目录
[1. 说明](#1. 说明)
[1.1 模型训练方式的选择](#1.1 模型训练方式的选择)
[1.2 训练流程](#1.2 训练流程)
[1.3 LLM与数据结合的方式](#1.3 LLM与数据结合的方式)
[2. 回归任务+时序模型训练实例](#2. 回归任务+时序模型训练实例)
[3. LLM的SFT(有监督微调)训练](#3. LLM的SFT(有监督微调)训练)
[3.1 环境准备](#3.1 环境准备)
[3.2 不同硬件环境下的训练](#3.2 不同硬件环境下的训练)
[A10 * 2卡下的训练](#A10 * 2卡下的训练)
[H20 * 1卡下的训练](#H20 * 1卡下的训练)
[4. RAG检索增强⽣成)应用](#4. RAG检索增强⽣成)应用)
[5. Ollama下的部署](#5. Ollama下的部署)
[模型格式转换(HuggingFace → GGUF)](#模型格式转换(HuggingFace → GGUF))
[部署脚本 ollama_deploy.sh](#部署脚本 ollama_deploy.sh)
[6. 名词解释](#6. 名词解释)
[7. 体会](#7. 体会)
1. 说明
1.1 模型训练方式的选择
这里不得不说我开始的时候走了弯路,实际上,如果你的目标是实现一个跟文本内容有关系的智能体(如让AI根据公司规章制度回复咨询问题),那么可以用RAG或SFT方式来实现。
但如果想做数值分析(比如:根据某只股票的行情数据做预测),那么用LLM训练出来的模型是不合适的,而应采用CNN神经网络模型训练方式,训练回归任务+时序模型。
1.2 训练流程
无论哪种训练方式,基本遵循这个流程图,定义相关的特征列,指定预测目标字段,不断调参,迭代训练结果:

1.3 LLM与数据结合的方式
RAG(检索增强⽣成)
- LLM+外挂知识库+提示词的应用模式,我的理解是:用户要一位老中医按指定医书开方煎药。
SFT(有监督微调)
- 不断用特定数据投喂LLM,直到它能按我的意思生成八九不离十的结果,从而形成一个定制LLM,我的理解是把一个智能体训练成一个老中医。
RLHF(强化学习)
- 大量的全量数据投喂,直到它能一本正经地胡说八道(当然也可能是言之有物),养成一个智能体。
适用场景
SFT:
适合:拥有⾮常充⾜的数据
能够直接提升模型的固有能⼒;⽆需依赖外部检索;
RAG:
适合:只有少量的数据;动态更新的数据
每次回答问题前需耗时检索知识库;回答质量依赖于检索系统的质量;
少量企业私有知识:最好SFT和 RAG 都做;资源不⾜时优先 RAG;
会动态更新的知识:RAG
⼤量垂直领域知识:SFT
硬件环境
| 机器 | 备注 |
|---|---|
| H20 * 1,16核(vCPU) 96 GiB 100 Mbps | 单卡 |
| NVIDIA A10 24G * 2 ,32核(vCPU) 128 GiB 100 Mbps | 双卡 |
软件环境
| 主要软件 | 版本 |
|---|---|
| OS | ubuntu22.04 LTS |
| huggingface-hub | 0.30.1 |
| peft | 0.14.0 |
| torch | 2.6.0 |
2. 回归任务+时序模型训练实例
Tips: 以下代码可直接粘贴到AI求解释
**需求:**根据历史特征点(如过去3小时),预测未来三小时的目标值。
首先,通过processor.py进行数据处理,把纵向的时序特征数据扩展到时间区间内的相关行,如:
|------|----------|----------|----------|-----|---|---|
| 原数据列 | 激活数_lag1 | 激活数_lag2 | 激活数_lag3 | ... | | |
| | 2 | 4 | 7 | | | |
| | | | | | | |
目的把数据"拉平",用于训练时序窗口数据。
import pandas as pd
import numpy as np
from pathlib import Path
import logging
from utils.helper import (
translate_features,
load_config,
setup_logging,
prepare_features,
)
config = load_config()
setup_logging(file="logs/processor.log")
logger = logging.getLogger(__name__)
def process_data():
"""修复配置访问和空值问题版本"""
try:
config = load_config()
logger.info("成功加载配置文件")
# 验证必要配置项
required_config = [
"data.raw_path",
"data.processed_path",
"data.time_col",
"data.group_cols",
"data.features",
"data.target",
"data.window_size",
