需求分析
在 面试刷题平台 项目中,用户基于 MyBatis-Plus 的 QueryWrapper 构造动态查询条件,实现对题目的模糊匹配与多字段过滤。
| 字段名 | 对应数据库字段 | 条件构造方式 | 说明 |
|---|---|---|---|
searchText |
title、content |
.like("title", searchText).or().like("content", searchText) |
通用搜索,会在标题或内容里查关键字 |
title |
title |
like(StringUtils.isNotBlank(title), "title", title) |
单独查标题模糊匹配 |
content |
content |
like(StringUtils.isNotBlank(content), "content", content) |
单独查内容模糊匹配 |
answer |
answer |
like(StringUtils.isNotBlank(answer), "answer", answer) |
查题目答案模糊匹配 |
具体代码如下:
java
/**
* 从数据库中获取查询条件
*
* @param questionQueryRequest
* @return
*/
@Override
public QueryWrapper<Question> getQueryWrapper(QuestionQueryRequest questionQueryRequest) {
QueryWrapper<Question> queryWrapper = new QueryWrapper<>();
if (questionQueryRequest == null) {
return queryWrapper;
}
// todo 从对象中取值
Long id = questionQueryRequest.getId();
Long notId = questionQueryRequest.getNotId();
String title = questionQueryRequest.getTitle();
String content = questionQueryRequest.getContent();
String searchText = questionQueryRequest.getSearchText();
String sortField = questionQueryRequest.getSortField();
String sortOrder = questionQueryRequest.getSortOrder();
List<String> tagList = questionQueryRequest.getTags();
Long userId = questionQueryRequest.getUserId();
String answer = questionQueryRequest.getAnswer();
// todo 补充需要的查询条件
// 从多字段中搜索
if (StringUtils.isNotBlank(searchText)) {
// 需要拼接查询条件
queryWrapper.and(qw -> qw.like("title", searchText).or().like("content", searchText));
