方式就是打开文件了;
而在Linux系统中,我们也可以给文件创建快捷方式------就是软链接
ln -s code code.c创建软链接文件code指向文件code.c;(可以说code文件是code.c的快捷方式)
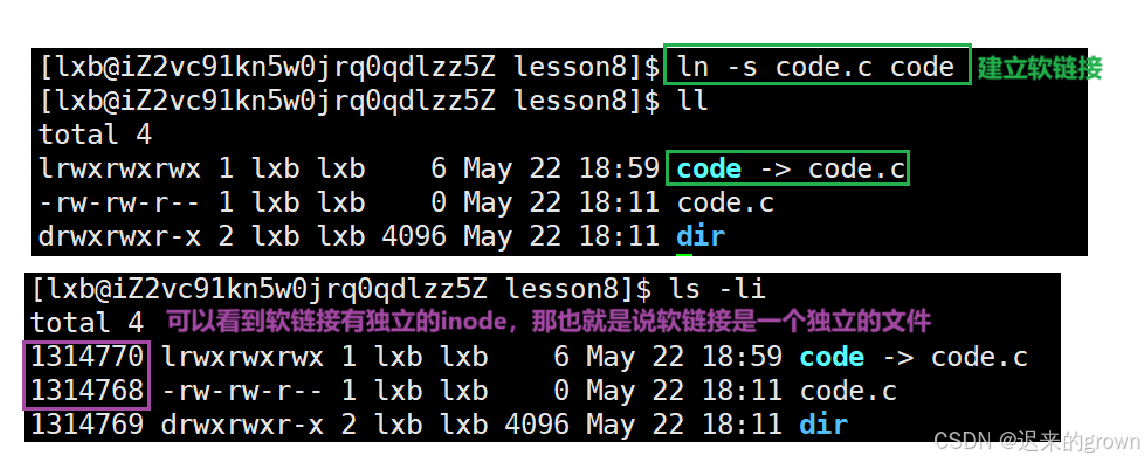
软链接是一个独立的文件
2. 硬链接
我们直到一个目录中,存在.和..两个隐藏文件,.指向当前目录,..指向上级目录;
那也就是说,这些文件名都对应一个inode值。
这里.和..就是典型的硬链接。
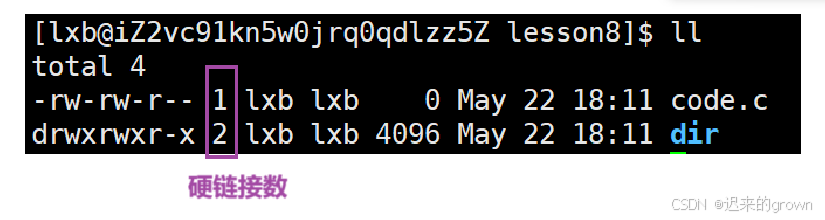
而在内核中,记录了连接数:
创建硬链接:
ln 已存在文件 硬链接文件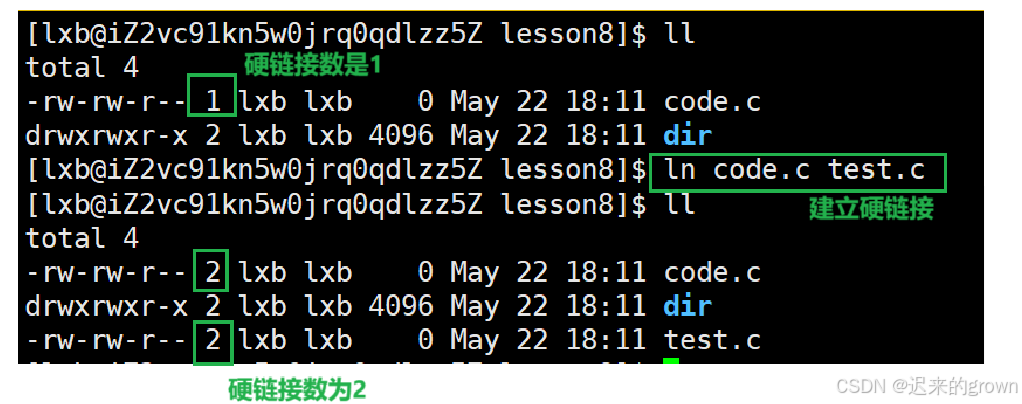
这里要注意,我们只能给文件创建硬链接,不能给目录创建硬链接。
这里可能会感觉很奇怪,
.和..不就是给目录创建硬链接吗?我们为什么不能创建?这里还是为了避免循环路径问题,在内核中在路径搜索时,对
.和..做了特殊处理,所以.和..不会造成循环路径问题;而软链接,它是一个独立的文件,在路径遍历时不会把他当做目录文件来处理。
如果我们自己创建硬链接,就有可能造成循环路径问题。
3. 软硬链接的区别
- 软链接是一个独立的文件
- 硬链接只是文件名和目标文件的一组映射关系
4. 软硬链接的作用
- 软链接就类似于快捷方式
- 硬链接
.和..,方便用户进程操作;文件备份。
到这里本篇文章内容就结束了,感谢各位大佬的支持