"data.predict_steps",
]
for key in required_config:
if not _nested_get(config, key.split(".")):
raise ValueError(f"配置项缺失: {key}")
# 读取原始数据
raw_df = pd.read_csv(config["data"]["raw_path"])
logger.info(f"原始数据加载完成,共{len(raw_df)}行")
# 时间处理
time_col = config["data"]["time_col"]
raw_df[time_col] = pd.to_datetime(
raw_df[time_col].str.split(" - ").str[0],
format="%Y-%m-%d %H:%M",
errors="coerce",
)
raw_df = raw_df.dropna(subset=[time_col])
# 验证目标列存在
target_col = config["data"]["target"]
if target_col not in raw_df.columns:
raise KeyError(f"目标列 {target_col} 不存在于原始数据")
processed_dfs = []
group_cols = config["data"]["group_cols"]
window_size = config["data"]["window_size"]
predict_steps = config["data"]["predict_steps"]
cnt = 0
for (user_id, material_id), group in raw_df.groupby(group_cols):
group = group.sort_values(time_col)
required_min_rows = window_size + predict_steps
if len(group) < required_min_rows:
# logger.warning(
# f"分组 {user_id}-{material_id} 数据不足,需要至少 {required_min_rows} 行,当前为 {len(group)} 行,跳过处理。"
# )
continue
else:
cnt += 1
# 生成滞后特征
for feature in config["data"]["features"]:
for lag in range(1, window_size + 1):
lag_col = f"{feature}_lag{lag}"
group[lag_col] = group[feature].shift(lag)
# 生成目标列
target_col = config["data"]["target"]
for step in range(1, predict_steps + 1):
group[f"target_{step}"] = group[target_col].shift(-step)
# 清理无效数据(删除包含NaN的行)
group = group.dropna()
if not group.empty:
processed_dfs.append(group)
logger.info(f"处理完成 {user_id}-{material_id},剩余{len(group)}行")
logger.info(f"总共有{cnt}条合规数据")
if not processed_dfs:
raise ValueError("处理后的数据为空,请检查输入数据是否满足窗口要求。")
processed_df = pd.concat(processed_dfs)
processed_df.to_parquet(config["data"]["processed_path"])
logger.info(processed_df)
logger.info(f"数据处理完成,保存至 {config['data']['processed_path']}")
except Exception as e:
logger.error(f"数据处理失败: {str(e)}")
raise
def _nested_get(dct, keys):
"""安全获取嵌套配置项"""
for key in keys:
try:
dct = dct[key]
except (KeyError, TypeError):
return None
return dct
if __name__ == "__main__":
from utils.helper import setup_logging
setup_logging()
process_data()其次,通过以下训练代码产生三个预测模型,对应未来三个小时预测值,训练时输出MAE, RMSE,R2等误差指标进行监控。
import lightgbm as lgb
import pandas as pd
import joblib