}
// 模糊查询
queryWrapper.like(StringUtils.isNotBlank(title), "title", title);
queryWrapper.like(StringUtils.isNotBlank(content), "content", content);
queryWrapper.like(StringUtils.isNotBlank(answer), "answer", answer);
// JSON 数组查询
if (CollUtil.isNotEmpty(tagList)) {
for (String tag : tagList) {
queryWrapper.like("tags", "\"" + tag + "\"");
}
}
// 精确查询
queryWrapper.ne(ObjectUtils.isNotEmpty(notId), "id", notId);
queryWrapper.eq(ObjectUtils.isNotEmpty(id), "id", id);
queryWrapper.eq(ObjectUtils.isNotEmpty(userId), "userId", userId);
// 排序规则
queryWrapper.orderBy(SqlUtils.validSortField(sortField),
sortOrder.equals(CommonConstant.SORT_ORDER_ASC),
sortField);
return queryWrapper;
}采用like模糊匹配的问题------案例
首先在搜索框中搜索 "CSS",能查询出两个相关的题目
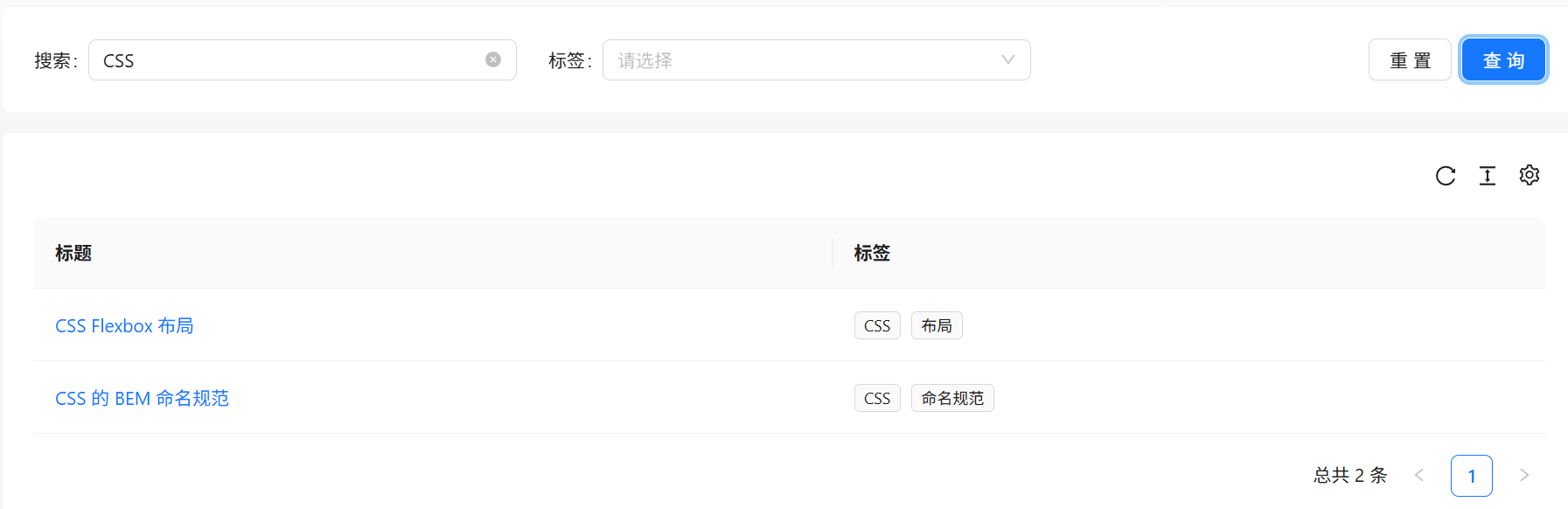
现在我想搜索标题中带有 "CSS" 和 "布局"这两个关键词,但是模糊匹配 like 显然不能满足我们的需求
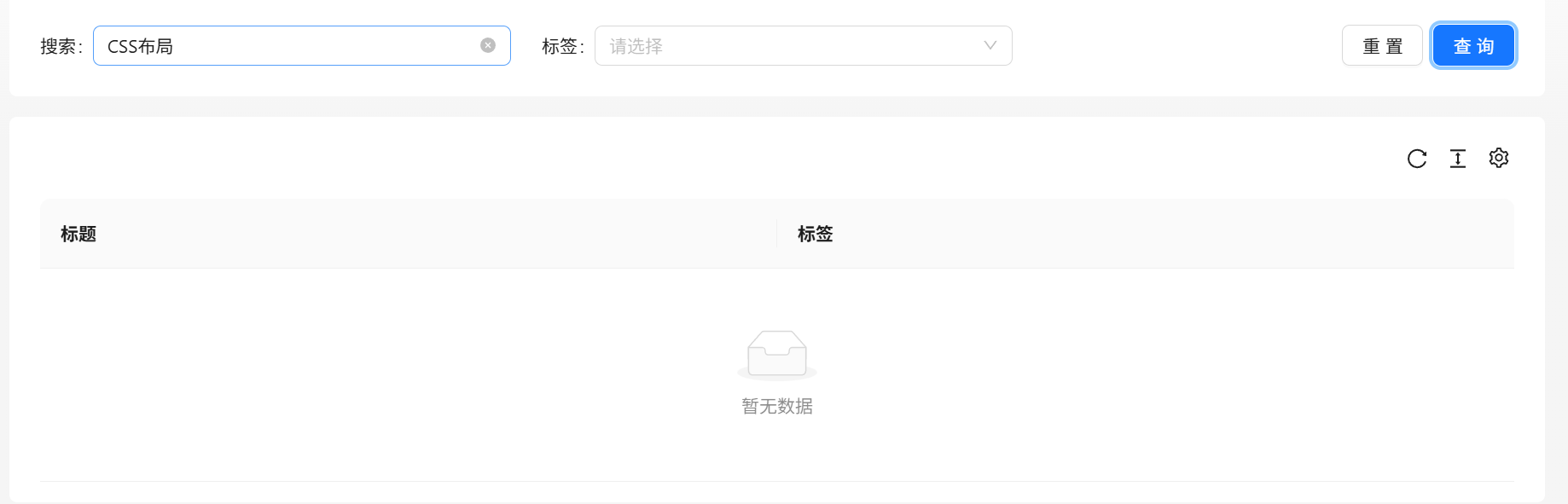
解决方案------采用Elasticsearch搜索
Elasticsearch简介
Elasticsearch 生态系统
Elasticsearch 生态系统非常丰富,包含了一系列工具和功能,帮助用户处理、分析和可视化数据,Elastic Stack 是其核心组成部分。
Elastic Stack(也称为 ELK Stack)由以下几部分组成:
- Elasticsearch:核心搜索引擎,负责存储、索引和搜索数据。
- Kibana:可视化平台,用于查询、分析和展示Elasticsearch 中的数据。
- Logstash:数据处理管道,负责数据收集、过滤、增强和传输到 Elasticsearch。
- Beats:轻量级的数据传输工具,收集和发送数据到 Logstash 或 Elasticsearch。
Elasticsearch 的核心概念
索引(Index):类似于关系型数据库中的表,索引是数据存储和搜索的 基本单位。每个索引可以存储多条文档数据。
文档(Document):索引中的每条记录,类似于数据库中的行。文档以 JSON 格式存储。
字段(Field):文档中的每个键值对,类似于数据库中的列。
映射(Mapping):用于定义 Elasticsearch 索引中文档字段的数据类型及其处理方式,类似于关系型数据库中的 Schema 表结构,帮助控制字段的存储、索引和查询行为。
