目录
[一 静态库](#一 静态库)
[1. 创建静态库](#1. 创建静态库)
[2. 使用静态库](#2. 使用静态库)
[2.1 第一种](#2.1 第一种)
[2.2 第二种](#2.2 第二种)
[二 动态库](#二 动态库)
[1. 创建动态库](#1. 创建动态库)
[2. 使用动态库](#2. 使用动态库)
[三 静态库 VS 动态库](#三 静态库 VS 动态库)
[四 动态库加载](#四 动态库加载)
[1. 可执行文件加载](#1. 可执行文件加载)
[2. 动态库加载](#2. 动态库加载)
一 静态库
Linux静态库:.a结尾
Windows静态库:.lib结尾
1. 创建静态库
bash
ar -xxx 形成的文件 目标文件
// r (replace) 存在则替换
// c (create) 不存在则创建2. 使用静态库
2.1 第一种
先生成 .o 文件
bash
g++/gcc -c 可执行文件构建静态库文件:把一个或多个.o文件打包
bash
ar -rc 形成的静态库文件 .o 文件把静态库文件放在系统默认的工作目录下,把头文件也放到系统默认的工作目录下。
然后
bash
gcc/g++ 可执行文件 -l 去掉前缀lib和后缀.a,只留下中间的字符串这种方式严重不推荐使用,因为系统存放的是官方提供的库,建议不要和第三方写的库混在一起。
示例:
cpp
// fun.cc
int add(int x,int y)
{
return x+y;
}
int sub(int x,int y)
{
return x-y;
}
cpp
// fun.hpp
int add(int x,int y);
int sub(int x,int y);
cpp
// test.cc
#include <iostream>
#include "fun.hpp"
int main()
{
std::cout<<add(10,20)<<std::endl;
std::cout<<sub(10,20)<<std::endl;
return 0;
}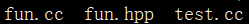
- 首先把方法形成点o文件。
g++ -c fun.cc 形成 fun.o
- 然后再把 fun.o 打包成静态库。
ar -rc libmyfun.a fun.o 形成 libmyfun.a
-
在把头文件 fun.hpp 放在系统默认的工作目录 /usr/include/
-
再把 libmyfun.a 放在系统默认的工作目录 /lib64/
-
最后一步把包含的头文件去掉双引号替换成尖括号,除了源文件,其他的可以删除了,因为已经拷贝到系统目录下了。
-
最后 g++ test.cc -l myfun 去掉 前缀 lib 和 .a 后缀。
2.2 第二种
前面是借用系统默认路劲来进行方便查找的,也可以自己指定头文件指定路劲和库文件指定路径。
cpp
gcc/g++ 可执行文件 -I 自己的头文件所在的目录 -L 自己的所在的目录 -l 库文件名 去掉前缀lib和后缀.a-
为什么库文件要指定名称,头文件不需要?因为头文件默认是在系统找,但你 -I 指定了路劲,就在指定的路劲下找,因为你已经包了头文件,所以就不需要指定头文件名了。
-
如果不用尖括号表示,就不在系统找,用双引号表示就需要包你的头文件处于当前目录的相对路径。
示例:
- 还是和上面一样把方法打包成静态库,在编译的时候进行 -I指定头文件路径,-L指定库文件路径,-l指定库文件名。


- 把源代码里面的尖括号去掉换成双引号也行
-I 和 双引号本质是一样的都是指定路径下找,但 -I不需要指名库文件名,源代码已经包含了,双引号要指名。
二 动态库
Linux静态库:.so结尾
Windows静态库:.dll结尾
1. 创建动态库
-
创建 .o 文件
gcc/g++ -fpic -o 文件名
-
创建动态库
gcc/g++ -shared .o文件 -o 形成的文件名 -> lib开头 .so结尾
2. 使用动态库