import numpy as np
from sklearn.model_selection import ParameterGrid, TimeSeriesSplit
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from typing import Dict, List
import logging
from utils.helper import load_config, setup_logging
def train_model() -> Dict[int, List[lgb.Booster]]:
"""
训练多步预测模型并实时输出评估指标
返回: 字典{预测步数: [模型列表]}
"""
config = load_config()
logger = logging.getLogger(__name__)
df = pd.read_parquet(config["data"]["processed_path"])
window_size = config["data"]["window_size"]
feature_cols = [
f"{feat}_lag{lag}"
for feat in config["data"]["features"]
for lag in range(1, window_size + 1)
]
models = {}
for step in range(1, config["data"]["predict_steps"] + 1):
logger.info(f"Training model for prediction step {step}")
y = df[f"target_{step}"]
models[step] = []
# 使用时序交叉验证
tscv = TimeSeriesSplit(n_splits=10)
fold_metrics = []
for fold, (train_index, val_index) in enumerate(tscv.split(df)):
X_train, X_val = (
df.iloc[train_index][feature_cols],
df.iloc[val_index][feature_cols],
)
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
# 初始化模型
# model = lgb.LGBMRegressor(**config["model"]["params"])
param_grid = {
"num_leaves": [63, 127, 255],
"learning_rate": [0.01, 0.02, 0.05],
"lambda_l1": [0, 0.1, 0.2],
}
for params in ParameterGrid(param_grid):
model = lgb.LGBMRegressor(**{**config["model"]["params"], **params})
# 训练并验证
model.fit(
X_train,
y_train,
eval_set=[(X_val, y_val)],
eval_metric="rmse",
callbacks=[lgb.log_evaluation(period=10)],
)
# 计算验证指标
val_pred = model.predict(X_val)
mae = mean_absolute_error(y_val, val_pred)
rmse = np.sqrt(mean_squared_error(y_val, val_pred))
r2 = r2_score(y_val, val_pred)
fold_metrics.append((mae, rmse, r2))
logger.info(
f"Step {step} Fold {fold+1}: "
f"MAE={mae:.4f}, RMSE={rmse:.4f}, R2={r2:.4f}"
)
models[step].append(model)
# 保存最终模型
joblib.dump(
models[step][-1],
f"{config['model']['save_dir']}/{config['model']['name']}_{step}.pkl",
)
# 输出平均指标
avg_mae = np.mean([m[0] for m in fold_metrics])
avg_rmse = np.mean([m[1] for m in fold_metrics])
avg_r2 = np.mean([m[2] for m in fold_metrics])
logger.info(
f"Step {step} Average: "
f"MAE={avg_mae:.4f}, RMSE={avg_rmse:.4f}, R2={avg_r2:.4f}"
)
# 输出特征关联性
importance = pd.DataFrame(