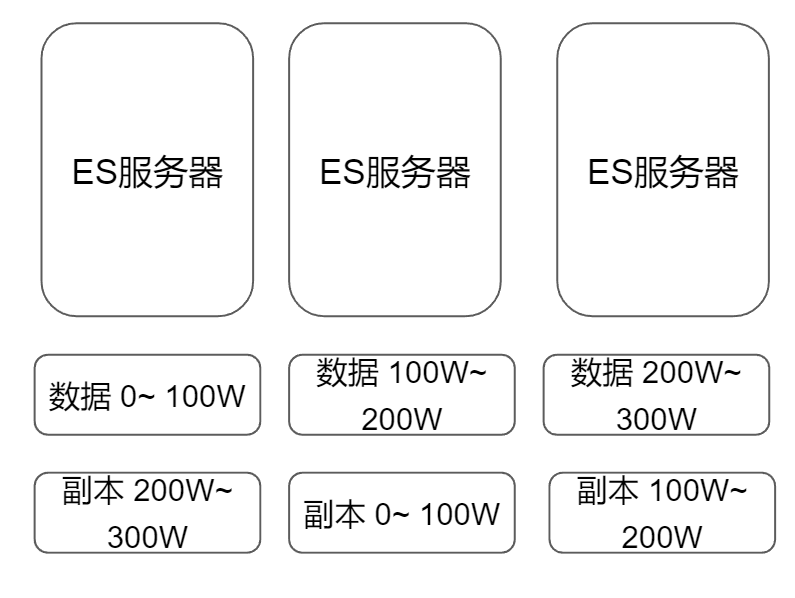
集群(Cluster):多个节点组成的群集,用于存储数据并提供搜索功能。集群中的每个节点都可以处理数据。
分片(Shard):为了实现横向扩展,ES 将索引拆分成多个分片,每个分片可以分布在不同节点上。
副本(Replica):分片的复制品,用于提高可用性和容错性,如图所示:
Elasticsearch 实现全文检索的原理
分词:Elasticsearch 的分词器会将输入文本拆解成独立的词条(tokens),方便进行索引和搜索。分词的具体过程包括以下几步:
- 字符过滤:去除特殊字符、HTML 标签或进行其他文本清理。
- 分词:根据指定的分词器(analyzer),将文本按规则拆分成一个个词条。例如,英文可以按空格拆分,中文使用专门的分词器处理。
- 词汇过滤:对分词结果进行过滤,如去掉停用词(常见但无意义的词,如 "the"、"is" 等)或进行词形归并(如将动词变为原形)。
倒排索引:倒排索引是 Elasticsearch 实现高效搜索的核心数据结构。它将文档中的词条映射到文档 ID,实现快速查找。
工作原理:
- 每个文档在被索引时,分词器会将文档内容拆解为多个词条。
- 然后,Elasticsearch为每个词条生成一个倒排索引,记录该词条在哪些文档中出现。
还有打分规则,可以查看官方文档,这里不做详细介绍。
查询条件
重点了解:
- 精确匹配 vs. 全文检索:term 是精确匹配,不分词;match 用于全文检索,会对查询词进行分词。
- 组合查询:bool查询可以灵活组合多个条件,适用于复杂的查询需求。
- 模糊查询:fuzzy 和 wildcard提供了灵活的模糊匹配方式,适用于拼写错误或不完全匹配的场景
数据同步方案
一般情况下,如果做查询搜索功能,使用 ES 来模糊搜索,但是数据是存放在数据库 MySQL 里的,所以说我们需要把 MySQL 中的数据和 ES 进行同步,保证数据一致(以 MySQL 为主)。
数据流向:MySQL => ES (单向)
数据同步一般有 2 个过程:全量同步(首次)+ 增量同步(新数据)
对于本项目,由于数据量不大,题目更新也不频繁,容忍丢失和不一致,所以定时任务方案,实现成本最低。
定时任务:比如 1 分钟 1 次,找到 MySQL 中过去几分钟内(至少是定时周期的 2 倍)发生改变的数据,然后更新到 ES。
实操案例
设计 ES 索引
为了将 MySQL 题目表数据导入到 Elasticsearch 中并实现分词搜索,需要为 ES 索引定义 mapping。ES 的 mapping 用于定义字段的类型、分词器及其索引方式。
相当于数据库的建表,数据库建表时我们要考虑索引,同样 Elasticsearch 建立索引时,要考虑到字段选取、分词器、字段格式等问题。
完整命令如下:
java
PUT /question_v1
{
"aliases": {
"question": {}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"tags": {
"type": "keyword"
},
"answer": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"userId": {