gcc/g++ 可执行文件名 -I 指定头文件路径 -L 指定方法路径 -l 指定方法名 去掉lib和.so生成的可执行文件直接运行会报链接错误,因为动态库是程序运行的时候进行连接,虽然gcc/g++能编过,因为指定了,但后续执行可执行文件,就是操作系统做的了,但操作系统不知道你是要动态查找库,所以要加选项,
第一种方法:
因为操作系统在运行时也会在系统默认的路径下查找动态库,所以直接把库名拷贝到这个路径下即可。
第二种方法:
与动态库进行软连接到系统目录下,本质和第一种是一样的。
第三种方法:
把动态库路径导入到环境变量中 LD_LIBRARY_PATH 但是是内存级的,或者直接修改用户家目录的隐藏文件 .bashrc ,给LD_LIBRARY_PATH配置动态库路径。
第四种方法:
在 /etc/ld.so.conf.d 这个目录下新建一个文件以.conf结尾,并写入动态库路径。
三 静态库 VS 动态库
如果同时有静态库和动态库,则优先连接动态库,除非加上 -static 选项表示全部静态连接,否则有动态库连接动态库,没有则连接静态库。
静态库是在连接的时候把库文件直接拷贝到源文件中,体积非常大,而动态库则是在运行的时候去查找库,体积小。
静态库,每个可执行文件都会拷贝一份,动态库所有程序在运行时共享。
静态库如果变更,则重新需要编译源代码,动态库只需要改变库方法里的实现即可。
四 动态库加载
1. 可执行文件加载
1.1 经过编译之后的文件
先来看看这个代码
cpp
#include <iostream>
int add(int x,int y)
{
return x+y;
}
int main()
{
add(1,2);
return 0;
}进行反汇编 objdump -d 可执行文件
cpp
1168 <Z3addii>:
| 1168: f3 0f 1e fa | endbr64 |
| 116c: 55 | push %rbp |
| 116d: 48 89 e5 | mov %rsp,%rbp |
| 1170: 89 7d fc | mov %edi,-0x4(%rbp) |
| 1173: 89 75 f8 | mov %esi,-0x8(%rbp) |
| 1176: 8b 55 fc | mov -0x4(%rbp),%edx |
| 1179: 8b 45 f8 | mov -0x8(%rbp),%eax |
| 117c: 01 d0 | add %edx,%eax |
| 117e: 5d | pop %rbp |
| 117f: c3 | ret |
1180 <main>:
| 1180: f3 0f 1e fa | endbr64 |
| 1184: 55 | push %rbp |
| 1185: 48 89 e5 | mov %rsp,%rbp |
| 1188: be 02 00 00 00 | mov $0x2,%esi |
| 118d: bf 01 00 00 00 | mov $0x1,%edi |
| 1192: e8 d1 ff ff ff | call 1168 <Z3addii> |
| 1197: b8 00 00 00 00 | mov $0x0,%eax |
| 119c: 5d | pop %rbp |
| 119d: c3 | ret |显然文件进行汇编之后是有地址的,也就是说文件没有没加载到内存,在磁盘上就已经有了地址了,定义的变量数据都被转换成地址了。
-
每个函数内部的地址都是相对于该函数的起始位置的偏移量,比如 1168 -> 1 ,-> 2 , -> 3,1加上1168就能访问到具体的语句,被称为相对编址,而上图没有采用,而是采用的绝对地址,1168 -> 116c,直接访问116c不需加上偏移量,被称为绝对编址,这种采用绝对编制范围 全0 ~ 全F,也可以说是逻辑地址(虚拟地址),这个文件里面的地址都是采用ELF格式进行编制的,有自己的固定格式。
-
虚拟地址空间可以划分各个不同的区域,文件经过编译后生成的汇编文件通过ELF格式划分出不同的各个区域,并通过加载器进行扫描,得出各个区域的起始和结束地址。
-
可执行文件加载
-
程序加载是先创建内核数据结构还是先加载可执行文件?
先创建内核数据结构,并构建虚拟地址空间(mm_struct),也就是一个结构体,每个区域开始和结束用start,end来标识,那么怎么初始化?