{"feature": feature_cols, "importance": model.feature_importances_}
).sort_values("importance", ascending=False)
logger.info(f"Top 10 features for step {step}:")
logger.info(importance.head(10))
return models3. LLM的SFT(有监督微调)训练
3.1 环境准备
模型下载工具
# 安装模型下载工具
pip install modelscope
# 编辑~/.bashrc, 手动指定环境变量(模型存储路径),不然默认会存到~/.cache撑爆根盘
MODELSCOPE_CACHE=/data0/modelscope
# 下载所需基类模型
modelscope download --model deepseek-ai/deepseek-llm-7b-base -local_dir /data0/modelscope/models/deepseek-ai/deepseek-llm-7b-base
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B -local_dir /data0/modelscope/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B安装所需的系统库
安装 openmpi,以便支持mpi4py包
apt-get update && apt-get install infiniband-diags ibverbs-utils \
libibverbs-dev libfabric1 libfabric-dev libpsm2-dev -y
apt-get install openmpi-bin openmpi-common libopenmpi-dev libgtk2.0-dev
apt-get install librdmacm-dev libpsm2-dev安装所需的包
# 关键包安装
pip install torch torchvision torchaudio scikit-learn transformers datasets accelerate deepspeed bitsandbytes evaluate accuracy tensorboard
pip install --upgrade --no-cache-dir --no-deps unsloth
pip install mpi4py
pip install fastapi pydantic uvicorn pytest3.2 不同硬件环境下的训练
A10 * 2卡下的训练
命令:
deepspeed --num_gpus 2 --master_port 29501 train.pyH20 * 1卡下的训练
命令:
# 数据预处理
python main.py --phase process
# 模型训练(单卡)
python main.py --phase train
# 多卡训练(示例)
torchrun --nproc_per_node=2 main.py --phase train
# 模型评估
python main.py --phase eval
# 预测接口
python api/main.py训练中: 
模型评估:
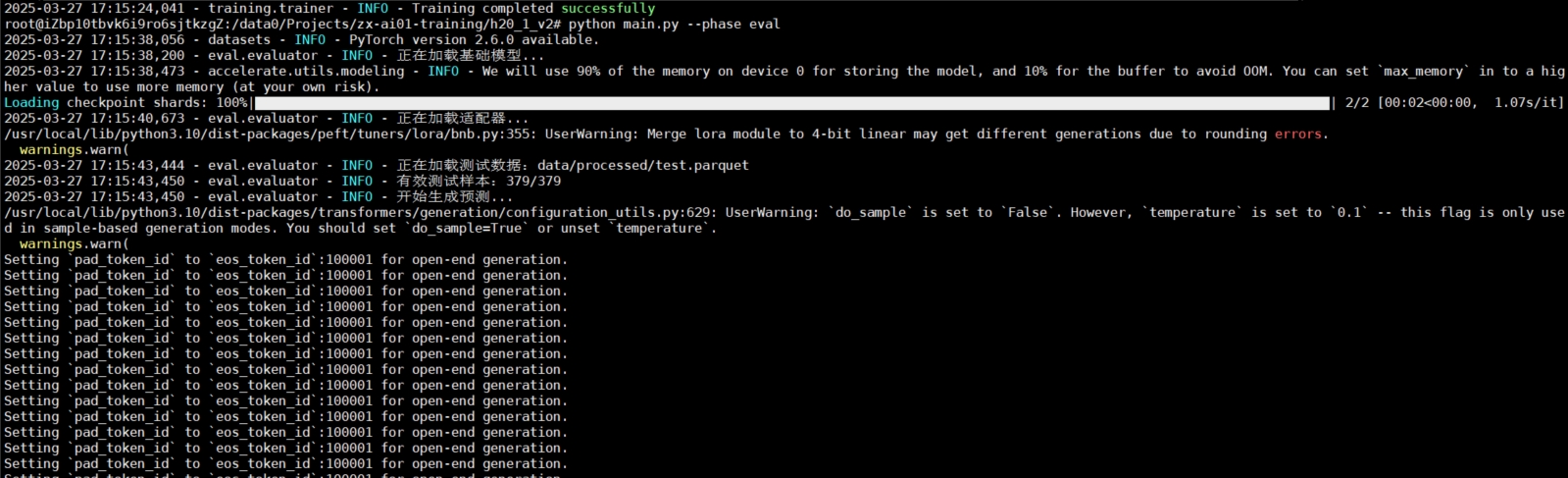
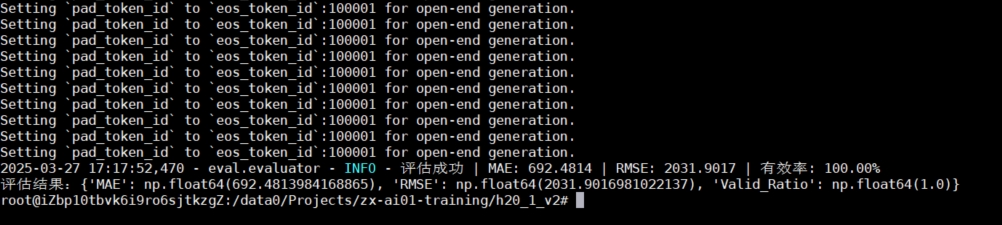
4. RAG检索增强⽣成)应用
- 以下是Dify v0.15.3 中的使用样例
LLM-SQL专家
-
置换用户问题为具体sql语句的描述
角色定义:
你是数据库专家,精通MySQL,能够根据用户提出的自然语言问题,自动生成相应的SQL查询语句。详细规则如下:
核心规则
- 仅使用提供的表和字段内容, 这部份内容放在
XML标签内。 - 确保SQL语句兼容MySQL
- 仅使用简体中文
- 仅输出单个完整的SQL语句,无注释
- 输出sql不要换行符号
- 查询输出限制10条内, 输出sql注意优化
数据库表结构
1. ads_summary(广告统计表) sqlCREATE TABLE `ads_summary` ( `id` int NOT NULL AUTO_INCREMENT COMMENT 