"type": "long"
},
"editTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"updateTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"isDelete": {
"type": "keyword"
}
}
}
}具体而言:
首先在 ES 中新建一个名为 question_v1 的索引;
- 零停机切换索引:在更新索引或重新索引数据时,你可以创建一个新索引并使用 alias切换到新索引,而不需要修改客户端查询代码,避免停机或中断服务。
- 简化查询:通过alias,可以使用一个统一的名称进行查询,而不需要记住具体的索引名称(尤其当索引有版本号或时间戳时)。
- 索引分组:alias可以指向多个索引,方便对多个索引进行联合查询,例如用于跨时间段的日志查询或数据归档。
什么是零停机切换?👇
| 版本 | 真正索引名 | 别名 alias |
|---|---|---|
| 第一次上线 | question_v1 |
question |
| 第二次优化 | question_v2 |
question ← 只改了别名指向就完成了迁移 |
mapping 规则设置
1、title:字段定义为 text 类型,用于存储较长的、需要全文搜索的内容。由于会有中文内容,所以使用了 IK 中文分词器进行分词处理,以提高查询的灵活性和匹配度。
- analyzer: ik_max_word:用于索引时进行最大粒度的分词,生成较多词语,适合在查询时提高召回率。
- search_analyzer: ik_smart:用于搜索时进行较智能的分词,生成较少的词语,通常用于提高搜索精度。
title.keyword:为 title 字段增加了一个子字段 keyword,用于存储未分词的标题,支持精确匹配。它还配置了 ignore_above: 256,表示如果 title 字段的长度超过 256 个字符,将不会为 keyword 字段进行索引。因为题目的标题一般不会很长,很少会对过长的标题进行精确匹配,所以用这一设置来避免过长文本导致的性能问题。
2、content:字段定义为 text 类型,索引时用 ik_max_word 分词器,把文本切得很碎,提高召回率;搜索时用 ik_smart 分词器,更加智能地匹配词,提高准确率
3、tags:标签通常是预定义的、用于分类或标签筛选的关键字,通常不需要分词。设置为 keyword 类型以便支持精确匹配和聚合操作
4、answer:字段定义为 text 类型,索引时用 ik_max_word 分词器,把文本切得很碎,提高召回率;搜索时用 ik_smart 分词器,更加智能地匹配词,提高准确率
5、userId:用来唯一标识用户的数值字段。在 Elasticsearch 中,数值类型(如 long)非常适合用于精确查询、排序和范围过滤。与字符串相比,数值类型的查询和存储效率更高,尤其是对于大量用户数据的查询。
6、editTime、createTime、updateTime:时间字段被定义为 date 类型,并指定了格式 "yyyy-MM-dd HH:mm:ss"。这样做的好处是 Elasticsearch 可以基于这些字段进行时间范围查询、排序和聚合操作,如按时间过滤或统计某时间段的数据。
日期为什么要格式化?