操作系统能直接分配代码段和数据段的虚拟地址吗?假设一个函数占10字节,一个占100字节,操作系统怎么知道?只有可执行文件自己知道。
通过读取磁盘上的文件,通过ELF+加载器得到每个区域的起始地址和结束地址,在由操作系统进行映射到虚拟地址空间代码段,所以虚拟地址空间不是操作系统独有的,是由:操作系统 + 可执行文件 + 加载器 + 编译器。
-
加载到内存
-
虚拟地址已经映射了可执行文件的各个区域的起始和结束地址了,但想运行程序,首先要找到main函数的起始地址,所以在可执行文件加载前通过加载器扫描每个区域,也能扫描到mian函数的起始地址,在放到CPU内部的PC寄存器里,表示当前执行的指令的下一跳地址。
-
加载前与给虚拟地址进行初始化代码段,数据段,加载到内存分配物理地址,并和原来初始化后的区域构建映射关系,通过页表,再有CPU执行PC指向的地址,进行页表查表到内存对应的程序。
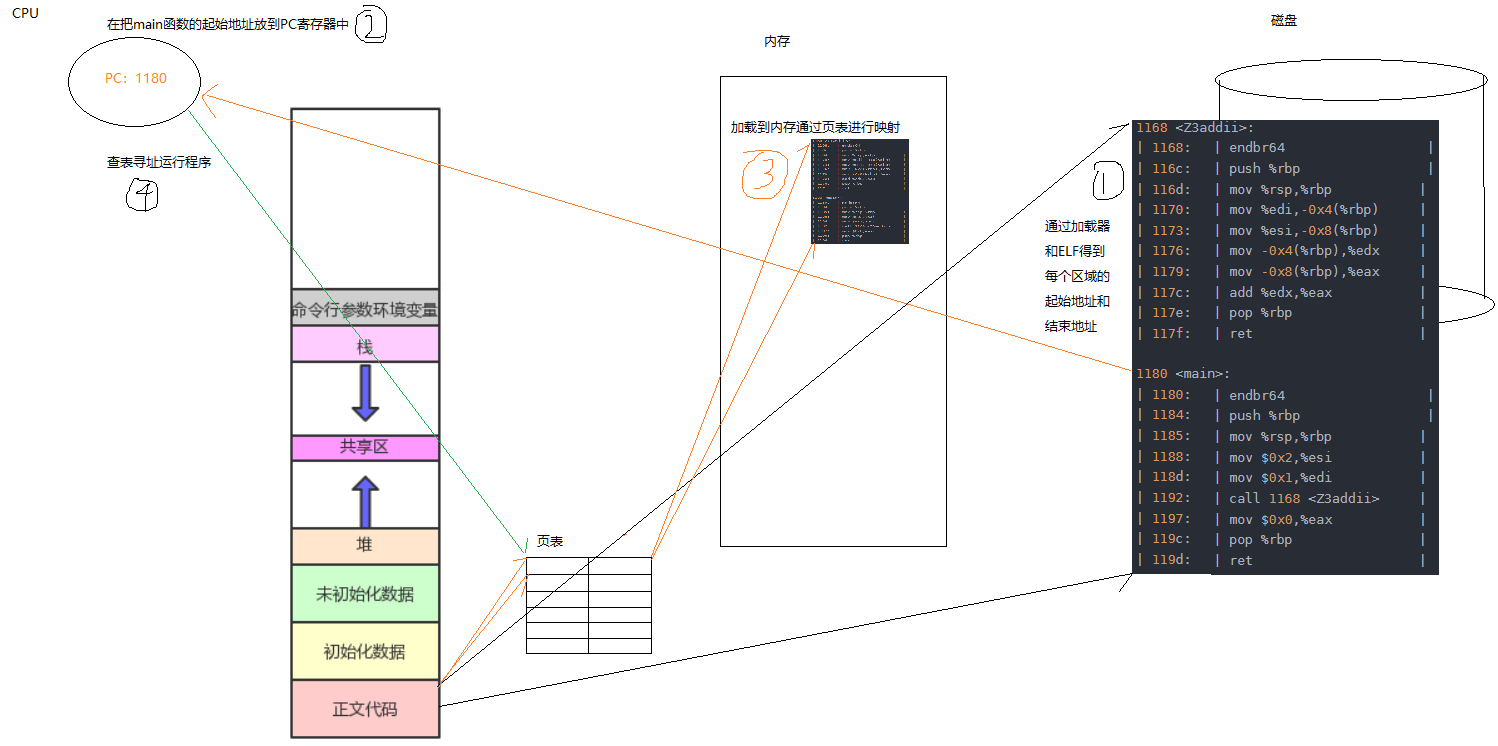
2. 动态库加载
- 上面说了可执行文件的加载,下面来看看动态库是如何加载和虚拟地址关联起来的。
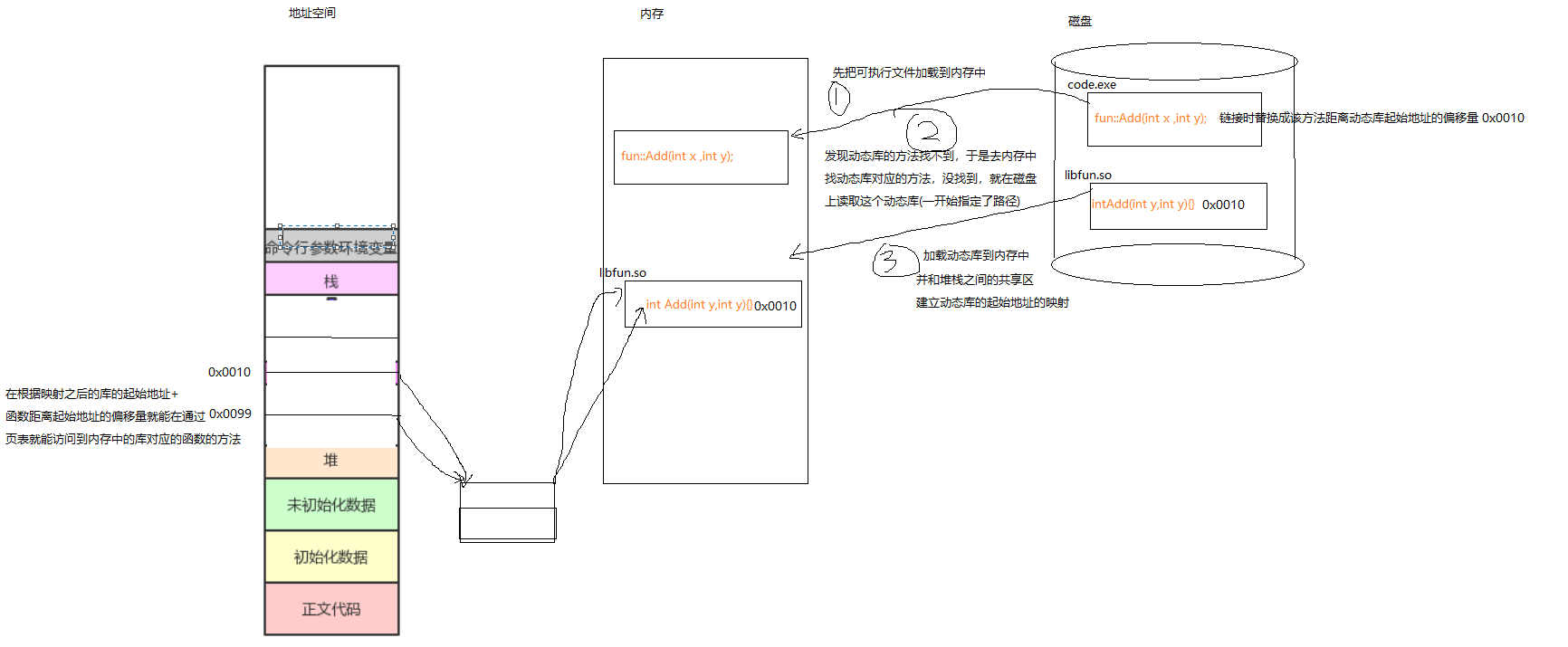
-
动态库加载和可执行文件加载类似,通过加载器扫描到每个区域的起始和结束地址,然后把库的起始地址映射到堆栈之间的共享区构建映射,在通过距离库的起始地址的偏移量+距离映射了的虚拟地址的偏移量,在通过查页表就能访问到内存中的方法了。
-
动态库加载到内存,他的地址是不变的,不管虚拟地址是否变化,最终映射到的库的起始地址是不变的。
-
内存中有很多动态库被使用,那么势必也需要维护起来,所以每个程序需要的动态库,首先去内存中进行查找,找不到就去查磁盘在加载到内存中。