'ads汇总表', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', `desc` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '文本', `account` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '用户', `label` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '标签', `star` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '点赞数量', `comment` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '评论数量', `collection` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '收藏数量', `share` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '分享数量', `create_time` timestamp NULL DEFAULT NULL COMMENT '数据抓取时间', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 190447 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = 'ads 统计数据表' ROW_FORMAT = Dynamic; </context> - 仅使用提供的表和字段内容, 这部份内容放在
LLM-数据分析专家
-
置换结果数据为表格输出的描述
角色定义:
你是专业的数据分析专家,负责解读MySQL数据库的查询结果{{#1740743643771.body#}}详细规则如下:
- 直接分析已提供数据,默认数据已满足查询条件
- 接受数据原貌,不质疑数据有效性
- 无需二次筛选或验证数据范围
- 空数据集统一回复"没有查询到相关数据"
- 避免使用提示性语言
- 分析结果以markdown格式输出
- 整理sql查询结果,以markdown表格格式输出放置输出开头
DeepSeek结果抓取
私有化部署的deepseek返回结果时,混杂着推理文本,需用代码执行组件过滤,只提取结果部份:
import re
import json
def main(content: str) -> dict:
json_start = content.find('{')
json_end = content.rfind('}') + 1
json_str = content[json_start:json_end]
data = json.loads(json_str)
if data and "steps" in data:
return {
"result": data["steps"],
}
else:
return []5. Ollama下的部署
说明:模型需进行合并和GGUF格式转换,方能在ollama下部署。
模型格式转换(HuggingFace → GGUF)
参考 https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
部署脚本 ollama_deploy.sh
#!/bin/bash
# 定义路径变量
BASE_PATH="/data0/Projects/zx-ai01-training"
MERGED_MODEL_PATH="${BASE_PATH}/h20_1_v2/data/merged_model"
OUTPUT_DIR="${BASE_PATH}/ollama/products"
GGUF_FILE="${OUTPUT_DIR}/deepseek-zx-sft-v1.0.0.gguf"
MODEL_NAME="deepseek-zx-sft-v1.0.0"
LLAMA_CPP_PATH="/root/llama.cpp"
# 创建输出目录(如果不存在)
mkdir -p "${OUTPUT_DIR}"
# 转换模型为 GGUF 格式
echo "正在将模型转换为 GGUF 格式..."
python3 "${LLAMA_CPP_PATH}/convert_hf_to_gguf.py" \
"${MERGED_MODEL_PATH}" \
--outfile "${GGUF_FILE}" \
--outtype f16 \
--model-name "${MODEL_NAME}"
if [ $? -ne 0 ]; then
echo "模型转换失败,请检查日志!"
exit 1
fi
# 创建 Modelfile
echo "正在创建 Modelfile..."
cat <<EOF >Modelfile
FROM ${GGUF_FILE}
PARAMETER temperature 0.1
PARAMETER num_ctx 4096
SYSTEM """
You are DeepSeek-R1, an AI assistant created by DeepSeek.
"""
EOF
# 部署到 Ollama
echo "正在部署模型到 Ollama..."
ollama create "${MODEL_NAME}" -f Modelfile
if [ $? -eq 0 ]; then
echo "部署完成!使用命令: ollama run ${MODEL_NAME} 启动对话"
else
echo "部署失败,请检查错误信息!"