- 一致性:定义日期字段的格式可以确保所有插入的日期数据都是一致的,避免因不同的日期格式导致解析错误。例如,Elasticsearch默认可以支持多种日期格式,但如果不定义明确的格式,可能会导致不一致的日期解析。
- 优化查询:格式化日期后,Elasticsearch知道该如何存储和索引这些时间数据,从而可以高效地执行基于日期的范围查询、过滤和排序操作。明确的格式定义还可以帮助Elasticsearch 进行更优化的存储和压缩。
- 避免歧义:没有明确格式的日期可能导致歧义,比如 "2023-09-03"是日期,还是年份?加上时间部分(如 "yyyy-MM-dd HH:mm:ss")可以更明确地表明时间的精度,便于进行更精确的查询
7、isDelete:使用 keyword 类型,表示是否被删除。 因为 keyword 是为精确匹配设计的,适用于枚举值精确查询的场景,性能好且清晰。为什么不用 boolean 类型呢?因为 MySQL 数据库存储的是 0 和 1,写入 ES 时需要转换类型。
编写 ES Dao 层
java
@Document(indexName = "question")
@Data
public class QuestionEsDTO implements Serializable {
private static final String DATE_TIME_PATTERN = "yyyy-MM-dd HH:mm:ss";
/**
* id
*/
@Id
private Long id;
/**
* 标题
*/
private String title;
/**
* 内容
*/
private String content;
/**
* 答案
*/
private String answer;
/**
* 标签列表
*/
private List<String> tags;
/**
* 创建用户 id
*/
private Long userId;
/**
* 创建时间
*/
@Field(type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)
private Date createTime;
/**
* 更新时间
*/
@Field(type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)
private Date updateTime;
/**
* 是否删除
*/
private Integer isDelete;
private static final long serialVersionUID = 1L;
/**
* 对象转包装类
*
* @param question
* @return
*/
public static QuestionEsDTO objToDto(Question question) {
if (question == null) {
return null;
}
QuestionEsDTO questionEsDTO = new QuestionEsDTO();
BeanUtils.copyProperties(question, questionEsDTO);
String tagsStr = question.getTags();
if (StringUtils.isNotBlank(tagsStr)) {
questionEsDTO.setTags(JSONUtil.toList(tagsStr, String.class));
}
return questionEsDTO;
}
/**
* 包装类转对象
*
* @param questionEsDTO
* @return
*/
public static Question dtoToObj(QuestionEsDTO questionEsDTO) {
if (questionEsDTO == null) {
return null;
}
Question question = new Question();
BeanUtils.copyProperties(questionEsDTO, question);
List<String> tagList = questionEsDTO.getTags();
if (CollUtil.isNotEmpty(tagList)) {
question.setTags(JSONUtil.toJsonStr(tagList));
}
return question;
}
}定义 Dao 层
java
/**
* 题目 ES 操作
*/
public interface QuestionEsDao
extends ElasticsearchRepository<QuestionEsDTO, Long> {
}这是一个面向 Elasticsearch 的 DAO 接口,支持自动增删改查
2 种 Spring Data Elasticsearch 的使用方法,应该如何选择呢?