exit 1
fi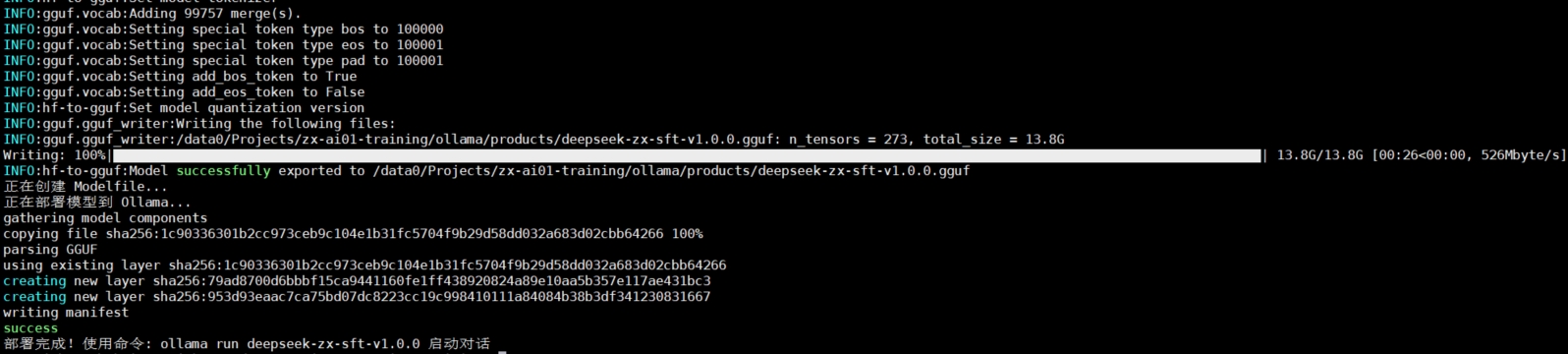
6. 名词解释
术语
| Word | Explain |
|---|---|
| Tensor | 张量 * 是一个定义在一些向量空间和一些对偶空间的笛卡尔积上的多重线性映射 * 在同构的意义下,第零阶张量 (r = 0) 为标量 (Scalar),第一阶张量 (r = 1) 为向量 (Vector), 第二阶张量 (r = 2) 则成为矩阵 (Matrix) |
| CoT (Chain of Thought) | 思维链 |
| RLHF(Reinforcement Learning from Human Feedback) | 强化学习 |
| SFT(Supervised Fine-Tuning) | 有监督微调 |
| RAG(Retrieval-Augmented Generation) | 检索增强⽣成 |
| LoRA (Low-Rank Adaptation of Large Language Model) | * 大语言模型微调 * 大语言模型的低阶适应 |
| MoE | 混合专家模型 |
| GRPO - group relative policy optimization | 组相对策略优化 |
| Distillation Techniques | 蒸馏技术 |
| Reasoning tasks | 推理任务 |
| CUDA - Compute Unified Device Architecture | * 统一计算设备架构 * NVIDIA创建的一个并行计算平台和编程模型 |
| cuDNN | 用于深度神经网络的GPU加速库 |
| nvidia-smi | NVIDIA System Management Interface 它是NVIDIA Management Library(NVML)构建的命令行工具 |
| OpenMPI | OpenMPI是一种高性能的消息传递库 |
| PEFT | (Parameter-Efficient Fine-Tuning)参数高效微调 |
| 超参数(hyperparameter) | 是指在机器学习模型训练前必须由开发者预先设定的参数,用于控制模型的结构、训练过程和性能。它们无法通过训练数据自动学习,而是需要手动调整或通过优化方法确定。 |
| CNN (Convolutional Neural Networks) | 卷积神经网络 每一层都提取上一层的特征,从而层层递进,目的提取到本质特征) |
Transformers上通用的模型类
(https://huggingface.co/docs/transformers/main/en/model_doc/auto)
模型评估指标
| 指标 | 名称 | 备注 |
|---|---|---|
| RMSE | 均方根误差 Root Mean Square Error | MSE加了个根号,这样数量级上比较直观,比如RMSE=10,可以认为回归效果相比真实值平均相差10 RMSE 越低,模型及其预测就越好。 |
| MSE | 均方误差 Mean Square Error | 均方误差将所有预测误差的平方求和,并取平均值,得到的结果就是该模型的均方误差。 一个好模型的 MSE 值接近于零。 |
| MAE | 平均绝对误差 Mean Absolute Error | 数学表达式为MAE = (1/n) Σ |yi -- xi|,其中n为样本数量,yi代表实际观测值,xi为预测值。计算过程分为三步:首先对每个样本的预测值与实际值求绝对差值,再将所有差值求和,最后除以样本总数得到平均值。 MAE越低,模型的准确性就越高。 |
| MAPE | 平均绝对百分误差 Mean Absolute Percentage Error | 平均绝对百分误差是对 MAE 改进后,通过计算真实值与预测的误差百分比避免了数据范围大小的影响。 MAPE 越小,模型性能越好。 |
| SMAPE | 对称平均绝对百分比误差Symmetric Mean Absolute Percentage Error | |
| R2 | R2_score 决定系数 | 反映因变量的全部变异能通过回归关系被自变量解释的比例。 R2_score = 1,样本中预测值和真实值完全相等,没有任何误差,表示回归分析中自变量对因变量的解释越好。 R2_score = 0。此时分子等于分母,样本的每项预测值都等于均值。 |
| SSE | 残差平方和 | 估计值与真实值的误差,反映模型拟合程度 |
特征相关性
- 机器学习模型的好坏取决于数据。这就是为什么数据科学家可以花费数小时对数据进行预处理和清理。他们只选择对结果模型的质量贡献最大的特征。这个过程称为"特征选择"。特征选择是选择能够使预测变量更加准确的属性,或者剔除那些不相关的、会降低模型精度和质量的属性的过程。
- 正相关:表示如果feature A增加,feature B也增加;如果feature A减少,feature B也减少。这两个特征是同步的,它们之间存在线性关系。
- 负相关(左)正相关(右)负相关:表示如果feature A增加,feature B减少,反之亦然。
- 无相关性:这两个属性之间没有关系。
相关的Python模块/包
| 包 | 备注 |
|---|---|
| unsloth | 这个包使得像Llama-3、Mistral、Phi-4和Gemma这样的大语言模型的微调速度提高2倍,内存使用减少70%,且不会降低准确性 |
| torch | 使用PyTorch进行深度学习的基础构建块。它提供了一个强大的张量库,类似于NumPy,但具有GPU加速的额外优势 |
| transformers | 是一个强大且流行的开源自然语言处理(NLP)库。它为广泛的最先进预训练模型提供了易于使用的接口。 要点: * compute_metrics 是 Transformers库中的一个重要函数,用于在模型训练或验证过程中计算和返回评估指标。这个函数通常在 Trainer 类的 validation_step 方法中被调用,用于评估模型的性能。 * Text, use a Tokenizer to convert text into a sequence of tokens, create a numerical representation of the tokens, and assemble them into tensors. * Speech and audio, use a Feature extractor to extract sequential features from audio waveforms and convert them into tensors. * Image inputs use a ImageProcessor to convert images into tensors. * Multimodal inputs, use a Processor to combine a tokenizer and a feature extractor or image processor. |
| deepspeed | https://www.deepspeed.ai/, 优化的模型训练工具,微软开源 |
| trl | 是一个专门用于transformer模型的强化学习(RL)库。它建立在Hugging Face的transformers库之上,利用其优势使transformer的RL更容易访问和高效。 |
GPU架构
1、Tesla架构
2006年,英伟达发布首个通用GPU计算架构Tesla。它采用全新的CUDA架构,支持使用C语言进行GPU编程,可以用于通用数据并行计算。Tesla架构具有128个流处理器,带宽高达86GB/s,标志着GPU开始从专用图形处理器转变为通用数据并行处理器。
2、Fermi架构
2009年,英伟达发布Fermi架构,是第一款采用40nm制程的GPU。Fermi架构带来了重大改进,包括引入L1/L2快速缓存、错误修复功能和 GPUDirect技术等。Fermi GTX 480拥有480个流处理器,带宽达到177.4GB/s,比Tesla架构提高了一倍以上,代表了GPU计算能力的提升。