- Spring 默认给我们提供的操作 es 的客户端对象ElasticsearchRestTemplate,也提供了增删改查,它的增删改查更灵活,适用于更复杂的操作,返回结果更完整,但需要自己解析。
- ElasticsearchRepository<Entity,IdType>,默认提供了更简单易用的增删改查,返回结果也更直接。适用于可预期的、相对简单的操作 。
向 ES 全量写入数据
java
package com.yuan.InterviewPal.job.once;
import cn.hutool.core.collection.CollUtil;
import com.yuan.InterviewPal.esdao.QuestionEsDao;
import com.yuan.InterviewPal.model.dto.question.QuestionEsDTO;
import com.yuan.InterviewPal.model.entity.Question;
import com.yuan.InterviewPal.service.QuestionService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
import java.util.stream.Collectors;
/**
* 全量同步题目到Es
*/
// todo 取消注释开启任务
@Component
@Slf4j
public class FullSyncQuestionToEs implements CommandLineRunner {
@Resource
private QuestionService questionService;
@Resource
private QuestionEsDao questionEsDao;
@Override
public void run(String... args) {
// 全量获取题目(数据量不大的情况下使用)
List<Question> questionList = questionService.list();
if (CollUtil.isEmpty(questionList)) {
return;
}
// 转为 ES 实体类
List<QuestionEsDTO> questionEsDTOList = questionList.stream()
.map(QuestionEsDTO::objToDto)
.collect(Collectors.toList());
// 分页批量插入到 ES
final int pageSize = 500;
int total = questionEsDTOList.size();
log.info("FullSyncQuestionToEs start, total {}", total);
for (int i = 0; i < total; i += pageSize) {
// 注意同步的数据下标不能超过总数据量
int end = Math.min(i + pageSize, total);
log.info("sync from {} to {}", i, end);
questionEsDao.saveAll(questionEsDTOList.subList(i, end));
}
log.info("FullSyncQuestionToEs end, total {}", total);
}
}向ES增量写入
如果使用 MyBatis Plus 提供的 mapper 方法,查询时会默认过滤掉 isDelete = 1(逻辑已删除)的数据,而我们的需求是让 ES 和 MySQL 完全同步,所以需要在 QuestionMapper 中编写一个能查询出 isDelete = 1 数据的方法。
编写查询某个时间后更新的所有题目的方法:
java
public interface QuestionMapper extends BaseMapper<Question> {
/**
* 查询题目列表(包括已被删除的数据)
*/
@Select("select * from question where updateTime >= #{minUpdateTime}")
List<Question> listQuestionWithDelete(Date minUpdateTime);
}写增量同步到 ES 的定时任务
java
// todo 取消注释开启任务
@Component
@Slf4j
public class IncSyncQuestionToEs {
@Resource
private QuestionMapper questionMapper;
@Resource
private QuestionEsDao questionEsDao;
/**
* 每分钟执行一次
*/
@Scheduled(fixedRate = 60 * 1000)
public void run() {
// 查询近 5 分钟内的数据
long FIVE_MINUTES = 5 * 60 * 1000L;
Date fiveMinutesAgoDate = new Date(new Date().getTime() - FIVE_MINUTES);
List<Question> questionList = questionMapper.listQuestionWithDelete(fiveMinutesAgoDate);
if (CollUtil.isEmpty(questionList)) {
log.info("no inc question");
return;
}
List<QuestionEsDTO> questionEsDTOList = questionList.stream()
.map(QuestionEsDTO::objToDto)
.collect(Collectors.toList());
final int pageSize = 500;
int total = questionEsDTOList.size();
log.info("IncSyncQuestionToEs start, total {}", total);
for (int i = 0; i < total; i += pageSize) {
int end = Math.min(i + pageSize, total);
log.info("sync from {} to {}", i, end);
questionEsDao.saveAll(questionEsDTOList.subList(i, end));
}
log.info("IncSyncQuestionToEs end, total {}", total);
}
}开发 ES 搜索
QuestionService 新增查询接口:
java
/**
* 从 ES 查询题目
*
* @param questionQueryRequest
* @return
*/
Page<Question> searchFromEs(QuestionQueryRequest questionQueryRequest);编写实现方法
由于查询逻辑较为复杂,为了保证灵活性,选用 ElasticsearchRestTemplate 开发。
java
@Override
public Page<Question> searchFromEs(QuestionQueryRequest questionQueryRequest) {
// 获取参数
Long id = questionQueryRequest.getId();
Long notId = questionQueryRequest.getNotId();
String searchText = questionQueryRequest.getSearchText();
List<String> tags = questionQueryRequest.getTags();
Long questionBankId = questionQueryRequest.getQuestionBankId();
Long userId = questionQueryRequest.getUserId();
// 注意,ES 的起始页为 0
int current = questionQueryRequest.getCurrent() - 1;
int pageSize = questionQueryRequest.getPageSize();
String sortField = questionQueryRequest.getSortField();
String sortOrder = questionQueryRequest.getSortOrder();
// 构造查询条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 过滤
boolQueryBuilder.filter(QueryBuilders.termQuery("isDelete", 0));
if (id != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("id", id));
}
if (notId != null) {
boolQueryBuilder.mustNot(QueryBuilders.termQuery("id", notId));
}
if (userId != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("userId", userId));
}
if (questionBankId != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("questionBankId", questionBankId));
}
// 必须包含所有标签
if (CollUtil.isNotEmpty(tags)) {
for (String tag : tags) {
boolQueryBuilder.filter(QueryBuilders.termQuery("tags", tag));
}
}
// 按关键词检索
if (StringUtils.isNotBlank(searchText)) {
boolQueryBuilder.should(QueryBuilders.matchQuery("title", searchText));
boolQueryBuilder.should(QueryBuilders.matchQuery("content", searchText));
boolQueryBuilder.should(QueryBuilders.matchQuery("answer", searchText));
boolQueryBuilder.minimumShouldMatch(1);
}
// 排序
SortBuilder<?> sortBuilder = SortBuilders.scoreSort();
if (StringUtils.isNotBlank(sortField)) {
sortBuilder = SortBuilders.fieldSort(sortField);
sortBuilder.order(CommonConstant.SORT_ORDER_ASC.equals(sortOrder) ? SortOrder.ASC : SortOrder.DESC);
}
// 分页
PageRequest pageRequest = PageRequest.of(current, pageSize);
// 构造查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withPageable(pageRequest)
.withSorts(sortBuilder)
.build();
SearchHits<QuestionEsDTO> searchHits = elasticsearchRestTemplate.search(searchQuery, QuestionEsDTO.class);
// 复用 MySQL 的分页对象,封装返回结果
Page<Question> page = new Page<>();
page.setTotal(searchHits.getTotalHits());
List<Question> resourceList = new ArrayList<>();
if (searchHits.hasSearchHits()) {
List<SearchHit<QuestionEsDTO>> searchHitList = searchHits.getSearchHits();
for (SearchHit<QuestionEsDTO> questionEsDTOSearchHit : searchHitList) {
resourceList.add(QuestionEsDTO.dtoToObj(questionEsDTOSearchHit.getContent()));
}
}
page.setRecords(resourceList);
return page;
}在 QuestionController 编写新的搜索接口:
java
@PostMapping("/search/page/vo")
public BaseResponse<Page<QuestionVO>> searchQuestionVOByPage(@RequestBody QuestionQueryRequest questionQueryRequest,
HttpServletRequest request) {
long size = questionQueryRequest.getPageSize();
// 限制爬虫
ThrowUtils.throwIf(size > 200, ErrorCode.PARAMS_ERROR);
Page<Question> questionPage = questionService.searchFromEs(questionQueryRequest);
return ResultUtils.success(questionService.getQuestionVOPage(questionPage, request));
}