3、Kepler架构
2012年,英伟达发布Kepler架构,采用28nm制程,是首个支持超级计算和双精度计算的GPU架构。Kepler GK110具有2880个流处理器和高达288GB/s的带宽,计算能力比Fermi架构提高3-4倍。Kepler架构的出现使GPU开始成为高性能计算的关注点。
4、Maxwell架构
2014年,英伟达发布Maxwell架构,采用28nm制程。Maxwell架构在功耗效率、计算密度上获得重大提升,一个流处理器拥有128个CUDA核心,而Kepler仅有64个。GM200具有3072个CUDA核心和336GB/s带宽,但功耗只有225W,计算密度是Kepler的两倍。Maxwell标志着GPU的节能计算时代到来。
5、Pascal架构
2016年,英伟达发布Pascal架构,采用16nm FinFETPlus制程,增强了GPU的能效比和计算密度。Pascal GP100具有3840个CUDA核心和732GB/s的显存带宽,但功耗只有300W,比Maxwell架构提高50%以上。Pascal架构使GPU可以进入更广泛的人工智能、汽车等新兴应用市场。
6、Volta架构
2017年,英伟达发布Volta架构,采用12nm FinFET制程。Volta 架构新增了张量核心,可以大大加速人工智能和深度学习的训练与推理。Volta GV100具有5120个CUDA 核心和900GB/s的带宽,加上640个张量核心,AI计算能力达到112 TFLOPS,比Pascal架构提高了近3倍。Volta的出现标志着AI成为GPU发展的新方向。
7、Turing架构
2018年,英伟达发布Turing 架构,采用12nm FinFET制程。Turing架构新增了Ray Tracing核心(RT Core),可硬件加速光线追踪运算。Turing TU102具有4608个CUDA核心、576个张量核心和72个RT核心,支持GPU光线追踪,代表了图形技术的新突破。同时,Turing架构在人工智能方面性能也有较大提升。
8、Ampere架构
2020年,英伟达发布Ampere架构,采用Samsung 8nm制程。Ampere GA100具有6912个CUDA核心、108个张量核心和hr个RT核心,比Turing架构提高约50%。Ampere 架构在人工智能、光线追踪和图形渲染等方面性能大幅跃升,功耗却只有400W,能效比显著提高。三大任务
回归任务:
回归任务的目标是预测连续值的输出。它试图建立一个数学模型来描述自变量和因变量之间的关系,并通过最小化误差的平方和来寻找数据的最佳函数匹配。例如,预测房价、温度或股票价格、商品推荐等。
分类任务:
分类算法通过对已知类别训练集的计算和分析,从中发现类别规则并预测新数据的类别。分类任务的目标是将输入数据分配到预定义的类别中。例如,垃圾邮件检测、图像识别或疾病诊断等。
生成任务:
生成任务通过学习数据集中的特征和标签之间的关系,从而能够生成新的数据样本。 不仅关注输入到输出的映射关系,还关注数据本身的分布和生成机制。例如,文本生成、图像生成、音乐生成等。
学习率 (Learning Rate): 控制每次迭代中模型参数更新的步长大小。
批量大小 (Batch Size): 每次更新模型参数时,输入数据被分成的样本数量。
网络层数 (Number of Layers): 模型中隐藏层的数量。
每层的神经元数量 (Number of Units per Layer): 每层中神经元的数量。
权重初始化 (Weight Initialization): 神经网络中所有权重参数的初始值设置。
正则化参数 (Regularization Parameters): 通过对模型参数进行约束来防止过拟合的技术。
7. 体会
- 人在开发工作中的角色彻底地转变了,从执行者变成产品/需求甲方,审查员,成品是代码。
- 没有AI辅助,开发工作很难高效进行,尤其涉及的面和细节太多时,靠传统的谷歌/百度查资料方式根本完成不了,以后离不开AI了...
- AI面前,生物人就是个傻子,很快人类会进入自我革新阶段,未来十几二十年,科技大爆发,陆续装上脑机芯片成为新物种时代。